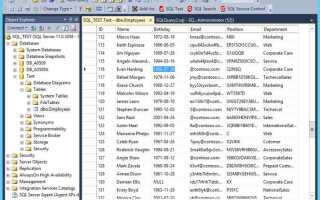
Для начала, чтобы вывести всю таблицу, достаточно использовать базовый запрос: SELECT * FROM table_name;. Этот запрос выберет все строки и все столбцы из указанной таблицы. Важно помнить, что использование звезды (*) означает выбор всех данных, что может повлиять на производительность, если таблица имеет большое количество столбцов.
Если нужно вывести только определенные столбцы, указываются их имена через запятую. Например, SELECT column1, column2 FROM table_name;. Такой подход помогает улучшить читаемость запроса и ускоряет обработку данных, так как сервер извлекает только необходимые поля.
Для фильтрации данных используется условие WHERE. Например, запрос SELECT * FROM table_name WHERE column_name = ‘value’; вернет только те строки, где значение в указанном столбце соответствует заданному условию. Этот метод незаменим при работе с большими объемами данных, позволяя существенно сузить выборку.
Когда необходимо извлечь данные из нескольких таблиц, используется оператор JOIN, который объединяет строки из разных источников. Существует несколько типов объединений, включая INNER JOIN, LEFT JOIN и другие, каждый из которых имеет свою специфику работы с данными, что позволяет гибко настраивать запросы для решения конкретных задач.
Каждый запрос в SQL – это мощный инструмент для работы с базами данных, и правильное использование операторов и условий значительно улучшает эффективность запросов и их читаемость.
Как выбрать данные из таблицы с помощью SELECT
Для выборки данных из таблицы в SQL используется оператор SELECT. Это основной инструмент для извлечения информации, который позволяет точно указать, какие столбцы и строки нужно получить. Синтаксис запроса выглядит следующим образом:
SELECT столбец1, столбец2, ... FROM таблица;Если необходимо выбрать все столбцы, используется символ *:
SELECT * FROM таблица;Вместо списка столбцов, можно указать конкретные условия для строк с помощью оператора WHERE. Например, если нужно получить данные только по определенному условию, запрос будет выглядеть так:
SELECT имя, возраст FROM сотрудники WHERE должность = 'Менеджер';Можно использовать различные операторы для более сложных условий: AND, OR, BETWEEN, IN и другие. Например, для выборки данных по возрасту, который находится в определенном диапазоне:
SELECT имя, возраст FROM сотрудники WHERE возраст BETWEEN 25 AND 40;Для сортировки результатов по возрастанию или убыванию используется оператор ORDER BY. Например, для сортировки списка сотрудников по возрасту:
SELECT имя, возраст FROM сотрудники ORDER BY возраст ASC;SELECT имя, возраст FROM сотрудники LIMIT 5;Также можно объединять результаты с нескольких таблиц, используя JOIN, если есть соответствующие связи между ними. Например, для объединения данных из таблицы сотрудников и таблицы отделов:
SELECT сотрудники.имя, отделы.название FROM сотрудники
JOIN отделы ON сотрудники.отдел_id = отделы.id;Важно помнить, что SELECT – это мощный инструмент, который можно комбинировать с различными функциями, агрегациями и фильтрами для получения точных и эффективных запросов.
Как отфильтровать результаты запроса с помощью WHERE
Для ограничения набора данных, возвращаемых запросом в SQL, используется оператор WHERE. Он позволяет указать условие, которому должны удовлетворять строки из таблицы. Условия могут включать сравнение значений, логические операторы и функции для проверки данных.
Простейший пример – выборка всех сотрудников с определённой должностью. Запрос может выглядеть так:
SELECT * FROM сотрудники WHERE должность = 'Менеджер';
Здесь условие должность = 'Менеджер' фильтрует только те строки, где значение в колонке должность совпадает с ‘Менеджер’.
Для более сложных фильтров можно использовать логические операторы, такие как AND и OR. Например, если нужно выбрать сотрудников, работающих в отделах «Маркетинг» или «Продажи», запрос будет таким:
SELECT * FROM сотрудники WHERE отдел = 'Маркетинг' OR отдел = 'Продажи';
Оператор AND позволяет комбинировать несколько условий, например, если нужно выбрать сотрудников, работающих в «Маркетинге» с зарплатой выше 50 000:
SELECT * FROM сотрудники WHERE отдел = 'Маркетинг' AND зарплата > 50000;
Также можно использовать операторы сравнения, такие как =, !=, >, <, >= и <=, а также BETWEEN для указания диапазона значений:
SELECT * FROM сотрудники WHERE зарплата BETWEEN 40000 AND 60000;
Если нужно найти строки с непустыми значениями в колонке, используется оператор IS NOT NULL:
SELECT * FROM сотрудники WHERE дата_рождения IS NOT NULL;
Для поиска строк, где значение начинается с определённого символа, применяется оператор LIKE. Пример запроса, выбирающего все имена сотрудников, начинающиеся на «Иван»:
SELECT * FROM сотрудники WHERE имя LIKE 'Иван%';
Фильтрация с помощью WHERE – это мощный инструмент для работы с большими объёмами данных, позволяющий отбирать только релевантные записи на основе заданных критериев.
Для сортировки данных по столбцам в SQL используется оператор ORDER BY. Он позволяет упорядочить строки результатов запроса в заданном порядке. Основная структура команды выглядит следующим образом:
SELECT столбец_1, столбец_2, ...
FROM таблица
ORDER BY столбец_1 [ASC|DESC], столбец_2 [ASC|DESC], ...;По умолчанию сортировка выполняется по возрастанию (ASC), но можно указать и убывание, добавив DESC после имени столбца. Например, для сортировки по убыванию значений в столбце age будет использоваться следующий запрос:
SELECT name, age
FROM users
ORDER BY age DESC;Если требуется сортировать данные по нескольким столбцам, то в запросе можно перечислить их в нужном порядке. Например, чтобы отсортировать пользователей сначала по возрасту, а затем по имени, можно использовать следующий запрос:
SELECT name, age
FROM users
ORDER BY age DESC, name ASC;Важно помнить, что сортировка по нескольким столбцам происходит в том порядке, в котором они указаны в запросе. Если для одного столбца задать сортировку по убыванию, а для другого по возрастанию, то SQL выполнит сортировку сначала по первому столбцу, затем по второму, если значения в первом столбце одинаковы.
Также можно сортировать данные по выражениям, а не только по столбцам. Например, чтобы отсортировать данные по длине строк в столбце name, можно использовать функцию LENGTH:
SELECT name
FROM users
ORDER BY LENGTH(name) DESC;Когда необходимо отсортировать данные без учета регистра символов, можно использовать функцию LOWER или UPPER для приведения значений в столбце к единому регистру. Например:
SELECT name
FROM users
ORDER BY LOWER(name) ASC;Кроме того, для ускорения выполнения сортировки в больших таблицах рекомендуется индексировать те столбцы, по которым часто происходит сортировка. Это значительно снижает нагрузку на сервер и ускоряет время обработки запросов.
Оператор LIMIT используется в SQL для ограничения количества строк, которые возвращаются в результате запроса. Это полезно при работе с большими объемами данных, когда необходимо получить только часть результата, например, для предварительного просмотра или пагинации.
Простой пример использования LIMIT: если вам нужно вывести только 10 первых строк из таблицы, запрос будет выглядеть так:
SELECT * FROM employees LIMIT 10;
SELECT * FROM employees LIMIT 10 OFFSET 20;
Важно помнить, что в большинстве СУБД нумерация строк начинается с 0, поэтому OFFSET 20 означает пропуск первых 20 строк.
Использование LIMIT может повлиять на производительность запроса, особенно при работе с большими таблицами, так как СУБД всё равно может сначала обработать все строки, чтобы применить ограничения. Для повышения производительности в таких случаях можно комбинировать LIMIT с индексами и дополнительными условиями WHERE.
Как использовать агрегатные функции для анализа данных
Агрегатные функции в SQL позволяют выполнять вычисления на наборе строк, сводя их к единому результату. Эти функции играют ключевую роль при анализе больших объемов данных, обеспечивая быструю и эффективную обработку информации.
Наиболее часто используемые агрегатные функции: COUNT(), SUM(), AVG(), MIN(), MAX(). Каждая из них имеет свою специфику применения, что важно учитывать при анализе.
COUNT() используется для подсчета числа строк, удовлетворяющих заданным условиям. Например, если нужно подсчитать количество заказов, выполненных клиентом, можно использовать запрос:
SELECT COUNT(*) FROM orders WHERE customer_id = 123;
Эта функция полезна для оценки количества записей, таких как количество пользователей, заказов или транзакций.
SUM() суммирует значения в указанном столбце. Например, для подсчета общей стоимости всех заказов клиента запрос будет следующим:
SELECT SUM(order_amount) FROM orders WHERE customer_id = 123;
Эта функция полезна при анализе финансовых данных, например, для вычисления общего объема продаж, затрат или доходов.
AVG() вычисляет среднее значение для указанного столбца. Для определения средней суммы заказа можно использовать запрос:
SELECT AVG(order_amount) FROM orders WHERE customer_id = 123;
Средние значения позволяют выявлять общие тенденции, такие как средний доход по сегментам клиентов или средней продолжительности сделок.
MIN() и MAX() используются для нахождения минимальных и максимальных значений в столбце соответственно. Например, чтобы найти самый дешевый и самый дорогой заказ клиента, можно использовать такие запросы:
SELECT MIN(order_amount) FROM orders WHERE customer_id = 123; SELECT MAX(order_amount) FROM orders WHERE customer_id = 123;
Эти функции помогают выявлять экстремальные значения в наборе данных, что полезно при определении наилучших и наихудших показателей.
Агрегатные функции также часто используются в сочетании с GROUP BY для разделения данных на группы. Например, чтобы найти среднюю стоимость заказа для каждого клиента, можно использовать такой запрос:
SELECT customer_id, AVG(order_amount) FROM orders GROUP BY customer_id;
Группировка данных позволяет проводить анализ по категориям, таким как регион, возрастная группа или тип товара, что помогает более детально изучать данные.
Не забывайте об индексации таблиц при работе с большими объемами данных. Это может значительно ускорить выполнение запросов, использующих агрегатные функции, особенно при необходимости обработки больших наборов данных за короткий промежуток времени.
Как объединять несколько таблиц с помощью JOIN
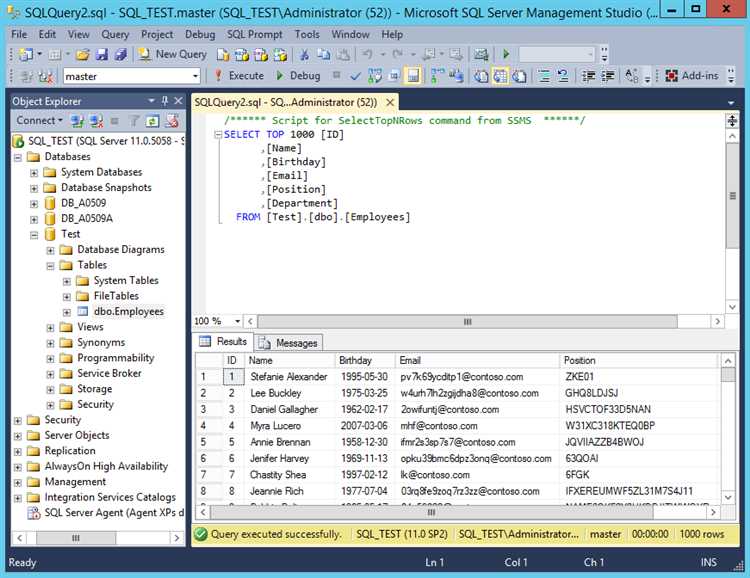
Оператор JOIN позволяет объединять строки из нескольких таблиц в SQL, основываясь на общих столбцах. Это позволяет получать более комплексные данные из разных источников в одной выборке. Существует несколько типов JOIN, каждый из которых имеет свои особенности.
Типы JOIN
- INNER JOIN – возвращает только те строки, которые имеют совпадения в обеих таблицах. Если в одной из таблиц нет соответствующих данных, строка не будет включена в результат.
- LEFT JOIN (или LEFT OUTER JOIN) – включает все строки из левой таблицы и соответствующие строки из правой таблицы. Если в правой таблице нет данных, то будут возвращены NULL-значения.
- RIGHT JOIN (или RIGHT OUTER JOIN) – аналогичен LEFT JOIN, но включает все строки из правой таблицы, даже если нет совпадений в левой.
- FULL JOIN (или FULL OUTER JOIN) – возвращает все строки из обеих таблиц, заполняя пустыми значениями NULL там, где нет совпадений.
- CROSS JOIN – возвращает декартово произведение двух таблиц. Каждая строка из первой таблицы будет объединена с каждой строкой из второй таблицы, что может привести к большому числу строк в результате.
Пример использования INNER JOIN
Допустим, у нас есть две таблицы: employees (сотрудники) и departments (отделы). Для того чтобы объединить данные о сотрудниках с информацией об их отделах, можно использовать запрос:
SELECT employees.name, departments.department_name FROM employees INNER JOIN departments ON employees.department_id = departments.department_id;
Этот запрос вернёт только тех сотрудников, которые имеют соответствующий отдел. Если сотрудник не назначен в отдел, он не попадет в результат.
LEFT JOIN для получения всех сотрудников
Для того чтобы включить всех сотрудников, даже если у них нет соответствующего отдела, используем LEFT JOIN:
SELECT employees.name, departments.department_name FROM employees LEFT JOIN departments ON employees.department_id = departments.department_id;
Здесь будут показаны все сотрудники. Для тех, у кого нет назначенного отдела, в столбце department_name будет значением NULL.
FULL JOIN для полноты данных
Когда необходимо получить все данные из обеих таблиц, даже если для некоторых строк нет совпадений, используется FULL JOIN:
SELECT employees.name, departments.department_name FROM employees FULL JOIN departments ON employees.department_id = departments.department_id;
Этот запрос вернёт всех сотрудников и все отделы, даже если некоторые из них не имеют соответствующих записей в другой таблице.
CROSS JOIN для комбинации всех строк
Если необходимо получить все возможные комбинации строк из двух таблиц, используется CROSS JOIN:
SELECT employees.name, departments.department_name FROM employees CROSS JOIN departments;
Этот запрос вернёт все сочетания сотрудников и отделов, даже если нет логического соответствия между ними.
Советы по использованию JOIN
- Используйте INNER JOIN, если вам нужно объединить только те строки, где есть точное соответствие.
- LEFT JOIN поможет сохранить все данные из первой таблицы, даже если во второй таблице нет совпадений.
- Для обработки отсутствующих данных из обеих таблиц используйте FULL JOIN.
- Остерегайтесь использования CROSS JOIN на больших таблицах, так как результат может быть очень большим.
SELECT FORMAT(12345.6789, 2);
Этот запрос выведет число как «12,345.68». В PostgreSQL аналогичное действие выполняется так:
SELECT TO_CHAR(12345.6789, '99999.99');
SELECT DATE_FORMAT(NOW(), '%d-%m-%Y');
Результат будет выглядеть как «23-04-2025». В PostgreSQL, для того чтобы получить аналогичный формат, используется:
SELECT TO_CHAR(NOW(), 'DD-MM-YYYY');
SELECT LPAD('Test', 10, '*');
Этот запрос выведет «*Test*****». В MySQL аналогичный эффект достигается с помощью:
SELECT LPAD('Test', 10, '*');
Настройка числовых и строковых данных с разделителями: В случае работы с большими числами, можно задать разделители тысяч. В MySQL это можно сделать с помощью FORMAT(), а в PostgreSQL через TO_CHAR() с использованием шаблона:
SELECT TO_CHAR(1234567890, '9,999,999,999');
Этот запрос отформатирует число с разделителями тысяч, результат будет «1,234,567,890».
Конкатенация данных: Для объединения данных в одну строку в SQL обычно используется CONCAT(). В PostgreSQL для тех же целей применяется оператор ||:
SELECT CONCAT(first_name, ' ', last_name) FROM employees;
Или в PostgreSQL:
SELECT first_name || ' ' || last_name FROM employees;
Вопрос-ответ:
Как вывести таблицу в SQL?
Чтобы вывести таблицу в SQL, используется команда `SELECT`. Например, для вывода всех данных из таблицы `employees` необходимо выполнить запрос: `SELECT * FROM employees;`. Эта команда выберет все строки и все столбцы из указанной таблицы.
Что такое SQL-запрос и как его использовать для вывода данных?
SQL-запрос — это инструкция для работы с базой данных. Для вывода данных используется оператор `SELECT`. Чтобы вывести определённые столбцы, можно указать их в запросе, например: `SELECT name, age FROM employees;` Это выведет только столбцы `name` и `age` из таблицы `employees`. Если нужно вывести все столбцы, используется символ `*`.
Как вывести данные с фильтрацией по определённому условию?
Для фильтрации данных в SQL используется оператор `WHERE`. Например, чтобы вывести данные сотрудников старше 30 лет, запрос будет выглядеть так: `SELECT * FROM employees WHERE age > 30;`. Это выберет все строки из таблицы `employees`, где значение в столбце `age` больше 30.
Как отсортировать данные при выводе таблицы?
Чтобы отсортировать данные в SQL, используется оператор `ORDER BY`. Например, для сортировки сотрудников по возрасту в порядке убывания запрос будет таким: `SELECT * FROM employees ORDER BY age DESC;`. Для сортировки по возрастанию используйте `ASC` (по умолчанию). Запрос `SELECT * FROM employees ORDER BY age ASC;` выведет сотрудников, отсортированных по возрасту от младшего к старшему.