

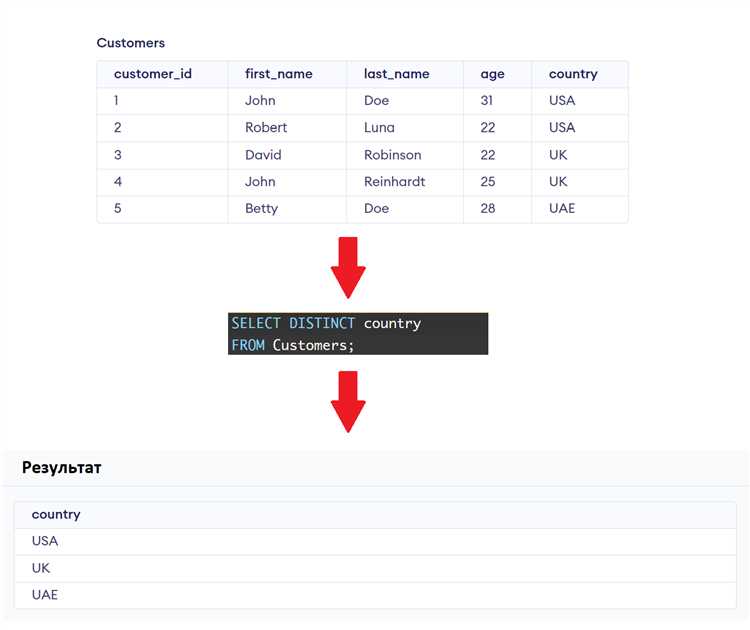
Для извлечения уникальных значений из столбца таблицы в SQL используется ключевое слово DISTINCT. Оно позволяет сократить дублирующиеся записи, возвращая только разные значения. Например, запрос SELECT DISTINCT имя_столбца FROM имя_таблицы отфильтрует повторяющиеся строки, что особенно полезно при анализе категориальных данных или создании выпадающих списков.
Следует учитывать, что DISTINCT применяется ко всей выборке, а не только к отдельному столбцу. Поэтому, если в запрос включены несколько столбцов, он вернёт уникальные комбинации значений. Для фильтрации только одного столбца необходимо указывать в SELECT только его. В противном случае результат может оказаться неожиданным.
Если требуется произвести дополнительные преобразования перед выборкой уникальных данных – например, привести значения к одному регистру – можно использовать функции LOWER() или UPPER() вместе с DISTINCT. Пример: SELECT DISTINCT LOWER(имя_столбца) FROM имя_таблицы. Это особенно актуально при работе с текстовыми данными, где «Москва» и «МОСКВА» считаются разными значениями.
При работе с большими таблицами важно учитывать производительность. DISTINCT может значительно замедлить выполнение запроса, особенно без индекса на столбец. В таких случаях стоит рассмотреть возможность предварительной агрегации данных или использования GROUP BY – SELECT имя_столбца FROM имя_таблицы GROUP BY имя_столбца возвращает те же уникальные значения, но может быть эффективнее на некоторых СУБД.
Применение DISTINCT для выборки уникальных значений
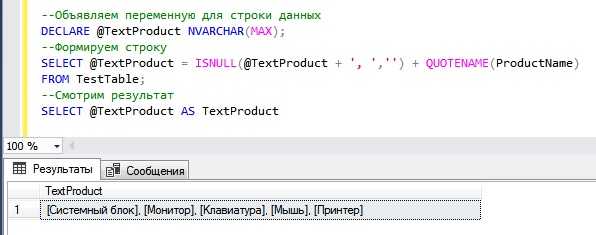
DISTINCT используется для исключения повторяющихся записей в результирующем наборе при выполнении SELECT-запроса. Он применяется непосредственно перед указанием имени столбца или выражения.
Пример запроса для получения уникальных значений из столбца email таблицы users:
SELECT DISTINCT email FROM users;Если требуется извлечь уникальные комбинации нескольких столбцов, DISTINCT применяется к кортежу значений. Например, чтобы найти уникальные пары город–страна:
SELECT DISTINCT city, country FROM locations;Важно учитывать, что DISTINCT обрабатывает всю строку, возвращаемую в результате. Если один столбец повторяется, но другие отличаются – запись будет считаться уникальной.
Чтобы избежать неожиданного поведения, убедитесь, что вы явно указываете только те столбцы, по которым действительно требуется фильтрация. При необходимости предварительно нормализуйте данные, например, приведя значения к одному регистру:
SELECT DISTINCT LOWER(email) FROM users;При работе с большими таблицами стоит учитывать производительность: DISTINCT требует сортировки или хэширования, что может повлиять на время выполнения. Оптимизируйте запросы, минимизируя количество возвращаемых столбцов и применяя индексацию.
Использование GROUP BY для группировки по значениям столбца
Оператор GROUP BY позволяет сгруппировать строки с одинаковыми значениями указанного столбца. Это удобно, когда требуется получить набор уникальных значений, дополнительно агрегируя данные.
Пример запроса: SELECT category FROM products GROUP BY category; – вернёт один результат на каждое уникальное значение category из таблицы products. Он работает аналогично SELECT DISTINCT, но предоставляет больше возможностей при добавлении агрегатных функций.
Для подсчёта количества записей в каждой группе используется COUNT(*): SELECT category, COUNT(*) FROM products GROUP BY category;. Это не только возвращает уникальные значения, но и показывает, сколько раз каждое из них встречается.
Использовать GROUP BY следует, если требуется дополнительная обработка – например, нахождение суммы, среднего или максимального значения в рамках каждой группы. В отличие от DISTINCT, GROUP BY гибче и подходит для аналитических задач.
Чем отличается SELECT DISTINCT от GROUP BY на практике
Оба оператора используются для получения уникальных строк, но поведение их различается в деталях и в целях применения. Понимание этих различий критично для оптимизации запросов и предотвращения логических ошибок.
- SELECT DISTINCT удаляет дубликаты из результирующего набора. Он применяется, когда нужно вернуть уникальные комбинации значений по заданным столбцам без агрегации.
- GROUP BY группирует строки по указанным полям и часто используется совместно с агрегатными функциями – COUNT(), SUM(), AVG(), MAX(), MIN(). Без агрегации GROUP BY эквивалентен DISTINCT, но сложнее по синтаксису и ресурсам.
На практике:
- Если требуется просто выбрать уникальные значения из одного или нескольких столбцов – выбирайте DISTINCT. Он короче, проще и читаемее.
- Если нужно сгруппировать данные и посчитать метрики (например, количество строк в каждой группе) – необходим GROUP BY.
Примеры:
SELECT DISTINCT city FROM customers;– вернёт уникальные города без подсчёта.SELECT city, COUNT(*) FROM customers GROUP BY city;– сгруппирует клиентов по городам и покажет, сколько клиентов в каждом.
Производительность: DISTINCT работает быстрее в случаях, когда не требуется агрегация. GROUP BY может быть медленнее, особенно без индексов на группируемых столбцах.
Итог: выбирайте DISTINCT для выборки уникальных строк, GROUP BY – для анализа и сводной информации.
Как получить уникальные значения с фильтрацией WHERE
Для извлечения уникальных значений из столбца с применением фильтра используйте комбинацию SELECT DISTINCT и условия WHERE. Это позволяет сократить выборку и сфокусироваться на нужных данных.
Пример запроса:
SELECT DISTINCT город
FROM клиенты
WHERE страна = 'Германия';В этом примере выбираются только уникальные значения столбца город, при этом учитываются только записи, где страна равна «Германия».
Убедитесь, что фильтрация не исключает нужные значения. Для этого используйте логические операторы AND, OR, IN и BETWEEN в блоке WHERE. Например:
SELECT DISTINCT профессия
FROM сотрудники
WHERE возраст BETWEEN 30 AND 40 AND отдел = 'Маркетинг';Запрос вернёт уникальные профессии сотрудников из отдела «Маркетинг» в возрасте от 30 до 40 лет включительно.
Чтобы учесть регистр строк в текстовых полях, применяйте функции, например LOWER() или UPPER():
SELECT DISTINCT LOWER(имя_товара)
FROM товары
WHERE категория = 'Электроника';Такой подход исключает дублирование из-за различий в регистре и делает выборку однородной.
Извлечение уникальных значений из нескольких столбцов
Для получения уникальных комбинаций значений из нескольких столбцов используется конструкция SELECT DISTINCT с указанием нужных полей. Например, чтобы извлечь уникальные сочетания имени и города из таблицы users, выполните:
SELECT DISTINCT name, city FROM users;
Если требуется получить уникальные значения из объединения данных разных столбцов, применяют UNION. Команда UNION автоматически исключает дубликаты. Пример запроса, извлекающего уникальные значения из двух столбцов одной таблицы:
SELECT email FROM contacts UNION SELECT phone FROM contacts;
(SELECT email FROM contacts UNION SELECT phone FROM contacts) ORDER BY 1;
При работе с большими наборами данных целесообразно индексировать задействованные поля для повышения производительности. Следует избегать использования UNION ALL, если необходимо исключить повторяющиеся значения – этот оператор сохраняет дубликаты.
Если требуется учесть только непустые значения, добавляются условия WHERE. Например:
SELECT email FROM contacts WHERE email IS NOT NULL UNION SELECT phone FROM contacts WHERE phone IS NOT NULL;
Для агрегации уникальных значений по нескольким столбцам в рамках одной колонки можно использовать UNNEST и ARRAY в PostgreSQL или UNPIVOT в SQL Server.
Получение уникальных записей с учетом сортировки
Для получения уникальных значений в SQL с учетом сортировки используется комбинация ключевых слов DISTINCT и ORDER BY. Это позволяет не только устранить дублирующиеся записи, но и упорядочить их по выбранному критерию.
Пример запроса для получения уникальных значений из столбца с сортировкой по возрастанию:
SELECT DISTINCT column_name
FROM table_name
ORDER BY column_name ASC;Здесь DISTINCT удаляет повторяющиеся записи в выбранном столбце, а ORDER BY сортирует результаты. Если нужно отсортировать данные по убыванию, используйте DESC вместо ASC.
В случае, если уникальность требуется по комбинации нескольких столбцов, запрос будет выглядеть следующим образом:
SELECT DISTINCT column1, column2
FROM table_name
ORDER BY column1, column2;Если сортировка применяется только к одному из столбцов, а уникальность – ко всей комбинации столбцов, SQL все равно учитывает сортировку по указанным столбцам. Например, если нужно получить уникальные пары значений, упорядоченные по первому столбцу, запрос будет следующим:
SELECT DISTINCT column1, column2
FROM table_name
ORDER BY column1;Важно помнить, что для сортировки уникальных записей по определенному столбцу сортировка будет выполняться после удаления дубликатов. Если порядок значений в результирующем наборе важен, следует тщательно выбирать столбцы для сортировки, так как сортировка по нескольким столбцам может изменить расположение уникальных значений.
При работе с большими объемами данных использование DISTINCT в сочетании с сортировкой может заметно повлиять на производительность. В таких случаях рекомендуется проверять индексирование столбцов, которые участвуют в запросах, для ускорения выполнения.
Как посчитать количество уникальных значений через COUNT(DISTINCT)
Функция COUNT(DISTINCT) используется для подсчета уникальных значений в столбце базы данных. Она исключает дублирующиеся значения и возвращает количество уникальных записей. Например, чтобы подсчитать количество уникальных клиентов, можно использовать запрос:
SELECT COUNT(DISTINCT customer_id) FROM orders;
Этот запрос вернет количество уникальных идентификаторов клиентов, сделавших хотя бы один заказ. Обратите внимание, что COUNT(DISTINCT) считает только уникальные значения и игнорирует повторяющиеся. Также важно понимать, что COUNT(DISTINCT) работает только с одним столбцом. Если необходимо посчитать уникальные комбинации значений из нескольких столбцов, запрос будет выглядеть так:
SELECT COUNT(DISTINCT column1, column2) FROM table_name;
В некоторых СУБД (например, MySQL) такой запрос не будет работать, так как COUNT(DISTINCT) поддерживает только один столбец. В этом случае для подсчета уникальных комбинаций можно использовать CONCAT() для объединения столбцов:
SELECT COUNT(DISTINCT CONCAT(column1, column2)) FROM table_name;
При работе с большими объемами данных COUNT(DISTINCT) может занимать значительное время, так как требует сканирования всех строк в таблице и фильтрации повторяющихся значений. Чтобы улучшить производительность, рекомендуется использовать индексы на столбцах, по которым выполняется подсчет уникальных значений.
Обработка NULL при выборе уникальных значений
По умолчанию, при использовании оператора DISTINCT значения NULL обрабатываются особым образом. Все строки с NULL в выбранном столбце считаются одинаковыми. Это означает, что если столбец содержит несколько значений NULL, результат будет содержать только одно NULL, даже если в таблице их несколько.
- Пример 1: Запрос:
SELECT DISTINCT column_name FROM table_name;Если в столбце column_name есть несколько строк с NULL, результат будет содержать только одну строку с NULL.
- Пример 2: Запрос с фильтрацией NULL значений:
SELECT DISTINCT column_name FROM table_name WHERE column_name IS NOT NULL;Этот запрос исключит все строки с NULL и вернёт только уникальные ненулевые значения.
Для более сложных случаев можно использовать функцию COALESCE или IFNULL, чтобы заменить NULL на конкретное значение перед применением DISTINCT. Это может быть полезно, если нужно обрабатывать NULL как некое дефолтное значение, например, заменять NULL на пустую строку или на значение по умолчанию.
- Пример 3: Использование
COALESCEдля замены NULL:
SELECT DISTINCT COALESCE(column_name, 'default_value') FROM table_name;Этот запрос заменяет все NULL в столбце на строку 'default_value' и затем выбирает уникальные значения, включая это дефолтное значение.
Если необходимо включить NULL в результат, но при этом правильно обработать уникальные значения, можно использовать комбинацию CASE и DISTINCT:
- Пример 4: Использование
CASEдля включения NULL:
SELECT DISTINCT CASE WHEN column_name IS NULL THEN 'NULL' ELSE column_name END FROM table_name;Этот запрос преобразует NULL в строку ‘NULL’ и далее проводит выборку уникальных значений. Это может быть полезно, когда нужно явно отображать NULL как отдельное значение в итоговом наборе.
При работе с NULL важно понимать, что любые операторы сравнения (например, =, !=, <, >) не применимы к NULL в том смысле, как они применяются к обычным значениям. Использование функций IS NULL и IS NOT NULL является стандартным способом работы с такими значениями.
Знание этих тонкостей позволяет более точно формировать запросы и предотвращать ошибки при обработке данных в SQL.





