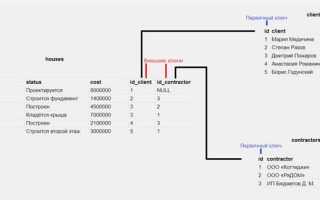
SQL-системы управления базами данных (СУБД) используют четкую и стандартизированную структуру для хранения данных. Каждая строка в таблице представляет собой запись, состоящую из различных полей, которые соответствуют конкретным атрибутам объекта. Важно, чтобы структура данных была спроектирована таким образом, чтобы поддерживать эффективное извлечение, обновление и удаление информации.
Основой хранения данных в SQL является использование таблиц, которые организуют данные в строки и столбцы. Каждая таблица имеет уникальное имя и состоит из колонок, каждая из которых содержит данные одного типа. Для обеспечения целостности данных применяются ограничения, такие как первичные ключи (primary keys), которые уникально идентифицируют записи, и внешние ключи (foreign keys), связывающие таблицы друг с другом. Применение этих ограничений гарантирует, что данные остаются консистентными при добавлении, удалении или изменении информации.
Каждый тип данных в SQL имеет свои особенности хранения. Например, строковые типы, такие как CHAR и VARCHAR, различаются по подходу к управлению памятью. CHAR фиксирован по длине, что может приводить к неэффективному использованию памяти при хранении коротких строк, тогда как VARCHAR позволяет экономить пространство, подстраиваясь под длину данных. Кроме того, для числовых данных применяются различные типы, включая INT, DECIMAL, FLOAT, каждый из которых подходит для разных типов вычислений и хранения значений.
При проектировании структуры базы данных необходимо учитывать как логическую, так и физическую организацию данных. Для повышения производительности часто используется индексация, которая ускоряет поиск записей, но требует дополнительных ресурсов при изменении данных. Также важным аспектом является нормализация, процесс разбиения данных на более мелкие таблицы с минимизацией избыточности и максимизацией их целостности. Однако важно не перестараться с нормализацией, так как слишком высокая степень может привести к ухудшению производительности из-за увеличения количества соединений между таблицами.
Как правильно выбрать типы данных для столбцов в SQL
Основное правило при выборе типа данных – учитывать характеристики данных, которые будут храниться в столбце. Необходимо точно определить, что за данные будут храниться в базе, чтобы выбрать наиболее подходящий тип. Вот основные факторы, которые влияют на этот выбор:
- Объем данных. Использование более широких типов данных для хранения меньших значений – это неэффективно. Например, для хранения флагов (да/нет) лучше использовать тип данных
BOOLEAN, а неCHAR(1)илиINT. - Точность и диапазон чисел. Для хранения денежных значений лучше использовать
DECIMALилиNUMERIC, так как они позволяют задать точность. Если точность не требуется, можно использоватьFLOATилиREAL, но будьте осторожны с округлением. - Производительность. Использование более компактных типов данных, таких как
INTвместоBIGINTдля числовых значений, может существенно улучшить производительность. Точные типы данных обеспечивают меньшую нагрузку на систему хранения и ускоряют обработку данных. - Семантика данных. Для даты и времени используйте
DATEилиDATETIME, а не строковые типы данных, чтобы избежать ошибок при обработке и запросах. ТипыVARCHARиTEXTприменимы для строковых данных, но при этом важно учитывать максимальную длину строк. - Совместимость и переносимость. При проектировании базы данных важно учесть, как выбранный тип данных будет взаимодействовать с другими системами. Например, типы
UUIDилиCHARчасто используются для совместимости с различными платформами.
Необходимость оптимизации хранимых данных также следует учитывать при выборе типа данных. Например, вместо использования строковых типов данных для хранения чисел или дат следует выбрать соответствующие типы, которые позволяют базе данных эффективно индексировать и обрабатывать эти данные. Это не только улучшит производительность запросов, но и уменьшит нагрузку на систему хранения.
Важно помнить, что оптимальный выбор типов данных зависит от конкретной задачи. Например, если в базе данных необходимо хранить большие текстовые блоки (например, статьи или описания), стоит использовать тип TEXT, а не VARCHAR, поскольку он оптимизирован для больших объемов данных. В то же время для хранения адресов электронной почты, телефонных номеров или URL-адресов будет достаточно более компактного типа VARCHAR.
Наконец, не забывайте, что точность и совместимость с другими системами – это не все аспекты. Важно также учитывать производительность на различных этапах работы с данными: при вставке, обновлении и извлечении. Например, использование индексов с типами данных, которые лучше подходят для поиска (например, INT или DATE), может значительно ускорить выполнение запросов.
Роль индексов в структуре хранения данных SQL
Индексы в SQL играют ключевую роль в оптимизации запросов, влияя на производительность системы хранения данных. Они представляют собой структуры данных, которые ускоряют поиск и извлечение информации из таблиц. Индекс хранит копию значений одного или нескольких столбцов и позволяет эффективно производить поиск, сортировку и фильтрацию данных.
Основной тип индекса в SQL – это B-деревья, которые обеспечивают логарифмическую сложность поиска (O(log n)). Они активно используются для поиска данных в больших таблицах, где полное сканирование данных заняло бы слишком много времени. Индексы можно создавать на одном столбце (одноколоночные) или на нескольких столбцах (составные индексы). Важно помнить, что добавление индекса улучшает скорость SELECT-запросов, но может замедлить операции вставки (INSERT), обновления (UPDATE) и удаления (DELETE), так как индексы требуют синхронизации с данными таблицы.
Оптимизация индексов начинается с правильного выбора столбцов для индексации. Индексы следует создавать на столбцах, которые часто участвуют в условиях WHERE, JOIN, ORDER BY. Однако создание индексов на столбцах с низкой кардинальностью (мало уникальных значений) не дает значительного прироста производительности и может только увеличить нагрузку на систему.
В SQL существуют различные типы индексов: уникальные, полнотекстовые и пространственные. Уникальные индексы гарантируют, что значения в индексируемых столбцах будут уникальными. Полнотекстовые индексы предназначены для быстрого поиска по текстовым данным, а пространственные – для работы с географическими данными. Каждый тип индекса применим в зависимости от конкретной задачи и типа данных, с которыми работают.
Также стоит учитывать стратегию хранения индексов. В зависимости от базы данных индексы могут храниться отдельно от таблиц или быть встроенными в структуру таблицы. Для хранения индексов часто используется отдельная структура данных (например, в MySQL – это таблицы типа InnoDB), что позволяет разделить операции поиска и манипуляции с данными, тем самым повышая общую эффективность.
При проектировании структуры индексов важно не только учитывать характеристики таблиц, но и следить за тем, чтобы количество индексов не превышало разумные пределы. Избыточное количество индексов увеличивает время на их обновление и потребление ресурсов системы. Рекомендуется периодически проводить анализ производительности и при необходимости пересматривать существующие индексы.
Особенности нормализации и денормализации данных в базе данных
Нормализация данных – процесс организации данных в базе с целью минимизации избыточности и предотвращения аномалий при обновлении, удалении и вставке информации. В SQL нормализация осуществляется с помощью разбиения таблиц на более мелкие и логично связанные сущности, с использованием ключей для поддержания целостности данных. Нормализация проводится через несколько форм, начиная с первой (1NF), которая требует, чтобы все атрибуты в таблице были атомарными, и заканчивая пятой (5NF), где таблица полностью разделена на независимые и логически обоснованные компоненты.
Денормализация, напротив, заключается в объединении таблиц или добавлении избыточных данных с целью улучшения производительности при запросах. Она используется, когда важна скорость чтения и анализа данных, а не их идеальная структура. Этот процесс может потребовать принятия решений о компромиссах между целостностью данных и эффективностью работы системы.
Решение о нормализации или денормализации следует принимать, исходя из конкретных задач и требований к базе данных. Нормализованные базы данных проще поддерживать и обновлять, так как изменение информации происходит в одном месте, минимизируя вероятность ошибок. Однако для сложных запросов с множественными соединениями между таблицами нормализованные структуры могут работать медленно из-за необходимости частых объединений таблиц. В этом случае денормализация позволяет избежать дорогостоящих операций соединения, ускоряя выполнение запросов.
Пример: если система обработки заказов требует частого извлечения полной информации о заказах с деталями товаров, денормализация может включать хранение информации о товаре непосредственно в таблице заказов. Это уменьшает время на выполнение запросов, но увеличивает риск возникновения аномалий, таких как несогласованность данных при изменении информации о товаре.
При денормализации важно соблюдать баланс, чтобы избыточность данных не превратилась в источник проблем с консистентностью. В некоторых случаях полезно использовать кеширование результатов сложных запросов или создание индексов, чтобы уменьшить нагрузку на систему.
Совмещение нормализации и денормализации в базе данных может быть эффективным подходом: нормализованные данные хранятся в основном хранилище, а денормализованные – в специализированных таблицах для ускорения конкретных операций. Это дает возможность оптимизировать работу системы и снизить риски потери целостности данных.
Как организовать связи между таблицами в SQL
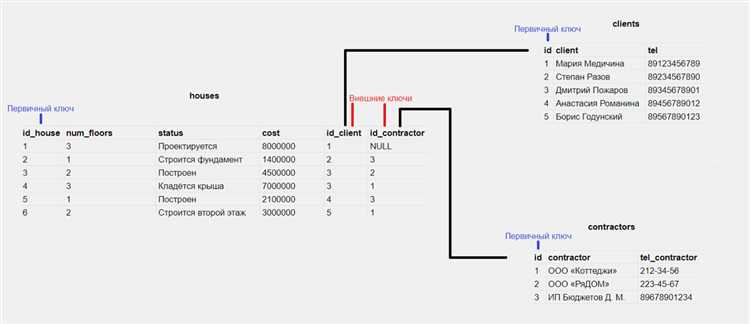
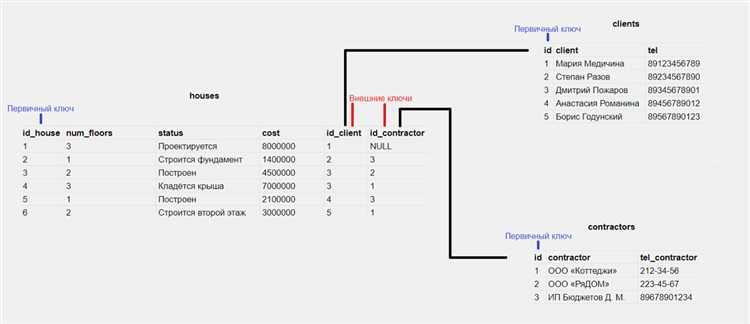
Организация связей между таблицами в SQL позволяет создать структурированные базы данных, которые эффективно обрабатывают взаимосвязанные данные. Основные типы связей включают один к одному, один ко многим и многие ко многим. Рассмотрим, как правильно их реализовать.
Для связи «один к одному» необходимо использовать внешний ключ (FOREIGN KEY), который ссылается на первичный ключ (PRIMARY KEY) другой таблицы. Эта связь используется редко, но она может быть полезна, когда нужно разделить информацию, которая относится к одному объекту, но должна храниться в разных таблицах для улучшения организации или безопасности данных.
Пример связи «один к одному»: таблица «Пользователи» может содержать основной профиль пользователя, а таблица «Паспортные данные» может содержать дополнительные сведения о пользователе. Внешний ключ в таблице «Паспортные данные» будет ссылаться на первичный ключ таблицы «Пользователи».
Связь «один ко многим» является одной из самых распространённых. Для её реализации также используется внешний ключ, но теперь одна запись в родительской таблице может иметь несколько соответствующих записей в дочерней таблице. Например, таблица «Клиенты» может иметь связь с таблицей «Заказы», где один клиент может сделать несколько заказов.
Для этого в таблице «Заказы» добавляется внешний ключ, который ссылается на первичный ключ таблицы «Клиенты». Это позволяет эффективно связывать заказы с конкретным клиентом, сохраняя структуру данных без дублирования информации.
Связь «многие ко многим» требует создания промежуточной таблицы, которая будет хранить внешние ключи обеих сторон связи. Например, таблица «Студенты» может быть связана с таблицей «Курсы», где один студент может проходить несколько курсов, а один курс может быть посещён множеством студентов. Для реализации такой связи создаётся таблица «Студенты_Курсы», в которой хранятся два внешних ключа: один к таблице «Студенты», другой к таблице «Курсы».
Важно помнить, что при создании связей необходимо учитывать целостность данных. Использование каскадных операций (CASCADE) для обновлений или удалений может значительно упростить поддержку целостности, но при этом требует внимательного подхода, чтобы избежать нежелательных изменений в связанных таблицах.
Также следует учитывать индексирование внешних ключей для улучшения производительности запросов, особенно в больших базах данных. Индексы на внешних ключах позволяют ускорить поиск и выполнение операций с данными, что критично для поддержания скорости работы системы.
Использование транзакций для обеспечения целостности данных
Атомарность гарантирует, что все операции транзакции выполняются полностью или не выполняются вовсе. Это важный аспект для обеспечения целостности данных, так как в случае сбоя системы после выполнения части операций, все изменения откатываются, предотвращая частично обновленные или неконсистентные данные. Примером может служить операция перевода денег между счетами. Если процесс перевода был прерван, система откатит изменения, чтобы избежать некорректного состояния баланса.
Консистентность предполагает, что транзакция переводит базу данных из одного согласованного состояния в другое. Это важно для сохранения бизнес-правил и логики работы приложения. Например, если при транзакции происходит нарушение целостности данных (например, попытка сохранить значение, которое выходит за пределы допустимого диапазона), операция откатывается, и база данных остается в целостном состоянии.
Изолированность определяет, что каждая транзакция выполняется независимо от других. Это предотвращает ситуации, когда параллельно выполняющиеся транзакции могут повлиять на друг друга, создавая некорректные данные. Режим изолированности в SQL можно настроить с помощью различных уровней, таких как Read Uncommitted, Read Committed, Repeatable Read и Serializable, которые контролируют степень видимости изменений другими транзакциями.
Долговечность гарантирует, что изменения, внесенные в базе данных в рамках завершенной транзакции, сохраняются даже в случае сбоя системы. Это реализуется через механизмы журналирования и резервного копирования, которые позволяют восстанавливать данные в случае падения системы, не потеряв при этом информации о завершенных транзакциях.
Для реализации транзакций в SQL используется оператор BEGIN TRANSACTION для начала транзакции и COMMIT для ее завершения. В случае ошибок можно использовать ROLLBACK для отката изменений. Например, в случае ошибочного обновления данных можно откатить транзакцию, и изменения не будут сохранены в базе данных.
Практическое использование транзакций также требует правильной настройки уровня изолированности. Например, для систем с высоким параллелизмом и большими объемами данных может быть целесообразно использовать уровень Repeatable Read для предотвращения фантомных чтений, в то время как для приложений, где важна скорость, можно применить уровень Read Committed, чтобы уменьшить блокировки.
Правильная настройка транзакций в SQL позволяет не только обеспечить целостность данных, но и повысить общую производительность системы, минимизируя блокировки и улучшая управление конкурентными запросами.
Как оптимизировать запросы к данным с помощью структуры таблиц
Оптимизация запросов в SQL начинается с правильного проектирования структуры таблиц. Эффективная организация данных способствует уменьшению времени выполнения запросов и повышению производительности базы данных. Несоответствующая структура может привести к избыточным вычислениям, блокировкам и долгим задержкам.
Первым шагом является нормализация данных. Разделение информации на несколько таблиц позволяет избежать дублирования данных и уменьшить объемы операций с ними. Например, если таблица содержит информацию о клиентах и их заказах, стоит выделить отдельные таблицы для клиентов и заказов, связав их через ключи. Это позволит сократить объем данных, который обрабатывается при выполнении запросов, и улучшить индексирование.
Однако чрезмерная нормализация может привести к излишнему числу соединений (JOIN), что замедляет выполнение запросов. В таких случаях следует применить денормализацию, то есть избыточное хранение данных, чтобы уменьшить количество соединений. Например, для часто выполняемых запросов можно хранить агрегированные данные, такие как суммы или средние значения, в самих таблицах.
Для ускорения поиска по таблицам важным шагом является использование индексов. Индексы позволяют значительно ускорить выполнение запросов, особенно при поиске по полям, часто используемым в WHERE или JOIN условиях. Однако следует учитывать, что избыточное количество индексов может замедлить операции вставки, обновления и удаления данных, поскольку индексы нужно поддерживать в актуальном состоянии. Рекомендуется индексировать только те столбцы, которые часто используются для фильтрации или сортировки данных.
Хорошо продуманные первичные и внешние ключи важны для обеспечения целостности данных и правильной работы индексов. Например, таблица с заказами должна содержать внешний ключ, который ссылается на таблицу клиентов, что упрощает объединение данных и обеспечивает их логическую согласованность. Также следует использовать подходящие типы данных для столбцов, чтобы минимизировать объем хранимых данных и ускорить обработку запросов.
При проектировании таблиц важно учитывать типы запросов, которые будут выполняться чаще всего. Для операций поиска и выборки данных следует использовать структуры, которые минимизируют количество ненужных сканирований таблиц. В случае часто обновляемых данных следует предпочесть таблицы с меньшими размерами и менее сложной структурой, чтобы ускорить операции записи.
Для частых выборок данных можно использовать партиционирование таблиц, которое позволяет разбивать большие таблицы на логические части, улучшая производительность запросов. Например, таблицу заказов можно разбить на партиции по датам, что ускорит выполнение запросов, связанных с выборкой данных за определенный период времени.
Кроме того, для сложных запросов с множественными JOIN-ами или подзапросами можно использовать материализованные представления. Они позволяют заранее сохранить результат сложных операций и ускорить выполнение запросов, которые часто выполняются в неизменном виде.
Оптимизация запросов через структуру таблиц – это не разовая задача, а процесс, который требует регулярного мониторинга и настройки в зависимости от изменения объема данных и частоты запросов. Важно периодически пересматривать индексы, нормализацию и денормализацию данных, чтобы поддерживать баланс между производительностью и масштабируемостью системы.
Управление большими объемами данных в SQL: методы и подходы
Работа с большими объемами данных в SQL требует применения специфичных методов и подходов для обеспечения производительности и эффективности обработки. Основными задачами становятся оптимизация скорости запросов, управление ресурсами и поддержание целостности данных при масштабировании. Рассмотрим ключевые методы для управления большими объемами данных в SQL.
Первый подход – использование индексов. Индексы значительно ускоряют выполнение запросов, но их неправильное использование может привести к увеличению времени на обновление данных и повышению нагрузки на систему. Важно правильно выбирать типы индексов, например, B-tree для поиска по диапазонам или Hash-индексы для равенства. Рекомендуется индексировать только те столбцы, которые активно используются в условиях поиска и сортировки.
Второй метод – партиционирование таблиц. Партиционирование помогает разделить большие таблицы на более мелкие части, что снижает время поиска и улучшает управление данными. В зависимости от нагрузки, можно использовать горизонтальное (по значениям в строках) или вертикальное (по столбцам) партиционирование. Также важно учитывать стратегию партиционирования при масштабировании базы данных, чтобы избежать перераспределения данных, что может привести к значительным затратам времени.
Третий подход – нормализация и денормализация данных. Нормализация позволяет избежать избыточности и упрощает обновления, однако при очень больших объемах данных нормализованные таблицы могут сильно увеличивать количество операций с джойнами. В таких случаях может быть полезной денормализация, которая помогает снизить нагрузку на систему за счет уменьшения количества объединений таблиц, но при этом увеличивает объем данных для хранения.
Четвертый метод – использование шардирования. Шардирование заключается в разделении данных между несколькими серверами или базами данных, что позволяет распределить нагрузку. Важно тщательно спланировать стратегию шардирования, чтобы избежать излишней сложности при запросах, а также контролировать целостность данных при распределении их между несколькими узлами.
Пятый подход – кэширование. Использование кэширования результатов запросов в памяти позволяет значительно сократить время отклика системы при многократных запросах к одним и тем же данным. Это особенно актуально для часто запрашиваемых данных, таких как справочники или статистика. Однако кэширование требует внимательного управления сроком хранения и актуальностью данных.
Шестой метод – архивирование и удаление старых данных. С течением времени некоторые данные теряют свою актуальность и становятся несущественными для текущих операций. В таких случаях рекомендуется архивировать данные в отдельные хранилища или удалять их, если они больше не нужны для работы системы. Это помогает снизить нагрузку на основную базу данных и улучшить её производительность.
Вопрос-ответ:
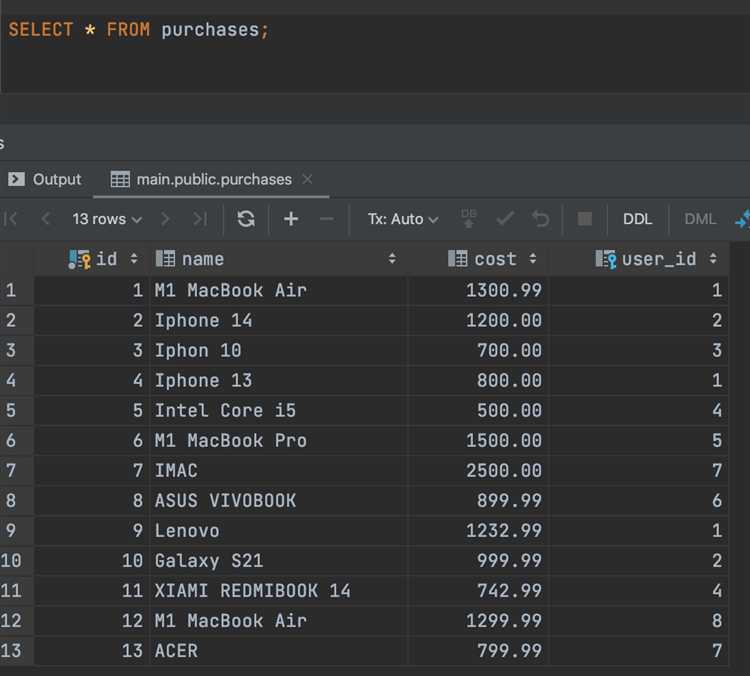
Что собой представляет структура хранения данных в SQL?
Структура хранения данных в SQL обычно включает несколько основных компонентов. Это таблицы, состоящие из строк и столбцов, где каждая строка представляет собой отдельную запись, а столбец — конкретное поле данных. Таблицы могут быть связаны друг с другом через ключи — первичные и внешние. Первичный ключ уникален для каждой записи в таблице, а внешний ключ связывает данные из разных таблиц. Структура данных может быть дополнена индексами, которые ускоряют поиск и сортировку, а также представлениями, которые служат для отображения данных из нескольких таблиц в одном запросе.
Какие типы данных можно хранить в SQL?
В SQL существует множество типов данных, которые могут быть использованы для хранения различных видов информации. Основные типы данных включают числовые (например, INT, DECIMAL), символьные (VARCHAR, CHAR), а также типы для хранения дат и времени (DATE, DATETIME). Кроме того, можно хранить бинарные данные (например, BLOB), а также специализированные типы для работы с текстом (TEXT) или для работы с географической информацией (например, GEOMETRY). Каждый тип данных используется в зависимости от того, какой вид данных предполагается хранить в столбце.
Как индексирование влияет на хранение данных в SQL?
Индексирование в SQL позволяет ускорить поиск данных в таблицах. Индексы представляют собой структуры, которые хранят упорядоченную информацию о значениях столбцов, что помогает уменьшить время, необходимое для выполнения запросов, особенно на больших объемах данных. Однако создание индексов требует дополнительных ресурсов на этапе записи данных, поскольку каждый раз, когда в таблицу добавляются новые записи или обновляются старые, индексы должны быть обновлены. Поэтому важно найти баланс между количеством индексов и производительностью системы в целом.
Что такое нормализация данных в SQL и зачем она нужна?
Нормализация данных в SQL — это процесс структурирования базы данных таким образом, чтобы минимизировать избыточность и зависимость между данными. Нормализация включает разделение данных на несколько связанных таблиц и создание связей между ними. Цель этого процесса — избежать дублирования информации, повысить согласованность данных и упростить их обновление. На практике нормализация помогает избежать ошибок, связанных с хранением одних и тех же данных в нескольких местах, и облегчает выполнение операций с данными, таких как добавление, изменение или удаление.