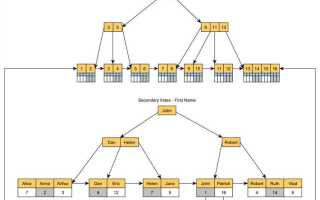
Кластеризованный индекс в MS SQL Server напрямую определяет физический порядок хранения данных в таблице. Его удаление – операция, требующая особого внимания, так как она может повлиять на производительность запросов, блокировки и стратегию хранения данных. В отличие от некластеризованных индексов, таблица с кластеризованным индексом фактически становится индексом – удаление означает реструктуризацию всей таблицы.
Перед удалением необходимо учитывать, что таблица без кластеризованного индекса становится хипом – структурой без упорядочивания строк. Это изменяет поведение сканирования и может повысить нагрузку на ресурсы при выполнении операций SELECT, особенно без дополнительных индексов. Также необходимо пересчитать план выполнения запросов и возможную необходимость создания вспомогательных некластеризованных индексов.
Удаление производится командой DROP INDEX с указанием имени индекса, либо через ALTER TABLE … DROP CONSTRAINT, если индекс был создан автоматически при определении первичного ключа. Важно убедиться, что зависимые объекты (например, foreign key-ограничения или представления с опцией WITH SCHEMABINDING) не блокируют удаление. В некоторых случаях потребуется временное удаление ограничений или пересоздание объектов.
Практика требует тестирования на копии производственной базы. Следует заранее оценить влияние на транзакции, использование временного пространства в tempdb, а также подготовить стратегию отката. В больших таблицах целесообразно использовать пошаговое выполнение с мониторингом блокировок и статистики IO.
Как определить наличие кластеризованного индекса на таблице

В Microsoft SQL Server наличие кластеризованного индекса на таблице можно определить с помощью системных представлений и функций. Один из самых точных способов – запрос к представлению sys.indexes.
Выполните следующий T-SQL-запрос, подставив имя интересующей таблицы и базы данных:
SELECT name, type_desc
FROM sys.indexes
WHERE object_id = OBJECT_ID('dbo.ИмяТаблицы') AND type = 1;
Если результат содержит строки, значит у таблицы есть кластеризованный индекс. Столбец type_desc будет иметь значение CLUSTERED.
Альтернативно используйте функцию INDEXPROPERTY для проверки конкретного индекса:
SELECT INDEXPROPERTY(OBJECT_ID('dbo.ИмяТаблицы'), 'ИмяИндекса', 'IsClustered') AS IsClustered;
Значение 1 означает, что индекс кластеризованный. Значение 0 – некластеризованный. NULL – индекс не найден.
Для получения всех индексов таблицы с указанием их типа используйте:
SELECT i.name, i.type_desc FROM sys.indexes i JOIN sys.objects o ON i.object_id = o.object_id WHERE o.name = 'ИмяТаблицы' AND o.type = 'U';
Убедитесь, что объект – пользовательская таблица (type = 'U'), иначе можно получить данные по представлениям и системным таблицам.
Что происходит с данными при удалении кластеризованного индекса
Удаление кластеризованного индекса в MS SQL Server приводит к полной перестройке физической структуры таблицы. Кластеризованный индекс определяет порядок хранения строк на диске. При его удалении SQL Server преобразует таблицу в хип – структуру без определённого порядка строк, что меняет способ доступа к данным.
Все строки таблицы физически перемещаются, поскольку теряется логическая структура сортировки. Это означает, что операции поиска по ключу, ранее ускоряемые кластеризованным индексом, начинают выполняться через полный просмотр таблицы, существенно снижая производительность при больших объёмах данных.
Удаление индекса инициирует перераспределение данных по новым страницам. Это сопровождается массовыми операциями записи и может вызвать значительные блокировки и рост нагрузки на диск. Временное пространство в tempdb также используется, особенно при наличии некластеризованных индексов, которые требуют обновления ссылок на строки.
Некластеризованные индексы, ссылавшиеся на удалённый кластеризованный ключ, автоматически модифицируются: их ссылочная структура меняется с ключа на RID (Row Identifier), указывающий на физическое местоположение строки. Это влияет на производительность, особенно при использовании операторов объединения и фильтрации.
Удаление кластеризованного индекса невозможно, если он поддерживает первичный ключ, пока не будет удалено или изменено это ограничение. После удаления индекса данные остаются в таблице, но теряют оптимизированный порядок доступа, что требует пересмотра запросов и возможного добавления альтернативных индексов.
Перед удалением рекомендуется оценить зависимость бизнес-процессов от структуры данных, выполнить полное резервное копирование и протестировать изменения на стенде. Это позволяет избежать необратимых последствий и сохранить стабильность работы системы.
Как удалить кластеризованный индекс с помощью T-SQL
Удаление кластеризованного индекса в T-SQL требует точного понимания структуры таблицы и возможных последствий для производительности и связей. Ниже представлен пошаговый процесс удаления кластеризованного индекса:
- Определите имя кластеризованного индекса. Выполните запрос:
SELECT name
FROM sys.indexes
WHERE object_id = OBJECT_ID('ИмяТаблицы') AND type_desc = 'CLUSTERED';- Удалите индекс с помощью команды
DROP INDEX:
DROP INDEX [ИмяИндекса] ON [ИмяСхемы].[ИмяТаблицы];- Если таблица принадлежит схеме, обязательно укажите схему.
- Удаление кластеризованного индекса приведёт к потере физического порядка строк.
- Если кластеризованный индекс создавался как первичный ключ, сначала удалите ограничение:
ALTER TABLE [ИмяСхемы].[ИмяТаблицы] DROP CONSTRAINT [ИмяОграничения];- Проверьте наличие некластеризованных индексов с включением
DROP_EXISTING = ONв планах изменения. - Убедитесь, что нет зависимостей, например, внешних ключей, основанных на удаляемом ограничении.
- Проверьте результат:
SELECT name, type_desc
FROM sys.indexes
WHERE object_id = OBJECT_ID('ИмяТаблицы');Удаление кластеризованного индекса может значительно повлиять на производительность запросов, особенно при работе с большими объемами данных. В ряде случаев рекомендуется создать альтернативный индекс до удаления основного.
Как удалить кластеризованный индекс через SSMS
Откройте SQL Server Management Studio и подключитесь к нужному экземпляру сервера. В Object Explorer разверните базу данных, содержащую таблицу с индексом. Перейдите к разделу «Tables», найдите нужную таблицу, щёлкните по ней правой кнопкой и выберите «Design».
В верхнем меню выберите «Indexes/Keys». В открывшемся окне найдите индекс с типом «Clustered». Убедитесь, что это именно тот индекс, который требуется удалить, так как кластеризованный индекс влияет на физический порядок хранения данных в таблице.
Выделите нужный индекс и нажмите «Delete». Нажмите «Close», затем сохраните изменения через Ctrl+S или пункт меню «File» → «Save».
Если таблица содержит ограничения первичного ключа, использующие кластеризованный индекс, их сначала необходимо удалить или изменить. Для этого в окне «Table Designer» перейдите к разделу «Relationships» или «Check Constraints» и удалите соответствующие зависимости.
После удаления кластеризованного индекса таблица остаётся без определённого порядка строк. Рекомендуется сразу создать новый кластеризованный индекс, если это необходимо для поддержания производительности запросов и логической структуры данных.
Какие ограничения и зависимости могут помешать удалению индекса
Индексы, используемые в качестве источника для уникальных ограничений (UNIQUE CONSTRAINT), также нельзя удалить напрямую. Сначала требуется удалить или изменить соответствующее ограничение.
Если индекс участвует в реализации FOREIGN KEY в других таблицах, его удаление приведет к нарушению ссылочной целостности. Нужно предварительно пересмотреть или удалить зависимости в дочерних таблицах.
В представлениях с опцией SCHEMABINDING таблица не может быть изменена, включая удаление индекса, до удаления или модификации представления. Используйте команду ALTER VIEW без SCHEMABINDING либо DROP VIEW.
Индексы, участвующие в репликации (особенно transactional или merge), не могут быть удалены без пересмотра конфигурации публикации. Удаление может привести к ошибкам синхронизации.
Кластеризованный индекс, используемый в индексированных представлениях (indexed views), удалить нельзя, пока представление существует. Необходимо сначала удалить представление.
Функции, триггеры или хранимые процедуры, ссылающиеся на конкретный порядок данных, обеспечиваемый кластеризованным индексом, могут работать некорректно после его удаления. Необходимо проанализировать зависимости через sys.sql_expression_dependencies и провести регрессионное тестирование.
Как подготовить таблицу к удалению кластеризованного индекса

Удаление кластеризованного индекса в MS SQL требует предварительной подготовки таблицы. Этот процесс может затронуть производительность системы и структуру данных, поэтому важно учитывать несколько ключевых аспектов.
- Проверка зависимостей: Перед удалением индекса убедитесь, что нет важных зависимостей, таких как внешние ключи, которые могут быть нарушены после его удаления. Используйте команду
sp_dependsдля поиска объектов, которые зависят от индекса. - Оценка воздействия на производительность: После удаления кластеризованного индекса таблица будет использовать нестандартный порядок хранения данных, что может ухудшить производительность запросов. Оцените текущие планы выполнения запросов с помощью
EXEC sp_helpindexи сделайте тестирование без индекса на рабочем сервере или тестовом окружении. - Создание резервной копии данных: Резервное копирование важно на всех этапах. Даже если это кажется избыточным, потеря индекса может повлиять на восстановление данных, особенно если структура таблицы сильно изменится.
- Удаление ненужных индексов: Если таблица содержит несколько индексов, которые больше не используются, удаление их также может улучшить производительность, освободив ресурсы.
- Использование ALTER TABLE для управления индексами: Для удаления кластеризованного индекса используйте команду
DROP INDEX, но не забудьте, что сначала нужно будет снять блокировки и подготовить систему к изменениям. Рекомендуется делать это в период низкой нагрузки на сервер. - Планирование изменений: Отключение индекса может потребовать длительное время для пересоздания данных. Подготовьте стратегию миграции или временного использования других индексов для ускорения запросов в период промежуточных изменений.
Эти действия помогут вам минимизировать риски при удалении кластеризованного индекса и подготовить таблицу к эффективным изменениям в структуре данных.
Что делать после удаления кластеризованного индекса

После удаления кластеризованного индекса необходимо выполнить несколько шагов для восстановления оптимальной работы базы данных и улучшения производительности запросов.
1. Проверить фрагментацию данных. Удаление кластеризованного индекса может привести к фрагментации таблицы, так как записи будут перераспределяться по страницам. Для анализа уровня фрагментации используйте команду DBCC SHOWCONTIG или sys.dm_db_index_physical_stats, чтобы выявить степень фрагментации и принять решение о дефрагментации данных с помощью команды ALTER INDEX REBUILD или REORGANIZE.
2. Создать новый кластеризованный индекс. Если удаление индекса было непреднамеренным, или если вы хотите оптимизировать таблицу, следует создать новый кластеризованный индекс. Выбор колонок для нового индекса должен базироваться на характере запросов, таких как частые выборки по конкретным столбцам или условиям сортировки.
3. Обновить статистику. После удаления индекса статистика по данным таблицы может стать неактуальной. Для улучшения планов выполнения запросов выполните команду UPDATE STATISTICS для таблицы или конкретных индексов, что поможет СУБД правильно оценивать оптимальные планы выполнения запросов.
4. Пересмотреть запросы и планы выполнения. После удаления индекса могут измениться планы выполнения запросов, что приведет к ухудшению производительности. Используйте SQL Server Management Studio (SSMS) или DMVs для анализа текущих планов выполнения запросов и их оптимизации с учетом изменений в структуре таблиц.
5. Мониторинг и анализ производительности. После удаления индекса полезно провести мониторинг производительности базы данных. Используйте инструменты, такие как SQL Server Profiler или Dynamic Management Views (DMVs), чтобы следить за временем выполнения запросов и выявить возможные узкие места, связанные с удалением индекса.
6. Рассмотреть создание нерегулярных индексов. В зависимости от изменившихся требований к производительности можно рассмотреть создание уникальных, полнотекстовых или включающих индексов, если это необходимо для ускорения специфических запросов, таких как поиск по тексту или выборки с дополнительными колонками.
7. Оценить влияние на приложения. Убедитесь, что удаление индекса не повлияло на работу приложений, использующих базу данных. Проведите тестирование функциональности, чтобы убедиться, что отсутствие кластеризованного индекса не замедляет критичные операции.
Альтернативы кластеризованному индексу после его удаления
После удаления кластеризованного индекса важно рассмотреть альтернативы, которые могут помочь поддерживать эффективность запросов и организацию данных. Каждое из решений зависит от особенностей конкретной базы данных и требований к производительности.
Один из возможных вариантов – создание нефизического кластеризованного индекса с помощью хипертаблиц. Этот подход позволяет достичь сходных результатов в плане организации данных, при этом индексирование осуществляется на уровне представлений, а не самой таблицы. Это подход подходит для базы данных с редкими изменениями данных, где требуется максимальная гибкость в выборе индексов.
Другой важной альтернативой является использование неиндексированных таблиц с дополнительными фильтрами. В этой ситуации запросы могут быть оптимизированы за счет применения фильтров в SQL-запросах, которые эффективно уменьшают количество данных, извлекаемых с диска. Такой подход подходит для приложений с небольшим количеством записей или где данные, сохраняемые в базе, редко изменяются.
Для сохранения оптимизации запросов можно использовать составные индексы. В отличие от кластеризованных, они не изменяют физическую организацию данных, но могут значительно ускорить выполнение сложных запросов, особенно тех, что включают несколько столбцов. Это альтернатива также имеет преимущество в поддержке выборок по различным критериям.
Если удаление кластеризованного индекса связано с высокой активностью записи данных, можно применить инкрементальные индексы. Эти индексы фокусируются на быстро обновляемых данных, обеспечивая эффективную работу с транзакциями, не создавая значительных задержек при записи новых значений. Такой подход идеально подходит для баз данных с постоянным вводом данных, где требуется поддерживать высокую скорость операций.
В некоторых случаях полезно использовать параллельные индексы, которые разделяют данные на части, ускоряя выполнение запросов с большими объемами информации. Это эффективное решение для аналитических запросов, когда важна скорость обработки больших объемов данных, а структура таблиц не требует физической организации, как при использовании кластеризованных индексов.
Каждое из предложенных решений требует учета специфики работы с данными, а также регулярного мониторинга производительности системы для своевременной оптимизации индексации в зависимости от изменения нагрузки на сервер.
Вопрос-ответ:
Что такое кластеризованный индекс в MS SQL и почему его удаление может быть необходимым?
Кластеризованный индекс в MS SQL — это тип индекса, который определяет физический порядок строк в таблице. Это значит, что строки таблицы упорядочиваются на уровне хранения данных в соответствии с ключом кластеризованного индекса. Удаление кластеризованного индекса может быть необходимо по разным причинам: например, если индекс больше не нужен для оптимизации запросов, если требуется изменить структуру таблицы или если в ходе оптимизации базы данных выявлены проблемы с производительностью.
Какие последствия могут возникнуть при удалении кластеризованного индекса в MS SQL?
Удаление кластеризованного индекса может повлиять на производительность работы с базой данных. Запросы, которые ранее использовали этот индекс для оптимизации поиска, могут стать менее эффективными. Без индекса выполнение запросов, которые требуют сортировки или поиска по большому объему данных, может занять больше времени. Также могут возникнуть проблемы с обеспечением целостности данных, если индекс использовался для реализации связей между таблицами (например, в случае внешних ключей).
Что будет, если удалить кластеризованный индекс, но не создать новый?
Если удалить кластеризованный индекс и не создать новый, то таблица останется без кластеризованного индекса. Это повлияет на работу с данными, так как запросы, использующие поиск по столбцам, не входящим в первичный ключ, будут работать медленнее. В таблице останется только некластеризованный индекс (если он был), что не позволит оптимизировать запросы с сортировкой или выборкой большого объема данных. Поэтому рекомендуется либо создавать новый кластеризованный индекс, либо тщательно пересматривать структуру запросов и таблиц для поддержания нужной производительности.