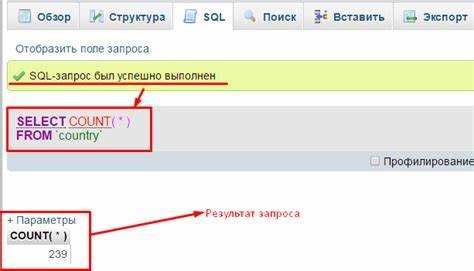
Подсчёт количества строк в таблице – это одна из базовых, но часто неправильно реализуемых операций в SQL. В большинстве случаев используется выражение SELECT COUNT(*) FROM table_name, однако такой подход может иметь различную производительность в зависимости от архитектуры базы данных и объёма данных.
Для PostgreSQL, использование COUNT(*) над всей таблицей инициирует полный просмотр таблицы (Sequential Scan), что может занимать значительное время при миллионах записей. Если задача – получить приблизительное количество строк для анализа или мониторинга, можно обратиться к системным представлениям, например: SELECT reltuples::bigint FROM pg_class WHERE relname = ‘table_name’. Это даст оценочное число строк, основанное на статистике, собираемой планировщиком запросов.
В MySQL, использование SELECT COUNT(*) на InnoDB-таблице также приведёт к полному сканированию, так как движок не хранит точное количество строк. Однако для таблиц с движком MyISAM команда SHOW TABLE STATUS LIKE ‘table_name’ может вернуть точное количество строк значительно быстрее.
Для SQLite оптимального пути нет – COUNT(*) всегда выполняется напрямую и без оптимизаций. При необходимости ускорения можно использовать триггеры и поддерживать отдельный счётчик строк в другой таблице.
Выбор метода зависит от контекста: нужна ли точность, насколько критична скорость, и какова частота обновлений таблицы. Оценка стоимости запроса и тестирование на реальных данных позволяет найти компромисс между точностью и производительностью.
Простой способ подсчета строк с использованием COUNT(*)

Функция COUNT(*) в SQL используется для подсчета всех строк в таблице, включая те, где все значения NULL. Этот метод не требует указания конкретного столбца и учитывает каждую запись, независимо от содержимого.
Пример запроса для получения общего количества строк в таблице users:
SELECT COUNT(*) FROM users;
Такой запрос выполняется быстро при наличии индексированного столбца, особенно если используется движок базы данных, поддерживающий оптимизацию подсчета строк (например, PostgreSQL при анализе системных таблиц).
Важно учитывать, что COUNT(*) не фильтрует строки. Чтобы подсчитать только определённые записи, необходимо использовать условие WHERE. Например:
SELECT COUNT(*) FROM users WHERE active = true;
Если необходимо точное значение при высокой нагрузке или большом объёме данных, убедитесь, что таблица анализировалась командой ANALYZE или что статистика актуальна, иначе результат может быть неточным при использовании планировщика запросов.
Когда использовать COUNT(1) вместо COUNT(*)
COUNT(1) используется для подсчёта строк в таблице, аналогично COUNT(*), но с иным способом обработки на уровне оптимизатора. COUNT(*) учитывает все строки, включая NULL, и не требует обращения к конкретным столбцам. COUNT(1) заставляет оптимизатор рассматривать константу, что может повлиять на план выполнения.
В системах, где таблица содержит сложные представления, подзапросы или соединения, COUNT(1) может показывать лучшую производительность за счёт исключения проверки всех столбцов. Однако это преимущество проявляется только при специфической реализации движка СУБД. В PostgreSQL и SQLite разницы нет. В Oracle COUNT(1) иногда работает быстрее в условиях большого количества столбцов и отсутствия индекса.
В MySQL оптимизатор приравнивает COUNT(1) и COUNT(*) по эффективности, но COUNT(1) может быть полезен для явной демонстрации, что не требуется анализ содержимого строк. Это повышает читаемость в случаях с агрегатами и аналитическими запросами.
Использовать COUNT(1) оправдано, когда известны особенности СУБД, и необходимо уточнить поведение запроса. В остальных случаях COUNT(*) остаётся предпочтительным благодаря универсальности и предсказуемости.
Подсчет строк с учетом условия WHERE
Для точного подсчета строк, соответствующих определённому критерию, используется конструкция SELECT COUNT(*) с уточнением условий через WHERE. Это позволяет исключить ненужные записи и получить релевантное значение.
Пример: чтобы узнать количество активных пользователей в таблице users, где поле status имеет значение ‘active’, выполните:
SELECT COUNT(*) FROM users WHERE status = 'active';
Если необходимо учесть диапазон дат, например количество заказов за последний месяц, запрос будет следующим:
SELECT COUNT(*) FROM orders WHERE order_date >= CURRENT_DATE - INTERVAL '30 days';
При использовании JOIN в подзапросах важно, чтобы условие WHERE не ограничивало результаты до соединения, иначе возможна потеря строк. Всегда проверяйте, на каком этапе фильтруются данные.
Для сложных условий применяйте логические операторы AND, OR и скобки. Пример подсчета сотрудников из отдела продаж с опытом более 5 лет:
SELECT COUNT(*) FROM employees WHERE department = 'sales' AND experience > 5;
Используйте EXPLAIN для анализа плана выполнения и оптимизации запросов с условиями, особенно при работе с большими объемами данных.
Как исключить дубликаты с помощью COUNT(DISTINCT)
Функция COUNT(DISTINCT) используется для подсчета уникальных значений в столбце. Она игнорирует повторяющиеся записи, что критично при работе с неочищенными данными, где возможно дублирование по ключевому признаку.
Пример: необходимо узнать количество уникальных клиентов по идентификатору client_id в таблице orders.
SELECT COUNT(DISTINCT client_id) AS unique_clients FROM orders;Если требуется учесть уникальность по нескольким столбцам, например, client_id и order_date, то синтаксис изменится:
SELECT COUNT(DISTINCT client_id, order_date) FROM orders;Однако не все СУБД поддерживают множественные столбцы в COUNT(DISTINCT). В PostgreSQL и MySQL 8.0+ это возможно. В других случаях используйте вложенные запросы или агрегирование через GROUP BY:
SELECT COUNT(*) FROM (SELECT client_id, order_date FROM orders GROUP BY client_id, order_date) AS unique_orders;Использование COUNT(DISTINCT) снижает нагрузку по сравнению с GROUP BY в случае простых подсчетов по одному полю. При наличии индексов на проверяемые столбцы производительность заметно возрастает.
Избегайте применения DISTINCT к столбцам с типами TEXT, BLOB и другим крупным структурам – это приводит к перерасходу ресурсов. Приводите значения к хешу или используйте идентификаторы.
Проверяйте влияние запроса на производительность через EXPLAIN и индексируйте поля, участвующие в COUNT(DISTINCT), особенно при больших объемах данных.
Получение количества строк в нескольких таблицах сразу

Для одновременного подсчёта строк в нескольких таблицах используйте оператор UNION ALL в сочетании с SELECT COUNT(*). Это позволяет получить результаты одним запросом без необходимости запускать каждый запрос по отдельности.
SELECT 'users' AS table_name, COUNT(*) AS row_count FROM users
UNION ALL
SELECT 'orders', COUNT(*) FROM orders
UNION ALL
SELECT 'products', COUNT(*) FROM products;
Если нужно подсчитать строки во всех таблицах базы данных без ручного перечисления, используйте системные представления:
- Для PostgreSQL:
SELECT relname AS table_name, n_live_tup AS estimated_rows FROM pg_stat_user_tables ORDER BY estimated_rows DESC; - Для MySQL:
SELECT table_name, table_rows FROM information_schema.tables WHERE table_schema = 'имя_вашей_бд'; - Для SQL Server:
SELECT t.name AS table_name, SUM(p.rows) AS row_count FROM sys.tables t JOIN sys.partitions p ON t.object_id = p.object_id WHERE p.index_id IN (0,1) GROUP BY t.name;
Если необходимо получить точные значения, избегайте использования оценочных столбцов вроде table_rows в MySQL или n_live_tup в PostgreSQL – выполняйте SELECT COUNT(*) в подзапросах, но помните о высокой нагрузке при большом объёме данных.
Для автоматизации можно использовать динамическое формирование SQL-запроса на стороне приложения или через хранимую процедуру. Это особенно полезно при работе с десятками таблиц.
Использование системных представлений для оценки количества строк
В большинстве СУБД существуют системные представления, которые позволяют быстро получить информацию о числе строк в таблице. Это может быть полезно, если требуется оценить размер таблицы без выполнения полноценного запроса с подсчётом строк, что может быть ресурсозатратно, особенно для больших данных.
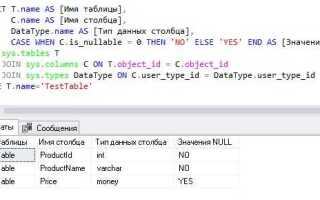
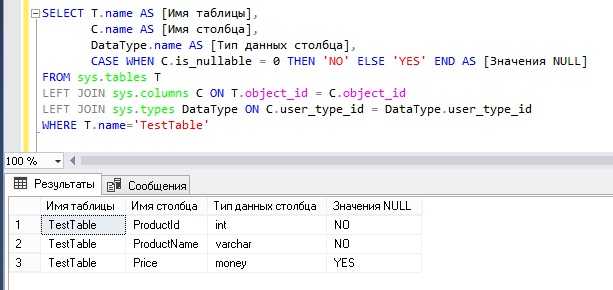
Для SQL Server, например, можно использовать представление sys.dm_db_partition_stats, которое хранит статистику по разделам базы данных. Это представление включает столбец row_count, показывающий количество строк в таблице, с учётом всех её разделов. Запрос для получения количества строк может выглядеть так:
SELECT SUM(row_count)
FROM sys.dm_db_partition_stats
WHERE object_id = OBJECT_ID('schema.table_name')
AND index_id IN (0,1);
Здесь index_id IN (0,1) позволяет учесть все строки как в кластере, так и в некластерных индексах, поскольку они могут хранить данные о строках.
В MySQL аналогичная информация доступна через системное представление information_schema.tables. Для получения числа строк используется столбец table_rows, который хранит приближённое значение количества строк в таблице. Запрос будет следующим:
SELECT table_rows FROM information_schema.tables WHERE table_schema = 'database_name' AND table_name = 'table_name';
Этот подход даёт быстрое, но приближённое значение. Для точного подсчёта нужно выполнить запрос COUNT(*) на самой таблице.
Для PostgreSQL полезным системным представлением является pg_class, которое хранит статистику по таблицам. Чтобы получить число строк, используется следующая команда:
SELECT reltuples::bigint FROM pg_class WHERE oid = 'schema.table_name'::regclass;
Здесь reltuples указывает на примерное количество строк, полученное из статистики, а oid – это уникальный идентификатор таблицы в базе данных.
Использование системных представлений позволяет значительно снизить нагрузку на сервер и получить быстрые результаты, однако важно помнить, что данные могут быть приближёнными, особенно в случаях, когда статистика не была обновлена после изменения данных в таблице.
Проверка производительности COUNT на больших таблицах
При работе с большими таблицами использование функции COUNT может привести к значительным нагрузкам на систему, особенно если таблица содержит миллионы строк. Основная проблема заключается в том, что стандартный запрос SELECT COUNT(*) FROM таблица требует полной сканирования всех строк в таблице, что сильно увеличивает время выполнения на больших объемах данных.
Чтобы улучшить производительность, стоит обратить внимание на несколько факторов. Во-первых, индексы играют ключевую роль. Если в таблице есть индекс по столбцу, по которому выполняется подсчет, это может существенно ускорить выполнение запроса. Например, использование индекса по первичному ключу или уникальному индексу позволяет базе данных быстро определить количество строк, без необходимости сканировать всю таблицу.
Однако на очень больших таблицах даже индексы не всегда дают ожидаемый результат. В таких случаях можно использовать альтернативные методы подсчета, например, кэширование результатов. Часто запрашиваемое количество строк можно сохранять в отдельной таблице или в кэше, что позволяет избежать повторных вычислений. Для динамических таблиц, в которых количество строк часто изменяется, можно обновлять это значение в процессе вставки или удаления данных.
Еще одной практикой является использование параллельных запросов. В некоторых системах управления базами данных (СУБД) поддерживается выполнение запросов с использованием нескольких потоков, что может ускорить операцию подсчета. В таком случае таблица делится на несколько частей, и подсчет выполняется параллельно для каждой части, что значительно снижает время ожидания.
Также стоит помнить, что функция COUNT(*) может быть менее эффективной, чем использование COUNT(1), так как она не всегда использует оптимизацию, зависящую от структуры данных и индексов. В некоторых случаях этот вариант может работать быстрее, так как не требует полной проверки значений столбцов.
В ситуациях, когда точный подсчет строк не критичен, можно использовать методика вычисления оценочного количества строк. Многие СУБД поддерживают статистику о таблицах, и вместо выполнения запроса можно получить приблизительное количество строк через системные представления или функции. Это даст результат намного быстрее, но может быть не столь точным.
Если необходимо постоянно работать с большими объемами данных и нужно часто выполнять подсчеты строк, стоит рассмотреть возможность пересмотра архитектуры базы данных. Например, хранение агрегированных данных в отдельной таблице, где хранятся только результаты подсчетов для различных диапазонов или групп, может быть гораздо более эффективным решением, чем многократное выполнение тяжелых запросов COUNT.