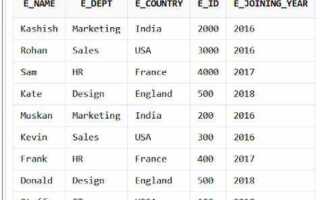
Определение номера строки в SQL важно при ранжировании данных, разбиении на страницы, а также для отладки и анализа. В отличие от Excel, в реляционных базах данных строки не имеют фиксированных позиций – порядок зависит от запроса. Поэтому необходимо использовать специальные конструкции, такие как оконные функции.
Функция ROW_NUMBER() предоставляет уникальный номер строки в пределах определённого окна, заданного с помощью OVER(ORDER BY …). Пример: SELECT ROW_NUMBER() OVER (ORDER BY id) AS row_num FROM users – здесь каждой строке из таблицы users присваивается порядковый номер в соответствии с сортировкой по id.
Если требуется определить номер строки в подмножестве данных (например, внутри каждой категории), применяется PARTITION BY: ROW_NUMBER() OVER (PARTITION BY category_id ORDER BY created_at). Это особенно полезно при анализе временных рядов или поиске первой записи по группе.
Важно учитывать: без явного ORDER BY номер строки будет непредсказуемым, поскольку SQL не гарантирует порядок строк без соответствующего указания. Также, если цель – получить устойчивый и воспроизводимый результат, следует использовать уникальные поля в сортировке, чтобы исключить дублирование номеров при равных значениях.
Использование ROW_NUMBER() для нумерации строк в выборке
Функция ROW_NUMBER() назначает уникальный номер каждой строке в рамках заданного окна. Это особенно полезно при реализации постраничной навигации, удалении дубликатов или ранжировании данных.
Синтаксис следующий: ROW_NUMBER() OVER (PARTITION BY [колонка] ORDER BY [колонка]). Ключевая часть – OVER с обязательным указанием ORDER BY. Без него SQL вернёт ошибку.
Пример: чтобы пронумеровать сотрудников по дате найма внутри каждого отдела:
SELECT
employee_id,
department_id,
hire_date,
ROW_NUMBER() OVER (PARTITION BY department_id ORDER BY hire_date) AS row_num
FROM employees;Если PARTITION BY опущен, нумерация будет глобальной по всей выборке. Это удобно, например, для получения топ-N записей. Пример – первые три заказа по убыванию суммы:
SELECT *
FROM (
SELECT
order_id,
customer_id,
amount,
ROW_NUMBER() OVER (ORDER BY amount DESC) AS row_num
FROM orders
) t
WHERE row_num <= 3;Важно: ROW_NUMBER() не гарантирует стабильный результат без уникального критерия сортировки. При одинаковых значениях в ORDER BY строки могут получить произвольные номера при повторных выполнениях запроса.
Как пронумеровать строки без изменения порядка данных
Для нумерации строк в SQL без изменения их порядка необходимо использовать оконные функции. Если порядок задаётся по определённому полю, например, дате создания, применяется функция ROW_NUMBER() с директивой OVER(ORDER BY). Пример:
SELECT ROW_NUMBER() OVER(ORDER BY created_at) AS row_num, * FROM orders;
Если порядок данных не следует менять, но отсутствует явное поле сортировки, следует использовать скрытое логическое поле, обеспечивающее исходную последовательность. Например, если таблица читается в порядке физического размещения записей, можно использовать псевдостолбец ctid в PostgreSQL:
SELECT ROW_NUMBER() OVER(ORDER BY ctid) AS row_num, * FROM my_table;
В SQL Server аналогичной цели можно достичь через %%physloc%% или добавлением идентификатора при вставке, сохранив исходную последовательность.
Важно: без указания порядка оконная функция не гарантирует устойчивую нумерацию. Всегда явно определяйте столбец сортировки, отражающий нужный порядок. При его отсутствии создайте временное поле со значениями, соответствующими текущей позиции, и используйте его в ORDER BY.
Присвоение номеров строк с учётом сортировки по дате
Для нумерации строк в зависимости от даты используется оконная функция ROW_NUMBER() с обязательным указанием порядка сортировки. Пример:
SELECT ROW_NUMBER() OVER (ORDER BY created_at DESC) AS row_num, * FROM orders;
Здесь каждой строке присваивается уникальный номер согласно убыванию даты создания заказа. Это особенно важно при анализе последних транзакций или построении отчетов по хронологии.
Сортировка по возрастанию применяется аналогично: ORDER BY created_at ASC. Используйте это, если требуется получить номера строк от самой ранней даты к поздней.
Если требуется дополнительная группировка, например, нумерация в пределах пользователя, добавляется конструкция PARTITION BY:
SELECT ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY created_at DESC) AS row_num, * FROM orders;
Такой подход позволяет отслеживать, например, последнюю активность каждого пользователя в отдельности. Для стабильных результатов сортировки убедитесь, что поле даты имеет точность до секунд или больше, иначе при одинаковых значениях порядок может быть произвольным.
Добавление номера строки в результат JOIN-запроса
Для добавления номера строки в результат JOIN-запроса в SQL можно использовать функцию ROW_NUMBER(), которая назначает уникальный номер каждой строке в результате выполнения запроса. Это особенно полезно, когда необходимо отсортировать данные по определенному признаку и добавить индекс в результирующий набор данных.
Пример использования функции ROW_NUMBER() с JOIN-запросом:
SELECT
ROW_NUMBER() OVER (ORDER BY t1.id) AS row_num,
t1.*, t2.*
FROM
table1 t1
JOIN
table2 t2 ON t1.id = t2.table1_id;
В этом примере ROW_NUMBER() присваивает номер каждой строке, начиная с 1, в зависимости от сортировки по столбцу t1.id. Указание OVER (ORDER BY t1.id) гарантирует, что номер строки будет назначен с учетом порядка данных.
При необходимости номер строки может быть сброшен для каждой группы данных. Для этого можно использовать разделение по столбцу с помощью ключевого слова PARTITION BY. Например:
SELECT
ROW_NUMBER() OVER (PARTITION BY t1.category ORDER BY t1.id) AS row_num,
t1.*, t2.*
FROM
table1 t1
JOIN
table2 t2 ON t1.id = t2.table1_id;
В данном случае номер строки будет начинаться с 1 для каждой категории (t1.category) отдельно. Это полезно, если нужно, например, номеровать строки внутри каждой категории или группы.
При использовании ROW_NUMBER() важно помнить, что эта функция работает только с запросами, поддерживающими оконные функции, что требует версии СУБД, которая поддерживает подобные операции (например, PostgreSQL, SQL Server, MySQL 8.0 и выше).
Нумерация строк по группам с использованием PARTITION BY
Команда SQL PARTITION BY позволяет выполнять нумерацию строк по отдельным группам внутри таблицы, что полезно для анализа данных по категориям. Этот метод используется в сочетании с функциями окон, такими как ROW_NUMBER(), RANK() или DENSE_RANK(). Он позволяет создать уникальную нумерацию для каждой группы без необходимости добавления дополнительного столбца.
Для нумерации строк по группам важно правильно выбрать разделение данных. PARTITION BY делит данные на группы, а функция, например, ROW_NUMBER(), присваивает уникальный номер каждой строке в группе. Группировка осуществляется по одному или нескольким столбцам, в зависимости от потребностей анализа.
Пример использования функции ROW_NUMBER() с PARTITION BY для нумерации строк по группам:
SELECT
department_id,
employee_id,
ROW_NUMBER() OVER (PARTITION BY department_id ORDER BY hire_date) AS row_num
FROM employees;
В этом примере строки таблицы employees нумеруются внутри каждой группы по столбцу department_id, а порядок нумерации зависит от даты найма сотрудника. Каждому сотруднику будет присвоен уникальный номер в пределах своего департамента.
Важно помнить, что PARTITION BY не изменяет саму таблицу, а только упорядочивает данные в рамках запроса, не создавая новых столбцов в исходной таблице. Эта техника используется для аналитических запросов, где необходимо оценить порядковый номер строк в группах или провести сравнение данных внутри каждой группы.
Рекомендуется использовать PARTITION BY для работы с большими объемами данных, когда необходимо получать статистику или анализировать данные по подмножествам, не выполняя сложных подзапросов.
Сравнение ROW_NUMBER(), RANK() и DENSE_RANK() при нумерации
При нумерации строк в SQL существует три функции: ROW_NUMBER(), RANK() и DENSE_RANK(). Несмотря на схожесть в применении, они ведут себя по-разному, особенно в случае одинаковых значений в столбцах, используемых для сортировки. Рассмотрим основные различия и рекомендации по выбору функции в зависимости от ситуации.
1. ROW_NUMBER() – эта функция присваивает уникальный номер каждой строке. Нумерация начинается с 1, и не возникает пропусков, даже если строки имеют одинаковые значения в сортируемых столбцах.
- Используется, когда требуется уникальный номер для каждой строки, независимо от повторяющихся значений.
- Рекомендуется, когда важно, чтобы каждая строка имела свой уникальный индекс.
2. RANK() – в отличие от ROW_NUMBER(), RANK() присваивает одинаковые номера строкам с одинаковыми значениями в сортируемых столбцах, но после этих строк пропускает номер. Например, если две строки получили ранг 1, следующая строка будет иметь ранг 3.
- Используется, когда необходимо сохранить пропуски в нумерации для одинаковых значений.
- Полезно при создании отчетов или рейтингов, где одинаковые результаты должны быть отображены на одинаковых позициях, но пропуск позиций является важным.
3. DENSE_RANK() – в отличие от RANK(), DENSE_RANK() также присваивает одинаковые номера строкам с одинаковыми значениями, но не делает пропусков в номерах. Если две строки получили ранг 1, следующая строка будет иметь ранг 2, а не 3.
- Используется, когда нужно избежать пропусков в номерах при одинаковых значениях.
- Рекомендуется для случаев, когда важно, чтобы нумерация оставалась последовательной, даже если строки имеют одинаковые значения.
Рекомендации:
- Выбирайте ROW_NUMBER(), если нужно обеспечить уникальность номера для каждой строки, независимо от значений.
- Используйте RANK(), если хотите учитывать пропуски в нумерации для строк с одинаковыми значениями.
- Используйте DENSE_RANK(), если пропуски в нумерации нежелательны при наличии одинаковых значений.
Как получить номер строки в подзапросе
- ROW_NUMBER() – это оконная функция, которая возвращает уникальный номер строки для каждой строки в результате подзапроса.
Пример использования:
SELECT ROW_NUMBER() OVER (ORDER BY id) AS row_num, id, name FROM employees WHERE department = 'Sales';
Здесь функция ROW_NUMBER() генерирует номер строки для каждого сотрудника в отделе «Sales», начиная с 1. Номера строк будут упорядочены по полю id.
- RANK() – аналогична
ROW_NUMBER(), но в случае одинаковых значений в порядке сортировки для двух строк будет присвоен один и тот же номер.
Пример использования:
SELECT RANK() OVER (ORDER BY salary DESC) AS row_num, name, salary FROM employees;
В отличие от ROW_NUMBER(), RANK() присваивает одинаковые номера строкам с одинаковым значением salary, но пропускает следующий номер.
- NTILE(n) – разбивает строки на
nравных групп и присваивает номер каждой группе.
Пример:
SELECT NTILE(4) OVER (ORDER BY salary DESC) AS quartile, name, salary FROM employees;
Этот запрос делит сотрудников на 4 группы по уровню зарплаты, присваивая каждой строке номер квартиля.
Каждый из этих методов можно использовать в подзапросах для более сложных операций с номером строки, например, при анализе данных или создания отчетов. Важно учитывать, что оконные функции работают только в том случае, если подзапрос возвращает упорядоченные данные.
Нумерация строк при помощи переменных в MySQL
Для нумерации строк в MySQL можно использовать пользовательские переменные. Они позволяют назначить уникальный номер каждой строке результата запроса, не требуя создания дополнительных столбцов или изменений в структуре базы данных.
Переменная в MySQL хранит значение на протяжении выполнения запроса, что позволяет ей накапливать значения для каждой строки. С помощью этой техники можно легко добавить порядковый номер к каждой строке, независимо от порядка сортировки.
Пример использования переменной для нумерации строк:
SELECT @rownum := @rownum + 1 AS row_number, column1, column2 FROM table_name, (SELECT @rownum := 0) AS init;
В этом запросе:
- Переменная @rownum инициализируется значением 0 с помощью подзапроса (SELECT @rownum := 0).
- Каждая строка получает уникальный номер, увеличиваясь на 1 при каждом проходе по результату.
- Чтобы вернуть результат в виде порядковых номеров, используется выражение @rownum := @rownum + 1.
Данный метод полезен в ситуациях, когда необходимо генерировать нумерацию по запросу без модификации самой базы данных или использования дополнительных индексов. Однако следует помнить, что переменная зависит от порядка строк в результате, который может изменяться в зависимости от условий сортировки.
Важно учитывать, что нумерация с использованием переменных в MySQL не является устойчивой при выполнении сложных операций с объединениями (JOIN) или при большом объеме данных, что может вызвать проблемы с производительностью. Поэтому этот метод лучше всего применять в рамках простых запросов или с небольшими наборами данных.