Microsoft SQL Server (MS SQL) – это одна из самых популярных систем управления базами данных, которая широко используется для обработки больших объемов данных и создания сложных бизнес-решений. В этом руководстве мы разберем, как эффективно работать с MS SQL как для новичков, так и для опытных пользователей, предоставив конкретные шаги и рекомендации для разных уровней знаний.
Для начинающих пользователей ключевыми этапами работы с MS SQL являются установка и настройка SQL Server, а также освоение базовых операций: создание баз данных, таблиц, работа с запросами на языке T-SQL. Важно не только понимать синтаксис языка, но и знать основные принципы работы с данными, такие как индексация, нормализация и использование транзакций. Начните с простых запросов, а затем постепенно переходите к более сложным операциям, таким как создание представлений и хранимых процедур.
Продвинутые пользователи могут углубиться в оптимизацию запросов, настройку производительности и безопасность баз данных. Для этого следует изучить использование индексов для ускорения запросов, профилирование запросов с помощью SQL Server Profiler и управление блокировками для обеспечения высокого уровня доступности. Также важно освоить методы работы с распределенными базами данных и реализацию отказоустойчивых решений с помощью технологии Always On.
Каждый этап работы с MS SQL требует практики, так как теория без реального опыта может быть неэффективной. Начинать стоит с простых операций, постепенно усложняя задачи по мере приобретения уверенности и знаний. Важно регулярно практиковаться и следить за новыми функциями и обновлениями, чтобы поддерживать свой уровень знаний актуальным.
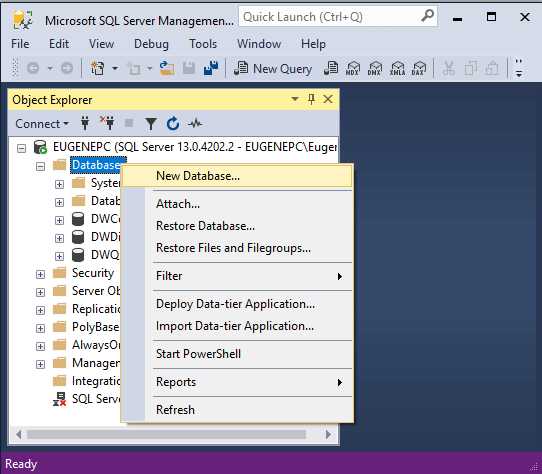
Настройка и подключение к базе данных MS SQL через SQL Server Management Studio
1. Установка SQL Server Management Studio (SSMS):
Скачайте последнюю версию SSMS с официального сайта Microsoft. После загрузки выполните установку, следуя инструкциям мастера. Убедитесь, что вы установили все необходимые компоненты для полноценной работы с SQL Server.
2. Запуск SQL Server Management Studio:
После установки откройте SSMS. На экране появится окно подключения, где необходимо указать параметры подключения к серверу.
3. Указание сервера и аутентификации:
В поле «Сервер» введите имя хоста SQL Server. Это может быть либо имя компьютера, на котором установлен сервер, либо IP-адрес. Если сервер настроен на использование именованных экземпляров, добавьте имя экземпляра через символ \ (например, SERVER\INSTANCE).
Выберите тип аутентификации. Обычно это:
— Windows Authentication, если вы хотите использовать учетную запись Windows.
— SQL Server Authentication, если для входа используется учетная запись SQL Server с паролем.
4. Проверка параметров подключения:
Перед подключением убедитесь, что сервер доступен в сети. Для этого можно использовать команду ping с IP-адресом сервера или его именем. Также проверьте, что SQL Server слушает на порту, который вы указали (обычно 1433 для TCP/IP). Если сервер находится в защищенной сети, убедитесь, что настройки брандмауэра разрешают подключение к нужному порту.
5. Подключение:
Нажмите кнопку «Подключиться». В случае правильных данных и настроек, SSMS установит соединение с сервером, и в панели объектов появится доступ к базам данных и другим объектам SQL Server. Если возникли проблемы с подключением, обратитесь к журналу ошибок SQL Server, чтобы выяснить, что именно не так с параметрами подключения.
6. Настройка безопасности:
После успешного подключения рекомендуется проверить настройки безопасности SQL Server. Создайте новые учетные записи с минимальными правами для пользователей, а также включите шифрование данных, если это необходимо. Использование комбинированной аутентификации (Windows + SQL Server) добавляет дополнительный уровень безопасности.
7. Управление подключениями:
Если SSMS подключается слишком долго, проверьте настройки таймаутов на сервере и в клиентском приложении. Также можно настроить параметры соединения через файл конфигурации, чтобы избежать повторных запросов на подключение в случае простоя сети.
Работа с SQL Server через SSMS предоставляет множество возможностей для эффективного администрирования, и правильная настройка подключения является важным шагом для обеспечения стабильности и безопасности работы с базой данных.
Основы написания запросов: выборка данных с помощью SELECT
Запросы на выборку данных в SQL формируются с помощью оператора SELECT, который извлекает информацию из таблиц базы данных. Основное назначение этого оператора – получение данных для анализа или обработки. Структура базового запроса выглядит следующим образом:
SELECT <столбцы> FROM <таблица>;Основной элемент – это выбор столбцов, которые нужно вернуть. Если нужно выбрать все столбцы из таблицы, используется символ звездочки (*):
SELECT * FROM employees;Чтобы выбрать только определенные столбцы, указываются их имена через запятую:
SELECT first_name, last_name FROM employees;Также можно применять условие с помощью WHERE, чтобы отфильтровать данные по нужным критериям. Например, чтобы выбрать сотрудников с зарплатой выше 50000:
SELECT first_name, last_name, salary FROM employees WHERE salary > 50000;Важно помнить, что SQL-запрос чувствителен к регистру в части имен столбцов и таблиц, а также значения в строках (например, для текстовых данных). Поэтому, если в базе используются большие или маленькие буквы, их следует указывать точно так, как они записаны в схеме базы данных.
Для упорядочивания результатов используется оператор ORDER BY. По умолчанию сортировка идет по возрастанию. Чтобы отсортировать данные по убыванию, необходимо добавить DESC:
SELECT first_name, last_name, salary FROM employees WHERE salary > 50000 ORDER BY salary DESC;Если нужно ограничить количество возвращаемых строк, используется оператор TOP (для MS SQL Server). Например, чтобы выбрать только 10 сотрудников с наибольшей зарплатой:
SELECT TOP 10 first_name, last_name, salary FROM employees ORDER BY salary DESC;Для работы с уникальными значениями используется DISTINCT. Этот оператор исключает повторяющиеся строки из результата:
SELECT DISTINCT department FROM employees;Для вычислений в запросах можно использовать арифметические операторы (например, сложение, вычитание). Например, чтобы посчитать годовую зарплату сотрудников (умножив месячную зарплату на 12):
SELECT first_name, last_name, salary * 12 AS annual_salary FROM employees;Таким образом, оператор SELECT является ключевым элементом при работе с данными в MS SQL. Для правильного написания запросов важно учитывать структуру данных, типы столбцов и логику, необходимую для фильтрации и сортировки информации.
Как создавать таблицы и работать с типами данных в MS SQL
В MS SQL для создания таблиц используется команда CREATE TABLE. Эта команда позволяет задать структуру таблицы, включая имена столбцов, их типы данных и ограничения. Пример синтаксиса:
CREATE TABLE ИмяТаблицы (
Столбец1 ТипДанных Ограничения,
Столбец2 ТипДанных Ограничения,
...
);Типы данных играют ключевую роль в корректной работе базы данных. В MS SQL существует несколько категорий типов данных, которые могут быть использованы для хранения различных видов информации.
Для хранения целых чисел используются типы INT и BIGINT. Тип INT хранит числа от -2 147 483 648 до 2 147 483 647, в то время как BIGINT подходит для хранения более крупных значений (от -9 223 372 036 854 775 808 до 9 223 372 036 854 775 807).
Если требуется хранить числа с плавающей точкой, используют FLOAT и REAL. Тип FLOAT поддерживает более широкие диапазоны значений и точность, чем REAL.
Для хранения строк текста применяют типы VARCHAR и CHAR. VARCHAR рекомендуется использовать, когда длина строк варьируется, так как этот тип данных более экономичен по памяти. В свою очередь, CHAR эффективен для строк фиксированной длины, например, для хранения кодов или идентификаторов. Размер данных для VARCHAR можно указать с помощью числа символов (например, VARCHAR(255)).
Для хранения дат и времени используются типы DATE, TIME, DATETIME и DATETIME2. Тип DATE сохраняет только дату без времени, а TIME – только время. Типы DATETIME и DATETIME2 включают и дату, и время. DATETIME2 обеспечивает большую точность, чем DATETIME, и может использоваться в ситуациях, когда нужна высокая точность по времени.
Особое внимание стоит уделить типу BIT, который используется для хранения булевых значений (0 или 1). Этот тип данных идеально подходит для полей, где возможны только два состояния (например, «да» или «нет»).
Для работы с уникальными идентификаторами и ключами используется тип UNIQUEIDENTIFIER, который генерирует уникальные значения с помощью функции NEWID().
Кроме того, MS SQL поддерживает ENUM и SET для хранения набора заранее заданных значений, однако эти типы данных реализуются с помощью таблиц и внешних ограничений, поскольку они не поддерживаются напрямую в MS SQL.
Для того чтобы задать ограничения на значения столбцов, можно использовать ключевые слова NOT NULL, DEFAULT, PRIMARY KEY, FOREIGN KEY, CHECK и другие. Например, если нужно, чтобы столбец не мог содержать пустых значений, используйте NOT NULL.
Для изменения структуры уже существующей таблицы применяется команда ALTER TABLE, которая позволяет добавлять, удалять или изменять столбцы, а также устанавливать ограничения.
Пример добавления нового столбца в таблицу:
ALTER TABLE ИмяТаблицы ADD НовыйСтолбец ТипДанных;Для удаления столбца используется:
ALTER TABLE ИмяТаблицы DROP COLUMN Столбец;Таким образом, знание типов данных и умение создавать таблицы в MS SQL помогает эффективно работать с базой данных, гарантируя правильное использование памяти и точность хранения информации.
Использование индексов для оптимизации поиска и вставки данных

Для эффективного использования индексов важно правильно выбирать столбцы для их создания. Рекомендуется индексировать столбцы, которые часто используются в условиях поиска (например, в операторах WHERE), а также те, по которым выполняются сортировки (ORDER BY) или соединения (JOIN). Стоит избегать создания индексов на столбцах с низкой кардинальностью (например, булевых или очень часто повторяющихся значений), так как они не приносят значительных улучшений в производительности.
Индексы также оказывают влияние на операции вставки, обновления и удаления данных. Каждый раз, когда данные в таблице изменяются, индекс нужно обновить, что может замедлить вставку новых записей. Это особенно важно учитывать при проектировании систем с высокой нагрузкой на вставку данных. Поэтому важно выбирать баланс между количеством индексов и их влиянием на производительность вставки.
Для оптимизации вставки данных можно использовать следующие подходы:
- Ограничить количество индексов на таблице, оставив только те, которые критичны для производительности поиска.
- Использовать отложенное обновление индексов с помощью опции
NOLOCKили выполнить обновление индексов в периоды низкой нагрузки на систему. - Использовать индексы только для колонок, которые участвуют в частых запросах, минимизируя количество ненужных операций с индексами.
Для поиска следует выбирать тип индекса в зависимости от характера запросов. Для часто выполняемых точных поисков (например, по равенству) лучше использовать кластеризованные индексы. Для более сложных операций, таких как поиск по диапазону значений, подходят некластеризованные индексы. Также полезно использовать покрытия индексов, когда индекс включает все необходимые столбцы для выполнения запроса, что позволяет избежать доступа к основной таблице.
Неправильная индексация может привести к деградации производительности. Поэтому регулярный мониторинг и анализ индексов с использованием инструментов, таких как SQL Server Management Studio (SSMS), помогает выявить неэффективные индексы и их избыточное использование.
Создание и управление хранимыми процедурами и функциями
Создание хранимой процедуры
Для создания хранимой процедуры используется команда CREATE PROCEDURE. Она может содержать параметры, которые позволяют передавать значения в процедуру при её вызове. Пример создания процедуры, которая выбирает пользователей из таблицы по возрасту:
CREATE PROCEDURE GetUsersByAge
@Age INT
AS
BEGIN
SELECT Name, Age
FROM Users
WHERE Age = @Age;
END;В этом примере процедура принимает параметр @Age, который используется в SQL-запросе. Для вызова процедуры применяется команда EXEC:
EXEC GetUsersByAge @Age = 25;Создание функции
Функции в SQL Server могут быть скалярными (возвращают одно значение) или табличными (возвращают таблицу). Для создания функции используется команда CREATE FUNCTION. Пример создания функции, которая возвращает возраст пользователя по его имени:
CREATE FUNCTION GetUserAge (@Name NVARCHAR(100))
RETURNS INT
AS
BEGIN
DECLARE @Age INT;
SELECT @Age = Age FROM Users WHERE Name = @Name;
RETURN @Age;
END;В этом примере функция принимает параметр @Name, выполняет запрос к таблице и возвращает значение возраста. Вызов функции осуществляется в запросе:
SELECT dbo.GetUserAge('John');Управление хранимыми процедурами и функциями
После создания хранимых процедур и функций важно уметь ими управлять. Для удаления объектов используется команда DROP. Например, для удаления процедуры или функции:
DROP PROCEDURE GetUsersByAge;DROP FUNCTION GetUserAge;Если требуется изменить существующую процедуру или функцию, используется команда ALTER. Однако, при изменении процедур и функций важно помнить, что SQL Server не поддерживает изменение их структуры без удаления и создания заново, если это связано с изменением параметров или возвращаемого типа.
Оптимизация и отладка
Для повышения производительности хранимых процедур и функций стоит учитывать несколько моментов. Используйте индексы для ускорения выполнения запросов внутри процедуры. Следует избегать сложных операций внутри циклов и ограничить использование курсоров, так как они могут значительно замедлить выполнение. Также полезно включать проверку ошибок с помощью конструкции TRY...CATCH, чтобы обеспечить корректную обработку исключений.
Важные рекомендации:
- Используйте параметризацию запросов для предотвращения SQL-инъекций.
- Регулярно пересматривайте и оптимизируйте хранимые процедуры для улучшения производительности.
- Помните о безопасности: ограничивайте доступ к процедурам и функциям с помощью ролей и прав пользователей.
- Используйте схемы для группировки связанных объектов и улучшения читаемости.
Работа с транзакциями и обеспечением целостности данных
Каждая транзакция в SQL может состоять из нескольких операций, таких как вставка, обновление или удаление данных. Основная цель транзакции – поддержание консистентности данных, особенно в условиях многозадачности, где несколько пользователей могут одновременно работать с одной базой данных.
Чтобы использовать транзакции в MS SQL, необходимо выполнить несколько ключевых шагов:
- Начало транзакции: Для начала транзакции используется команда
BEGIN TRANSACTION. Она сигнализирует о начале блока операций, которые будут выполнены атомарно. - Коммит (подтверждение) транзакции: После успешного выполнения всех операций транзакции применяется команда
COMMIT. Она сохраняет изменения в базе данных. - Откат транзакции: Если в процессе выполнения транзакции произошла ошибка, используется команда
ROLLBACK, которая отменяет все изменения, сделанные в рамках транзакции, возвращая данные в исходное состояние.
Для эффективного использования транзакций важно соблюдать несколько рекомендаций:
- Минимизация продолжительности транзакции: Транзакции не должны длиться слишком долго, чтобы избежать блокировки ресурсов и ухудшения производительности базы данных.
- Изоляция транзакций: SQL Server поддерживает различные уровни изоляции транзакций, такие как
READ COMMITTED,REPEATABLE READ,SERIALIZABLEи другие. Выбор уровня изоляции зависит от требований к конкурентному доступу и целостности данных. - Управление блокировками: При работе с транзакциями важно контролировать блокировки, чтобы избежать ситуаций дедлока (deadlock). Это можно достичь с помощью правильного порядка выполнения операций и настройки таймаутов.
Целостность данных в базе данных обеспечивается с помощью механизмов, таких как ссылочная целостность, проверки ограничений и триггеров.
- Ссылочная целостность: Она обеспечивается через внешние ключи, которые связывают записи в разных таблицах. При удалении или обновлении данных в родительской таблице сервер базы данных проверяет, не нарушается ли ссылочная целостность. Для этого используется каскадное обновление или удаление (ON DELETE CASCADE).
- Ограничения: В MS SQL можно использовать ограничения для обеспечения целостности данных, такие как
CHECK,DEFAULT,NOT NULLи другие. Эти ограничения позволяют автоматически контролировать правильность и полноту данных при их вставке или обновлении. - Триггеры: Триггеры – это специальные процедуры, которые автоматически выполняются при изменении данных в таблицах. Они могут использоваться для реализации дополнительной логики проверки целостности данных, например, для проверки значений перед вставкой.
Для контроля целостности данных также важно следить за миграциями данных, чтобы изменения в структуре таблиц не привели к потере данных или нарушению логики работы приложения. Инструменты, такие как SQL Server Management Studio (SSMS), позволяют отслеживать изменения и корректировать их в реальном времени.
Вопрос-ответ:
Как начать работать с MS SQL для новичков?
Для того чтобы начать работать с MS SQL, сначала нужно установить SQL Server. Это можно сделать, скачав бесплатную версию SQL Server Express с официального сайта Microsoft. После установки, можно использовать SQL Server Management Studio (SSMS), который предоставляет удобный интерфейс для работы с базой данных. Начать стоит с изучения основ работы с запросами SQL, таких как SELECT, INSERT, UPDATE и DELETE. Также полезно изучить создание таблиц, индексов и использование простых функций.
Как научиться писать сложные запросы в MS SQL?
Для создания сложных запросов в MS SQL нужно понимать основы работы с несколькими таблицами, агрегатными функциями и подзапросами. Изучите оператор JOIN, который позволяет объединять данные из разных таблиц, а также GROUP BY для группировки данных и агрегатные функции (например, COUNT, SUM, AVG). Также стоит освоить работу с подзапросами и оконными функциями для выполнения более продвинутых операций. Постоянно практикуясь и решая реальные задачи, можно развить навыки написания сложных запросов.
Какие инструменты можно использовать для работы с MS SQL, кроме SQL Server Management Studio?
Помимо SQL Server Management Studio (SSMS), есть несколько других инструментов для работы с MS SQL. Например, Azure Data Studio — это бесплатное приложение от Microsoft, которое подходит как для локальных, так и для облачных баз данных. Также можно использовать сторонние программы, такие как DBeaver и HeidiSQL, которые поддерживают работу с различными СУБД, в том числе и с MS SQL. Для разработчиков, которые работают с .NET, можно использовать Visual Studio, интегрируя SQL Server прямо в среду разработки.
Какие советы могут помочь при работе с большими объемами данных в MS SQL?
При работе с большими объемами данных важно учитывать несколько аспектов. Во-первых, необходимо правильно индексировать таблицы для ускорения поиска данных. Используйте индексы по часто используемым полям и избегайте чрезмерного количества индексов, чтобы не замедлять операции записи. Во-вторых, можно использовать партиционирование таблиц для разделения данных на более мелкие части. Это помогает эффективно управлять данными и ускоряет обработку запросов. Также стоит обращать внимание на использование правильных типов данных, чтобы минимизировать затраты памяти и ускорить работу с данными.
Как настроить резервное копирование базы данных в MS SQL?
Для настройки резервного копирования базы данных в MS SQL нужно использовать функционал, который предоставляет SQL Server Management Studio. В SSMS необходимо выбрать базу данных, щелкнуть правой кнопкой мыши и выбрать «Задачи» -> «Резервное копирование». В открывшемся окне можно выбрать тип резервного копирования (полное, дифференциальное, журнал транзакций) и указать место для хранения резервной копии. Для автоматизации процесса резервного копирования можно настроить задания в SQL Server Agent, чтобы они выполнялись по расписанию, например, ежедневно или еженедельно.
Как начать работать с MS SQL для новичка?
Если вы только начинаете работать с MS SQL, первым шагом будет установка SQL Server и SQL Server Management Studio (SSMS), которые позволят вам управлять базами данных и выполнять SQL-запросы. После установки важно освоить основные операции, такие как создание таблиц, вставка данных, выполнение запросов SELECT, а также изучить базовые операции с данными, например, UPDATE и DELETE. Вы также должны понять, что такое индексы и как они влияют на производительность запросов. Важно постепенно изучать синтаксис SQL и практиковаться, чтобы стать уверенным в работе с базами данных.
Как улучшить производительность SQL-запросов в MS SQL Server?
Для улучшения производительности запросов в MS SQL Server существует несколько методов. Во-первых, следует анализировать выполнение запросов с помощью инструментов, таких как SQL Server Profiler или Execution Plan, чтобы понять, какие части запроса занимают больше времени. Часто причиной медленной работы могут быть неоптимизированные индексы или отсутствие индексов на колонках, по которым выполняются фильтрации или сортировки. Также важно следить за правильностью написания запросов, избегая ненужных подзапросов и функций, которые могут замедлять выполнение. Периодическое обновление статистики и индексов также помогает поддерживать высокую производительность. Помимо этого, можно использовать запросы с ограничениями на выборку (например, через TOP или WHERE) и разбиение больших таблиц на более мелкие.