При проектировании баз данных часто возникает необходимость представления и хранения иерархических структур, таких как деревья. Например, каталоги товаров, организационные структуры или комментарии в форумах. SQL, несмотря на свою реляционную природу, не имеет встроенной поддержки для работы с деревьями данных. Тем не менее, существуют эффективные подходы для реализации этой задачи, каждый из которых имеет свои преимущества и недостатки в зависимости от конкретных требований.
Один из самых распространённых методов – это использование рекурсивных отношений, которые могут быть реализованы с помощью рекурсивных запросов SQL (например, с использованием CTE (Common Table Expressions)). Такой подход позволяет строить дерево с помощью представления данных как цепочки родитель-ребёнок. Для этого обычно в таблице добавляется дополнительное поле для хранения идентификатора родителя, что даёт возможность моделировать иерархию.
Другим распространённым подходом является использование материализованных путей, где для каждого элемента дерева в отдельном поле хранится путь, состоящий из всех идентификаторов его предков. Это позволяет легко и быстро извлекать все элементы, принадлежащие определённой ветви дерева, но требует дополнительного обновления путей при добавлении или удалении элементов, что может снизить производительность при изменениях структуры.
Каждый из этих подходов имеет свои особенности и может быть оптимален в различных сценариях. Например, если нужно часто запрашивать дерево целиком или части иерархии, рекурсивные запросы с CTE подойдут лучше, в то время как при постоянных изменениях структуры дерева эффективнее будет использовать материализованные пути с дополнительной логикой для обновлений путей.
Выбор модели хранения для иерархических данных в SQL
Иерархические данные представляют собой структуру, где элементы связаны родительскими и дочерними отношениями, что требует особого подхода к их хранению в реляционных базах данных. Существуют несколько моделей, каждая из которых имеет свои преимущества и ограничения в зависимости от типа задачи.
Основные модели хранения иерархических данных в SQL:
- Модель вложенных наборов (Adjacency List) – простая и широко используемая модель. Каждый элемент дерева хранится с указанием родительского элемента. Преимущество – легкость в реализации, недостаток – сложность при извлечении глубоко вложенных данных, требующих рекурсивных запросов.
- Модель пути (Path Enumeration) – каждый элемент хранит путь от корня до текущего узла в виде строки (например, «1/3/5»). Это упрощает извлечение всей поддеревья, но делает обновление данных более сложным, особенно при изменении структуры дерева.
- Модель материалации дерева (Materialized Path) – путь к элементу хранится в отдельной колонке, что позволяет легко извлекать поддеревья с помощью LIKE-запросов. Эта модель эффективна при чтении, но может потребовать дополнительной работы при обновлениях структуры.
- Модель вложенных множеств (Nested Sets) – в этой модели каждому элементу присваиваются два числа, представляющие его положение в дереве. Это решение позволяет извлекать поддеревья очень эффективно с использованием обычных SQL-запросов. Однако модель сложнее в реализации и требует дополнительных вычислений при обновлении данных.
- Модель предков и потомков (Closure Table) – отдельная таблица для хранения всех пар «родитель-потомок». Она позволяет эффективно извлекать любые отношения между узлами дерева. Недостаток – необходимость поддержания дополнительной таблицы, что может увеличивать сложность обновлений.
Выбор подходящей модели зависит от ряда факторов:
- Частота обновлений: Если структура дерева изменяется часто, модели, основанные на хранении пути (Path Enumeration) или использование таблицы предков и потомков, будут иметь преимущества, так как обновление данных происходит реже, чем извлечение.
- Потребности в запросах: Если основная задача – извлечение всего поддерева, то модель вложенных множеств (Nested Sets) или материализованный путь будут наиболее эффективными. Если нужны сложные отношения между узлами, лучше использовать модель предков и потомков.
- Сложность реализации: Модели типа Adjacency List проще в реализации и поддержке, в то время как модели, как Nested Sets и Closure Table, требуют дополнительного проектирования и управления данными.
Для большинства задач, где требуется высокая гибкость в запросах и сравнительно невысокая частота изменений, оптимальной может быть модель Path Enumeration или Nested Sets. В случаях, когда дерево часто изменяется, лучше выбрать модель Adjacency List или Closure Table, которые позволят более эффективно работать с обновлениями.
Использование структуры «родитель-ребёнок» для хранения деревьев

Для реализации этой структуры в SQL часто используется дополнительное поле, например, `parent_id`, которое указывает на родителя текущего элемента. Если узел является корнем дерева, то его `parent_id` будет равно `NULL`. Важно, чтобы каждый элемент дерева имел уникальный идентификатор, например, поле `id`, которое будет использоваться для установления связи с родителями и дочерними элементами.
Пример структуры таблицы:
CREATE TABLE categories (
id INT PRIMARY KEY,
name VARCHAR(255),
parent_id INT,
FOREIGN KEY (parent_id) REFERENCES categories(id)
);
Этот подход достаточно прост и эффективен для небольших деревьев и редко меняющихся иерархий. Однако с увеличением глубины дерева или частотой изменений структура может стать менее производительной из-за необходимости выполнения рекурсивных запросов.
При поиске дочерних узлов для конкретного родителя можно использовать запрос типа:
SELECT * FROM categories WHERE parent_id = ?;
Также возможен поиск всего дерева начиная с конкретного узла, что требует рекурсивных операций. Для таких случаев полезно использовать Common Table Expressions (CTE), которые позволяют легко строить рекурсивные запросы:
WITH RECURSIVE tree AS (
SELECT id, name, parent_id
FROM categories
WHERE parent_id IS NULL
UNION ALL
SELECT c.id, c.name, c.parent_id
FROM categories c
JOIN tree t ON c.parent_id = t.id
)
SELECT * FROM tree;
Этот запрос вернёт все узлы дерева, начиная с корня и включая все его дочерние элементы, на всех уровнях.
Преимущества этой структуры заключаются в её простоте, гибкости и способности к адаптации под различные задачи. Однако следует учитывать, что она может не подойти для очень глубоких деревьев или случаев, когда необходимо часто изменять иерархию. В таких ситуациях может потребоваться более сложная модель хранения, например, использование методов, таких как Nested Set или Materialized Path.
Применение рекурсивных запросов в SQL для работы с деревьями

Рекурсивные запросы в SQL позволяют эффективно работать с деревьями данных, где структура таблицы отражает иерархию. Для реализации рекурсии в SQL используется конструкция WITH RECURSIVE, поддерживаемая большинством современных СУБД, таких как PostgreSQL, MySQL, SQL Server.
Основной идеей рекурсивных запросов является наличие двух частей: базового запроса, который извлекает корневые элементы, и рекурсивной части, которая итеративно строит дерево, связывая дочерние и родительские элементы. Это позволяет извлекать всю иерархию, начиная от корня и до самых глубоких уровней.
Пример запроса для извлечения всех дочерних элементов с использованием рекурсии:
WITH RECURSIVE tree AS ( -- Базовый запрос: выбор корня дерева SELECT id, parent_id, name FROM nodes WHERE parent_id IS NULL UNION ALL -- Рекурсивный запрос: выбор дочерних элементов SELECT n.id, n.parent_id, n.name FROM nodes n INNER JOIN tree t ON n.parent_id = t.id ) SELECT * FROM tree;
В данном примере таблица nodes содержит поля id, parent_id и name, где parent_id ссылается на родительский элемент. Рекурсивный запрос строит дерево, начиная с корня (где parent_id равен NULL) и продолжая искать дочерние элементы, связывая их через parent_id и id.
Рекурсивные запросы подходят для различных типов задач:
- Построение структуры категорий и подкатегорий.
- Иерархическое представление сотрудников в компании.
- Создание и отображение сетей взаимосвязанных объектов (например, папок и файлов).
Однако рекурсивные запросы имеют свои особенности, которые важно учитывать при проектировании схемы:
- Глубина рекурсии. СУБД часто имеют ограничения по количеству рекурсивных вызовов. Например, в PostgreSQL это значение по умолчанию – 1000, и его можно изменить с помощью параметра
max_recursionв запросе. - Производительность. Рекурсивные запросы могут быть менее эффективными при больших объемах данных, поэтому их следует использовать с учетом объемов и требований к быстродействию.
- Циклические зависимости. Важно заранее убедиться, что в данных нет циклов, иначе рекурсивный запрос может зациклиться. Для этого часто применяют дополнительные условия или фильтрацию данных.
Для работы с большими деревьями и повышения производительности можно использовать дополнительные техники, такие как:
- Материализация путей. Вместо рекурсивных запросов иногда выгоднее хранить заранее рассчитанные пути или уровни иерархии в отдельной таблице, чтобы ускорить запросы.
- Индексация. Правильное индексирование полей
idиparent_idзначительно ускоряет выполнение рекурсивных запросов.
Таким образом, рекурсивные запросы – мощный инструмент для работы с иерархическими данными в SQL, но их применение требует учета особенностей конкретной СУБД и типа данных. Правильная настройка, индексация и внимание к потенциальным проблемам с производительностью помогут максимально эффективно использовать этот механизм.
Хранение деревьев данных с использованием таблиц с ссылочной целостностью
Для эффективного представления деревьев данных в SQL базах данных часто используется подход с таблицами, поддерживающими ссылочную целостность. В этом случае дерево моделируется через связь родитель-дочерний элемент, что позволяет легко управлять и обновлять иерархии, сохраняя при этом целостность данных. Основной принцип заключается в том, что дочерний элемент ссылается на родительский через внешний ключ.
Каждый элемент дерева может быть представлен строкой в таблице, где один из столбцов будет хранить идентификатор родительского элемента. Этот столбец представляет собой внешний ключ, который ссылается на идентификатор строки родителя. Например, для таблицы категорий товаров, где категория может иметь подкатегории, колонка parent_id будет указывать на id родительской категории. Такой подход сохраняет структуру дерева и позволяет легко реализовать операции вставки, удаления и обновления элементов дерева.
Пример структуры таблицы:
id | name | parent_id -----|-------------|---------- 1 | Электроника | NULL 2 | Телефоны | 1 3 | Ноутбуки | 1 4 | Смартфоны | 2
Здесь строка с id=1 представляет родительскую категорию «Электроника», а строки с parent_id = 1 указывают на подкатегории этой категории. Таблица не нуждается в дополнительной информации о глубине дерева, так как структура иерархии определена через связи между родителями и детьми.
При таком подходе важно обеспечить ссылочную целостность. Это можно реализовать с помощью ограничений FOREIGN KEY, которые гарантируют, что значения в колонке parent_id всегда будут ссылаться на существующие значения в колонке id или быть NULL, если элемент является корнем дерева.
Для удаления элементов дерева или изменения их местоположения необходимо правильно учитывать зависимые записи. Например, при удалении родительской категории стоит либо удалить все дочерние элементы (если это требуется), либо обновить их parent_id, чтобы они ссылались на нового родителя. Такие операции можно автоматизировать через каскадные удаления или обновления с помощью опции ON DELETE CASCADE или ON UPDATE CASCADE в определении внешнего ключа.
Одним из недостатков данного подхода является ограниченная поддержка операций для сложных деревьев с высокой глубиной и количеством ветвей. В таких случаях, возможно, потребуется оптимизация запросов с использованием рекурсивных CTE (Common Table Expressions) или других техник для более быстрого извлечения данных и обхода дерева.
Тем не менее, подход с использованием внешних ключей прост и гибок, что делает его эффективным для многих задач, связанных с хранением и обработкой данных в иерархической форме в реляционных базах данных.
Преимущества и недостатки хранения деревьев через Closure Table
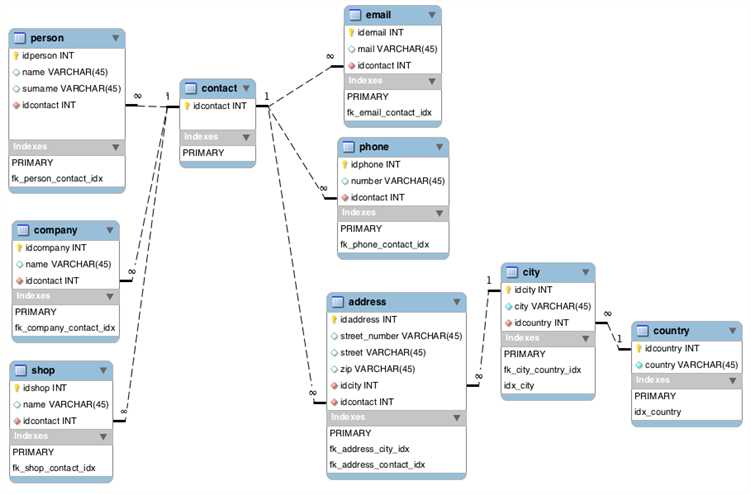
Использование Closure Table для хранения деревьев данных в SQL предоставляет значительные преимущества в плане гибкости и производительности при выполнении запросов, но требует дополнительных затрат на управление данными и их обновление.
Основным преимуществом данного подхода является упрощение операций поиска всех предков или потомков для конкретного узла. В отличие от других методов, таких как материализованный путь или Nested Set, Closure Table позволяет эффективно получать всю структуру дерева за одну операцию. Это достигается за счет хранения всех пар «родитель-потомок» в отдельной таблице, что ускоряет выполнение запросов и минимизирует количество соединений.
Заключение всех связей в одну таблицу упрощает задачи, связанные с вычислением всех путей от корня до листа или всех связанных узлов, что позволяет быстро получать необходимую информацию без дополнительных вычислений во время выполнения запросов. Например, для получения всех потомков узла достаточно выполнить запрос к таблице с условиями на идентификаторы родительских и дочерних узлов.
Однако, данный метод требует значительных затрат на обновление структуры дерева. При добавлении или удалении узлов необходимо обновлять несколько записей в таблице. Например, при удалении узла необходимо удалить все его связи с потомками и предками, что может привести к большому числу операций на одну транзакцию, особенно для больших деревьев. Это делает обновление данных менее эффективным по сравнению с другими методами, такими как Nested Set.
Другим недостатком является необходимость хранения дополнительных данных для каждой связи между узлами. Для каждого узла требуется записать не только его связь с родителем, но и все возможные предки и потомки, что может существенно увеличить объем данных. В случаях, когда дерево сильно разветвлено, количество записей в таблице может возрасти экспоненциально, что приведет к увеличению времени обработки запросов на вставку и удаление.
Также стоит отметить, что Closure Table не предоставляет явных ограничений для хранения деревьев с цикличными зависимостями, что может привести к нарушению целостности данных. Поэтому важно предусматривать механизмы контроля за корректностью структуры дерева на уровне приложения.
В целом, использование Closure Table подходит для случаев, когда требуется высокая скорость выборки данных, а обновление структуры дерева происходит относительно редко. Это отличный выбор для систем, где важно быстро получать все потомков или предков без необходимости пересчитывать всю структуру дерева на лету.
Использование Materialized Path для оптимизации запросов к деревьям
Метод Materialized Path представляет собой способ хранения и управления деревьями данных в реляционных базах данных, который позволяет существенно оптимизировать запросы, связанные с иерархическими структурами. В этом подходе каждый узел дерева хранит в себе путь от корня до текущего узла в виде строки, что значительно ускоряет операции поиска и выборки.
Основная идея Materialized Path заключается в том, что каждый элемент дерева получает уникальный идентификатор в виде строки, которая представляет путь к нему. Например, если узел является дочерним элементом узла с идентификатором «1», то его путь будет выглядеть как «1/2». Это позволяет легко и быстро извлекать данные для любых операций, таких как выборка всех потомков или родительских узлов.
Преимущества использования этого подхода для запросов к деревьям данных очевидны:
1. Поиск потомков. Запрос на выборку всех потомков конкретного узла можно выполнить с помощью простой операции сравнения строк. Например, для узла с идентификатором «1» все потомки будут иметь путь, начинающийся с «1». Это позволяет использовать SQL-запросы вида:
SELECT * FROM tree WHERE path LIKE '1/%';
2. Поиск родительских узлов. Найти родителя также легко, используя префикс пути. Для узла с путем «1/2» запрос на выборку родителя будет следующим:
SELECT * FROM tree WHERE path = '1';
3. Оптимизация JOIN-ов. В отличие от других методов, таких как Nested Sets, где для каждого узла требуется хранить дополнительные данные (например, левый и правый индексы), Materialized Path минимизирует количество необходимой информации и упрощает запросы без необходимости сложных соединений.
4. Гибкость в изменении структуры дерева. При добавлении или удалении узлов структура дерева меняется без необходимости перерасчета целых поддеревьев, как это происходит в других методах. Нужно лишь обновить путь для добавленного или удалённого элемента.
Однако стоит учитывать некоторые нюансы:
1. Размер строки пути. Чем глубже дерево, тем длиннее строки, что может увеличить объём данных, особенно для больших деревьев. В случае очень глубоких иерархий может возникнуть необходимость использовать более компактные представления пути, такие как числовые идентификаторы.
2. Обновления данных. Хотя Materialized Path упрощает выборки, обновление путей может быть более трудоёмким при перемещении узлов. Нужно обновить пути всех дочерних элементов при изменении родителя, что может повлиять на производительность при частых изменениях структуры дерева.
3. Индексы. Для улучшения производительности запросов важно создавать индексы на колонке с путём, особенно если дерево содержит большое количество узлов. Это обеспечит быстрый поиск и фильтрацию данных по пути.
В целом, метод Materialized Path представляет собой эффективный способ работы с иерархическими данными в SQL, особенно для деревьев с редкими изменениями структуры. Однако для динамичных деревьев, где часто происходят перемещения узлов, можно рассмотреть дополнительные методы оптимизации, такие как использование партиционирования данных или кэширования путей в отдельных таблицах.
Реализация поиска и обхода деревьев данных с использованием SQL

Одним из наиболее распространённых способов реализации дерева в SQL является хранение данных в виде таблицы с колонками для идентификатора элемента и идентификатора его родителя. Пример структуры таблицы:
CREATE TABLE nodes ( id INT PRIMARY KEY, parent_id INT, name VARCHAR(255) );
Здесь каждый узел дерева имеет идентификатор `id` и ссылку на родительский узел через `parent_id`. Главный узел дерева будет иметь значение NULL в поле `parent_id`.
Для обхода дерева можно использовать рекурсивные запросы. Пример запроса для поиска всех дочерних элементов для заданного узла с использованием Common Table Expressions (CTE):
WITH RECURSIVE tree AS ( SELECT id, parent_id, name FROM nodes WHERE id = 1 -- Начальный узел UNION ALL SELECT n.id, n.parent_id, n.name FROM nodes n JOIN tree t ON n.parent_id = t.id ) SELECT * FROM tree;
Этот запрос позволяет найти все узлы, которые находятся ниже заданного узла в иерархии, включая сам узел. Обратите внимание, что с помощью рекурсии можно легко обрабатывать деревья произвольной глубины.
Если необходимо получить только прямых детей узла, то можно ограничить запрос до первого уровня иерархии:
SELECT id, name FROM nodes WHERE parent_id = 1;
Для поиска пути от любого узла до корня дерева используется обратный обход. Пример запроса для нахождения пути от узла до корня:
WITH RECURSIVE path AS ( SELECT id, parent_id, name FROM nodes WHERE id = 5 -- Узел, от которого строим путь UNION ALL SELECT n.id, n.parent_id, n.name FROM nodes n JOIN path p ON n.id = p.parent_id ) SELECT * FROM path;
Этот запрос строит путь от узла с `id = 5` до самого верхнего уровня, пока не будет достигнут узел с `parent_id = NULL`.
Кроме того, для оптимизации поиска и обхода деревьев данных рекомендуется индексировать столбцы `parent_id`, что значительно ускоряет выполнение запросов на поиск дочерних узлов. Например:
CREATE INDEX idx_parent_id ON nodes(parent_id);
Для работы с большими деревьями данных можно также использовать методы денормализации, где каждый узел содержит дополнительную информацию о всех своих предках или потомках, что упрощает некоторые операции, но требует дополнительных затрат на обновление данных.
Вопрос-ответ:
Что такое деревья данных и зачем они нужны в базе данных SQL?
Деревья данных — это структуры, которые позволяют эффективно организовывать и хранить информацию в виде иерархии. Например, это могут быть семейные деревья, категории продуктов или организационные схемы. В SQL деревья данных могут быть использованы для моделирования связей между записями, что упрощает поиск, добавление и удаление информации, которая зависит от других данных. Такой подход позволяет уменьшить избыточность и упростить работу с иерархическими структурами.
Какие способы хранения деревьев данных существуют в SQL?
В SQL существует несколько способов хранения деревьев данных. Один из них — это использование таблицы с родительским идентификатором (adjacency list model), где каждый элемент хранит ссылку на своего родителя. Другой подход — использование моделей с префиксами (path enumeration model) или с вложенными множествами (nested set model). Эти методы различаются по сложности запросов и производительности. Например, модель с вложенными множествами позволяет эффективно извлекать поддеревья, но сложнее в обновлении данных, чем модель с родительским идентификатором.
Как хранение деревьев данных влияет на производительность запросов в SQL?
Производительность запросов зависит от выбранного способа хранения деревьев. Например, модель с родительским идентификатором проста в реализации, но может требовать выполнения множества запросов для извлечения поддеревьев, что снижает производительность. В свою очередь, модель с вложенными множествами позволяет быстрее извлекать и обновлять поддеревья, однако её сложность при добавлении и удалении элементов может привести к замедлению работы с данными. Важно выбирать метод в зависимости от специфики задач и требований к производительности.
Как обрабатывать изменения в структуре дерева данных, например, при добавлении или удалении узлов?
При добавлении или удалении узлов в дереве данных важно учитывать выбранную модель хранения. Например, при использовании модели с родительским идентификатором достаточно обновить ссылку на родителя для нового элемента или для удалённого узла. В случае модели с вложенными множествами такие операции могут потребовать перерасчёта значений для множества элементов, что усложняет обновления. Модели с префиксами и путь-энумерацией также могут потребовать дополнительных вычислений при изменении структуры, например, перестановки значений или обновления целых поддеревьев.