Подзапросы в SQL могут казаться удобным инструментом для решения сложных задач, но они не всегда являются наилучшим выбором с точки зрения производительности и читаемости кода. В некоторых случаях использование подзапросов может замедлить выполнение запросов, особенно при работе с большими объемами данных. Оптимизация запросов и поиск способов переписать их без подзапросов – важный навык для разработчиков, который позволяет улучшить производительность приложений и сократить время отклика баз данных.
Один из распространенных способов переписать запрос без подзапросов – это использовать операторы JOIN и LEFT JOIN. Вместо того чтобы писать подзапрос для извлечения данных из других таблиц, можно объединить таблицы с помощью соединений. Это часто сокращает время выполнения, поскольку SQL-сервер может более эффективно обработать соединенные таблицы.
Другим важным методом является использование агрегатных функций с группировкой данных. Часто подзапросы применяются для того, чтобы сгруппировать или подсчитать значения, которые затем используются в основном запросе. Однако, большинство таких операций можно выполнить с использованием группировки непосредственно в главном запросе, что позволяет избежать дополнительной нагрузки, связанной с подзапросами.
Кроме того, для более сложных случаев, когда подзапросы не обходятся без них, можно применить такие техники, как использование CROSS APPLY или OUTER APPLY. Эти операторы позволяют работать с набором данных, как если бы они были подзапросом, но они выполняются более эффективно в некоторых случаях, чем обычные подзапросы.
Преимущества переписывания запроса без подзапроса

Кроме того, запросы без подзапросов часто выполняются быстрее. Подзапросы могут приводить к дополнительным вычислениям на уровне вложенных запросов, что увеличивает нагрузку на базу данных. В случае переписывания запроса с использованием соединений (JOIN) или других методов, база данных может эффективно использовать индексы и оптимизировать выполнение запроса.
При переписывании запроса без подзапроса также становится проще использовать индексы. Подзапросы часто затрудняют правильное использование индексов, поскольку база данных может не всегда корректно определить, как их применить в контексте вложенного запроса. Без подзапросов запросы становятся более прозрачными для оптимизаторов запросов, что повышает вероятность использования индексов для улучшения скорости выполнения.
Переписывание запроса также способствует лучшей читаемости и поддерживаемости кода. Подзапросы могут создавать излишнюю вложенность и усложнять логику запроса, что затрудняет его анализ и модификацию. Простой и прямолинейный запрос без подзапроса обычно легче поддерживать в долгосрочной перспективе, особенно в крупных проектах с постоянными изменениями в структуре данных.
Наконец, запросы без подзапросов обычно менее подвержены ошибкам, связанным с порядком выполнения запросов и контекстами. В подзапросах могут возникать ситуации, когда данные, используемые во внешнем запросе, не соответствуют данным, получаемым из подзапроса, что приводит к неверным результатам. Запросы без подзапросов избавляют от этой проблемы, улучшая стабильность и надежность выполнения.
Использование JOIN для замены подзапросов в SELECT
Подзапросы в SQL могут создавать избыточные вычисления и ухудшать производительность, особенно при работе с большими объемами данных. Один из способов улучшить выполнение запросов – заменить подзапросы на использование оператора JOIN. Это позволяет выполнять объединение таблиц на одном уровне запроса, что часто оказывается более эффективным, чем использование вложенных запросов.
Для замены подзапроса на JOIN важно понять, как правильно структурировать запрос и какие типы JOIN применить в зависимости от логики задачи. Например, если в подзапросе используется фильтрация по значению из другой таблицы, можно использовать INNER JOIN или LEFT JOIN, чтобы объединить таблицы на основе общего столбца.
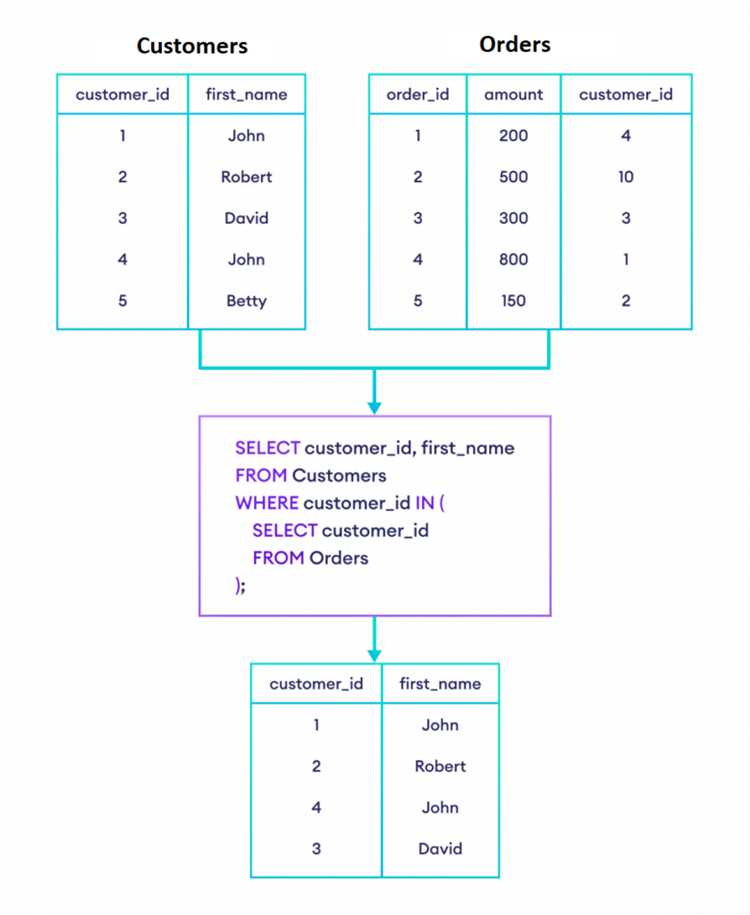
Рассмотрим пример. Пусть у нас есть таблицы orders и customers, и мы хотим найти заказы, сделанные конкретными клиентами. Используя подзапрос, это может выглядеть так:
SELECT order_id, order_date
FROM orders
WHERE customer_id IN (SELECT customer_id FROM customers WHERE city = 'Москва');Вместо подзапроса можно использовать JOIN, чтобы избежать вложенности и улучшить читаемость и производительность запроса:
SELECT orders.order_id, orders.order_date
FROM orders
JOIN customers ON orders.customer_id = customers.customer_id
WHERE customers.city = 'Москва';В данном примере JOIN выполняет объединение таблиц на основе поля customer_id, что позволяет избежать подзапроса в WHERE. Это улучшает читаемость и делает запрос более оптимизированным.
Еще один случай, когда JOIN может быть полезен – когда подзапрос используется для выборки агрегированных данных. Например, если нам нужно выбрать клиентов, сделавших заказы на сумму больше 10,000, с использованием подзапроса это будет выглядеть так:
SELECT customer_id
FROM orders
GROUP BY customer_id
HAVING SUM(order_amount) > 10000;Такой запрос также можно преобразовать с использованием JOIN:
SELECT customers.customer_id
FROM customers
JOIN orders ON customers.customer_id = orders.customer_id
GROUP BY customers.customer_id
HAVING SUM(orders.order_amount) > 10000;Этот пример показывает, как можно использовать JOIN для работы с агрегированными данными и избежать подзапросов в SELECT или HAVING.
Важно помнить, что выбор между подзапросами и JOIN зависит от задачи. Иногда подзапросы могут быть более логичными и удобными для реализации, но часто JOIN обеспечивают лучшую производительность, особенно при правильной индексации таблиц.
Как применить LEFT JOIN вместо подзапроса с агрегацией
Когда в запросе используется подзапрос с агрегацией, часто можно добиться того же результата, применив LEFT JOIN. Основной принцип заключается в том, что подзапрос с агрегацией выполняет расчёты для каждой строки, что может привести к излишним вычислениям. Используя LEFT JOIN, можно выполнить агрегацию на уровне внешней таблицы, сократив количество операций и улучшив производительность.
Предположим, у нас есть две таблицы: orders и customers. Необходимо получить информацию о клиентах с их последними заказами и суммой заказов. Один из способов решения задачи – это использование подзапроса с агрегацией. Например:
SELECT c.customer_id, c.name,
(SELECT SUM(o.amount)
FROM orders o
WHERE o.customer_id = c.customer_id
AND o.order_date > '2023-01-01') AS total_amount
FROM customers c;
Однако такой подход не всегда оптимален, особенно если таблица orders велика, так как подзапрос будет выполняться для каждой строки из customers.
Вместо этого можно использовать LEFT JOIN с агрегацией. В этом случае агрегация происходит один раз для всех строк в таблице заказов, а затем результат присоединяется к таблице клиентов. Пример запроса:
SELECT c.customer_id, c.name,
COALESCE(SUM(o.amount), 0) AS total_amount
FROM customers c
LEFT JOIN orders o ON o.customer_id = c.customer_id
AND o.order_date > '2023-01-01'
GROUP BY c.customer_id, c.name;
В этом примере агрегация выполняется после выполнения соединения с таблицей заказов. Это сокращает количество операций и позволяет базе данных эффективно обработать данные с помощью одного шага агрегации, а не множества подзапросов.
Основные преимущества такого подхода:
- Уменьшается количество вычислений, особенно если подзапрос выполняется для каждой строки в основной таблице.
- Производительность запроса улучшается за счёт оптимизации агрегации на уровне соединения.
- Запрос становится проще для понимания и сопровождения.
Важно помнить, что использование LEFT JOIN может привести к появлению строк с NULL значениями для тех клиентов, у которых нет заказов после определенной даты. В таких случаях можно использовать функцию COALESCE для замены NULL значений на ноль.
Оптимизация запросов с условием WHERE без подзапроса
Для улучшения производительности запросов, использующих условие WHERE, без применения подзапросов важно правильно строить логику выборки данных. Один из подходов – замена подзапроса на прямое соединение таблиц. Это позволяет избежать многократных вызовов базы данных и сократить время выполнения запроса.
Когда подзапрос применяется для фильтрации данных, его можно заменить на соединение через JOIN. В большинстве случаев это снижает сложность выполнения, так как запрос с объединением таблиц выполняется быстрее. Например, если подзапрос используется для фильтрации по значениям в другой таблице, то вместо подзапроса можно выполнить JOIN с фильтрацией в основном запросе.
Пример подзапроса:
SELECT name FROM employees WHERE department_id IN (SELECT id FROM departments WHERE name = 'IT');
Эквивалентный запрос без подзапроса с использованием JOIN:
SELECT e.name FROM employees e JOIN departments d ON e.department_id = d.id WHERE d.name = 'IT';
Другим методом является использование EXISTS. Если подзапрос проверяет существование записи, то его можно заменить на EXISTS с JOIN. Такая конструкция оптимизирует запрос, исключая необходимость выполнения подзапроса для каждой строки.
Пример с подзапросом:
SELECT name FROM employees WHERE EXISTS (SELECT 1 FROM departments WHERE id = employees.department_id AND name = 'IT');
Эквивалентный запрос с использованием JOIN:
SELECT e.name FROM employees e JOIN departments d ON e.department_id = d.id WHERE d.name = 'IT';
Также стоит учитывать, что операции с использованием агрегатных функций в подзапросах могут быть заменены на оконные функции. Это позволяет выполнить более сложные вычисления и фильтрацию данных без необходимости выносить логику в отдельный подзапрос. Например, для подсчета количества сотрудников в каждом департаменте можно использовать оконную функцию COUNT() с PARTITION BY вместо подзапроса.
Пример с подзапросом:
SELECT name FROM employees WHERE department_id IN (SELECT department_id FROM employees GROUP BY department_id HAVING COUNT(*) > 10);
Эквивалентный запрос с оконной функцией:
SELECT name FROM employees WHERE COUNT(*) OVER (PARTITION BY department_id) > 10;
Таким образом, использование JOIN, EXISTS и оконных функций вместо подзапросов может значительно улучшить производительность запросов и упростить их структуру, особенно при работе с большими объемами данных.
Применение оконных функций вместо подзапросов
Оконные функции предоставляют мощный способ обработки данных без необходимости использовать подзапросы, что существенно улучшает производительность запросов. В отличие от подзапросов, оконные функции позволяют выполнять вычисления по набору строк, не меняя структуру выборки, что делает их более гибкими и эффективными.
Один из основных случаев, когда оконные функции могут заменить подзапросы – это агрегация данных. Например, если требуется посчитать, как много строк существует до текущей строки, можно использовать функцию ROW_NUMBER() вместо подзапроса, который бы вычислял количество строк для каждой группы данных.
Рассмотрим пример запроса, где без оконных функций понадобился бы подзапрос для расчета ранга сотрудников в компании по зарплате:
SELECT employee_id, salary, (SELECT COUNT(*) FROM employees e2 WHERE e2.salary >= e1.salary) AS rank FROM employees e1;
Этот запрос можно переписать с использованием оконной функции RANK(), которая автоматически рассчитывает ранг для каждой строки в пределах заданного окна:
SELECT employee_id, salary, RANK() OVER (ORDER BY salary DESC) AS rank FROM employees;
В данном примере оконная функция RANK() возвращает ранг для каждого сотрудника, основываясь на его зарплате, без необходимости использования подзапроса, что значительно ускоряет выполнение запроса.
ROW_NUMBER()– присваивает уникальный номер строкам, что полезно для случаев, когда нужно сортировать данные и не учитывать дубликаты.RANK()– аналогичнаROW_NUMBER(), но присваивает одинаковые ранги строкам с одинаковыми значениями в сортировке, оставляя пропуски в номерах.DENSE_RANK()– как иRANK(), но не оставляет пропусков в номерах.NTILE(n)– разбивает набор данных наnравных частей и присваивает каждой строке номер ее части.
Оконные функции позволяют избежать сложных подзапросов и сделать запросы более читаемыми и быстрыми. Они позволяют эффективно выполнять агрегации, ранжирование и деление данных, что особенно важно при работе с большими объемами информации.
Применение оконных функций особенно полезно в случае, когда необходимо выполнить сложные вычисления для каждого ряда без изменения самих данных, что невозможно сделать с использованием подзапросов.
Ошибки при переписывании запросов и как их избежать
Переписывание SQL-запросов без использования подзапросов требует тщательной проработки логики и внимания к деталям. Ошибки на этом этапе могут привести к ухудшению производительности, неправильным результатам или даже к полному отказу запроса. Вот основные ошибки, с которыми можно столкнуться, и способы их избежать.
- Игнорирование индексов: При переписывании запроса важно учитывать индексы на таблицах. Использование соединений (JOIN) или фильтрации (WHERE) на колонках без индексов может значительно замедлить выполнение запроса. Рекомендуется перед изменениями проверять, какие индексы присутствуют, и оптимизировать запрос с учётом их наличия.
- Неправильное использование JOIN: Важно не забывать о типах соединений (INNER JOIN, LEFT JOIN и т.д.). Замена подзапроса на соединение может привести к ошибкам в результатах, если тип соединения выбран неверно. Например, использование LEFT JOIN в месте, где требуется INNER JOIN, приведёт к лишним строкам в результате.
- Проблемы с агрегацией: Когда запрос содержит агрегирующие функции (SUM, COUNT, AVG), важно правильно указать условия для группировки (GROUP BY). Ошибка на этом этапе может привести к искажённым результатам. Важно, чтобы все неагрегированные столбцы в SELECT также присутствовали в GROUP BY.
- Потеря оптимизации: Некоторые подзапросы могут использовать оптимизации, которые сложно воспроизвести в запросе без них. Например, подзапросы в WHERE могут автоматически использовать индексы. При переписывании запроса без подзапросов нужно тщательно проверять, чтобы не потерять производительность.
- Избыточные соединения: Иногда при замене подзапросов на соединения происходит дублирование данных или лишние соединения. Это может происходить, если один из столбцов используется не по назначению, либо запрос строится без учёта всех связей между таблицами. Важно проверять, что в результирующем наборе данных нет лишних повторений строк.
- Ошибки в логике объединений: При переписывании запросов важно точно понимать, какие данные должны быть объединены. Ошибки могут возникнуть, если заменить подзапрос на неправильное соединение или добавить лишние условия в ON-клаузулу, что может привести к неверным результатам.
- Невнимательность к порядку выполнения: В SQL запросы выполняются по определённому порядку: сначала фильтрация данных, затем соединения и агрегация. Ошибка в переписанном запросе может заключаться в неправильной последовательности этих операций, что приведёт к неверным данным или снижению производительности. Следует всегда помнить о логическом порядке выполнения запросов.
- Невозможность учёта сложных условий: Иногда подзапросы используются для обработки сложных логических условий или фильтрации, которые сложно выразить с помощью обычных соединений. Неудачная попытка переписать такой запрос может привести к утрате необходимой логики или сложности в понимании запроса.
Для успешной переписки SQL-запросов без подзапросов необходимо тщательно анализировать каждый этап изменения. Следует использовать инструменты для анализа производительности запросов и всегда проверять результаты на тестовых данных, чтобы избежать критичных ошибок в финальной версии запроса.
Вопрос-ответ:
Что такое подзапрос и почему его стоит избегать в SQL запросах?
Подзапрос — это запрос, который встраивается внутрь другого запроса. Он часто используется для выборки данных, которые потом используются в основном запросе. Однако подзапросы могут снижать производительность, так как каждый подзапрос выполняется отдельно и может потребовать дополнительных ресурсов. Кроме того, сложные запросы с подзапросами труднее поддерживать и отлаживать. Вместо подзапросов можно использовать соединения (JOIN), которые могут быть более эффективными.
Какие методы можно использовать для переписывания SQL запроса без подзапроса?
Вместо подзапросов часто применяют операторы JOIN, которые позволяют объединить таблицы и выполнить запрос в одном шаге. Также можно использовать временные таблицы или CTE (Common Table Expressions), чтобы разделить сложный запрос на несколько логических частей. В некоторых случаях применение оконных функций может быть полезно для выполнения тех же операций, что и в подзапросах, но с лучшей производительностью.
Можно ли избежать подзапросов в запросах с агрегацией?
Да, можно. Вместо подзапроса для агрегации данных можно использовать JOIN с группировкой (GROUP BY). Например, вместо того, чтобы в подзапросе сначала вычислять сумму или среднее, а затем использовать эти данные в основном запросе, можно сразу агрегировать данные с помощью JOIN и GROUP BY в одном запросе. Это поможет избежать излишних вычислений и ускорить выполнение запроса.
В каких случаях использование подзапросов все-таки оправдано?
Несмотря на то, что подзапросы часто могут быть заменены JOIN, в некоторых случаях они удобны и полезны. Например, когда нужно выполнить выборку данных из разных таблиц и не требуется их объединение. Также подзапросы могут быть полезны для выполнения условий в WHERE или HAVING, если логика фильтрации слишком сложна для прямого применения в JOIN. Однако следует помнить, что подзапросы могут снизить производительность при больших объемах данных, поэтому важно всегда проверять выполнение запросов с подзапросами с помощью EXPLAIN PLAN.
Как переписать SQL запрос, не используя подзапросы, но сохраняя ту же логику?
Для того чтобы переписать SQL запрос без использования подзапросов, можно применить соединения (JOIN) или объединение (UNION). Вместо того чтобы использовать подзапросы для получения промежуточных данных, можно объединить таблицы напрямую через JOIN, что обеспечит выполнение тех же операций, но без вложенных запросов. Например, если вам нужно получить данные из двух таблиц, можно использовать LEFT JOIN или INNER JOIN, чтобы соединить таблицы по нужным ключам и фильтровать результаты с помощью WHERE. Важно также проверять, чтобы запрос был оптимизирован с точки зрения производительности, поскольку подзапросы могут иногда приводить к неоптимальному выполнению.
Какие преимущества может дать переписанный SQL запрос без подзапросов по сравнению с запросом с ними?
Переписанный запрос без подзапросов может быть более понятным и легче поддерживаемым, так как отсутствие вложенности повышает читаемость кода. Кроме того, такие запросы могут иметь лучшую производительность, особенно если подзапросы используются несколько раз в одном запросе. Прямое соединение таблиц может значительно уменьшить нагрузку на базу данных, так как меньше вычислительных шагов требуется для выполнения запроса. Однако важно помнить, что это не всегда гарантирует улучшение, и для каждого случая нужно проводить тесты производительности, чтобы убедиться, что переписанный запрос действительно эффективнее.