Анализ плана выполнения SQL-запроса – ключевой инструмент для выявления узких мест в производительности базы данных. Вместо того чтобы полагаться на предположения, план показывает, какие индексы используются, сколько строк просматривается, какие операции являются наиболее ресурсоёмкими. Это позволяет не просто «улучшать запрос», а точно понимать, *что именно* требует оптимизации.
В SQL Server используется команда SET SHOWPLAN_ALL ON или графическое представление плана выполнения в SSMS. В Oracle – оператор EXPLAIN PLAN FOR с последующим запросом к PLAN_TABLE. Для всех систем ключевым является понимание, как интерпретировать доступ к индексам, соединения (Nested Loop, Hash Join) и фильтрацию строк.
Без регулярного просмотра плана выполнения невозможно обеспечить стабильную производительность при росте объёма данных. Используйте анализ плана как часть CI/CD-процессов: автоматическое сравнение планов помогает выявить деградацию до появления жалоб от пользователей.
Как использовать EXPLAIN в MySQL для анализа SELECT-запроса
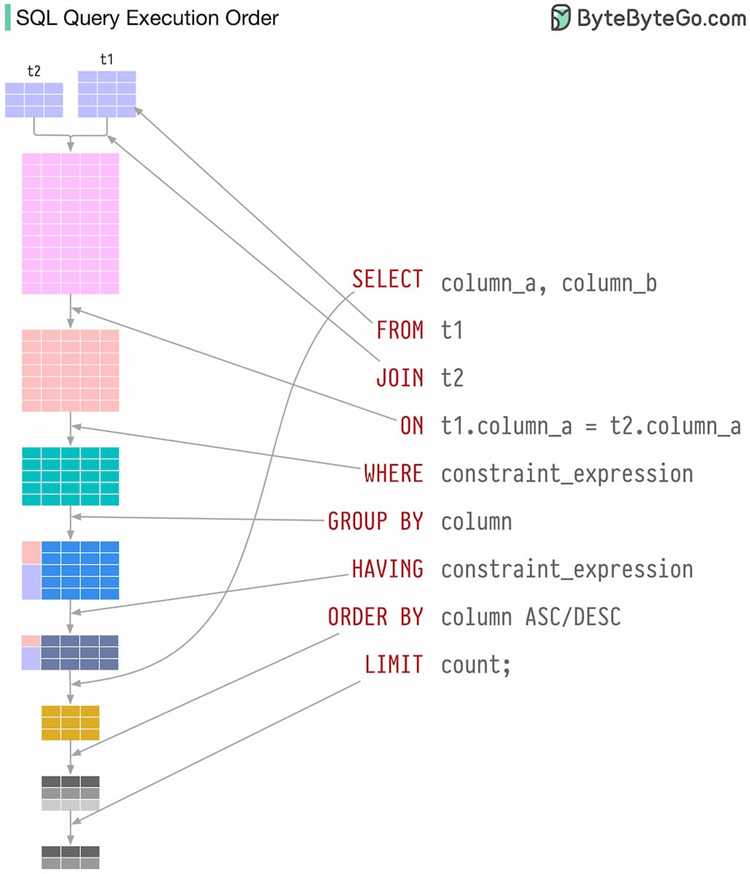
Команда EXPLAIN в MySQL позволяет точно определить, как движок базы данных будет обрабатывать SELECT-запрос. Это ключевой инструмент для выявления узких мест в производительности.
- Используйте
EXPLAIN SELECT ...перед интересующим запросом. Это вернет строку или набор строк, каждая из которых описывает одну из операций, выполняемых в процессе выборки. - Особое внимание обращайте на колонку
type– она указывает тип соединения. Идеальные значения:const,eq_ref,ref. Если видитеALL– это признак полного сканирования таблицы. - Колонка
keyпокажет, какой индекс был использован. Если значениеNULL, индекс не используется, что часто указывает на неэффективный запрос. - Поле
rowsотображает количество строк, которые MySQL предполагает прочитать. Чем меньше это значение – тем лучше. - Анализируйте
Extra. Полезные индикаторы:Using index– хороший знак;Using temporaryиUsing filesort– повод для оптимизации, особенно при больших объемах данных.
Для анализа сложных запросов используйте EXPLAIN FORMAT=JSON. Этот режим дает больше деталей: информацию об условиях фильтрации, индексах, выбранных стратегиях соединения.
Регулярно используйте EXPLAIN при изменении структуры таблиц, добавлении индексов или рефакторинге запросов. Это позволяет заранее оценить влияние изменений на производительность.
Применение команды EXPLAIN ANALYZE в PostgreSQL
Каждый шаг плана содержит информацию о времени старта, продолжительности, количестве строк, которые реально были обработаны, а также о том, сколько строк ожидалось на этапе планирования. При значительных расхождениях между ожидаемыми и фактическими значениями стоит проверить корректность статистики таблиц с помощью ANALYZE или VACUUM ANALYZE.
Пример использования: EXPLAIN ANALYZE SELECT * FROM users WHERE age > 30;. В результате будет видно, использует ли запрос индекс или выполняет последовательное сканирование. Если используется Seq Scan при наличии подходящего индекса, необходимо проверить, почему планировщик не выбрал индекс: например, из-за устаревшей статистики или слишком малого числа подходящих строк.
Особое внимание стоит уделять полям Actual Total Time и Rows Removed by Filter. Высокие значения времени при небольшом объёме данных – сигнал к оптимизации. Удаление большого количества строк фильтрами может указывать на неэффективные условия WHERE.
Для анализа сложных запросов полезно добавлять BUFFERS: EXPLAIN (ANALYZE, BUFFERS). Это позволит понять, где происходят обращения к диску, и выделить узкие места, связанные с I/O.
Изучая EXPLAIN ANALYZE, всегда сравнивайте ожидаемые и фактические значения, ищите дорогостоящие операции и ненужные полные сканирования. Только через точные метрики можно выявить, какие части запроса требуют переписывания или добавления индексов.
Получение плана выполнения через SQL Server Management Studio
Чтобы получить план выполнения запроса в SQL Server Management Studio (SSMS), откройте новое окно запроса и введите интересующий SQL-код. Перед выполнением нажмите кнопку «Включить отображение плана выполнения» (пиктограмма с графом, либо сочетание клавиш Ctrl+M). Это обеспечит генерацию *Estimated Execution Plan* и *Actual Execution Plan* в зависимости от метода запуска.
Для анализа именно фактического плана выполнения (Actual Execution Plan), выполните запрос обычным способом (F5 или кнопка «Execute»). По завершении выполнения внизу окна откроется дополнительная вкладка «Execution Plan», содержащая подробности обработки запроса.
Каждый оператор на плане визуально представлен в виде узла с описанием затрат. Чтобы узнать, какой шаг занимает наибольшее время, ориентируйтесь на параметр Estimated Subtree Cost. Щелкнув по любому элементу плана, откройте его свойства в правой панели. Здесь отображаются:
- Actual Number of Rows – фактическое количество строк, прошедших через узел;
- Estimated Number of Rows – предполагаемое количество строк;
- Actual Execution Mode и Estimated Execution Mode – строчный или пакетный режим;
- Warnings – сообщения об операциях, вызвавших проблемы (например, Missing Index или Hash Warning);
- Logical Operation – тип логической операции (например, Index Seek, Nested Loops, Hash Match).
При наличии рекомендаций по индексам они отображаются в верхней части плана. Используйте их только после анализа возможного влияния на другие запросы. Чтобы сравнить оценку с фактом, смотрите расхождения между Estimated и Actual Row Count. Значительное отличие сигнализирует о неактуальной статистике или неэффективной выборке.
Для получения плана выполнения без фактического запуска запроса используйте кнопку «Показать оценочный план выполнения» (Ctrl+L). Это полезно для анализа потенциальных последствий тяжёлых запросов без риска их выполнения.
Не игнорируйте параметры Parallelism и Waits, особенно при анализе долгих операций. Символ двух стрелок на плане означает параллельное выполнение, что может указывать на перегрузку ресурсов или необходимость перераспределения нагрузки.
Использование AUTOTRACE в Oracle для изучения плана запроса
Команда AUTOTRACE в Oracle предоставляет удобный способ анализа выполнения SQL-запросов. Она используется для получения информации о плане выполнения запроса, статистике его исполнения и количестве затраченных ресурсов. AUTOTRACE полезен для диагностики проблем производительности и оптимизации запросов. Он может быть активирован в SQL*Plus или SQLcl, обеспечивая подробные данные о том, как Oracle выполняет запрос.
Чтобы включить AUTOTRACE, используйте команду:
SET AUTOTRACE ON
После выполнения запроса с активированным AUTOTRACE, Oracle покажет план выполнения запроса и статистику. Эта информация включает в себя время, потраченное на выполнение, количество строк, обработанных каждым оператором, и другие важные метрики. Например, план может содержать информацию о том, использовались ли индексы, сканировались ли таблицы, или был выполнен сортировочный процесс.
SET AUTOTRACE OFF
- SET AUTOTRACE ON EXPLAIN – только план запроса без статистики выполнения.
- SET AUTOTRACE ON STATISTICS – только статистика выполнения запроса.
Для использования AUTOTRACE необходимы соответствующие привилегии. Пользователь должен иметь доступ к представлению V_$SQL_PLAN для получения плана выполнения и V_$SESSION для получения статистики. Важно учитывать, что AUTOTRACE не всегда будет предоставлять полную картину для сложных запросов, особенно если они выполняются в распределенных системах или используют параллельное выполнение.
Для более точного анализа и настройки индексов рекомендуется использовать AUTOTRACE в сочетании с другими инструментами Oracle, такими как SQL_TRACE и TKPROF, что позволит выявить узкие места в запросах и ускорить их выполнение.
Первое, на что стоит обратить внимание – это шаги, где используется «Table Scan» или «Full Table Scan». Если запросу приходится сканировать всю таблицу, вместо того чтобы воспользоваться индексом, это сигнал о возможной проблеме с индексами. Причиной может быть отсутствие подходящего индекса, устаревший статистики или неправильный выбор индекса оптимизатором.
Также важно проверять типы операций, таких как «Index Scan» или «Index Seek». Если план выполнения показывает, что вместо использования индексного поиска происходит полный индексный скан, это может свидетельствовать о неэффективности индекса. В случае, если индекс используется для «Range Scan» (поиск по диапазону), убедитесь, что индекс охватывает все необходимые колонки для фильтрации, иначе запрос будет работать медленно.
Посмотрите на числовые показатели в плане, такие как «Rows», «Loops», «Cost» и «I/O». Эти метрики могут указать, насколько эффективно используется индекс. Если значение «Rows» значительно отличается от того, что ожидалось по индексу, возможно, индекс плохо подобран или перегружен избыточными данными.
Обратите внимание на шаги с операциями «Nested Loop» и «Merge Join». Если запрос использует «Nested Loop» в сочетании с полным сканированием таблицы или неэффективным индексом, это может сильно снизить производительность, особенно при больших объемах данных. В таких случаях стоит попробовать изменить индекс или структуру запроса.
Еще один момент – это статистики индексов. Если оптимизатор использует неправильный индекс, возможно, статистика устарела. Обновите статистику таблиц и индексов для более точных оценок производительности и правильного выбора индекса.
Включение индекса на поле, которое редко фильтруется, может привести к его неэффективному использованию. Если план выполнения показывает, что индекс используется, но «Cost» операции слишком высок, проверьте, является ли индекс подходящим для данного запроса. Иногда стоит пересмотреть выбор колонок для индексации, чтобы уменьшить стоимость операций.
Наконец, обратите внимание на «Index Fragmentation». Высокая фрагментация индекса может замедлить его работу. Если индекс сильно фрагментирован, выполните его реорганизацию или перестроение. Это особенно важно для индексов, которые часто обновляются.
Как интерпретировать значения стоимости (cost) в PostgreSQL
В PostgreSQL план выполнения запроса сопровождается оценкой стоимости каждого шага. Стоимость измеряется в абстрактных единицах и состоит из двух чисел: стартовой стоимости (startup cost) и общей стоимости (total cost). Оба значения полезны для понимания, как система планирует выполнить запрос и сколько ресурсов потребуется на разных этапах.
Стартовая стоимость (startup cost) отражает количество работы, необходимое для начала выполнения операции, включая время на подготовку данных, создание индексов и другие предварительные шаги. Это значение позволяет понять, насколько быстро будет осуществляться переход к основным операциям. Стартовая стоимость не зависит от количества строк в таблице, а скорее от сложности самой операции, например, от необходимости сортировки или чтения индекса.
Общая стоимость (total cost) включает в себя все этапы выполнения операции – от подготовки до получения результатов. Она складывается из стартовой стоимости и стоимости обработки данных. Эта цифра помогает оценить, какой объём работы предстоит системе для завершения запроса. Важно отметить, что общая стоимость тесно связана с количеством обрабатываемых строк и может значительно изменяться в зависимости от использования индексов или сложности join-операций.
Пример интерпретации: если в плане выполнения запроса указана стартовая стоимость 0.5 и общая стоимость 10.0, это означает, что для начала операции потребуется 0.5 единиц ресурса, а полное выполнение запроса потребует 10.0 единиц ресурса. Разница между этими значениями помогает оценить, сколько времени будет затрачено на обработку данных после старта.
При сравнении различных планов выполнения запросов важно учитывать не только абсолютные значения стоимости, но и их соотношение между различными операциями. Например, если одна операция имеет значительно более высокую стартовую стоимость по сравнению с другой, это может свидетельствовать о необходимости дополнительных затрат на предварительные вычисления или индексацию, что потенциально увеличит время выполнения запроса.
Чтобы эффективно использовать стоимость для оптимизации запросов, следует внимательно анализировать «стоимость» в контексте выбора алгоритма и структуры данных, используемой для обработки. Например, если запрос выполняется медленно, высокая стартовая стоимость может указывать на неэффективное использование индекса или необходимость перераспределения работы между операциями.
Таким образом, интерпретация стоимости выполнения запроса в PostgreSQL помогает понять, какие этапы требуют больше всего ресурсов и как можно оптимизировать запрос, выбирая более быстрые методы выполнения или изменяя структуру данных.
Получение графического плана выполнения в SQL Server
Графический план выполнения запроса в SQL Server позволяет визуализировать, как СУБД обрабатывает SQL-запрос. Это полезный инструмент для оптимизации и выявления узких мест. Чтобы получить графический план, выполните несколько шагов.
- Использование опции «Include Actual Execution Plan»
При выполнении запроса в SQL Server Management Studio (SSMS), активируйте опцию для отображения реального плана выполнения. Для этого перед запуском запроса нажмите на кнопку «Include Actual Execution Plan» в панели инструментов или используйте сочетание клавишCtrl + M. После выполнения запроса план будет доступен на вкладке «Execution Plan». - Пример запроса
Чтобы увидеть графический план, выполните простой запрос после активации соответствующей опции:
SELECT * FROM Employees WHERE DepartmentID = 5;
После выполнения вы увидите графическое представление, где каждый шаг (например, сканирование таблицы, индексирование) будет отображен отдельным узлом.
- Анализ графического плана
В графическом плане каждый узел представляет собой операцию. Например:
- Clustered Index Scan – сканирование таблицы с использованием кластеризованного индекса.
- Index Seek – поиск данных с использованием индекса.
- Table Scan – полное сканирование таблицы без использования индекса.
Размер узлов и стрелки, соединяющие их, дают информацию о затратах на выполнение каждой операции и их взаимосвязи.
- Использование «Estimated Execution Plan»
В случае необходимости можно получить предполагаемый план выполнения без фактического исполнения запроса. Для этого нажмите на кнопку «Display Estimated Execution Plan» или используйте сочетание клавишCtrl + L. Это покажет, как SQL Server планирует выполнить запрос, не запуская его. - Оптимизация на основе плана выполнения
Изучая графический план, обратите внимание на следующие моменты:
- Высокие затраты на операции, такие как Table Scan, могут указывать на отсутствие нужных индексов.
- Если план включает Sort, это может свидетельствовать о высоких затратах на сортировку данных, и стоит рассмотреть возможности улучшения запроса.
- Наличие операций Nested Loops может указывать на неэффективные соединения таблиц.
На основе этого можно принимать решения об оптимизации: создание индексов, изменение структуры запроса или добавление ограничений.
Графический план выполнения запроса – мощный инструмент, который помогает не только анализировать текущие запросы, но и принимать меры для их оптимизации. Внимательно изучая такие планы, можно значительно улучшить производительность запросов в SQL Server.
Сравнение реального и предполагаемого плана выполнения в PostgreSQL
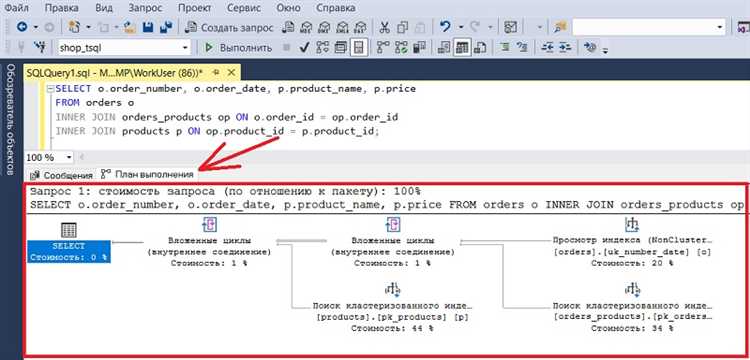
В PostgreSQL можно анализировать два типа планов выполнения запроса: предполагаемый (EXPLAIN) и реальный (EXPLAIN ANALYZE). Предполагаемый план выполняется на основе статистики и данных о структуре базы, в то время как реальный план отображает фактическое поведение запроса в процессе его исполнения. Различия между ними могут помочь выявить проблемы с производительностью и понять, почему запрос выполняется медленно.
Предполагаемый план (EXPLAIN) строится без выполнения запроса. Он ориентирован на статистику, которая может быть устаревшей или неполной. В нем PostgreSQL указывает предполагаемое время выполнения и ресурсы, которые потребуются для выполнения запроса. Однако, предполагаемые данные могут отличаться от реальных, если статистика устарела или не охватывает всех возможных путей выполнения.
Реальный план (EXPLAIN ANALYZE) включает фактическое время выполнения, количество обработанных строк и другие метрики, собранные в процессе выполнения запроса. Этот план позволяет увидеть, как фактически PostgreSQL выполняет запрос, с учетом текущей нагрузки и состояния системы. Особенно полезен EXPLAIN ANALYZE при поиске узких мест и ошибок в индексации, а также для диагностики неоптимальных путей выполнения.
Основные различия между реальным и предполагаемым планом:
1. Время выполнения: предполагаемый план может не учитывать реальные задержки, связанные с блокировками, кэшированием или актуальным состоянием сервера.
2. Выборка строк: предполагаемый план может ошибаться в оценке количества строк на каждом этапе запроса. Например, если статистика обновлена не вовремя, PostgreSQL может неправильно оценить количество строк, что приведет к неэффективному выбору плана.
3. Кэширование: EXPLAIN не учитывает данные, которые могут быть закэшированы в памяти, в то время как EXPLAIN ANALYZE показывает реальное время чтения данных, включая кэширование и обращения к диску.
Для анализа разницы между планами рекомендуется:
— Внимательно изучать метрики реального плана, такие как «actual time» и «loops», чтобы понять, какие части запроса занимают больше всего времени.
— Если предполагаемый план сильно отличается от реального, стоит обновить статистику с помощью команды ANALYZE для корректировки планов.
— Использовать реальные планы для проверки гипотез о производительности и для точного выявления узких мест в запросах.
Важно помнить, что разница между реальным и предполагаемым планом не всегда указывает на ошибку. Однако, если запрос работает значительно медленнее, чем ожидается по предполагаемому плану, это повод для детального анализа.
Вопрос-ответ:
Как можно увидеть план выполнения SQL запроса?
Чтобы увидеть план выполнения SQL запроса, можно использовать команду EXPLAIN в большинстве СУБД (например, в PostgreSQL, MySQL, Oracle и других). Эта команда показывает, как база данных будет обрабатывать запрос, какие индексы будут использоваться, сколько ресурсов потребуется для выполнения и так далее. Например, в MySQL достаточно перед запросом написать EXPLAIN SELECT …; и система покажет, как будет выполнен данный запрос. В других системах также есть аналогичные команды или опции.
Что такое «план выполнения» SQL запроса?
План выполнения SQL запроса — это последовательность шагов, которые СУБД собирается выполнить для обработки запроса. Он включает в себя информацию о том, какие индексы будут использованы, в каком порядке будут сканироваться таблицы, какие алгоритмы сортировки и фильтрации будут применяться, а также оценку затрат (время, память). План выполнения помогает понять, насколько эффективно будет работать запрос и какие возможные улучшения могут быть внесены в структуру запроса или базы данных.
Как интерпретировать результат команды EXPLAIN?
Результат команды EXPLAIN может включать несколько столбцов, таких как «id», «select_type», «table», «type», «possible_keys», «key», «rows» и другие. Например, столбец «type» показывает, какой тип соединения будет использован между таблицами (например, «ALL» — полный скан таблицы, «index» — использование индекса). Столбец «rows» показывает, сколько строк система оценивает для обработки на данном этапе. Чем меньше количество строк, тем быстрее будет выполняться запрос. Чтобы эффективно интерпретировать результат, нужно знать, какие значения оптимальны для конкретной СУБД и типа запроса.
Есть ли разница в планах выполнения запросов в разных СУБД?
Да, планы выполнения могут сильно различаться в разных СУБД, поскольку каждая система использует свои алгоритмы для обработки запросов. Например, в MySQL и PostgreSQL используются разные подходы для выбора индексов, обработки соединений между таблицами и оптимизации запросов. Также каждый движок может по-разному оценивать стоимость выполнения операций и влиять на выбор того или иного плана. Поэтому для каждой СУБД существует своя специфика интерпретации и использования команд EXPLAIN или их аналогов.
Можно ли изменить план выполнения запроса вручную?
Да, в некоторых случаях можно воздействовать на план выполнения запроса. Это можно сделать с помощью добавления или изменения индексов, переписывания самого запроса, использования подсказок для оптимизатора запросов (например, с помощью директив типа «FORCE INDEX» в MySQL), а также через настройку параметров СУБД, таких как размеры буферов или кэширования. Однако важно понимать, что вмешательство в план выполнения запроса должно быть осмотрительным, так как неправильные изменения могут привести к ухудшению производительности.
Как можно посмотреть план выполнения SQL запроса?
Для того чтобы просмотреть план выполнения SQL запроса, нужно использовать команду, которая зависит от используемой системы управления базами данных (СУБД). Например, в MySQL это команда `EXPLAIN`, которая показывает, как запрос будет выполняться, включая информацию о том, какие индексы будут использованы, сколько строк будет обрабатываться на каждом шаге, и прочие детали. В PostgreSQL аналогичная команда — `EXPLAIN ANALYZE`, которая не только генерирует план, но и выполняет запрос, показывая реальное время выполнения. В MS SQL Server используется команда `EXPLAIN` или `SET SHOWPLAN_ALL ON`, чтобы получить план выполнения. Для анализа плана можно обратить внимание на этапы запроса, такие как сканирование таблиц, использование индексов и сортировка данных, что поможет улучшить производительность запросов.