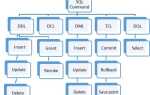
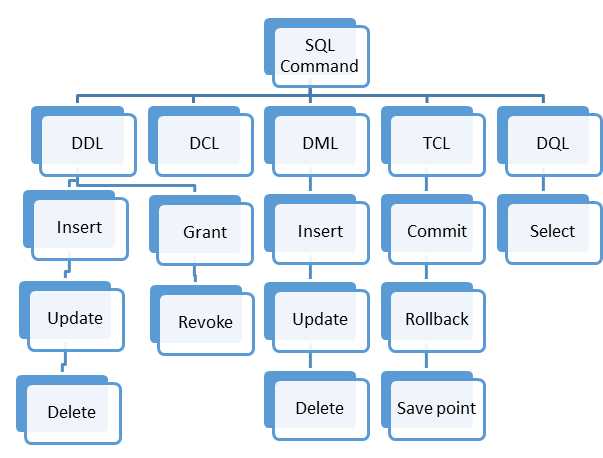
SQL предоставляет чётко структурированный набор операций, охватывающих полный жизненный цикл данных – от извлечения до удаления. Ключевая особенность языка – ориентированность на декларативный подход: разработчик указывает, *что* требуется получить, а не *как*. Это позволяет эффективно управлять как небольшими, так и масштабными наборами данных, минимизируя избыточность в коде.
Извлечение данных начинается с оператора SELECT, который допускает выборку с фильтрацией (WHERE), сортировкой (ORDER BY) и агрегацией (GROUP BY, HAVING). Практика показывает, что комбинирование этих конструкций с подзапросами и оконными функциями позволяет значительно повысить читаемость и производительность запросов.
Модификация данных осуществляется с помощью INSERT, UPDATE и DELETE. Для массовой загрузки данных стоит использовать INSERT INTO … SELECT, особенно в случае миграций между таблицами. При обновлении – добавление условия WHERE обязательно: его отсутствие может привести к изменению всех записей. Удаление данных требует особой осторожности – рекомендуется предварительно запускать запрос в режиме SELECT, чтобы убедиться в корректности выборки.
Управление транзакциями через BEGIN, COMMIT и ROLLBACK обеспечивает контроль над целостностью данных при выполнении критичных операций. Особенно важно использовать транзакции при обновлении нескольких связанных таблиц, чтобы избежать частичного изменения состояния базы.
В совокупности эти операции формируют основу большинства прикладных решений, использующих СУБД. Их грамотное применение позволяет не только оптимизировать взаимодействие с данными, но и минимизировать риски ошибок при их обработке.
Как выполнять выборку данных с помощью оператора SELECT
Оператор SELECT позволяет извлекать строки из таблицы, указывая конкретные столбцы и условия. Чтобы получить все данные из таблицы, используется конструкция SELECT * FROM имя_таблицы;. Однако для повышения производительности и читаемости следует явно указывать нужные поля: SELECT имя, возраст FROM сотрудники;.
Для фильтрации строк применяется оператор WHERE. Пример: SELECT имя FROM клиенты WHERE город = 'Москва'; извлечёт имена клиентов из Москвы. Условия могут быть составными: WHERE возраст > 30 AND статус = 'активен'.
Сортировка результатов осуществляется через ORDER BY. SELECT * FROM заказы ORDER BY дата_создания DESC; вернёт заказы в порядке убывания даты. Можно сортировать по нескольким столбцам: ORDER BY статус, дата_создания.
Для ограничения количества возвращаемых строк используется оператор LIMIT. SELECT * FROM товары LIMIT 10; вернёт первые 10 записей. В PostgreSQL можно использовать OFFSET для пропуска строк: LIMIT 10 OFFSET 20;.
Агрегация данных осуществляется через функции COUNT, SUM, AVG, MIN, MAX. SELECT COUNT(*) FROM заказы WHERE статус = 'завершён'; посчитает завершённые заказы. Группировка выполняется с помощью GROUP BY: SELECT клиент_id, SUM(сумма) FROM заказы GROUP BY клиент_id;.
Для отбора групп по условию используется HAVING: HAVING SUM(сумма) > 10000. Этот фильтр применяется после агрегации и не заменяет WHERE.
Чтобы исключить дубликаты, используется ключевое слово DISTINCT. SELECT DISTINCT категория FROM товары; вернёт уникальные категории товаров.
Вложенные запросы (подзапросы) позволяют использовать результат одного SELECT внутри другого. SELECT имя FROM клиенты WHERE id IN (SELECT клиент_id FROM заказы WHERE сумма > 5000); вернёт клиентов с крупными заказами.
Фильтрация строк с использованием WHERE и логических операторов

Оператор WHERE применяется для выбора строк, соответствующих заданному условию. Он используется во всех типах запросов: SELECT, UPDATE, DELETE. Без WHERE операции затрагивают все строки таблицы.
Для построения точных условий применяются логические операторы: AND, OR, NOT. Они позволяют комбинировать или исключать условия. Например:
SELECT * FROM сотрудники
WHERE отдел = 'Продажи' AND стаж > 3;Выражение вернёт только тех сотрудников, которые работают в отделе продаж и имеют стаж более 3 лет. Порядок логических операций важен: AND имеет более высокий приоритет, чем OR. Чтобы избежать неоднозначности, используйте скобки:
SELECT * FROM заказы
WHERE (статус = 'оплачен' OR статус = 'доставлен') AND дата >= '2024-01-01';Оператор NOT инвертирует условие:
SELECT * FROM клиенты
WHERE NOT страна = 'Россия';Для работы с диапазонами чисел и дат удобны BETWEEN и IN:
SELECT * FROM транзакции
WHERE сумма BETWEEN 1000 AND 5000;SELECT * FROM товары
WHERE категория IN ('Электроника', 'Бытовая техника');Проверка на NULL осуществляется только с помощью IS NULL и IS NOT NULL:
SELECT * FROM пользователи
WHERE email IS NOT NULL;Для повышения читаемости и производительности фильтрации:
- Избегайте лишних логических операций
- Проверяйте индексацию полей, участвующих в условиях
- Сравнивайте значения одного типа данных
- Используйте
EXPLAINдля анализа плана выполнения запроса
Сортировка результатов с помощью ORDER BY
Ключевое слово ORDER BY используется для упорядочивания строк результата запроса на основе значений одного или нескольких столбцов. По умолчанию используется сортировка по возрастанию (ASC), но явно можно задать убывающий порядок с помощью DESC.
- Сортировка по одному столбцу:
SELECT * FROM сотрудники ORDER BY фамилия ASC; - Сортировка по нескольким столбцам:
SELECT * FROM сотрудники ORDER BY отдел, стаж DESC;– сначала по отделу по возрастанию, затем по стажу по убыванию внутри каждого отдела. - Указание позиции столбца:
SELECT имя, возраст FROM клиенты ORDER BY 2 DESC;– сортировка по второму столбцу результата, в данном случае по возрасту. - Сортировка по вычисляемым выражениям:
SELECT имя, зарплата * 12 AS годовой_доход FROM сотрудники ORDER BY годовой_доход DESC; - CASE в ORDER BY для нестандартной логики:
SELECT * FROM заказы ORDER BY CASE статус WHEN 'срочный' THEN 1 WHEN 'обычный' THEN 2 ELSE 3 END;
- Избегайте сортировки по столбцам, не входящим в SELECT при использовании DISTINCT или GROUP BY – это может вызвать ошибку.
- Сортировка требует ресурсов, особенно на больших объёмах данных – добавляйте индексы на поля, по которым часто выполняется ORDER BY.
- Для стабильной сортировки используйте уникальные поля в качестве дополнительных критериев, чтобы избежать непредсказуемого порядка строк с одинаковыми значениями.
Группировка данных и агрегатные функции: GROUP BY и HAVING

Оператор GROUP BY используется для агрегирования строк с одинаковыми значениями в указанных столбцах. Его применяют совместно с агрегатными функциями: COUNT(), SUM(), AVG(), MIN(), MAX().
При использовании GROUP BY необходимо включать в SELECT только агрегатные функции и поля, участвующие в группировке. Нарушение этого правила приведёт к ошибке выполнения запроса.
Пример: подсчёт количества заказов по каждому клиенту:
SELECT client_id, COUNT(*) AS order_count
FROM orders
GROUP BY client_id;
Чтобы фильтровать результаты после группировки, применяется HAVING. В отличие от WHERE, который фильтрует строки до группировки, HAVING работает с агрегированными данными.
Пример: отбор клиентов с более чем 5 заказами:
SELECT client_id, COUNT(*) AS order_count
FROM orders
GROUP BY client_id
HAVING COUNT(*) > 5;
Для повышения производительности избегайте HAVING без нужды. Если фильтр можно применить до группировки – используйте WHERE.
Группировка по нескольким полям создаёт подгруппы. Например, группировка по client_id и status покажет число заказов по каждому статусу для каждого клиента:
SELECT client_id, status, COUNT(*) AS status_count
FROM orders
GROUP BY client_id, status;
Используйте псевдонимы (AS) для читаемости. Упрощайте группировку – не включайте в SELECT лишние поля. Для вложенных запросов применяйте подзапросы с GROUP BY внутри CTE или под SELECT.
Обновление данных с использованием оператора UPDATE
Оператор UPDATE изменяет существующие строки в таблице на основе заданных условий. Для точечного изменения используется синтаксис: UPDATE имя_таблицы SET столбец1 = значение1 [, столбец2 = значение2, ...] WHERE условие;. Без WHERE обновятся все строки, что может привести к потере данных.
Перед выполнением команды рекомендуется выполнить предварительный SELECT с аналогичным условием, чтобы убедиться в корректности выборки. Это снижает риск нежелательных массовых изменений.
Для обновления с использованием данных из другой таблицы применяется форма с подзапросом: UPDATE t1 SET t1.col = (SELECT t2.col FROM t2 WHERE t2.id = t1.id). Альтернатива – UPDATE t1 SET t1.col = t2.col FROM t2 WHERE t1.id = t2.id (в PostgreSQL и SQL Server).
Если требуется учесть сложную бизнес-логику, можно использовать CASE внутри SET: SET status = CASE WHEN score >= 90 THEN 'A' WHEN score >= 75 THEN 'B' ELSE 'C' END.
В MySQL перед обновлением рекомендуется отключать или настраивать ограничения FOREIGN_KEY_CHECKS, если затрагиваются внешние ключи. В Oracle стоит учитывать поведение триггеров, особенно при каскадных изменениях.
Для минимизации блокировок используйте индексированные поля в WHERE и избегайте обновления по неиндексированным критериям. Это ускоряет выполнение и снижает вероятность конфликтов транзакций.
Удаление строк из таблиц через DELETE
Команда DELETE используется для удаления строк из таблицы с учетом заданного условия. Без WHERE происходит удаление всех записей, но структура таблицы сохраняется. Пример полной очистки таблицы: DELETE FROM employees;. Это приведёт к полной потере данных без возможности восстановления, если не настроено резервное копирование или откат транзакций.
Для удаления выборочно используется WHERE. Пример: DELETE FROM employees WHERE department_id = 5;. Условие должно быть максимально конкретным, чтобы избежать случайного удаления лишних строк. Рекомендуется предварительно выполнить SELECT с тем же условием: SELECT * FROM employees WHERE department_id = 5;.
Если в таблице есть связи по внешнему ключу, при удалении строк может возникнуть ошибка ограничения целостности. В таких случаях применяют каскадное удаление (ON DELETE CASCADE) или сначала удаляют зависимые записи вручную.
Удаление больших объёмов данных требует осторожности. Рекомендуется использовать пакетную обработку с ограничением количества строк: DELETE FROM logs WHERE log_date < NOW() - INTERVAL 1 YEAR LIMIT 10000;. Это снижает нагрузку на систему и позволяет выполнять операцию в несколько этапов.
После удаления строк индекс может фрагментироваться. Для оптимизации таблицы используется команда OPTIMIZE TABLE (MySQL) или VACUUM (PostgreSQL). Это восстанавливает производительность и освобождает дисковое пространство.
Добавление новых записей с использованием INSERT INTO

Оператор INSERT INTO используется для добавления строк в существующую таблицу. Минимальный синтаксис требует указания имени таблицы и значений для всех обязательных столбцов:
INSERT INTO имя_таблицы VALUES (значение1, значение2, …);
Рекомендуется явно указывать список столбцов для повышения читаемости и уменьшения риска ошибок при изменении структуры таблицы:
INSERT INTO имя_таблицы (столбец1, столбец2) VALUES (значение1, значение2);
При добавлении нескольких строк за одну операцию следует использовать множественные группы значений:
INSERT INTO имя_таблицы (столбец1, столбец2) VALUES (значение1, значение2), (значение3, значение4);
Если значения формируются из результата запроса, применяется форма INSERT INTO … SELECT. Это особенно эффективно при миграции данных между таблицами или предварительной фильтрации:
INSERT INTO архив (id, имя) SELECT id, имя FROM пользователи WHERE статус = ‘неактивен’;
Чтобы избежать конфликтов при наличии ограничений уникальности, можно использовать INSERT IGNORE (MySQL) или ON CONFLICT DO NOTHING (PostgreSQL):
INSERT INTO пользователи (email) VALUES (‘example@mail.com’) ON CONFLICT DO NOTHING;
В случае необходимости обновления существующих записей вместо ошибки применяют конструкцию ON DUPLICATE KEY UPDATE или ON CONFLICT DO UPDATE:
INSERT INTO товары (id, цена) VALUES (1, 100) ON CONFLICT (id) DO UPDATE SET цена = EXCLUDED.цена;
Для обеспечения безопасности и предотвращения SQL-инъекций необходимо использовать параметризованные запросы при работе с пользовательским вводом.
Объединение таблиц с помощью JOIN: INNER, LEFT, RIGHT, FULL

Операторы JOIN в SQL применяются для извлечения данных из нескольких таблиц, связанных между собой логически. Выбор типа JOIN зависит от требований к выборке и структуры данных.
- INNER JOIN возвращает только те строки, где найдено совпадение по указанному условию соединения. Используется, когда необходимы только связанные записи из обеих таблиц. Например, при анализе заказов и клиентов без учета незавершённых или анонимных сделок.
- LEFT JOIN включает все строки из левой таблицы и только совпадающие – из правой. Если совпадений нет, значения из правой таблицы заполняются NULL. Этот тип объединения удобен для получения полной картины с сохранением записей, даже если сопоставление отсутствует, например, список всех пользователей с их последними действиями, включая тех, кто ещё не проявил активность.
- RIGHT JOIN аналогичен LEFT JOIN, но приоритет у правой таблицы. Применяется реже, поскольку ту же задачу можно решить с помощью LEFT JOIN, изменив порядок таблиц.
- FULL JOIN возвращает объединённый набор всех строк из обеих таблиц, где совпадения по условию соединения заполняются, а несовпадающие строки получают NULL для недостающих значений. Полезен при агрегации информации из источников, не полностью синхронизированных, например, при сопоставлении данных из внешней CRM и внутренней базы заказов.
Рекомендации:
- Перед использованием JOIN убедитесь, что между таблицами есть корректные ключи связи – чаще всего это первичный и внешний ключи.
- Избегайте JOIN без условия ON – это приводит к декартовому произведению и может создать чрезмерную нагрузку на систему.
- Используйте псевдонимы таблиц для читаемости и однозначности при объединении более двух источников.
- Анализируйте планы выполнения запросов – неправильный тип JOIN может привести к неэффективным сканированиям и задержкам.
Вопрос-ответ:
Какие операции можно выполнять в SQL для работы с данными?
В SQL доступны различные операции для работы с данными, включая выборку данных (SELECT), добавление данных (INSERT), обновление данных (UPDATE) и удаление данных (DELETE). Эти операции позволяют извлекать, изменять или удалять информацию из таблиц базы данных.
Как можно извлечь только определенные столбцы из таблицы в SQL?
Для этого в SQL используется операция SELECT, в которой можно указать конкретные столбцы, которые нужно выбрать. Например, запрос SELECT column1, column2 FROM table_name; извлекает только столбцы column1 и column2 из таблицы table_name.
Как в SQL добавить новые данные в таблицу?
Для добавления данных в таблицу используется команда INSERT. В запросе указывается название таблицы и значения для каждой из колонок. Например: INSERT INTO table_name (column1, column2) VALUES (value1, value2); — этот запрос добавит одну строку с указанными значениями в соответствующие столбцы таблицы.
Каким образом можно обновить информацию в уже существующих строках таблицы в SQL?
Для обновления данных используется команда UPDATE. В запросе указывается таблица, столбцы и новые значения для обновления, а также условие, которое ограничивает строки для изменения. Например: UPDATE table_name SET column1 = new_value WHERE condition; обновит значения столбца column1, если строки соответствуют заданному условию.
Как удалить строки из таблицы в SQL?
Для удаления данных из таблицы используется команда DELETE. В запросе указывается таблица и условие, по которому будут удаляться строки. Например, DELETE FROM table_name WHERE condition; удалит все строки, которые соответствуют условию. Если условие не указано, будут удалены все строки из таблицы.