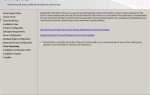
В SQL данные классифицируются по типам, которые определяют формат хранения и способы обработки информации. Эти типы данных обеспечивают правильное функционирование базы данных и оптимизацию запросов. Разделение данных на категории помогает разработчику точно определить, как будут храниться и обрабатываться различные элементы информации, от числовых значений до строковых данных. Знание этих категорий необходимо для эффективной работы с базами данных и повышения производительности приложений.
Основные категории данных включают числовые, строковые, временные и бинарные типы. Каждая из этих категорий имеет свои особенности и области применения. Числовые типы данных, такие как INT, DECIMAL и FLOAT, предназначены для хранения значений, которые поддаются арифметическим операциям. Важно понимать различия между ними, например, в точности и диапазоне возможных значений, чтобы избежать потери данных или неправильных вычислений при работе с большими числами.
Для хранения текстовой информации используются строковые типы данных – CHAR, VARCHAR, TEXT. Выбор между ними зависит от особенностей данных: для фиксированного размера строки лучше использовать CHAR, в то время как VARCHAR идеально подходит для переменной длины текстов. Ошибки в выборе строкового типа могут привести к лишнему расходу памяти или, наоборот, к ошибкам при вставке данных.
Типы данных для хранения времени и даты, такие как DATE, TIME и DATETIME, также имеют значительные различия. Например, если необходимо хранить только дату без времени, стоит выбрать DATE, что позволит сэкономить место и избежать ненужных вычислений.
Наконец, бинарные типы данных (BLOB, VARBINARY) предназначены для хранения больших объемов двоичных данных, таких как изображения и файлы. Эти типы требуют осторожности при манипуляциях с большими объемами данных, чтобы избежать снижения производительности при выполнении запросов.
Целочисленные типы данных: различия между INT и BIGINT

Типы данных INT и BIGINT используются для хранения целых чисел, но различаются диапазоном значений, который они могут содержать. Эти различия важны при проектировании базы данных, так как выбор типа влияет на производительность и объем памяти, занимаемой данными.
Тип INT (или INTEGER) имеет диапазон значений от -2,147,483,648 до 2,147,483,647 для знаковых целых чисел. Этот тип данных используется для большинства приложений, где величины чисел не выходят за пределы указанного диапазона. Например, для хранения количества пользователей, счетчиков или позиций в списках.
Тип BIGINT предназначен для более широких диапазонов целых чисел. Он может хранить значения от -9,223,372,036,854,775,808 до 9,223,372,036,854,775,807. BIGINT используется в случаях, когда предполагаются очень большие числовые значения, такие как идентификаторы в крупных системах или при расчетах с большими объемами данных.
Основные различия:
- Диапазон значений: INT ограничен диапазоном от -2 млрд до 2 млрд, в то время как BIGINT охватывает значения порядка 9 квинтиллионов, что гораздо больше.
- Использование памяти: INT занимает 4 байта, а BIGINT – 8 байт. Таким образом, BIGINT требует больше памяти, что может повлиять на производительность при обработке больших объемов данных.
- Производительность: Операции с INT быстрее, так как они занимают меньше памяти и могут эффективно обрабатываться процессорами с меньшей нагрузкой. В то время как BIGINT, несмотря на большие возможности, может замедлять операции из-за большего объема памяти и меньшей скорости работы с большими числами.
- Использование: INT подходит для большинства стандартных приложений, где значения чисел не превышают несколько миллиардов. BIGINT стоит использовать только в случае, когда ожидаются очень большие числа, например, при хранении уникальных идентификаторов в распределенных системах или в аналитических приложениях с большими объемами данных.
Рекомендуется использовать INT по умолчанию, если нет конкретной необходимости в более широком диапазоне чисел. Это оптимизирует использование памяти и повышает производительность системы. Однако при проектировании баз данных для масштабируемых решений, например, в системах с глобальными идентификаторами или большими вычислениями, предпочтительнее использовать BIGINT, чтобы избежать переполнения значений.
Числовые типы с плавающей запятой: когда использовать FLOAT и DECIMAL

Типы данных с плавающей запятой в SQL (FLOAT и DECIMAL) служат для хранения чисел с дробной частью, однако выбор между ними зависит от конкретных требований к точности и диапазону значений.
FLOAT используется для хранения чисел с плавающей запятой, когда важна экономия памяти и допустима небольшая потеря точности. Этот тип данных эффективен для научных вычислений, статистических данных, а также когда точность на уровне нескольких знаков после запятой не является критичной. FLOAT представляет числа в виде приблизительных значений, что может привести к погрешностям при операциях с очень большими или очень малыми значениями. Стандартная точность FLOAT зависит от реализации, но обычно она составляет от 6 до 15 знаков.
DECIMAL, в отличие от FLOAT, применяется, когда важна высокая точность, особенно для финансовых операций. Этот тип данных сохраняет точность до заданного числа знаков после запятой. DECIMAL идеально подходит для расчетов с деньгами, процентами, а также для любых других данных, где даже малейшая погрешность может быть критичной. Например, при вычислениях с ценами товаров или расчете налогов ошибочные округления могут привести к финансовым потерям. DECIMAL позволяет задавать точность и масштаб, что даёт разработчику контроль над количеством знаков до и после запятой.
Выбор между FLOAT и DECIMAL зависит от того, какая именно точность требуется для данных и какие ограничения по памяти существуют в системе. Если точность важнее, используйте DECIMAL. Если же нужна высокая производительность и допустимы небольшие погрешности, лучше выбрать FLOAT.
Когда необходимо работать с очень большими или маленькими числами, лучше использовать FLOAT, так как его диапазон значений гораздо шире. DECIMAL, в свою очередь, может быть менее эффективным по памяти для работы с числами, не требующими высокой точности.
Типы данных для хранения строк: VARCHAR или TEXT?
При выборе типа данных для хранения строк в SQL часто возникает вопрос: использовать ли VARCHAR или TEXT? Оба типа предназначены для хранения текстовых данных, но их особенности могут значительно повлиять на производительность и удобство работы с базой данных.
VARCHAR (Variable Character) – это тип данных для хранения строк переменной длины. Максимальная длина строки для VARCHAR зависит от ограничения, заданного при создании столбца. Например, VARCHAR(255) ограничивает длину строки до 255 символов. Это позволяет экономить место, так как база данных не будет выделять память на фиксированный размер, а будет использовать только необходимое пространство для каждого значения.
Главное преимущество VARCHAR – возможность задания максимальной длины, что способствует контролю за размером данных. Однако если значение строки превышает заданную длину, возникнет ошибка, и данные не смогут быть вставлены в таблицу.
С другой стороны, TEXT предназначен для хранения строк произвольной длины. Он не имеет ограничений по количеству символов, и это его основное преимущество. TEXT используется для хранения больших объемов данных, например, текстовых документов, комментариев, описаний, и других подобных данных, где длина строки непредсказуема. Однако стоит отметить, что в некоторых СУБД данные типа TEXT могут обрабатываться несколько медленнее, чем VARCHAR, из-за особенностей хранения и работы с большими объемами текста.
При выборе между VARCHAR и TEXT важно учитывать несколько факторов:
- Размер данных: Если строки, которые будут храниться в базе, имеют ограниченную длину, предпочтительнее использовать VARCHAR. Это обеспечит экономию памяти и улучшит производительность.
- Перформанс: Для кратких строк VARCHAR обычно быстрее, так как СУБД может эффективно управлять их хранением. Для длинных строк с неопределенным размером лучше выбрать TEXT, если не нужно ограничивать длину данных.
- Совместимость с индексами: Строки типа VARCHAR легче индексируются, в отличие от TEXT, где создание индексов на полных текстах может быть ограничено или усложнено.
Таким образом, VARCHAR идеально подходит для данных с известной длиной или ограниченной длиной, в то время как TEXT следует использовать, если нужно хранить длинные текстовые блоки или данные неопределенной длины. Важно также учитывать ограничения вашей СУБД, так как в некоторых случаях тип TEXT может требовать дополнительных настроек для оптимальной работы.
Дата и время в SQL: как выбрать между DATE, TIME и DATETIME
В SQL существует несколько типов данных для хранения значений, связанных с датой и временем: DATE, TIME и DATETIME. Выбор подходящего типа зависит от задач, которые необходимо решить. Каждый из этих типов имеет свои особенности и предназначен для определенных случаев использования.
Тип данных DATE используется для хранения только даты, без времени. Он подходит, когда важен только календарный день, например, для хранения даты рождения, даты события или срока действия документа. Хранение только даты позволяет экономить место в базе данных, если время не нужно. Формат записи: ‘YYYY-MM-DD’.
Тип данных TIME предназначен для хранения времени без даты. Этот тип удобен, когда нужно зафиксировать время события, не привязывая его к конкретному календарному дню. Например, для хранения времени начала или конца рабочего дня. Он использует формат ‘HH:MI:SS’. Если необходимо учесть временную зону, рекомендуется использовать TIMESTAMP WITH TIME ZONE (в некоторых СУБД), так как TIME не поддерживает информацию о временных зонах.
Тип данных DATETIME объединяет дату и время в одном значении. Он необходим, когда требуется точно зафиксировать момент события, включая как день, так и время. Этот тип подходит для хранения времени транзакции, записи логов, отметок времени для событий и т.д. Формат записи: ‘YYYY-MM-DD HH:MI:SS’. Важно отметить, что в некоторых СУБД тип DATETIME может иметь ограничения по точности и диапазону (например, MySQL поддерживает DATETIME с точностью до секунд, но в других СУБД точность может быть выше).
При выборе между этими типами важно учитывать следующие факторы:
- Нужна ли точность до дня или до времени?
- Требуется ли учитывать временные зоны?
- Какую точность в пределах времени вам нужно поддерживать (секунды, миллисекунды)?
Если задача не требует хранения времени, достаточно использовать DATE. Для записи только времени – используйте TIME. Когда необходимо хранить и дату, и время, выбирайте DATETIME, однако учитывайте, что в разных СУБД могут быть небольшие различия в точности и диапазоне этого типа.
Типы данных для хранения булевых значений: BOOLEAN и BIT

В SQL для представления булевых значений используются два типа данных: BOOLEAN и BIT. Эти типы часто применяются для хранения информации о логическом состоянии, таком как «истина» или «ложь». Несмотря на схожесть, они имеют несколько различий в зависимости от СУБД.
Тип данных BOOLEAN предназначен для хранения логических значений, где основными значениями могут быть только два состояния: TRUE (истина) и FALSE (ложь). В некоторых СУБД, таких как PostgreSQL, BOOLEAN является полноценным типом данных, который позволяет эффективно работать с булевыми значениями. Однако в MySQL и других СУБД, BOOLEAN часто реализуется как alias для типа TINYINT(1), где 1 соответствует TRUE, а 0 – FALSE.
BIT представляет собой тип данных, который может хранить бинарные значения. В отличие от BOOLEAN, который оперирует только двумя состояниями, BIT позволяет хранить значения с произвольной длиной в битах. В MySQL, например, можно указать длину BIT (например, BIT(1) или BIT(8)). При использовании BIT(1), значение будет интерпретироваться как логическое, где 0 – это ложь, а 1 – истина. BIT часто используется для оптимизации хранения в случаях, когда требуется сохранить большое количество булевых значений.
При выборе между BOOLEAN и BIT важно учитывать особенности используемой СУБД. Если требуется максимальная совместимость с другими системами, например, с PostgreSQL, предпочтительнее использовать BOOLEAN. Для MySQL и SQL Server, где тип BOOLEAN представлен как TINYINT(1) или где более важна экономия пространства при работе с множеством булевых значений, лучше подойдет BIT.
При хранении булевых значений в больших объемах данных, использование BIT может быть более эффективным, так как позволяет оптимизировать память. Однако важно помнить, что если используется BIT(1), то фактически это не всегда приводит к заметному улучшению производительности, особенно если таких значений немного.
Рекомендации по использованию: если ваша база данных предполагает работу с булевыми значениями, и вам необходимо сохранить читаемость и совместимость с другими системами, предпочтительнее выбирать BOOLEAN. BIT целесообразен, если необходимо хранить данные в компактном формате или работать с большим числом булевых значений в одном поле.
Типы данных для работы с бинарными данными: VARBINARY и BLOB

В SQL для хранения бинарных данных используются два основных типа: VARBINARY и BLOB. Каждый из них имеет свои особенности и применяется в разных сценариях работы с большими объемами бинарной информации, такими как изображения, файлы или другие данные, не предназначенные для хранения в текстовом формате.
VARBINARY – это тип данных, который используется для хранения бинарных данных переменной длины. Он идеально подходит для хранения небольших бинарных объектов, таких как криптографические ключи, пароли или бинарные представления малых файлов. Тип данных VARBINARY определяет максимальный размер в байтах, который может быть сохранен в поле. Например, в MySQL и SQL Server длина VARBINARY может быть до 8,000 байт (или до 2GB в некоторых реализациях).
- Преимущества VARBINARY:
- Экономит пространство при работе с бинарными данными фиксированного размера.
- Предназначен для хранения коротких данных.
- Недостатки:
- Ограничение на максимальный размер данных.
BLOB (Binary Large Object) – это тип данных для хранения больших бинарных объектов. BLOB используется для хранения крупных данных, таких как изображения, видео или другие большие файлы. В отличие от VARBINARY, BLOB может хранить бинарные данные на несколько гигабайт. BLOB разделяется на несколько подтипов, включая TEXT и MEDIUMBLOB, в зависимости от требуемого объема памяти.
- Преимущества BLOB:
- Подходит для хранения крупных объектов (от нескольких мегабайт до гигабайт).
- Не ограничен размером, как VARBINARY.
- Недостатки:
- Требует больше ресурсов для хранения и обработки больших данных.
- Может оказывать влияние на производительность при работе с большими объемами данных.
При выборе между VARBINARY и BLOB важно учитывать размер данных, которые необходимо хранить. Для хранения небольших данных (до нескольких килобайт) целесообразно использовать VARBINARY, так как это более эффективно с точки зрения производительности. Для работы с большими бинарными объектами, такими как изображения и видеофайлы, лучше использовать BLOB, так как он не имеет ограничений по размеру, как VARBINARY.
Важным аспектом при работе с этими типами данных является правильное управление индексацией и хранением данных, так как избыточные или плохо организованные данные могут значительно замедлить запросы к базе данных.
Особенности использования тип данных ENUM в SQL
Тип данных ENUM в SQL используется для хранения ограниченного набора значений, что делает его полезным при необходимости представления фиксированного множества возможных вариантов. Каждое значение в ENUM представляется строкой, а в базе данных хранится как целое число, которое соответствует порядковому номеру значения в списке.
Одной из ключевых особенностей является возможность жесткого контроля за входными данными. Когда создается столбец с типом ENUM, можно заранее задать все допустимые значения, что минимизирует риск ошибок ввода и повышает целостность данных. Например, для поля «статус» можно использовать значения: ‘активен’, ‘неактивен’, ‘на проверке’.
ENUM обладает хорошей производительностью, так как хранит данные как целые числа, что ускоряет их обработку. При этом на уровне SQL-запросов возвращаются строки, что удобно для взаимодействия с пользователем.
При проектировании базы данных с использованием ENUM важно учитывать, что список значений не является динамичным. Добавление нового значения требует изменения структуры таблицы, что может повлиять на производительность при больших объемах данных. Лучше избегать частых изменений в списке значений, так как это потребует дополнительных операций в БД, таких как обновление всех строк, содержащих старое значение.
ENUM имеет ограничение по количеству значений, которое зависит от системы управления базами данных. Например, MySQL поддерживает до 65,535 значений в одном ENUM. Однако на практике это редко является проблемой, так как тип данных используется для небольших, четко ограниченных наборов значений.
Еще одним моментом является использование ENUM для представления логических значений, таких как «да/нет». В таких случаях часто предпочтительнее использовать тип данных BOOLEAN или TINYINT для лучшей совместимости с различными СУБД и лучшей читаемости кода.
Рекомендуется использовать ENUM в тех случаях, когда количество возможных значений заранее известно и остается стабильным. Для более гибких решений, особенно если набор значений может изменяться, лучше использовать таблицы с внешними ключами, что обеспечит большую масштабируемость и гибкость в будущем.
Преимущества и ограничения типа JSON в базе данных SQL

Тип данных JSON в SQL предоставляет гибкость для хранения структурированных данных в виде объектов и массивов, что делает его полезным для приложений с динамично меняющимися структурами. Один из ключевых плюсов – возможность хранения данных без предварительного указания схемы, что избавляет от необходимости изменять структуру таблиц при добавлении новых полей.
JSON поддерживает вложенность и разнообразие типов данных, что позволяет эффективно сохранять сложные структуры, такие как вложенные объекты и массивы. Это облегчает интеграцию с веб-приложениями и API, которые часто используют формат JSON для обмена данными. К тому же, многие базы данных, такие как PostgreSQL и MySQL, предлагают функции для работы с JSON, включая индексацию, поиск и извлечение данных по ключам, что ускоряет выполнение запросов.
Один из важных аспектов – возможность выполнения операций непосредственно на данных в формате JSON. Это позволяет фильтровать, изменять и извлекать конкретные элементы без необходимости извлекать весь объект. В PostgreSQL, например, доступны операторы для доступа к элементам JSON, такие как `->`, `->>`, что делает работу с данными более эффективной.
Однако использование типа JSON в SQL не лишено ограничений. Одним из них является производительность. Операции с JSON могут быть медленнее по сравнению с обычными типами данных, так как требуется дополнительная обработка для парсинга и извлечения значений из структурированного текста. Особенно это заметно при работе с большими объемами данных, где каждое извлечение элемента может потребовать значительных ресурсов.
Ещё одно ограничение – отсутствие строгой схемы. Хотя это может быть преимуществом при разработке, отсутствие контроля над структурой данных может привести к сложности в поддержке и обработке данных в долгосрочной перспективе. Также при отсутствии схемы сложно выполнять агрегации и другие типы анализа данных, поскольку структура JSON может изменяться.
Для минимизации этих недостатков рекомендуется использовать JSON в тех случаях, когда данные действительно имеют гибкую структуру и редко меняются, либо когда необходимо работать с данными, которые поступают в формате JSON из внешних источников. В ситуациях, где структура данных стабильна и хорошо определена, стоит отдавать предпочтение традиционным типам данных, которые обеспечат более высокую производительность и удобство в работе.
Вопрос-ответ:
Что такое категории данных в SQL и зачем они нужны?
Категории данных в SQL определяют типы значений, которые могут быть сохранены в базе данных. Они помогают системе управления базами данных (СУБД) понимать, какие операции можно выполнять с данными, например, арифметические или строковые. Например, категории данных могут включать целые числа, строки, даты и булевы значения. Это важно для правильного хранения и обработки данных, а также для обеспечения целостности данных.
Какие основные категории данных существуют в SQL?
В SQL существует несколько основных категорий данных, среди которых можно выделить: числовые (например, INT, DECIMAL, FLOAT), строковые (CHAR, VARCHAR, TEXT), дата и время (DATE, DATETIME, TIMESTAMP), логические (BOOLEAN) и бинарные данные (BLOB). Каждая из этих категорий предназначена для конкретных типов информации, что позволяет эффективно управлять данными в базе данных и выполнять различные операции с ними.
Чем отличаются типы данных INT и DECIMAL в SQL?
Тип данных INT используется для хранения целых чисел, без десятичных знаков. Он подходит для хранения чисел, которые не требуют дробной части. DECIMAL, в свою очередь, предназначен для хранения чисел с фиксированной десятичной точкой, что позволяет точно представлять дробные значения, например, для хранения финансовых данных. DECIMAL позволяет задать точность и масштаб, что делает его идеальным для операций, где важна точность при работе с деньгами или другими числами с дробной частью.
Как в SQL выбрать правильный тип данных для столбца в таблице?
Выбор типа данных зависит от того, какие значения будут храниться в столбце. Если нужно хранить целые числа, лучше выбрать INT или BIGINT. Для хранения строковых данных подходящими будут CHAR или VARCHAR в зависимости от длины строк. Для даты и времени следует использовать типы DATE, TIME или DATETIME. Важно учитывать не только формат данных, но и их объем, чтобы оптимизировать использование памяти и повысить производительность запросов. Также следует учитывать возможные операции, которые будут выполняться с этими данными (например, математические или строковые операции).
Что такое тип данных BOOLEAN в SQL и как он используется?
Тип данных BOOLEAN в SQL используется для хранения логических значений, которые могут быть либо TRUE (истина), либо FALSE (ложь). Он часто используется для хранения флагов или признаков, например, для обозначения состояния активности или завершенности операции. В некоторых СУБД значение BOOLEAN может быть реализовано через хранение целых чисел (0 для FALSE, 1 для TRUE), но концептуально это всегда логический тип данных. Этот тип удобен для выполнения логических операций и фильтрации данных в запросах.
Что такое категории данных в SQL и какие их особенности?
Категории данных в SQL — это типы данных, которые определяют, как хранятся и обрабатываются значения в базе данных. Основные категории включают числовые (например, INT, DECIMAL), строковые (например, VARCHAR, CHAR), типы данных для даты и времени (например, DATE, DATETIME), а также логические типы (например, BOOLEAN). Каждая категория имеет свои особенности, такие как диапазон значений, точность, требуемая память для хранения и поддерживаемые операции. Например, тип данных INT подходит для целых чисел, а DECIMAL используется, когда важна точность при работе с деньгами или другими числовыми значениями с фиксированным количеством знаков после запятой.
Как выбрать подходящую категорию данных для хранения информации в SQL?
Выбор категории данных зависит от того, какой тип информации нужно хранить. Например, для чисел без десятичных знаков следует использовать тип INT, а если необходимо хранить числа с десятичной частью — DECIMAL или FLOAT. Для текста, который может менять длину, используют VARCHAR, а если текст фиксированной длины — CHAR. Для работы с датами и временем лучше выбрать типы DATE, DATETIME или TIMESTAMP в зависимости от точности и временной зоны. Важно учитывать требования к памяти и производительности, так как использование слишком большого типа данных может привести к избыточному использованию памяти, а слишком маленький — к потере данных или невозможности корректно сохранить значения.