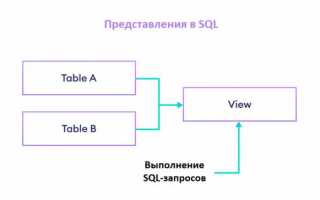
Представления (views) в SQL позволяют эффективно работать с данными, скрывая сложность запросов и упрощая взаимодействие с базой данных. Создание представлений предоставляет пользователю возможность работать с результатами сложных операций без необходимости повторно писать однотипные запросы. Это особенно полезно для тех случаев, когда часто требуется одна и та же агрегация данных или фильтрация по определённым условиям.
Для создания представления необходимо использовать команду CREATE VIEW, которая позволяет определить набор данных, представленных в виде виртуальной таблицы. Например, вместо многократного выполнения сложных SQL-запросов с объединениями и фильтрацией, можно создать представление, которое будет извлекать необходимые данные за вас. Это ускоряет выполнение запросов и снижает вероятность ошибок, поскольку логика вычислений уже инкапсулирована в представлении.
Рекомендации по созданию эффективных представлений:
1. Оптимизируйте запросы, лежащие в основе представления. Представления не должны содержать избыточных данных или выполнять сложные подзапросы, которые могут замедлить выполнение. Простейшие операции, такие как объединение таблиц, агрегации и фильтрация, должны быть основой представления.
2. Используйте индексы на столбцах, участвующих в фильтрации или соединении. Несмотря на то, что представление не хранит данные, индексы на базовых таблицах могут существенно ускорить выполнение запросов, использующих эти представления.
Представления особенно полезны в случае, когда нужно скрыть детали реализации бизнес-логики от конечного пользователя, обеспечив при этом безопасность и упрощение работы с базой данных. Но важно помнить, что представления не всегда являются панацеей: чрезмерное использование может привести к излишней нагрузке на систему, если запросы в них слишком сложны.
Как правильно выбрать данные для представления
Правильный выбор данных для представления в SQL напрямую влияет на производительность запросов и удобство работы с базой данных. Чтобы создать эффективное представление, необходимо точно определить, какие данные должны быть включены в представление, и какие из них могут быть исключены.
Во-первых, нужно определить, какие именно столбцы и строки данных будут использоваться наиболее часто. Важно, чтобы представление не содержало лишней информации, которая не будет запрашиваться или используется редко. Для этого следует проанализировать типичные запросы и выделить те поля, которые действительно необходимы для решения бизнес-задач.
Во-вторых, следует минимизировать количество вычислений в представлении. Если представление использует сложные вычисления, такие как агрегации или объединения нескольких таблиц, это может существенно замедлить выполнение запроса. Важно понимать, что не все вычисления должны быть реализованы в представлении, некоторые из них можно вынести в запросы на уровне приложения.
Также стоит учитывать индексирование. Для ускорения работы с представлениями желательно включать в них только те поля, которые индексированы, или, если это возможно, создавать индексы на столбцы, участвующие в фильтрах или соединениях. Это обеспечит быстрое извлечение данных и уменьшит нагрузку на систему.
Немаловажным фактором является выбор между агрегированными данными и необработанными. Если требуется часто получать данные в агрегированном виде (например, суммировать продажи по месяцам), то будет разумно создать представление, которое сразу возвращает агрегированные значения. В противном случае, лучше оставить необработанные данные, что даст больше гибкости в запросах.
Кроме того, стоит обратить внимание на актуальность данных. Если представление включает данные, которые часто обновляются, и запросы к представлению предполагают работу с актуальной информацией, можно использовать механизм материализованных представлений. Они сохраняют результаты вычислений, что позволяет ускорить работу, но требует регулярной синхронизации данных.
Что учитывать при объединении таблиц в представлении
При объединении таблиц в представлении важно учитывать несколько ключевых аспектов, которые могут существенно повлиять на производительность и точность данных. Основные факторы, которые следует учитывать:
Тип соединения. Выбор типа соединения (INNER JOIN, LEFT JOIN, RIGHT JOIN и др.) напрямую влияет на результат запроса. Для обеспечения правильности данных следует точно понимать, какие строки должны быть включены в итоговый результат. Например, LEFT JOIN может привести к включению пустых значений из одной из таблиц, если соответствующих записей нет в другой таблице.
Использование индексов. Индексы на полях, по которым выполняется объединение, могут значительно ускорить выполнение запроса. Если часто используется соединение по одному и тому же полю, создание индекса на этом поле поможет ускорить работу представлений.
Количество данных. Объединение крупных таблиц без предварительного фильтрации данных может привести к значительному увеличению объема возвращаемых данных, что снизит производительность. Использование условий WHERE и ограничений на количество строк поможет избежать перегрузки.
Отсутствие дублирования данных. Важно избегать дублирования строк, особенно если используются сложные соединения. Применение DISTINCT или группировки данных в SELECT помогает избежать избыточных записей в итоговом наборе данных.
Порядок объединений. Последовательность объединений может влиять на производительность. Например, соединение небольших таблиц с большими может быть менее эффективным, чем наоборот. Рекомендуется сначала фильтровать данные из больших таблиц перед объединением с меньшими, чтобы уменьшить объем данных, которые должны быть обработаны.
Представление и кэширование. При работе с часто запрашиваемыми данными важно учитывать возможность кэширования результата представления. В зависимости от СУБД, представление может быть либо всегда актуализируемым, либо сохраненным в виде материала, что позволяет ускорить доступ к данным.
Совместимость типов данных. При объединении таблиц с полями разных типов данных важно учитывать их совместимость. Например, числовые поля не всегда можно соединить с текстовыми без приведения типов, что может привести к ошибкам или снижению производительности.
Как оптимизировать запросы в представлениях для работы с большими данными
Использование индексов – эффективный способ ускорить выполнение запросов, особенно если представление работает с большими таблицами. Индексы на часто используемых колонках, таких как те, что участвуют в фильтрации или соединениях, значительно сокращают время поиска данных. Важно создавать индексы только на тех столбцах, которые реально требуются для конкретных запросов, чтобы избежать ухудшения производительности при вставке или обновлении данных.
Фильтрация данных на ранних стадиях – при создании представлений необходимо стараться как можно раньше отфильтровывать данные. Например, лучше использовать условия фильтрации в подзапросах или CTE (общих табличных выражениях), чем работать с большими наборами данных в финальном запросе. Это помогает уменьшить нагрузку на сервер и улучшить общую производительность.
Использование агрегаций и оконных функций с осторожностью – агрегации и оконные функции требуют значительных вычислительных ресурсов, особенно при обработке больших объемов данных. Лучше избегать их использования на больших наборах данных без предварительной фильтрации. Когда использование этих функций необходимо, стоит применять их только к подмножества данных, чтобы снизить нагрузку.
Разбиение данных (partitioning) может существенно улучшить производительность при работе с большими таблицами. Разбиение таблиц по логическим признакам (например, по датам или географическим регионам) позволяет более эффективно обрабатывать запросы, потому что сервер будет работать только с нужными разделами данных, а не с полной таблицей.
Materialized views – использование материализованных представлений может значительно ускорить запросы, так как результаты таких представлений сохраняются в базе данных. Однако следует учитывать, что материализованные представления требуют регулярного обновления для обеспечения актуальности данных. Это обновление должно быть настроено таким образом, чтобы минимизировать его влияние на производительность.
Использование подхода «lazy loading» – если представление требует сложных вычислений или объединений, стоит отдавать предпочтение запросам, которые загружают данные только по мере необходимости, а не извлекают их все сразу. Это особенно важно при работе с большими объемами данных, когда полный набор данных может быть слишком объемным для обработки за один запрос.
Оптимизация соединений (joins) требует использования правильных типов соединений. Например, когда необходимо объединить несколько таблиц, стоит избегать использования CROSS JOIN, если это не абсолютно необходимо, так как такой тип соединения может создать огромное количество промежуточных строк. Вместо этого предпочтительнее использовать INNER JOIN или LEFT JOIN с правильной фильтрацией.
Параллельная обработка данных в современных СУБД позволяет значительно ускорить выполнение запросов на многопроцессорных системах. Для этого важно, чтобы запросы были написаны с учетом параллелизма, и сама база данных была настроена на использование многозадачности. Некоторые СУБД автоматически разделяют работу по нескольким процессам, но в некоторых случаях это требует дополнительных настроек.
Применяя эти подходы, можно существенно повысить производительность запросов в представлениях при работе с большими данными, снижая нагрузку на систему и ускоряя обработку информации.
Как ограничить доступ к данным через представление
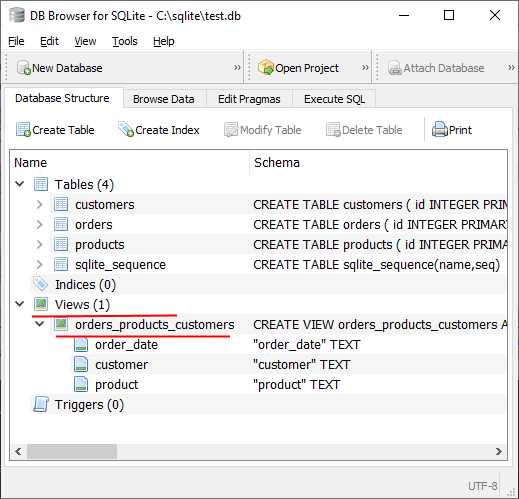
Ограничение доступа через представления в SQL позволяет минимизировать риски несанкционированного доступа к чувствительным данным, предоставляя пользователям только те данные, которые им необходимы для работы. Для реализации такого ограничения можно использовать несколько подходов.
Один из эффективных способов – это создание представлений, включающих только определённые столбцы таблицы. Например, можно создать представление, которое скрывает персонально идентифицируемую информацию, такую как адреса или номера телефонов, для пользователей, которым эти данные не требуются для выполнения их задач.
Другой способ ограничения доступа – использование фильтров (WHERE). Это позволяет предоставить доступ к данным только в рамках определённых условий. Например, если нужно предоставить доступ к данным сотрудников только в рамках одного отдела, можно добавить фильтр, который будет выбирать только тех сотрудников, которые относятся к этому отделу.
Представление можно настроить с использованием функции безопасности SQL, например, с помощью ролей и прав доступа. Создав представление, вы можете установить права для разных ролей. Это позволяет разным пользователям видеть разные подмножества данных в зависимости от их роли. Важно, чтобы представление не предоставляло больше данных, чем требуется для выполнения задачи пользователя.
Для более гибкой настройки безопасности можно использовать представления с динамическим фильтром, который учитывает идентификацию пользователя. Например, при подключении пользователь может видеть только свои собственные данные, если это предусмотрено логикой представления.
Следует учитывать, что представления не могут обеспечить полной безопасности данных, так как пользователи с правами на создание или изменение представлений могут обходить ограничения. В таких случаях необходимо комбинировать представления с дополнительными мерами безопасности, такими как шифрование данных и более строгие уровни доступа на уровне самой базы данных.
Использование агрегатных функций в представлениях
Агрегатные функции, такие как COUNT(), SUM(), AVG(), MIN() и MAX(), часто используются в представлениях для выполнения вычислений на основе данных из нескольких строк. Они упрощают анализ больших объемов информации, минимизируя необходимость выполнения повторяющихся запросов.
Использование агрегатных функций в представлениях может значительно повысить производительность, если правильно структурировать запросы и учитывать особенности индексации и объема данных.
COUNT()позволяет подсчитать количество строк, что полезно для получения общей информации о наборе данных. Например, если нужно посчитать количество заказов для каждого клиента, представление с агрегированным результатом избавляет от необходимости многократных вычислений.SUM()используется для подсчета суммы значений в столбце. В представлениях это полезно для анализа финансовых данных, таких как общая сумма продаж или расходов за определенный период.AVG()вычисляет среднее значение в столбце. Например, для анализа среднего дохода клиентов, представление может сразу вернуть этот показатель, избегая необходимости расчета через отдельные запросы.MIN()иMAX()позволяют находить минимальные и максимальные значения в столбце. Это может быть полезно для поиска наименьшей или наибольшей суммы, цены, даты и других метрик.
Пример создания представления с использованием агрегатных функций:
CREATE VIEW sales_summary AS
SELECT customer_id,
COUNT(order_id) AS total_orders,
SUM(order_amount) AS total_spent,
AVG(order_amount) AS avg_order_value
FROM orders
GROUP BY customer_id;В этом примере представление sales_summary агрегирует информацию о заказах, группируя их по идентификатору клиента. Это позволяет быстро получить статистику по каждому клиенту, не выполняя сложных расчетов в реальном времени.
При работе с агрегатными функциями важно учитывать следующие рекомендации:
- Использование
GROUP BYв представлении поможет правильно сгруппировать данные перед применением агрегатных функций. - Старайтесь минимизировать количество вычислений внутри представлений, чтобы ускорить их выполнение. Лучше вычислять агрегированные значения один раз, чем выполнять те же операции многократно.
- Не забывайте о производительности. Использование агрегатных функций на больших объемах данных может существенно замедлить выполнение запросов, поэтому важно следить за правильностью индексации столбцов, которые участвуют в агрегации.
Грамотно построенные представления с агрегатными функциями ускоряют работу с данными, а также могут быть полезны для регулярных отчетов и аналитики. Они позволяют избавиться от необходимости многократных вычислений и улучшить общую производительность системы.
Как обновлять данные в представлениях с ограничениями
Первое важное ограничение связано с тем, что представление должно быть «обновляемым». Это означает, что оно не должно содержать агрегатных функций, подзапросов в SELECT-части, объединений (JOIN), подзапросов в WHERE, или DISTINCT. Эти конструкции делают представление неактуальным для обновления данных, так как они нарушают связь между представлением и исходными таблицами.
Для обновления данных через представление, оно должно быть связано с одной таблицей, и все столбцы, которые могут быть обновлены, должны быть однозначно определены. В случае с несколькими таблицами или сложными условиями, обновление будет невозможно без вмешательства в саму структуру представления. Также важно, чтобы для каждого обновления существовали однозначные ключи, связывающие записи в представлении с записями в исходных таблицах.
Если представление строится на основе нескольких таблиц (например, через объединения), для обновления данных потребуется использовать INSTEAD OF триггеры. Эти триггеры позволяют перехватывать операцию обновления и перенаправлять её в нужную таблицу или таблицы, что даёт возможность контролировать изменения данных более гибко. Например, триггер может определить, какие из таблиц нужно обновить, и какие данные в них изменить в зависимости от конкретной записи представления.
Стоит помнить, что обновление данных в представлениях с ограничениями требует осторожности, поскольку любое изменение данных может нарушить целостность связей между таблицами. Поэтому при проектировании таких представлений необходимо учитывать не только технические аспекты, но и бизнес-логику работы с данными, чтобы обновления не приводили к потерям или искажению информации.
Наконец, важно помнить, что в некоторых СУБД (например, в PostgreSQL) поддержка обновлений через представления может быть ограничена, что накладывает дополнительные требования на проектирование системы. В таких случаях может потребоваться использование альтернативных подходов, таких как обновление через временные таблицы или обработка данных с использованием хранимых процедур.
Как решить проблемы производительности при использовании представлений
При работе с представлениями в SQL возможны проблемы с производительностью, особенно когда они используются для обработки больших объемов данных. Чтобы минимизировать эти проблемы, важно учитывать несколько факторов и применять эффективные техники оптимизации.
- Использование индексов на базовых таблицах. Представления не хранят данные, а лишь сохраняют SQL-запрос. Если запросы, из которых состоит представление, обрабатывают большие таблицы, важно убедиться, что на этих таблицах имеются индексы для ускорения выборок.
- Избегать избыточных вычислений. Часто представления содержат сложные вычисления или агрегации, которые выполняются при каждом запросе. Лучше использовать материализованные представления, если требуется часто выполнять одну и ту же агрегацию, чтобы результаты кэшировались.
- Оптимизация SQL-запросов в представлениях. Использование эффективных соединений (например, INNER JOIN вместо OUTER JOIN, когда это возможно), уменьшение подзапросов, упрощение выражений – все это может значительно улучшить производительность. Пример: использование фильтрации в WHERE, а не в HAVING.
- Минимизация количества представлений. Слишком большое количество вложенных представлений может замедлить выполнение запросов, поскольку каждое из них требует выполнения подзапроса. Лучше делать представления максимально простыми и использовать их только по мере необходимости.
- Применение материализованных представлений. Если представление используется часто и выполняет сложные вычисления, материализованное представление может значительно ускорить выполнение запросов, так как оно сохраняет результаты на диск и обновляется по расписанию.
- Мониторинг и анализ выполнения. Для выявления узких мест можно использовать инструменты профилирования запросов, такие как EXPLAIN в PostgreSQL или SQL Server Profiler. Это позволит увидеть, какие части запроса занимают больше времени, и даст возможность оптимизировать их.
- Обновление представлений в реальном времени. В случае работы с динамически изменяющимися данными следует тщательно подходить к вопросу обновления данных в представлениях. Регулярные обновления представлений могут помочь избежать устаревших данных, но это также может негативно сказаться на производительности, если они происходят слишком часто.
Комплексный подход к этим вопросам поможет улучшить производительность системы при использовании представлений, снизив нагрузку на базу данных и ускорив время отклика приложений.
Как применять индексы для ускорения работы с представлениями
Для эффективного использования индексов с представлениями следует учитывать несколько факторов:
1. Индексы на столбцах, часто используемых в WHERE и JOIN. Представления часто включают объединение нескольких таблиц, а также фильтрацию данных. Индексы на столбцах, которые активно участвуют в условиях фильтрации (например, в WHERE или JOIN), могут значительно ускорить выполнение запросов. Например, если представление объединяет таблицы по столбцу `user_id`, наличие индекса на этом столбце в обеих таблицах повысит скорость выполнения запроса.
2. Использование covering индексов. Покрывающие индексы содержат все столбцы, которые используются в запросе, что позволяет избежать дополнительного обращения к таблице. Если запрос к представлению включает только те столбцы, которые уже присутствуют в индексе, то СУБД может использовать только индекс, исключив чтение данных из таблицы. Это особенно полезно при сложных запросах, где требуется выборка большого числа строк, но только ограниченное количество столбцов.
3. Материализованные представления. В некоторых случаях можно создать материализованное представление, которое фактически является сохраненной копией данных. Для таких представлений индексы создаются как для обычных таблиц, что позволяет существенно ускорить доступ к данным. Материализованные представления актуальны, если данные не изменяются часто и требуют быстрого доступа для отчетности или аналитики.
4. Обновления индексов. Когда данные в таблицах изменяются (например, через INSERT, UPDATE или DELETE), индексы должны обновляться. Это может привести к снижению производительности, если запросы выполняются слишком часто или если таблицы содержат большое количество данных. В таких случаях важно правильно настроить частоту обновлений индексов или использовать частичные индексы для ограниченных наборов данных.
5. Частичные индексы. Если представление использует только подмножество данных, например, фильтруя записи по дате или статусу, можно создать частичные индексы. Это индексы, которые создаются только для части таблицы, где данные соответствуют определенному условию. Они могут значительно ускорить работу, так как индексируется лишь та часть таблицы, которая активно используется в запросах.
6. Порядок индексов в запросах. Иногда можно ускорить выполнение запросов, если правильно оптимизировать порядок соединений таблиц. Индексы на ключевых столбцах, участвующих в JOIN, могут ускорить эти операции. Однако стоит помнить, что наличие индекса на одном столбце не всегда гарантирует ускорение. Важно, чтобы SQL-оптимизатор правильно использовал индексы в зависимости от конкретного запроса.
Использование индексов для ускорения работы с представлениями – это мощный инструмент, но важно помнить, что индексы требуют дополнительного пространства и могут замедлить операции записи. Баланс между производительностью чтения и записи должен быть найден на основе анализа конкретных запросов и бизнес-требований.
Вопрос-ответ:
Что такое представление в SQL и зачем оно нужно?
Представление в SQL — это сохранённый запрос, который позволяет создать виртуальную таблицу. Его используют для упрощения работы с базой данных, поскольку оно позволяет объединять данные из нескольких таблиц, скрывать сложные запросы и повышать читаемость кода. Вместо того, чтобы каждый раз писать сложный запрос, можно просто обратиться к представлению, что делает код более чистым и понятным.
Какие преимущества дает использование представлений в SQL при работе с базой данных?
Использование представлений позволяет улучшить управление данными. С помощью представлений можно создавать удобные виртуальные таблицы для регулярных запросов, скрывая детали реализации и упрощая работу с данными. Это помогает избежать ошибок, когда необходимо использовать одинаковые запросы в нескольких местах, и ускоряет разработку. Представления также могут быть полезны для организации доступа, так как они позволяют ограничить видимость данных для разных пользователей, предоставляя доступ только к нужной информации.
Можно ли обновлять данные через представление в SQL?
Да, в некоторых случаях можно обновлять данные через представление. Однако это возможно только если представление напрямую связано с одной таблицей и не включает агрегатные функции или соединения. В случае простых представлений, которые состоят только из одной таблицы, изменения, сделанные через представление, будут автоматически отражаться в исходной таблице. Однако если представление содержит более сложные запросы (например, объединение нескольких таблиц), то обновление данных через представление будет невозможно.
Как повысить производительность запросов, используя представления?
Использование представлений может повысить производительность запросов, так как они позволяют уменьшить сложность SQL-кода и минимизировать необходимость повторного выполнения одинаковых операций. Например, если запрос часто используется для извлечения данных, создание представления позволяет выполнить эти операции заранее, и вместо многократного вычисления запроса, будет использоваться готовая виртуальная таблица. Однако важно учитывать, что представления не хранят данные, а лишь сохраняют структуру запроса. В некоторых случаях для увеличения производительности лучше использовать материализованные представления, которые сохраняют результат запроса на диске и позволяют быстрее получать данные.
Что такое представление в SQL и для чего оно используется?
Представление в SQL — это сохранённый запрос, который можно рассматривать как виртуальную таблицу. Оно не содержит данных, а лишь определяет, как данные должны быть отображены при запросе. Представления позволяют упрощать сложные запросы, скрывать детали работы с таблицами, а также повышать безопасность, ограничив доступ к определённым столбцам или строкам таблицы.