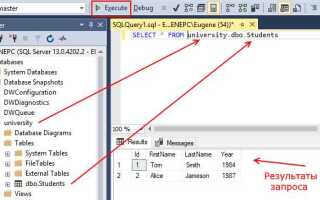
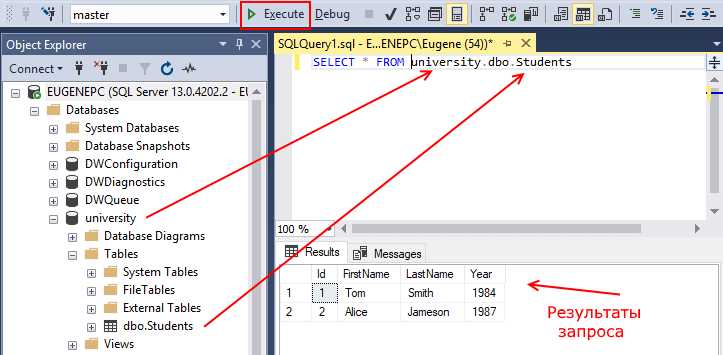
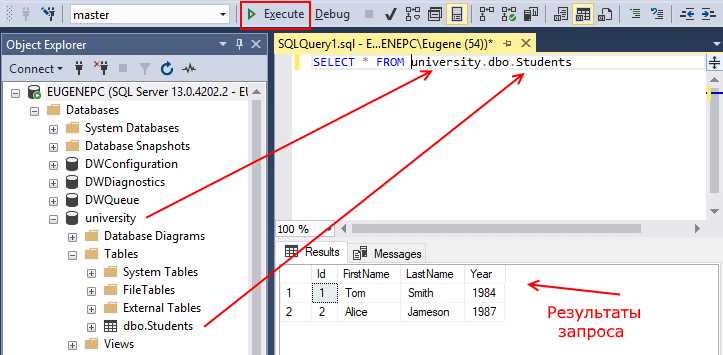
Для успешной работы с базой данных важно правильно строить SQL-запросы, начиная с их формирования. Открытие запроса в SQL – это первый и ключевой шаг на пути к получению необходимых данных. Однако многие начинающие разработчики часто допускают ошибки на этом этапе, что приводит к проблемам с производительностью или неправильным результатам. Важно не только правильно написать запрос, но и понимать принципы его оптимизации с самого начала.
Основные шаги при открытии запроса заключаются в выборе подходящего типа операции – будь то SELECT для извлечения данных, INSERT для добавления новых строк или UPDATE для изменения существующих записей. Начинать запрос следует с четкого указания цели: если нужно извлечь данные, важно точно указать, какие столбцы нужны, чтобы не перегружать запрос лишней информацией. Также стоит учитывать, что в SQL не существует «по умолчанию» выборки всех столбцов, что делает использование * избыточным и нежелательным для эффективной работы.
Кроме того, на стадии открытия запроса стоит обратить внимание на параметры фильтрации, такие как WHERE. Это критический момент, так как без фильтрации запрос может возвращать слишком много данных, что увеличит нагрузку на сервер. Четкие условия фильтрации позволяют минимизировать объем передаваемой информации и ускорить выполнение запроса.
Важным элементом правильного открытия запроса является и понимание структуры данных. Для эффективной работы с базой необходимо знание индексов и связей между таблицами, так как от этого зависит выбор правильных операторов соединений. Использование JOIN или INNER JOIN должно быть осознанным решением в зависимости от того, какие данные нужны в конечном итоге.
Как выбрать подходящий тип SQL-запроса для задачи
При выборе типа SQL-запроса важно опираться на цели задачи. Каждый запрос имеет свою область применения, и неправильный выбор может привести к неэффективной работе с базой данных.
1. Запросы SELECT необходимы для извлечения данных. Они используются, когда требуется получить информацию из одной или нескольких таблиц. Если задача включает фильтрацию или сортировку данных, добавляются операторы WHERE и ORDER BY. Также важно учитывать необходимость объединения таблиц с помощью JOIN, если данные распределены по нескольким таблицам.
2. Запросы INSERT применяются, когда требуется добавить новые строки в таблицу. Это стандартный запрос для записи данных. Важно тщательно проверять целостность данных перед вставкой, чтобы избежать нарушений ограничений (например, уникальности значений). В случае массовой вставки данных стоит использовать команду INSERT с множественными значениями для повышения производительности.
3. Запросы UPDATE используют, когда нужно изменить существующие записи в базе данных. Важно всегда ограничивать область обновления через WHERE, чтобы избежать изменения всех строк в таблице. Если планируется обновление нескольких строк, стоит учитывать производительность, так как массовое обновление может занять значительное время при большом объеме данных.
4. Запросы DELETE нужны для удаления данных. Как и в случае с UPDATE, обязательно указывайте условие через WHERE, чтобы избежать удаления всех данных из таблицы. Для ускорения выполнения удаления можно использовать операторы, такие как TRUNCATE, когда требуется полностью очистить таблицу без записи в журнал изменений.
5. Запросы для агрегации (например, с использованием функций COUNT, SUM, AVG) применяются, когда необходимо провести статистический анализ данных. Они используются для получения суммарной информации по определенным группам данных, например, по категориям товаров или временным промежуткам. Необходимо помнить, что операции с большими объемами данных требуют дополнительных усилий для оптимизации, таких как индексация.
6. Запросы на создание и изменение структуры базы данных (например, CREATE, ALTER, DROP) применяются при необходимости изменения схемы базы данных. Эти запросы должны быть использованы с осторожностью, так как они могут привести к потерям данных или нарушению работы приложений, использующих базу данных. Прежде чем выполнять такие запросы, всегда выполняйте резервное копирование базы данных.
Правильный выбор запроса зависит от конкретной задачи. Для анализа данных лучше использовать SELECT с агрегацией, для внесения изменений – UPDATE, а для обработки новых данных – INSERT. Основной фактор, который влияет на выбор типа запроса, – это как именно нужно взаимодействовать с данными (извлечение, изменение, удаление) и каково требование к производительности и безопасности выполнения этих операций.
Как правильно использовать операторы SELECT и WHERE для фильтрации данных
Оператор SELECT в SQL используется для выборки данных из базы данных. С помощью этого оператора можно извлечь определённые столбцы или все данные из таблицы. Однако для более точной работы с данными часто требуется фильтрация информации, что позволяет оператор WHERE. Его правильное использование существенно повышает эффективность запросов и сокращает количество лишней информации.
Оператор SELECT начинается с указания нужных столбцов или с символа «*», если нужно выбрать все столбцы. Например, запрос:
SELECT имя, возраст FROM сотрудники;
выведет только столбцы «имя» и «возраст» из таблицы «сотрудники». Чтобы сузить выборку, применяют WHERE, который фильтрует строки по заданным условиям.
Оператор WHERE позволяет определить фильтр, который будет применяться к строкам. Условия могут быть разнообразными: числовыми, текстовыми, датами или логическими. Например, чтобы выбрать сотрудников старше 30 лет, запрос будет выглядеть так:
SELECT имя, возраст FROM сотрудники WHERE возраст > 30;
Важно учитывать, что операторы в WHERE могут быть комбинированы с логическими операторами AND, OR и NOT. Они позволяют создавать сложные условия фильтрации. Пример использования оператора AND:
SELECT имя, возраст FROM сотрудники WHERE возраст > 30 AND город = 'Москва';
Здесь данные будут фильтроваться по двум критериям: возраст больше 30 и город равен ‘Москва’. Если необходимо выбрать данные, соответствующие хотя бы одному условию, используйте оператор OR:
SELECT имя, возраст FROM сотрудники WHERE город = 'Москва' OR город = 'Санкт-Петербург';
Если нужно исключить строки, удовлетворяющие определённым условиям, применяется оператор NOT. Например, чтобы исключить сотрудников из Москвы:
SELECT имя, возраст FROM сотрудники WHERE NOT город = 'Москва';
При фильтрации строк также важно учитывать тип данных и соответствие типов данных в условии. Для строковых значений следует использовать кавычки, например:
SELECT имя, возраст FROM сотрудники WHERE город = 'Москва';
Для числовых значений кавычки не требуются. Для дат используют формат, принятой в СУБД, например:
SELECT имя, дата_рождения FROM сотрудники WHERE дата_рождения > '1985-01-01';
Использование оператора LIKE в WHERE помогает фильтровать данные по шаблону. Например, для поиска сотрудников с именем, начинающимся на «А»:
SELECT имя, возраст FROM сотрудники WHERE имя LIKE 'А%';
Также важно помнить, что SQL чувствителен к регистру символов в некоторых СУБД, например, PostgreSQL. Для выполнения нечувствительного к регистру поиска можно использовать функции LOWER или UPPER.
Как подключиться к базе данных через SQL: шаги и настройки
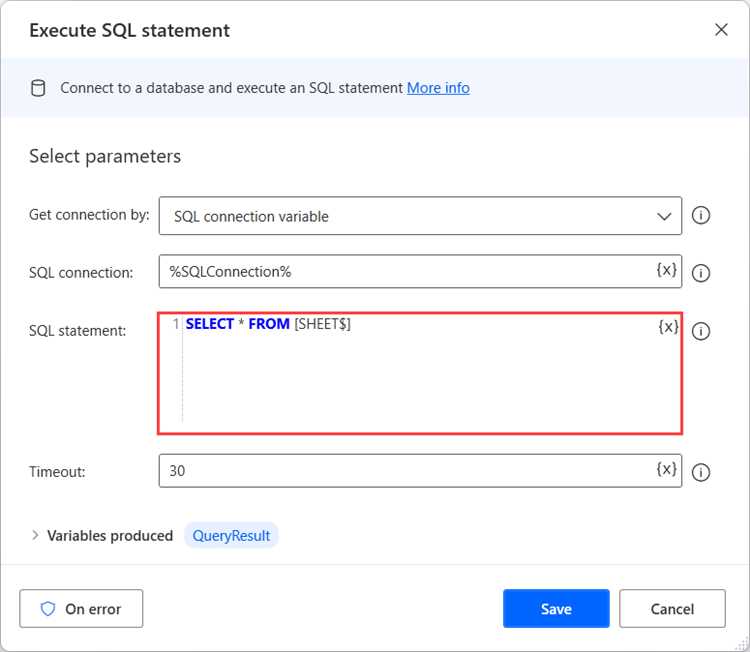
Шаги подключения можно разделить на несколько этапов:
- Выбор подходящего клиента: для каждой СУБД существует свой клиент или интерфейс для работы с SQL. Для MySQL это может быть MySQL Workbench, для PostgreSQL – pgAdmin, для Microsoft SQL Server – SQL Server Management Studio (SSMS). Также можно использовать командные строки и библиотеки в разных языках программирования.
- Получение данных для подключения: для подключения к базе данных вам понадобятся:
- Адрес хоста (например, IP-адрес или доменное имя сервера);
- Имя базы данных;
- Имя пользователя;
- Пароль.
- Настройка соединения: при настройке подключения важно указать правильные параметры:
- Порт сервера (обычно 3306 для MySQL, 5432 для PostgreSQL, 1433 для SQL Server);
- Протокол соединения (TCP/IP обычно используется по умолчанию);
- Дополнительные параметры безопасности, такие как использование SSL-соединения для защиты данных.
- Установка соединения: после ввода всех данных нужно инициировать подключение. В большинстве клиентов для этого есть кнопка «Подключиться». Если параметры введены правильно, соединение будет установлено. Если возникают ошибки, проверьте правильность введенных данных или настройте доступность порта в брандмауэре.
- Проверка соединения: после успешного подключения можно выполнить несколько простых SQL-запросов для проверки соединения, например, запрос
SELECT 1илиSELECT DATABASE(), чтобы убедиться, что работа с базой данных возможна.
Пример подключения к базе данных через командную строку:
mysql -h 192.168.1.100 -u username -p database_name
В данном примере:
-h 192.168.1.100– IP-адрес сервера;-u username– имя пользователя;-p– запрос пароля (он будет введен при подключении);database_name– имя базы данных.
Подключение через PostgreSQL может выглядеть следующим образом:
psql -h 192.168.1.100 -U username -d database_name
Здесь -h указывает на хост, -U – имя пользователя, -d – имя базы данных. После ввода команды будет предложено ввести пароль.
В Microsoft SQL Server для подключения через SQLCMD используется следующий формат:
sqlcmd -S 192.168.1.100 -U username -P password -d database_name
В случае, если вы используете библиотеку для подключения через программный код (например, Python, Java или C#), процесс подключения будет аналогичен, но будет выполняться через соответствующие драйверы и API.
Проверьте, что ваш сервер доступен по сети и настроены правильные права доступа на сервере, иначе подключение не будет возможным. Важно помнить, что безопасность соединения должна быть на первом месте, и всегда стоит использовать шифрование и защиту пароля.
Как использовать JOIN для объединения нескольких таблиц
JOIN в SQL позволяет объединять данные из нескольких таблиц на основе логической связи между ними. Этот оператор используется для извлечения данных, которые могут быть распределены по различным таблицам в базе данных. Главное – правильно указать условие для соединения таблиц.
Самый распространённый тип соединения – это INNER JOIN. Он возвращает только те строки, которые имеют совпадение в обеих таблицах. Пример запроса:
SELECT employees.name, departments.department_name FROM employees INNER JOIN departments ON employees.department_id = departments.id;
LEFT JOIN (или LEFT OUTER JOIN) возвращает все строки из левой таблицы, даже если для них нет соответствующих строк в правой таблице. Это полезно, когда необходимо получить все записи из одной таблицы, независимо от того, существуют ли связанные данные в другой таблице. Пример:
SELECT orders.order_id, customers.customer_name FROM orders LEFT JOIN customers ON orders.customer_id = customers.id;
RIGHT JOIN работает аналогично LEFT JOIN, но возвращает все строки из правой таблицы и только те строки из левой, которые соответствуют условию соединения. Этот тип соединения используется реже, так как аналогичный результат можно получить с помощью LEFT JOIN, поменяв местами таблицы.
FULL OUTER JOIN объединяет результаты LEFT и RIGHT JOIN, возвращая все строки из обеих таблиц, независимо от наличия совпадений. В SQL-серверах, не поддерживающих FULL OUTER JOIN напрямую, можно использовать UNION для симуляции такого поведения.
Когда необходимо соединить несколько таблиц, просто комбинируйте различные типы JOIN. Пример сложного запроса, объединяющего три таблицы:
SELECT orders.order_id, customers.customer_name, products.product_name FROM orders INNER JOIN customers ON orders.customer_id = customers.id INNER JOIN order_items ON orders.id = order_items.order_id INNER JOIN products ON order_items.product_id = products.id;
Этот запрос извлекает информацию о заказах, клиентах и продуктах. Использование нескольких соединений позволяет собирать данные из нескольких источников, но важно следить за тем, чтобы условия соединений были правильными и не создавали избыточных или неверных результатов.
Для оптимизации запросов важно учитывать индексы на столбцах, используемых для соединения, и избегать избыточных объединений, которые могут существенно повлиять на производительность базы данных.
Как гарантировать корректность данных при выполнении UPDATE или DELETE
Операции UPDATE и DELETE могут значительно изменить состояние данных в базе. Неправильное использование этих запросов приведет к потерям информации или повреждению базы данных. Чтобы минимизировать риски, необходимо соблюдать несколько практик.
- Использование WHERE: всегда применяйте условие WHERE, чтобы ограничить область воздействия запроса. Без этого оператор затронет все записи в таблице, что приведет к непредсказуемым результатам.
- Проверка условий перед выполнением: перед применением UPDATE или DELETE всегда стоит сначала выполнить SELECT с теми же условиями. Это поможет увидеть, какие именно записи будут изменены или удалены, и избежать случайных изменений.
- Транзакции: всегда используйте транзакции для выполнения изменений. Они позволяют откатить операции в случае ошибок. Это особенно важно при массовых изменениях данных. Пример:
BEGIN TRANSACTION; UPDATE table_name SET column = value WHERE condition; COMMIT;
- Резервное копирование: перед массовыми изменениями данных всегда делайте резервные копии. Это позволит восстановить данные, если что-то пойдет не так.
- Использование ограничений и триггеров: используйте ограничения целостности (например, FOREIGN KEY) и триггеры для предотвращения нежелательных изменений. Это может защитить таблицы от некорректных данных, даже если запросы пытаются их нарушить.
- Логирование изменений: на практике важно вести лог всех операций UPDATE и DELETE, чтобы можно было отслеживать, какие изменения были сделаны и кто их инициировал. Это особенно полезно в крупных проектах с несколькими пользователями.
- Проверка количества измененных строк: после выполнения запроса проверьте, сколько строк было затронуто. Это поможет убедиться, что запрос выполнялся именно так, как предполагалось. Например, в случае с UPDATE вы можете использовать конструкцию
ROW_COUNT()для проверки числа затронутых записей.
Следование этим рекомендациям поможет избежать потерь данных и повысить безопасность работы с базой данных при использовании команд UPDATE и DELETE.
Как отлаживать и оптимизировать SQL-запросы
Для эффективной работы с SQL-запросами важно не только корректно их писать, но и уметь находить и устранять проблемы производительности. Основные подходы к отладке и оптимизации запросов включают использование инструментов профилирования, индексов и правильных алгоритмов обработки данных.
Первый шаг при отладке запроса – это проверка его выполнения с помощью EXPLAIN (или аналога для других СУБД). Этот инструмент позволяет увидеть, какие индексы и методы доступа к данным использует сервер. Он помогает выявить узкие места, такие как полные сканирования таблиц или неэффективное использование индексов. Анализ результатов EXPLAIN помогает понять, как база данных решает задачу, и где нужно вмешательство.
Важно отслеживать время выполнения запроса. В MySQL, PostgreSQL и других СУБД можно включить журнал запросов, чтобы понять, какие из них занимают слишком много времени. На основе этих данных можно определить, где именно требуется улучшение – возможно, нужно переработать запрос или добавить индексы для ускорения операций поиска.
Оптимизация индексов – ключевой аспект ускорения запросов. Правильно настроенные индексы значительно уменьшают время выполнения запросов, особенно в больших таблицах. Однако чрезмерное количество индексов может замедлить операции вставки и обновления, так как каждый индекс будет требовать дополнительной обработки при изменении данных. Необходимо балансировать между количеством индексов и частотой операций на данных.
Переписывание запросов для уменьшения количества выполняемых операций также может значительно улучшить производительность. Например, замена подзапросов на соединения (JOIN) или использование агрегатных функций (например, COUNT, SUM) вместо нескольких запросов может ускорить выполнение. Важно избегать использования SELECT * – это всегда приводит к лишней обработке данных, особенно если таблица содержит много колонок.
Также следует учитывать использование ограничений в запросах. Например, LIMIT или WHERE позволяют уменьшить объем возвращаемых данных, что может ускорить выполнение запросов, особенно при выборке только нужных записей. Использование правильных типов данных также может помочь в оптимизации, так как использование более компактных типов данных снижает нагрузку на сервер.
Наконец, стоит следить за блокировками. Если в запросах используется многозадачность или транзакции, необходимо учитывать возможные блокировки. Тщательный анализ и предотвращение таких блокировок может предотвратить снижение производительности системы.