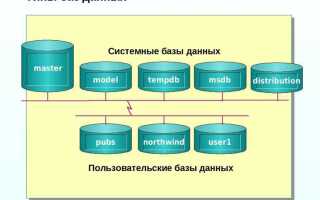
Выбор типа SQL базы данных оказывает прямое влияние на архитектуру, производительность и масштабируемость приложений. Разные СУБД реализуют стандарт SQL с уникальными расширениями и механизмами хранения данных. Это требует точного понимания их различий на этапе проектирования системы.
PostgreSQL – объектно-реляционная СУБД с поддержкой расширяемых типов данных, полнотекстового поиска и JSONB-структур. Оптимальна для систем, где необходима сложная логика обработки данных и строгая ACID-совместимость. Идеально подходит для аналитических систем, ERP и решений, требующих строгой транзакционности.
MySQL и MariaDB предлагают высокую скорость обработки запросов и простую репликацию. Они широко используются в веб-разработке, особенно в связке с PHP-приложениями. InnoDB как основной тип хранения обеспечивает транзакции и внешние ключи, что делает их пригодными не только для чтения, но и для рабочих нагрузок с интенсивной записью.
SQL Server от Microsoft предоставляет тесную интеграцию с экосистемой .NET и поддерживает расширенные функции безопасности, масштабируемости и анализа. Подходит для корпоративных решений, где важны инструменты BI, хранимые процедуры на T-SQL и интеграция с Windows Server.
Oracle Database ориентирована на крупные предприятия с высокими требованиями к надежности, вертикальному масштабированию и автоматизации. Отличается сложной лицензией и высокой стоимостью владения, но предлагает уникальные возможности – например, Flashback и автоматическую настройку производительности.
При выборе SQL СУБД необходимо учитывать не только текущие потребности, но и перспективу масштабирования, совместимость с фреймворками и доступность специалистов для поддержки выбранного решения.
Когда выбирать реляционную базу данных и какие задачи она решает
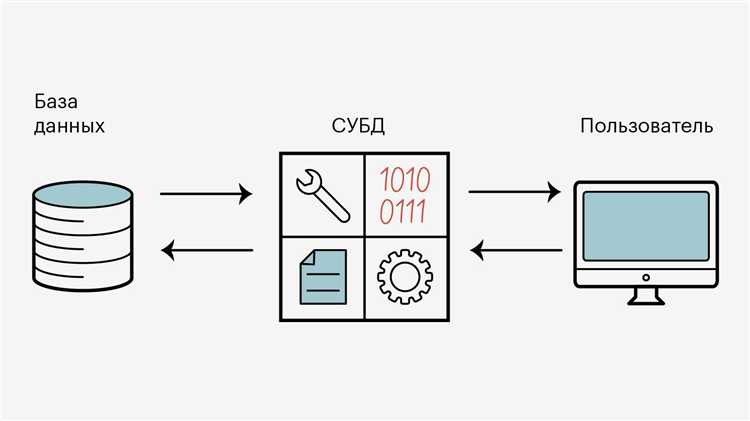
Реляционные базы данных подходят для систем, где данные строго структурированы, а связи между сущностями имеют первостепенное значение. Они обеспечивают атомарность, согласованность, изоляцию и долговечность (ACID), что критично для бизнес-приложений с высокой требовательностью к целостности данных.
- Финансовые системы. Банковские операции, учёт платежей, расчёты налогов требуют точных транзакций, которые невозможно реализовать надёжно без ACID-свойств.
- ERP и CRM-системы. Управление отношениями с клиентами, товарами, заказами предполагает сложные связи и необходимость выполнения запросов с множественными соединениями (JOIN).
- Системы бронирования. Авиабилеты, отели, аренда автомобилей – все эти задачи предполагают контроль за доступностью ресурсов и избежание конфликтов при параллельных операциях.
- Электронная коммерция. Отслеживание заказов, запасов, платежей и возвратов требует надёжного хранения и управления взаимосвязанными данными.
Выбор реляционной СУБД оправдан, когда структура данных предсказуема, схема заранее известна, а изменения происходят редко. SQL-запросы позволяют гибко обрабатывать данные, а строгая типизация и индексация ускоряют выборку и валидацию.
Реляционные СУБД, такие как PostgreSQL, MySQL, Oracle, обеспечивают надежную поддержку транзакций, масштабируемость в пределах одного узла, а также зрелую экосистему инструментов для администрирования, резервного копирования и репликации.
Если проект требует аналитической обработки, агрегации по множеству параметров и отчётности в реальном времени – реляционная модель обеспечивает оптимальные средства для реализации этих задач через представления, хранимые процедуры и триггеры.
Особенности работы с MySQL при разработке веб-приложений

MySQL – один из наиболее популярных выборов при создании веб-приложений, особенно в связке с PHP и фреймворками типа Laravel или Symfony. Однако эффективность работы с MySQL напрямую зависит от учета ряда технических нюансов.
При проектировании структуры базы данных важно сразу определить тип хранения таблиц. MyISAM подходит для операций чтения, но не поддерживает транзакции. InnoDB – предпочтительный выбор для веб-приложений благодаря поддержке ACID-свойств, блокировке на уровне строк и внешним ключам. Использование InnoDB обеспечивает целостность данных при высокой конкурентной нагрузке.
Оптимизация запросов критична. Используйте EXPLAIN для анализа SELECT-запросов, чтобы избежать сканирования всей таблицы. Индексация по полям, используемым в условиях WHERE, JOIN и ORDER BY, значительно ускоряет выполнение. Однако чрезмерное количество индексов снижает производительность операций INSERT и UPDATE.
Необходимо контролировать количество соединений с базой. Для этого настройте пул соединений в используемом сервере приложений (например, через PDO или Doctrine). Это особенно актуально при большом числе одновременных пользователей.
Безопасность – отдельный приоритет. Ограничивайте права доступа к базе: приложению не требуется доступ к DROP или ALTER. Используйте подготовленные выражения (prepared statements) для предотвращения SQL-инъекций, особенно при работе с пользовательским вводом.
Репликация и бэкапы должны быть интегрированы в архитектуру приложения. Настройка master-slave репликации позволяет разгрузить основной сервер, распределив чтение между репликами. Для резервного копирования используйте утилиты вроде `mysqldump` или `mysqlpump`, настраивая регулярные автоматические задачи через cron.
Для масштабируемости применяйте горизонтальное шардирование или промежуточные кеши (Redis, Memcached) при работе с часто запрашиваемыми, но редко изменяемыми данными. Это снижает нагрузку на MySQL и повышает отклик приложения.
Преимущества PostgreSQL для обработки сложных запросов и аналитики
Расширенные возможности SQL: PostgreSQL поддерживает оконные функции, рекурсивные CTE, подзапросы в любом месте выражения и пользовательские агрегатные функции. Это позволяет строить вложенные аналитические запросы без необходимости использования внешних инструментов.
Оптимизатор запросов: Планировщик PostgreSQL эффективно работает с многосложными запросами благодаря анализу стоимости выполнения, поддержке параллельного выполнения операций и индексам выражений. Это особенно важно при работе с отчётами и сводной аналитикой на больших объёмах данных.
Поддержка JSON и JSONB: Хранение и обработка полуструктурированных данных возможна без потери производительности. JSONB индексируется с помощью GIN-индексов, что ускоряет фильтрацию и агрегации по вложенным полям.
Интеграция с расширениями: Расширение pg_stat_statements позволяет детально анализировать частоту и стоимость выполнения запросов. PostGIS предоставляет полноценную поддержку геоаналитики. TimescaleDB оптимизирует хранение и обработку временных рядов.
Материализованные представления: Позволяют кэшировать результаты тяжёлых аналитических запросов с последующим обновлением по расписанию. Это существенно снижает нагрузку на систему при многократных обращениях к одним и тем же данным.
Гибкость масштабирования: Поддержка логической репликации, шардинга через расширение Citus и параллельной обработки делает PostgreSQL подходящим решением для распределённой аналитики без перехода на NoSQL-архитектуры.
Надёжность транзакций: MVCC (многоверсионность) позволяет обрабатывать аналитические запросы без блокировок данных, что критично для систем с высокой конкурентной нагрузкой.
Роль Microsoft SQL Server в корпоративных системах и интеграции с продуктами Microsoft
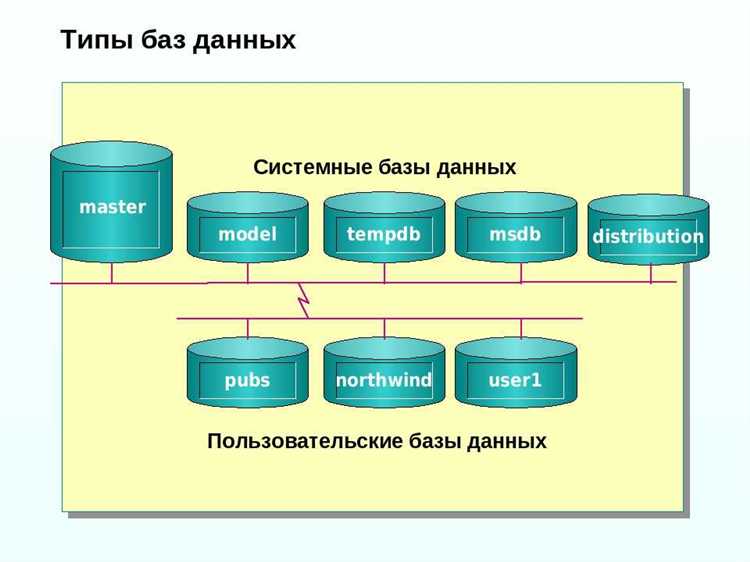
Microsoft SQL Server используется в корпоративных инфраструктурах благодаря тесной интеграции с экосистемой Microsoft и высокой совместимости с бизнес-приложениями. Он оптимизирован для работы с Active Directory, что обеспечивает централизованное управление доступом и поддержку политик безопасности на уровне домена.
В связке с Microsoft Power BI SQL Server выступает как высокопроизводительный источник данных. Использование DirectQuery и Analysis Services позволяет строить отчёты в реальном времени без необходимости экспорта данных.
Интеграция с Microsoft Excel реализована через надстройки Power Pivot и встроенные коннекторы OLE DB/ODBC. Это даёт возможность бизнес-аналитикам без знаний SQL выполнять агрегации и анализ больших объёмов данных напрямую из Excel, подключаясь к кубам или табличным моделям SQL Server.
Для автоматизации бизнес-процессов используется SQL Server Integration Services (SSIS) – ETL-платформа, тесно связанная с Visual Studio. Она поддерживает извлечение данных из Exchange, SharePoint и других Microsoft-сервисов, обеспечивая централизованную обработку.
С помощью SQL Server Reporting Services (SSRS) создаются отчёты, интегрированные в Microsoft Teams, Outlook и SharePoint. Это позволяет внедрять отчётность прямо в корпоративные коммуникационные среды.
Развёртывание SQL Server в Azure (в вариантах Azure SQL Database и Managed Instance) упрощает гибридные сценарии. Это включает миграцию с on-premise, масштабирование под нагрузки и резервное копирование через облачные сервисы Microsoft без необходимости в сторонних решениях.
Для DevOps-интеграции Microsoft предлагает SQL Server Data Tools (SSDT) и поддержку CI/CD в Azure DevOps. Это позволяет синхронизировать схемы баз данных, выполнять миграции и тесты на каждом этапе разработки.
SQL Server поддерживает Row-Level Security, Transparent Data Encryption, Always Encrypted, соответствуя требованиям GDPR и ISO 27001. Это критично для предприятий, работающих в регулируемых отраслях и использующих Microsoft Purview для аудита и классификации данных.
Чем отличается Oracle Database в контексте высоконагруженных систем

Oracle Database выделяется в высоконагруженных средах благодаря архитектуре Real Application Clusters (RAC), обеспечивающей горизонтальное масштабирование и отказоустойчивость. RAC позволяет одновременно использовать несколько серверов для одного экземпляра базы данных, распределяя нагрузку и устраняя единичную точку отказа.
Механизм Advanced Queuing и интеграция с Oracle Streams обеспечивают высокоэффективную обработку асинхронных событий и репликацию в реальном времени, что критически важно для систем с миллионами транзакций в сутки.
Функция In-Memory Database позволяет ускорить аналитические запросы за счёт хранения данных в формате колонок в оперативной памяти, что увеличивает производительность в десятки раз при анализе больших массивов данных без изменения приложений.
Oracle Data Guard обеспечивает автоматическое переключение на резервные узлы с минимальной задержкой, поддерживая непрерывную доступность даже при сбоях оборудования или ЦОДов. В сочетании с Flashback Database возможно мгновенное восстановление к состоянию до логической ошибки или некорректного обновления.
Индексы типа Bitmap, Partitioning и оптимизированный планировщик запросов позволяют точно управлять выполнением запросов и эффективно использовать ресурсы процессора и памяти, снижая латентность в пиковые часы нагрузки.
Поддержка IOPS-ориентированных хранилищ (например, Exadata) и сжатие данных на уровне хранения минимизируют задержки при массовом доступе и обеспечивают предсказуемую производительность даже в условиях постоянной конкуренции за ресурсы.
Для администрирования в реальном времени используется инструмент Oracle Enterprise Manager с возможностью тонкой настройки мониторинга и автоматического реагирования на превышения порогов, что критично для SLA-систем с жёсткими требованиями к отклику.
Использование SQLite в мобильной разработке и локальных хранилищах
SQLite применяется в Android и iOS как встроенное решение для хранения структурированных данных без необходимости подключения к серверу. Размер библиотеки не превышает 1 МБ, что делает её оптимальной для мобильных приложений, где важен контроль над ресурсами.
База данных хранится в одном файле, что упрощает её резервное копирование и перенос между устройствами. Поддержка транзакций, ограничений целостности и индексов позволяет использовать SQLite не только для кэширования, но и для работы с критически важными данными.
На Android SQLite интегрирована через класс SQLiteOpenHelper, который управляет созданием, обновлением и доступом к базе. В iOS взаимодействие реализуется через фреймворк Core Data или прямые вызовы C API.
Производительность зависит от структуры индексов и частоты операций записи. Для оптимизации рекомендуется группировать изменения в транзакции, использовать параметризованные запросы и избегать избыточного чтения. Хранение больших бинарных данных (изображений, видео) лучше реализовать вне базы, с сохранением ссылок в таблицах.
SQLite не поддерживает параллельную запись несколькими потоками, поэтому в многопоточном окружении необходима синхронизация на уровне приложения. Также стоит учитывать, что отсутствие шифрования по умолчанию требует использования расширений, таких как SQLCipher, при работе с конфиденциальной информацией.
Как выбрать подходящую SQL СУБД для проекта с учётом объёма данных и команды
При объёмах данных до 10 ГБ целесообразно использовать PostgreSQL или MySQL. Обе СУБД показывают высокую производительность на малых и средних нагрузках. PostgreSQL предпочтительнее при работе со сложными запросами, геоданными и необходимостью соблюдения строгих ACID-требований. MySQL подойдёт при приоритете скорости чтения и более простой структуре данных.
Если объём данных превышает 100 ГБ и растёт, стоит рассмотреть масштабируемые решения. Для горизонтального масштабирования оптимален PostgreSQL в связке с Citus или использование облачных решений вроде Amazon Aurora. При этом необходимо учитывать нагрузку: при высоком числе параллельных соединений (>500) стоит протестировать производительность под конкретные сценарии.
Маленькая команда без опытных администраторов выиграет от использования SQLite на старте проекта или Google Cloud SQL для упрощённого управления. SQLite – без серверной нагрузки, подходит для встраиваемых решений и мобильных приложений. Облачные СУБД снимают необходимость в ручной настройке резервного копирования и масштабирования.
Команды, использующие CI/CD и контейнеризацию, оценят поддержку PostgreSQL и MySQL в Docker и Kubernetes. Для DevOps-подходов важно наличие CLI-инструментов, стабильной поддержки миграций (например, Flyway или Liquibase) и совместимости с ORM-решениями (SQLAlchemy, TypeORM и др.).
Если проект распределённый и предполагает географически разнесённую структуру, рассмотрите YugabyteDB или CockroachDB – они обеспечивают SQL-интерфейс с возможностью горизонтального масштабирования и высокой отказоустойчивостью, но требуют глубокого понимания распределённых систем.
Выбор СУБД должен опираться на конкретные метрики: ожидаемый рост объёма данных, пиковая нагрузка, опыт команды в администрировании, требования к доступности и отказоустойчивости. Игнорирование этих параметров приводит к техническому долгу и затратам на миграцию в будущем.