Для эффективной оптимизации работы с базами данных важно точно понимать, сколько времени занимает выполнение каждого SQL запроса. Без этого невозможно объективно оценить, какие запросы требуют улучшений, а какие могут быть оставлены без изменений. Время выполнения запроса – это не просто цифра, это индикатор общей производительности системы. Имея точные данные, можно правильно расставить приоритеты для оптимизации.
Для точного измерения времени выполнения можно использовать функцию NOW() или SYSDATE(), чтобы фиксировать время до и после выполнения запроса. Однако этот способ требует внимательности, так как время может быть немного искажено из-за внешних факторов, например, задержек в сети или работы других процессов на сервере.
Практическая рекомендация: если необходимо провести точный замер времени для нескольких запросов, лучше использовать профилировщик, встроенный в СУБД, такой как MySQL Performance Schema или PostgreSQL pg_stat_statements. Эти инструменты дают более полную картину, позволяя отслеживать время выполнения запроса в реальном времени, а также сохранять статистику для последующего анализа.
Использование команды EXPLAIN для анализа времени выполнения
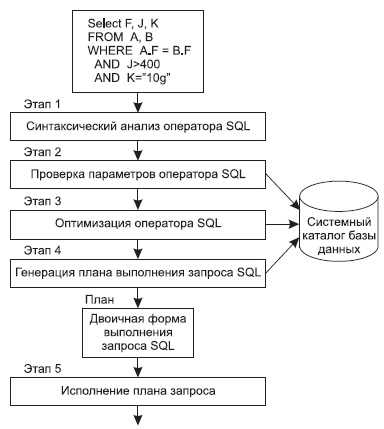
Команда EXPLAIN предоставляет подробную информацию о том, как СУБД выполняет SQL-запрос. Используя этот инструмент, можно выявить узкие места в запросах и понять, какие операции занимают больше всего времени.
- id – уникальный идентификатор запроса в плане выполнения. Помогает понять порядок операций.
- select_type – тип запроса (например, SIMPLE, PRIMARY, SUBQUERY). Это помогает выделить важные моменты в структуре запроса.
- table – имя таблицы, к которой осуществляется обращение.
- type – метод соединения таблиц, который может быть одним из следующих: ALL, index, range, ref, eq_ref и другие. Этот параметр показывает эффективность соединения таблиц.
- possible_keys – список индексов, которые могут быть использованы для оптимизации запроса.
- key – фактически используемый индекс, если он был выбран.
- rows – количество строк, которое необходимо обработать для выполнения запроса.
- Extra – дополнительная информация, например, о том, применяется ли фильтрация на уровне серверов или если необходимо выполнить полный обход данных.
Для анализа времени выполнения запроса можно использовать следующий подход:
- Запустите EXPLAIN перед основным запросом, чтобы получить план выполнения. Это поможет понять, какие операции могут быть оптимизированы.
- Обратите внимание на поле type. Если оно указывает на FULL SCAN (ALL), это может свидетельствовать о низкой производительности запроса.
- Если EXPLAIN показывает использование неподходящего индекса или его отсутствие, подумайте о добавлении индексов или изменении запроса для лучшей производительности.
- Используйте EXPLAIN ANALYZE в СУБД, поддерживающих этот режим, для более детализированного анализа времени выполнения запроса с реальными данными. Это поможет точно понять, сколько времени тратится на каждую операцию в запросе.
Время выполнения запроса с помощью SQL-функции NOW()
Функция NOW() в SQL используется для получения текущего времени и даты на момент выполнения запроса. Она возвращает значение в формате «YYYY-MM-DD HH:MM:SS». Эта функция может быть полезной для измерения времени выполнения запросов в некоторых случаях. Однако важно понимать, что сама по себе NOW() не предоставляет информации о времени выполнения запроса. Чтобы измерить продолжительность выполнения запроса, необходимо комбинировать NOW() с другими методами.
Для измерения времени выполнения запроса можно использовать NOW() в качестве метки времени до и после выполнения SQL-запроса. Один из подходов – это использование временных переменных или временных столбцов. Пример запроса для измерения времени выполнения может выглядеть следующим образом:
SELECT NOW() AS start_time; -- Ваш SQL запрос SELECT NOW() AS end_time;
Затем, для расчета разницы во времени, можно выполнить вычисления между временем начала и окончания. Однако этот способ требует дополнительных шагов и не является самым точным для измерения работы сложных или долгих запросов, так как может возникать погрешность из-за операций, происходящих между запросами.
Для более точных измерений в рамках одной транзакции или выполнения запроса лучше использовать встроенные механизмы, такие как EXPLAIN или профилировщики баз данных, которые обеспечат больше информации о времени выполнения запроса с деталями. Но если задача состоит исключительно в фиксировании времени начала и конца, NOW() будет хорошим выбором для простых случаев.
Измерение времени с использованием SQL-утилит командной строки
Для эффективного измерения времени выполнения SQL-запросов через командную строку можно использовать встроенные возможности утилит, таких как psql для PostgreSQL, mysql для MySQL или sqlcmd для SQL Server. Эти утилиты предлагают простые способы для получения данных о времени выполнения запроса.
Основные подходы для измерения времени:
- psql (PostgreSQL): В PostgreSQL утилита
psqlподдерживает параметр\timing, который позволяет отслеживать время выполнения запроса.
psql -U username -d database
\timing
SELECT * FROM large_table;
После активации параметра \timing, каждый запрос, выполненный в сессии psql, будет отображать время его выполнения в миллисекундах.
mysql -u username -p database --timer
SELECT * FROM large_table;
Для временных замеров можно использовать функцию BENCHMARK() в MySQL, которая выполняет заданный запрос определённое количество раз и возвращает время выполнения.
sqlcmd -S server -U username -P password -d database -Q "SELECT * FROM large_table" -o result.txt
Кроме того, можно использовать системные представления и функции SQL Server, такие как GETDATE(), для ручного измерения времени между началом и окончанием выполнения запроса.
- Использование встроенных SQL-функций: В большинстве СУБД можно использовать функции для получения времени выполнения запроса. Например, в MySQL и PostgreSQL можно использовать
EXPLAIN ANALYZEдля анализа времени выполнения запросов.
EXPLAIN ANALYZE SELECT * FROM large_table;
Эти инструменты позволяют точно измерять производительность запросов и оптимизировать их для повышения эффективности работы с базами данных.
Проверка времени работы запросов через инструменты мониторинга базы данных
Для эффективной диагностики производительности запросов базы данных и оптимизации их выполнения можно использовать различные инструменты мониторинга. Эти инструменты позволяют отслеживать время выполнения запросов в реальном времени и анализировать их поведение.
Одним из самых популярных инструментов для мониторинга является pg_stat_statements в PostgreSQL. Этот модуль собирает статистику по всем SQL-запросам, выполняемым на сервере, включая данные о времени выполнения, количестве вызовов и средних значениях. Для включения этого модуля необходимо добавить его в конфигурационный файл и перезагрузить сервер. После активации доступна информация о самых длительных запросах, что позволяет выявить узкие места в производительности.
В MySQL можно использовать Performance Schema. Этот инструмент предоставляет детализированную информацию о времени выполнения запросов, блокировках и других параметрах, влияющих на производительность. Для анализа работы запросов важно включить сбор данных о времени выполнения, установив соответствующие параметры конфигурации. С помощью SQL-запросов к таблицам Performance Schema можно получить точную информацию о задержках и времени выполнения отдельных запросов.
В Oracle для мониторинга запросов существует AWR (Automatic Workload Repository). Этот инструмент позволяет собирать и анализировать данные о производительности на уровне всей базы данных, включая время выполнения запросов. AWR собирает статистику, которая помогает не только идентифицировать медленные запросы, но и выявить проблемы с ресурсами, такие как CPU или I/O.
Для мониторинга в реальном времени также используются PrometheusGrafana для визуализации. Эти инструменты позволяют собирать метрики времени выполнения запросов, а также другие параметры, влияющие на производительность. Prometheus собирает метрики через различные экспортеры, а Grafana помогает строить интерактивные дашборды, отображающие данные в удобной для анализа форме.
Кроме того, можно использовать инструменты, такие как Datadog, которые позволяют мониторить не только время выполнения запросов, но и общее состояние системы. Datadog автоматически собирает метрики из всех слоев базы данных и предоставляет возможность глубокой аналитики через удобные отчеты и алерты. Это помогает оперативно выявлять запросы, которые требуют оптимизации.
Каждый инструмент имеет свои особенности, но все они помогают собрать точные данные о времени выполнения запросов и выявить потенциальные проблемы, которые влияют на производительность базы данных. Выбор инструмента зависит от конкретных требований и особенностей используемой СУБД.
Как использовать автохранимые процедуры для логирования времени выполнения
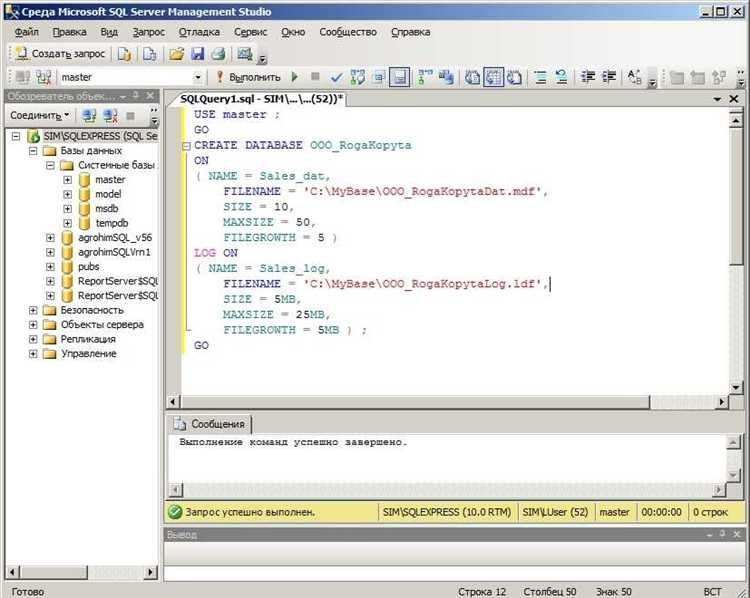
1. Создание процедуры для логирования
Первым шагом является создание процедуры, которая будет фиксировать время начала и окончания выполнения запроса. Для этого можно использовать стандартные функции SQL, такие как GETDATE() или SYSDATETIME() для получения текущего времени.
Пример автохранимой процедуры:
CREATE PROCEDURE LogQueryExecution
AS
BEGIN
DECLARE @StartTime DATETIME = SYSDATETIME();
-- Вставка записи в лог до выполнения запроса
INSERT INTO QueryLog (StartTime) VALUES (@StartTime);
-- Здесь выполняется SQL запрос, время которого нужно замерить
EXEC('YOUR_SQL_QUERY_HERE');
DECLARE @EndTime DATETIME = SYSDATETIME();
-- Обновление записи с временем завершения запроса
UPDATE QueryLog
SET EndTime = @EndTime, Duration = DATEDIFF(MILLISECOND, @StartTime, @EndTime)
WHERE StartTime = @StartTime;
END;
В данном примере создается лог, в котором сохраняются время начала, время окончания и продолжительность выполнения запроса в миллисекундах. Это позволит не только отслеживать производительность, но и анализировать задержки в работе базы данных.
2. Внедрение логирования в существующие запросы
Для использования процедуры нужно встраивать ее в SQL-запросы, которые необходимо мониторить. Например, можно обернуть каждый запрос в вызов процедуры:
EXEC LogQueryExecution;
Этот вызов автоматически запишет время начала и окончания выполнения запроса, а также вычислит длительность.
3. Оптимизация и хранение данных
Важно помнить, что логирование каждого запроса может значительно увеличить нагрузку на базу данных, особенно если запросов много. Рекомендуется регулярно очищать таблицу логов, например, через задачи по расписанию, чтобы не перегружать систему ненужными данными.
Можно настроить процедуру так, чтобы она сохраняла логи только для запросов, которые выполняются более определенного времени (например, более 100 мс). Это поможет избежать излишнего накопления данных.
4. Анализ результатов
Собранные данные можно анализировать с помощью SQL-запросов. Например, для нахождения самых медленных запросов можно использовать следующий запрос:
SELECT TOP 10 Query, Duration FROM QueryLog WHERE Duration > 100 ORDER BY Duration DESC;
Это поможет быстро выявить проблемные места и сосредоточиться на оптимизации наиболее ресурсоемких операций.
Анализ времени выполнения в графическом интерфейсе СУБД
Многие современные системы управления базами данных (СУБД) предоставляют графические интерфейсы для удобного анализа производительности запросов. Такие инструменты позволяют не только измерять время выполнения, но и визуализировать детали обработки запроса, что способствует более глубокому пониманию его эффективности.
В интерфейсах, таких как SQL Server Management Studio (SSMS), MySQL Workbench или pgAdmin, есть встроенные инструменты для анализа времени выполнения SQL-запросов. В большинстве случаев они предоставляют два основных типа данных: общее время выполнения запроса и время выполнения отдельных этапов его обработки, например, время парсинга, планирования и выполнения.
Для более точного анализа можно использовать графические инструменты, такие как «Execution Plan» (План выполнения), доступный в большинстве популярных СУБД. Этот инструмент отображает дерево операций, которые выполняются во время запроса, а также время, затраченное на каждую операцию. Например, в SQL Server можно увидеть, сколько времени затрачил каждый индекс или сортировка, что позволяет точно понять, где именно происходят узкие места в выполнении запроса.
Особое внимание следует уделить анализу «затратных» операций, таких как сортировка (Sort), объединения (Join) и фильтрация данных (Filter). Эти этапы часто становятся причиной значительных задержек. Применение индексов и правильная организация структуры данных могут существенно уменьшить время выполнения.
Важно также учитывать использование «Query Profiling» (Профилирование запросов), доступного в таких инструментах, как pgAdmin для PostgreSQL. Профилирование позволяет не только измерить время, но и увидеть, какие ресурсы использует запрос, включая процессорное время и объем данных, считываемых с диска.
Заключение: для эффективного анализа времени выполнения запросов в графическом интерфейсе СУБД необходимо не только измерять общее время, но и углубляться в детали выполнения каждого этапа запроса. Это позволяет точно выявить узкие места и оптимизировать запросы для повышения производительности.
Проблемы и ограничения при измерении времени выполнения SQL запросов
При измерении времени выполнения SQL запросов существует несколько факторов, которые могут повлиять на точность результатов. Эти ограничения важны для корректной интерпретации данных и выбора подходящей стратегии оптимизации запросов.
1. Влияние внешних факторов. Время выполнения запроса зависит от множества внешних факторов, таких как нагрузка на сервер, текущие процессы, сетевые задержки, а также конфигурация аппаратного обеспечения. Например, в условиях высокой нагрузки на сервер или работы с удаленной базой данных измерения могут значительно отклоняться от реальных значений, поскольку время отклика может увеличиваться из-за ограничений сети или ресурсов.
2. Кэширование данных. Многие СУБД используют кэширование результатов запросов. Повторное выполнение идентичных запросов в пределах одной сессии может показывать значительное снижение времени выполнения, так как данные уже загружены в память. Это может создать ложное впечатление, что запросы выполняются быстрее, чем на самом деле, если не учитывать состояние кэша.
3. Измерение на уровне клиента. Когда время выполнения измеряется с помощью клиентских инструментов, таких как библиотеки или приложения, важно учитывать задержки, связанные с сетевыми соединениями и обработкой на стороне клиента. Эти факторы могут существенно исказить реальное время выполнения запроса в СУБД.
4. Операции, зависящие от статистики. Статистика, используемая планировщиком запросов для выбора оптимального плана выполнения, может не всегда быть актуальной. Если статистика устарела или неполная, это может привести к выбору неэффективного плана, что в свою очередь влияет на время выполнения запроса.
5. Время выполнения зависит от размера данных. Время выполнения запросов может сильно варьироваться в зависимости от объема обрабатываемых данных. Например, запрос на выборку небольшого количества записей может выполняться значительно быстрее, чем запрос на обработку миллионов строк. Важно учитывать размер выборки и тип выполняемой операции при анализе времени выполнения.
6. Параллельное выполнение запросов. Многие современные СУБД поддерживают параллельное выполнение запросов. Это означает, что различные части запроса могут выполняться одновременно на нескольких ядрах процессора. Измерения времени выполнения могут быть искажены, если параллелизм не учитывается или если СУБД не использует его эффективно в зависимости от конфигурации.
7. Влияние индексов и их отсутствие. Наличие или отсутствие индексов может существенно изменять время выполнения запросов. Измерения без учета индексов могут привести к значительным погрешностям, так как без индексирования выполнение запроса потребует больше времени для поиска и сортировки данных.
При анализе времени выполнения SQL запросов необходимо учитывать эти ограничения и учитывать влияние внешних факторов, чтобы получить объективные результаты и оптимизировать запросы с учетом реальных условий работы системы.
Вопрос-ответ:
Как можно измерить время выполнения SQL запроса?
Время выполнения SQL запроса можно измерить с помощью инструментов профилирования запросов, которые предоставляет СУБД. Например, в MySQL можно использовать команду EXPLAIN, которая помогает увидеть план выполнения запроса и его время работы. В PostgreSQL для этого тоже есть команда EXPLAIN, а для более точных замеров можно использовать функцию pg_stat_statements, которая показывает статистику о выполнении запросов, включая их время. Также можно использовать команду SET STATISTICS TIME ON в PostgreSQL для включения измерений времени выполнения запросов.
Какие инструменты позволяют измерить время выполнения запросов в SQL Server?
В SQL Server для измерения времени выполнения запросов можно использовать различные способы. Один из самых популярных методов — это использование встроенной функции «SET STATISTICS TIME ON», которая позволяет выводить информацию о времени выполнения запросов в процессе их выполнения. Также можно использовать SQL Server Profiler, который позволяет мониторить производительность запросов в реальном времени и получать подробную информацию о времени, затраченном на их выполнение. Кроме того, для анализа производительности можно применить Dynamic Management Views (DMVs), например, sys.dm_exec_query_stats.
Как с помощью MySQL измерить время выполнения запроса?
В MySQL можно измерить время выполнения запроса с помощью команды EXPLAIN. Эта команда показывает план выполнения запроса и время его обработки. Также для замера времени можно воспользоваться командой «SHOW PROFILES», которая выводит информацию о времени выполнения запросов. Для этого необходимо включить профилирование запросов командой «SET profiling = 1». В результате можно будет увидеть детализированные данные о времени выполнения каждого запроса, включая время на его выполнение и другие параметры.
Почему время выполнения одного SQL запроса может значительно отличаться от времени выполнения другого запроса?
Разница во времени выполнения SQL запросов может быть связана с рядом факторов. Во-первых, это зависит от сложности самого запроса, а именно от количества обрабатываемых данных, количества операций соединений (JOIN), агрегаций и подзапросов. Во-вторых, время выполнения может изменяться в зависимости от состояния базы данных, например, наличия индексов, фрагментации данных или блокировок. Также большое значение имеет конфигурация СУБД, включая настройки кеширования, размера буферов и использования параллельных потоков обработки. Не последнюю роль играет и нагрузка на сервер, то есть другие процессы, которые могут конкурировать за ресурсы, влияя на время выполнения запросов.