Открытие и работа с кодом базы данных в SQL – это ключевая задача для каждого разработчика, который взаимодействует с реляционными базами данных. Это процесс, который требует точности и знаний специфических команд, чтобы правильно управлять структурами данных и производить изменения. Важно понимать, что SQL-запросы можно выполнять через различные инструменты, такие как командная строка, IDE (например, DBeaver, SQL Server Management Studio) или встроенные интерфейсы СУБД. Независимо от используемой платформы, основной принцип остается неизменным: чтобы работать с базой данных, нужно правильно ее открыть, понять структуру и научиться безопасно вносить изменения.
Первым шагом является подключение к серверу базы данных. Для этого необходимо иметь доступ к серверу, на котором расположена СУБД, а также правильные учетные данные. Важно использовать подходящие драйверы и настройки для подключения к конкретной СУБД, будь то MySQL, PostgreSQL, Microsoft SQL Server или другая система. Для подключения можно использовать как графические интерфейсы, так и командные инструменты, например, mysql -u username -p для MySQL или psql -U username -d database для PostgreSQL.
Когда соединение установлено, следующим шагом является выбор базы данных, с которой нужно работать. Для этого достаточно выполнить команду USE database_name; в MySQL или \c database_name в PostgreSQL. Если база данных уже существует, но вы хотите изучить ее код, первым делом полезно получить список доступных таблиц с помощью команды SHOW TABLES; в MySQL или \dt в PostgreSQL. Это даст общее представление о структуре базы данных.
Для эффективной работы с кодом важно соблюдать порядок выполнения операций, начиная с анализа текущей структуры базы данных и заканчивая тестированием измененных объектов. Использование транзакций – это обязательная практика для предотвращения потери данных или частичных изменений, которые могут нарушить целостность базы данных. Важно помнить, что любые изменения должны быть протестированы в тестовой среде перед внедрением в рабочую базу данных, чтобы избежать непредвиденных последствий.
Как получить доступ к коду базы данных через SQL Server Management Studio
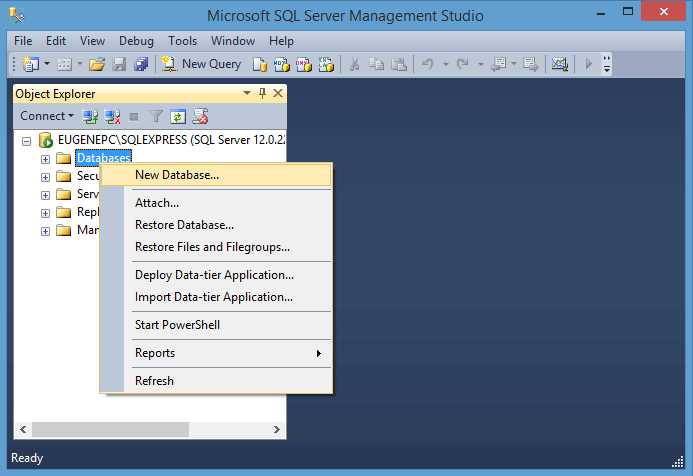
Для работы с кодом базы данных в SQL Server Management Studio (SSMS) необходимо выполнить несколько шагов, чтобы открыть и анализировать объекты базы данных, такие как таблицы, представления, хранимые процедуры и функции.
Первый шаг – подключение к серверу SQL. Запустите SSMS и введите данные для подключения к нужному серверу. После подключения откроется окно Object Explorer, где отображаются все базы данных на сервере.
Чтобы получить доступ к коду конкретной базы данных, выберите её в Object Explorer и разверните список объектов. Например, чтобы посмотреть код хранимой процедуры, перейдите в раздел Programmability → Stored Procedures, затем найдите нужную процедуру, кликните правой кнопкой мыши и выберите Script Stored Procedure as → CREATE To → New Query Editor Window. Это откроет окно с кодом для создания этой процедуры.
Для анализа кода таблиц или представлений откройте раздел Tables или Views, выберите нужный объект и используйте аналогичный подход для отображения его кода.
Также для удобства можно использовать запросы. Например, для получения кода всех объектов базы данных можно воспользоваться системными представлениями, такими как sys.objects, sys.sql_modules, sys.procedures. Запрос к этим представлениям позволит извлечь текст SQL-объектов.
SELECT OBJECT_DEFINITION(OBJECT_ID('имя_процедуры'))
Для быстрого поиска по объектам можно использовать встроенную функцию поиска в SSMS. Для этого нажмите Ctrl + F и выберите тип поиска, например, по имени процедуры или по определённому фрагменту кода.
Важно помнить, что для доступа к коду некоторых объектов могут потребоваться специальные права, такие как разрешение VIEW DEFINITION, которое предоставляет доступ к метаданным объектов базы данных. Если вы не можете увидеть код, запросите соответствующие привилегии у администратора системы.
Как открыть и просматривать структуру базы данных с помощью SQL-запросов

Для анализа структуры базы данных в SQL существует несколько ключевых запросов, которые позволяют получить информацию о таблицах, столбцах, индексах и других объектах базы. Начнем с самых основных запросов, которые помогут вам исследовать структуру базы данных.
1. Для получения списка всех таблиц в базе данных можно использовать запрос:
SHOW TABLES;
Этот запрос возвращает имена всех таблиц, находящихся в текущей базе данных. Важно помнить, что для работы с этим запросом необходимо выбрать базу данных командой USE имя_базы;.
2. Для просмотра структуры конкретной таблицы, включая все её столбцы и их типы данных, используйте команду:
DESCRIBE имя_таблицы;
Команда DESCRIBE предоставит информацию о каждом столбце, его типе, значении по умолчанию, возможности быть NULL и дополнительных параметрах.
3. Если необходимо получить более подробное описание столбцов, включая ограничения и связи с другими таблицами, используйте запрос:
SHOW COLUMNS FROM имя_таблицы;
Этот запрос даст аналогичную информацию с дополнительными деталями, такими как комментарии, если они были добавлены при создании столбцов.
4. Для получения списка всех индексов, которые существуют для таблицы, выполните запрос:
SHOW INDEXES FROM имя_таблицы;
Ответ будет содержать информацию о типах индексов, их уникальности и столбцах, которые включены в индексы. Это полезно для оценки производительности запросов, использующих эти индексы.
5. Для получения списка всех внешних ключей, установленных в таблице, используйте запрос:
SHOW CREATE TABLE имя_таблицы;
Этот запрос покажет не только структуру таблицы, но и все ограничения, включая внешние ключи и другие связанные элементы. Это важно для анализа связей между таблицами в базе данных.
6. Если нужно просматривать все доступные базы данных на сервере, выполните:
SHOW DATABASES;
Этот запрос вернет все базы данных, доступные в системе, что полезно для переключения между разными проектами или базами данных.
Применяя эти запросы, вы сможете эффективно изучать структуру базы данных, что особенно важно при работе с большими или сложными системами данных, а также для оптимизации и поддержания баз данных в актуальном состоянии.
Как найти и изменить код хранимых процедур в SQL
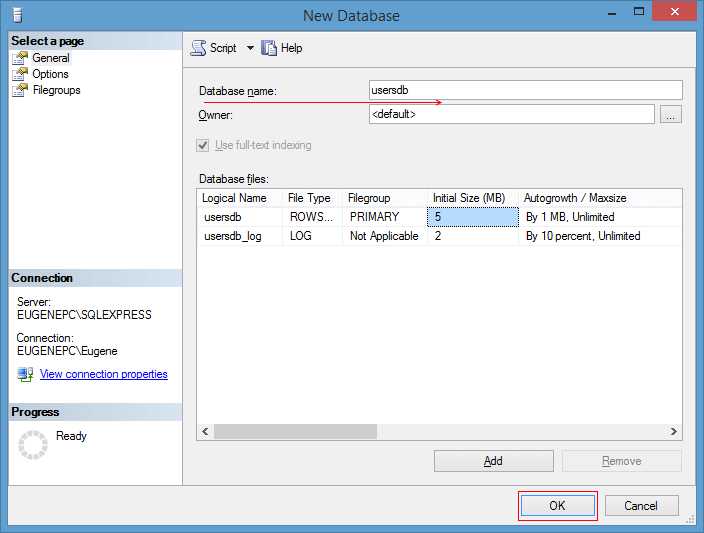
Чтобы найти код хранимых процедур в SQL, необходимо использовать системные представления базы данных, которые хранят метаданные о хранимых процедурах. В зависимости от СУБД, запросы могут отличаться, но для большинства баз данных, таких как MySQL, PostgreSQL или SQL Server, используются похожие подходы.
В SQL Server код хранимых процедур можно найти с помощью представления sys.objects и sys.sql_modules. Пример запроса для получения кода процедуры:
SELECT sm.definition FROM sys.sql_modules sm JOIN sys.objects o ON sm.object_id = o.object_id WHERE o.type = 'P' AND o.name = 'Имя_процедуры';
Этот запрос вернёт текстовое содержимое хранимой процедуры с указанным именем. В PostgreSQL для получения кода используется системная таблица pg_proc, а в MySQL можно обратиться к таблице information_schema.routines.
После того как вы нашли нужную процедуру, можно приступить к её изменению. В SQL Server для этого используется команда ALTER PROCEDURE, которая позволяет переписать существующую процедуру. Пример:
ALTER PROCEDURE Имя_процедуры AS BEGIN -- Новый код процедуры END;
При изменении хранимой процедуры важно помнить, что её код должен быть полностью указан в запросе, так как команда ALTER заменяет существующую процедуру, а не модифицирует её частично.
Для внесения изменений в код в PostgreSQL и MySQL используйте аналогичные команды. В PostgreSQL также используется CREATE OR REPLACE FUNCTION для замены процедуры или функции:

В SQL триггеры и функции служат для автоматизации выполнения действий при изменении данных в таблицах. Знание того, как эффективно работать с этими инструментами, значительно улучшает производительность и упрощает управление базой данных.
Триггеры – это специальные процедуры, которые автоматически выполняются при определённых изменениях в базе данных, таких как вставка, обновление или удаление строк. Триггер может быть настроен на выполнение до или после изменения данных.
Пример создания триггера, который запускается перед вставкой данных в таблицу:
CREATE TRIGGER trg_before_insert BEFORE INSERT ON employees FOR EACH ROW BEGIN IF NEW.salary < 10000 THEN SET NEW.salary = 10000; END IF; END;
В этом примере триггер гарантирует, что зарплата сотрудника не будет меньше 10,000 до её вставки в таблицу.
Когда необходимо удалить триггер, можно использовать команду:
DROP TRIGGER trg_before_insert;
Основные типы триггеров:
- BEFORE – выполняется до изменения данных.
- AFTER – выполняется после изменения данных.
- INSTEAD OF – выполняется вместо действия изменения данных (например, замещает операцию вставки, обновления или удаления).
Функции в SQL – это пользовательские программы, которые могут быть вызваны в запросах, что позволяет инкапсулировать логику и повторно использовать её. Функции могут возвращать значения, которые затем используются в других выражениях.
Пример создания функции, которая возвращает среднюю зарплату сотрудников в определённом отделе:
CREATE FUNCTION avg_salary(department_id INT) RETURNS DECIMAL(10,2) DETERMINISTIC BEGIN DECLARE avg_sal DECIMAL(10,2); SELECT AVG(salary) INTO avg_sal FROM employees WHERE department_id = department_id; RETURN avg_sal; END;
Функция возвращает среднюю зарплату для указанного отдела. Для её вызова используется SQL-запрос:
SELECT avg_salary(3);
Важно помнить, что функции в SQL могут быть не только встроенными, но и пользовательскими. Встраиваемые функции обычно реализуют часто используемые операции, такие как вычисления, манипуляции с датами и строками.
Рекомендации:
- Используйте триггеры для автоматизации проверки и манипуляций с данными, но не перегружайте их сложной логикой, чтобы избежать избыточной нагрузки на систему.
- Триггеры должны быть легко читаемыми и отлаживаемыми, особенно если они выполняют важные операции на уровне базы данных.
- Соблюдайте баланс при использовании функций и триггеров. Часто выполнение сложных операций в триггерах может замедлить работу базы данных, если они вызываются часто.
- Тщательно проверяйте функциональность триггеров и функций на тестовых данных перед их применением в продакшн-среде.
Использование триггеров и функций значительно упрощает работу с базами данных, но важно следить за производительностью и не допускать чрезмерной сложности в этих конструкциях.
Как экспортировать и импортировать код базы данных между серверами
Для начала экспорт кода базы данных можно осуществить с помощью создания дампа (файла), который содержит SQL-запросы для восстановления структуры базы данных. В MySQL для этого используется утилита mysqldump, в PostgreSQL – pg_dump, а в SQL Server – SQL Server Management Studio (SSMS).
В MySQL команда для экспорта будет следующей:
mysqldump -u username -p --no-data dbname > dbname_structure.sql
Здесь --no-data гарантирует, что экспортируются только определения таблиц, индексов и прочей структуры, без данных. В случае PostgreSQL используется команда:
pg_dump -U username -s dbname > dbname_structure.sql
После экспорта на одном сервере, файл dbname_structure.sql можно передать на другой сервер и импортировать с помощью команды:
mysql -u username -p dbname < dbname_structure.sql
В PostgreSQL импорт выполняется так:
psql -U username dbname < dbname_structure.sql
Импорт и экспорт кода базы данных между серверами требует, чтобы версии серверов были совместимы между собой. Это важно для предотвращения ошибок из-за несовпадения синтаксиса SQL или особенностей реализации определённых конструкций в разных версиях СУБД.
Для более сложных случаев можно использовать инструменты для миграции, такие как DBLink или Federated Tables для MySQL, которые позволяют работать с удалёнными базами данных без необходимости их полного экспорта и импорта.
Кроме того, не стоит забывать о необходимости проверки и тестирования работы базы данных после импорта. Иногда могут возникать проблемы с несовместимыми типами данных или уникальными ограничениями, которые необходимо разрешить вручную.
Как использовать версии и историю изменений в коде базы данных SQL

Для управления версиями кода базы данных SQL необходимо использовать системы контроля версий (например, Git) и инструменты, специально разработанные для работы с миграциями базы данных. Это позволяет отслеживать изменения, откатывать их при необходимости и поддерживать совместную работу над проектом. Рассмотрим несколько ключевых подходов.
- Использование Git для отслеживания изменений SQL-скриптов
Хранение SQL-скриптов в системе контроля версий позволяет легко отслеживать изменения, комментировать их и откатывать к предыдущим версиям. Каждый SQL-скрипт должен быть добавлен в репозиторий и коммититься с четким описанием изменений. Для этого:
- Создайте репозиторий для вашего проекта.
- Разбивайте код на небольшие логические блоки, например, скрипты для создания таблиц, индексов или вставки данных.
- Используйте понятные названия для коммитов, чтобы легко идентифицировать изменения (например, "Добавлен индекс на поле email" или "Обновлены связи между таблицами").
- Миграции базы данных
Для упрощения процесса управления версиями базы данных рекомендуется использовать инструменты миграции, такие как Flyway или Liquibase. Эти системы позволяют автоматически применять изменения к базе данных в соответствии с версией кода. С их помощью можно:
- Создавать и применять миграции (например, для добавления новых таблиц, изменения структуры существующих таблиц и т.д.).
- Отслеживать последовательность миграций и поддерживать согласованность базы данных с кодом.
- Откатывать изменения, если возникли ошибки или нужно вернуться к предыдущей версии базы данных.
Каждая миграция записывается в виде SQL-скрипта или Java-кода, который запускается при обновлении базы данных. Например, для Flyway каждая миграция будет иметь уникальный идентификатор, что помогает точно определить, какие изменения были применены к базе данных.
- Версионирование структуры базы данных
Одним из подходов к управлению версиями структуры базы данных является использование предварительно написанных миграций, которые отражают каждое изменение в схеме базы данных. Такой подход позволяет:
- Иметь точную историю всех изменений, начиная с первоначальной структуры базы данных.
- Легко применить новые миграции к различным средам (разработка, тестирование, продакшн), поддерживая консистентность.
- Использовать инструменты для автоматической генерации миграций при добавлении новых столбцов, изменении типов данных и прочих операций.
Это позволяет предотвратить "снижение" качества схемы базы данных, когда изменения вносит несколько разработчиков без централизованного контроля.
- История изменений с метками версий
Использование меток версий в репозитории и миграциях базы данных дает возможность контролировать, какие изменения были сделаны в каком порядке. Каждый этап разработки должен быть привязан к конкретной версии, что позволяет:
- Возвращаться к предыдущим версиям базы данных при необходимости.
- Понимать, какой код и какие миграции были применены на каждом этапе разработки.
- Проводить аудит изменений и анализировать, какие миграции могли привести к проблемам с производительностью или другим ошибкам.
Каждая версия должна быть четко документирована с указанием конкретных изменений и целей, для которых они были сделаны. Также стоит следить за правильностью и совместимостью миграций с текущими версиями базы данных.
- Тестирование миграций
Перед тем как применять миграции на продакшн-системе, важно протестировать их на промежуточных средах. Тестирование позволяет обнаружить потенциальные ошибки, например:
- Ошибки при миграции данных (например, потеря данных при изменении структуры таблицы).
- Ошибки в логике миграции, которые могут повлиять на производительность.
- Конфликты между миграциями, если несколько разработчиков работают над одной схемой базы данных.
Автоматические тесты должны включать в себя проверку корректности миграций, а также откаты изменений для оценки их воздействия на систему.
Вопрос-ответ:
Как открыть код базы данных в SQL?
Для открытия кода базы данных в SQL, сначала нужно подключиться к серверу базы данных с помощью клиента, например, MySQL Workbench или SQL Server Management Studio (SSMS). После подключения можно использовать команду "SHOW CREATE DATABASE имя_базы;" для получения исходного кода базы данных. В случае работы с таблицами, можно использовать команду "SHOW CREATE TABLE имя_таблицы;", чтобы увидеть SQL-скрипт, который создает таблицу. Также можно использовать команды, такие как DESCRIBE или SELECT * FROM для получения структуры и данных из таблицы.
Как просмотреть структуру базы данных в SQL?
Чтобы просмотреть структуру базы данных в SQL, можно использовать несколько команд. В MySQL, например, используйте команду "DESCRIBE имя_таблицы;" или "SHOW COLUMNS FROM имя_таблицы;", чтобы увидеть все поля таблицы с их типами данных, ключами и прочими аттрибутами. В SQL Server используется команда "sp_help имя_таблицы;", которая предоставляет подробную информацию о структуре таблицы, включая типы данных и ограничения. Эти команды позволяют получить полное представление о схеме базы данных.
Как изменить таблицу базы данных с помощью SQL?
Для изменения таблицы базы данных в SQL используется команда ALTER TABLE. Она позволяет добавлять, удалять или изменять столбцы таблицы. Например, чтобы добавить новый столбец, нужно использовать команду "ALTER TABLE имя_таблицы ADD имя_столбца тип_данных;". Чтобы изменить тип данных столбца, используется команда "ALTER TABLE имя_таблицы MODIFY имя_столбца новый_тип_данных;". Если необходимо удалить столбец, то применяется команда "ALTER TABLE имя_таблицы DROP COLUMN имя_столбца;". Важно всегда создавать резервные копии данных перед внесением изменений.
Как работать с индексами в SQL?
Индексы в SQL служат для ускорения поиска данных в таблицах. Для создания индекса используется команда "CREATE INDEX имя_индекса ON имя_таблицы (имя_столбца);". Существует несколько типов индексов, таких как уникальные индексы, которые предотвращают дублирование значений в столбцах, и составные индексы, включающие несколько столбцов. Чтобы удалить индекс, нужно использовать команду "DROP INDEX имя_индекса;". Индексы значительны для производительности, особенно при работе с большими объемами данных.
Как использовать транзакции в SQL?
Транзакции в SQL позволяют группировать несколько операций в одну единицу, что помогает поддерживать целостность данных. Для начала транзакции используется команда "BEGIN TRANSACTION". Далее выполняются необходимые операции, и в случае успеха транзакция фиксируется с помощью "COMMIT", а в случае ошибки — откатывается с помощью "ROLLBACK". Транзакции полезны, когда необходимо, чтобы несколько изменений данных выполнялись одновременно, например, при перевода денег между счетами, чтобы избежать частичных изменений.
Как открыть код базы данных в SQL и начать с ним работать?
Для того чтобы открыть код базы данных в SQL, вам нужно подключиться к базе данных с помощью специального инструмента, например, MySQL Workbench, pgAdmin или любой другой программы для работы с SQL. После этого вы можете использовать команду "SHOW CREATE DATABASE" или аналогичную команду для получения информации о структуре базы данных. Важно знать, что для работы с базой данных необходимо иметь соответствующие права доступа. Если вы хотите увидеть SQL-код для создания таблиц или других объектов базы данных, используйте команды, такие как "SHOW TABLES" или "DESCRIBE <название таблицы>", чтобы получить схему. После того как код будет открыт, можно начинать изменять его или выполнять другие операции с данными.