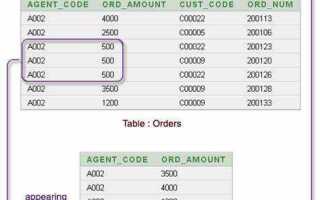
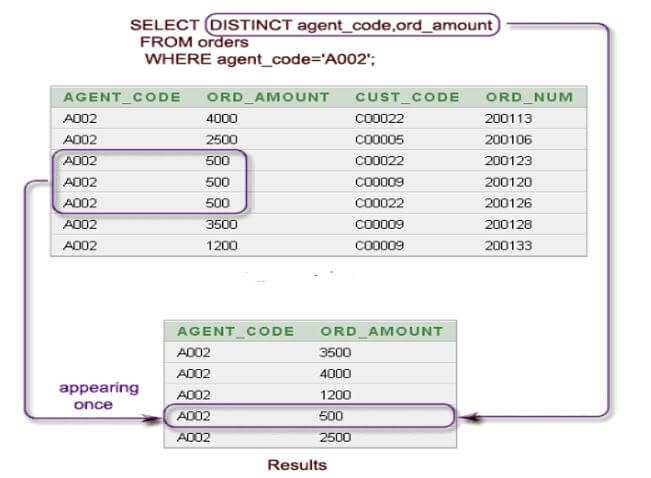
Оператор DISTINCT в SQL используется для удаления повторяющихся строк из результата запроса. При применении DISTINCT в SELECT-запросах, возвращаемые строки будут уникальными по указанным столбцам. Важно понимать, что это работает на уровне всей строки, а не на уровне отдельного столбца. Например, если два столбца в выборке имеют одинаковые значения, то DISTINCT исключит такие строки.
Для правильного использования DISTINCT следует учитывать, что его влияние распространяется на все поля, указанные в SELECT. Если в запросе заданы несколько столбцов, то уникальность определяется по комбинации значений этих столбцов. Это может привести к неожиданным результатам, если столбцы содержат большие объемы данных или имеют небольшие различия, которые могут быть важны для анализа.
Рекомендуется избегать использования DISTINCT в случаях, когда нужно работать с большими объемами данных, так как его выполнение может замедлить запросы. В таких случаях лучше использовать другие методы, такие как агрегатные функции или предварительная фильтрация данных. Важно также помнить, что DISTINCT не изменяет исходные данные в базе, а лишь фильтрует результат выборки, что делает его безопасным инструментом в контексте работы с данными.
Применение DISTINCT для удаления дубликатов в запросах
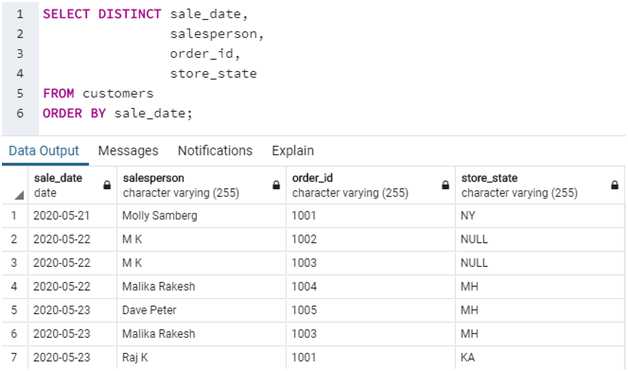
Оператор DISTINCT в SQL позволяет исключить повторяющиеся строки из результата запроса. Он анализирует только те столбцы, которые указаны в запросе, и возвращает уникальные комбинации значений по этим столбцам. Это полезно, когда нужно получить список уникальных записей, например, в случае с данными о пользователях или товарах.
Для использования DISTINCT в запросах необходимо добавить его перед указанием столбцов, которые должны быть уникальными. Например, запрос:
SELECT DISTINCT city FROM customers;
выведет список всех уникальных городов из таблицы customers, убирая дублирующиеся значения. Важно отметить, что DISTINCT применяет фильтрацию ко всей строке данных, а не только к отдельным столбцам. Это означает, что для каждой строки будет проверяться комбинация значений всех указанных столбцов, и дубликаты будут исключены только при полном совпадении значений.
Применение DISTINCT в запросах с несколькими столбцами имеет свои особенности. Например, запрос:
SELECT DISTINCT first_name, last_name FROM employees;
вернет уникальные пары имен и фамилий, что может быть полезно для получения списка сотрудников без повторов. При этом, если два сотрудника имеют одинаковые фамилию и имя, то они будут исключены как дубликаты.
В некоторых случаях использование DISTINCT может негативно повлиять на производительность запроса, особенно если таблица содержит большое количество данных. Для повышения эффективности следует заранее убедиться, что дубликаты действительно существуют, и применять DISTINCT только в случае необходимости.
Стоит помнить, что DISTINCT не удаляет данные из таблиц, а лишь изменяет результат запроса. Если требуется удалить дубликаты в самой таблице, необходимо использовать соответствующие операции, такие как DELETE с подзапросами.
Особенности использования DISTINCT с несколькими столбцами
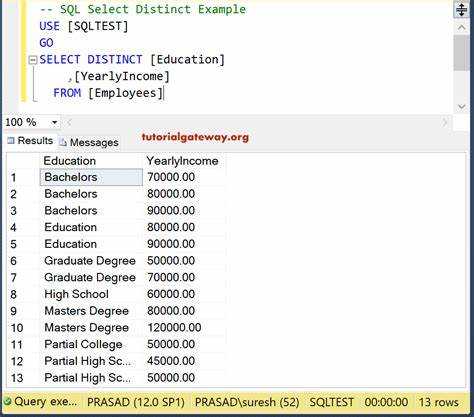
Когда в запросе используются несколько столбцов с оператором DISTINCT, результат будет включать только уникальные комбинации значений из всех указанных столбцов. Это означает, что SQL будет искать строки, в которых все значения в выбранных столбцах уникальны в сочетании, а не по отдельности.
Важно понимать, что DISTINCT применяется ко всем столбцам в списке SELECT. Например, если запрос включает столбцы A и B, DISTINCT будет учитывать сочетание значений столбцов A и B, и только те строки, которые имеют уникальные пары этих значений, попадут в результат. Если два ряда имеют одинаковые значения как для A, так и для B, только один из них будет включен в итоговый результат.
Пример запроса с несколькими столбцами:
SELECT DISTINCT column1, column2 FROM table_name;
Этот запрос вернёт только уникальные пары значений из столбцов column1 и column2. Обратите внимание, что уникальность определяется комбинацией всех указанных столбцов.
Когда работа с несколькими столбцами становится необходимой для оптимизации, важно избегать избыточных данных в запросах. Например, если вы используете DISTINCT с несколькими столбцами в большом наборе данных, это может привести к значительному увеличению времени выполнения запроса, особенно если база данных не имеет индексов по этим столбцам. В таких случаях стоит проанализировать индексирование или рассмотреть использование более эффективных методов агрегации данных.
Также стоит учитывать, что использование DISTINCT с несколькими столбцами может дать неожиданный результат, если не учитывать порядок столбцов. Разная последовательность столбцов может повлиять на итоговые уникальные комбинации. Например, DISTINCT (column1, column2) и DISTINCT (column2, column1) могут вернуть разные наборы данных в зависимости от уникальности каждой пары столбцов.
Если цель запроса – получить уникальные строки по нескольким столбцам, но при этом избежать значительных задержек, можно использовать индексы, которые оптимизируют поиск уникальных значений по этим столбцам. В некоторых случаях может быть эффективнее использовать GROUP BY с агрегатными функциями, особенно если необходимо не просто выбрать уникальные строки, но и агрегировать данные по этим столбцам.
Влияние DISTINCT на производительность запроса
Использование оператора DISTINCT в SQL позволяет исключить дублирующиеся строки из результатов запроса. Однако, помимо улучшения читаемости данных, он может существенно повлиять на производительность, особенно при работе с большими объемами информации. Важно понимать, в каких случаях применение DISTINCT оправдано и как оно влияет на время выполнения запроса.
Основное влияние DISTINCT на производительность связано с необходимостью выполнения дополнительной обработки данных. Для того чтобы удалить дубли, система должна сравнивать строки на уровне всех столбцов, указанных в запросе. Это требует дополнительного времени, особенно если таблица имеет множество строк и столбцов.
- Алгоритм удаления дубликатов: SQL-система сортирует или использует хеширование для обнаружения одинаковых записей. Сортировка данных – более медленный процесс, особенно при отсутствии индексов. В некоторых случаях применение индексов может ускорить работу, но не всегда.
- Ресурсы процессора и памяти: DISTINCT потребляет больше вычислительных ресурсов, так как необходимо хранить уникальные строки в памяти до завершения обработки запроса. Это особенно важно при большом объеме данных или ограничениях по памяти.
- Индексы: Использование индексов на столбцах, участвующих в запросе, может уменьшить время выполнения, поскольку система будет быстрее находить уникальные записи. Однако, если индекс не подходит для уникальности данных, выполнение запроса с DISTINCT может быть медленным.
- Размер выборки: Чем меньше результирующий набор данных, тем меньше влияние DISTINCT на производительность. Проблемы начинают проявляться, если результаты выборки содержат тысячи или миллионы строк.
Для повышения производительности можно использовать следующие рекомендации:
- Избегать избыточного использования DISTINCT: Применяйте оператор DISTINCT только в тех случаях, когда дубли действительно не нужны. В некоторых случаях можно обойтись без этого оператора, например, с использованием агрегатных функций или фильтрации данных до выполнения запроса.
- Оптимизировать запросы: Использование WHERE и JOIN для фильтрации данных до применения DISTINCT позволит уменьшить количество обрабатываемых строк.
- Использовать индексы: Создайте индексы на столбцы, участвующие в запросе с DISTINCT, чтобы ускорить поиск уникальных значений. Особенно это актуально для столбцов, по которым выполняется сортировка или фильтрация.
- Проверить наличие дубликатов на этапе извлечения данных: Если возможно, убирайте дубли с помощью других средств обработки данных на уровне приложения, а не через SQL-запросы.
В целом, использование DISTINCT должно быть обоснованным и продуманным. Для улучшения производительности важно учитывать размер выборки, наличие индексов и способы фильтрации данных. Правильная настройка запросов и индексирование помогут минимизировать возможные потери в производительности.
Как работает DISTINCT в сочетании с агрегатными функциями
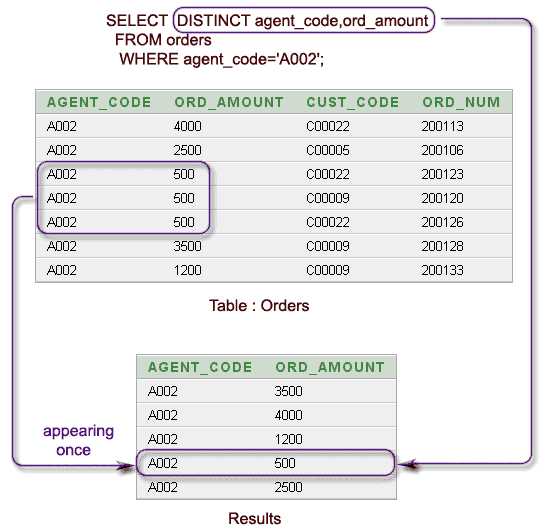
Оператор DISTINCT в SQL используется для исключения дублирующихся значений в результате запроса. В сочетании с агрегатными функциями, такими как COUNT, SUM, AVG, MAX и MIN, DISTINCT позволяет работать с уникальными значениями столбца или выражения, что может значительно изменить поведение этих функций.
Когда DISTINCT применяется с агрегатной функцией, он влияет на данные, которые функция агрегирует. Например, если мы хотим посчитать количество уникальных значений в столбце, используем комбинацию COUNT и DISTINCT:
SELECT COUNT(DISTINCT column_name) FROM table_name;
Это гарантирует, что будут учтены только уникальные значения в столбце, игнорируя все дубли.
Аналогично, если используется агрегатная функция SUM, то DISTINCT будет суммировать только уникальные значения:
SELECT SUM(DISTINCT column_name) FROM table_name;
Важно заметить, что агрегатные функции работают с результатами, которые возвращаются DISTINCT. Это значит, что при использовании SUM(DISTINCT), функция будет учитывать сумму только уникальных значений в столбце, что может отличаться от обычного поведения SUM, который учитывает все значения, включая дубли.
Пример с функцией AVG:
SELECT AVG(DISTINCT column_name) FROM table_name;
В этом случае AVG будет вычислять среднее значение только для уникальных значений, игнорируя все повторяющиеся данные. Это особенно полезно, когда требуется анализировать данные, исключая повторяющиеся записи.
Не стоит забывать, что использование DISTINCT с агрегатными функциями может существенно повлиять на производительность запроса. При работе с большими объемами данных SQL может выполнить дополнительную операцию для исключения дублирующихся значений перед выполнением агрегации, что иногда приводит к увеличению времени выполнения запроса.
Рекомендуется использовать DISTINCT только тогда, когда действительно необходимо работать только с уникальными значениями, поскольку излишнее его использование в сочетании с агрегатными функциями может привести к лишним вычислениям и снизить общую производительность базы данных.
Отличие DISTINCT и GROUP BY в SQL
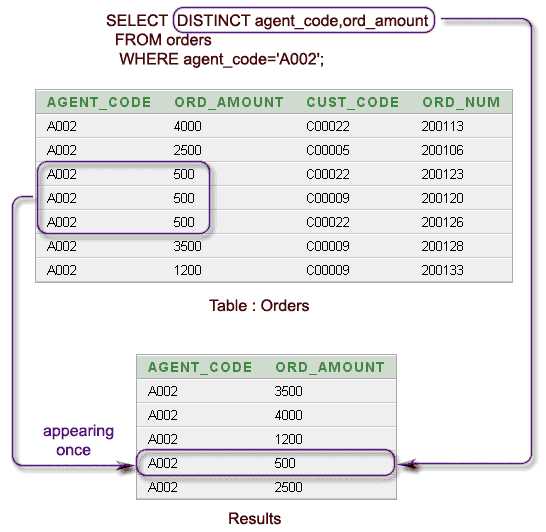
Операторы DISTINCT и GROUP BY в SQL на первый взгляд могут показаться схожими, так как оба используются для работы с уникальными значениями. Однако их назначение и способы применения имеют ключевые различия.
Основное отличие заключается в том, что:
- DISTINCT используется для удаления дублирующихся строк в результате запроса. Он применяется ко всем столбцам, выбранным в запросе. В результате выполнения запроса с DISTINCT, возвращаются только уникальные строки на основе всех выбранных данных.
- GROUP BY группирует строки, имеющие одинаковые значения в указанных столбцах, и позволяет выполнять агрегатные операции (например, SUM, COUNT, AVG) на каждой группе.
Рассмотрим примеры, чтобы понять различия:
- Запрос с DISTINCT:
- Запрос с GROUP BY:
SELECT DISTINCT column_name FROM table_name;
Этот запрос вернет все уникальные значения из столбца column_name.
SELECT column_name, COUNT(*) FROM table_name GROUP BY column_name;
Этот запрос вернет уникальные значения столбца column_name, но также выполнит агрегатную операцию (например, подсчет количества строк) для каждой группы значений.
Ключевые различия:
- Группировка: GROUP BY всегда группирует строки, а DISTINCT только удаляет дубликаты.
- Агрегатные функции: В запросе с GROUP BY можно использовать агрегатные функции, такие как COUNT, SUM, AVG, в то время как с DISTINCT это невозможно.
- Производительность: В некоторых случаях использование GROUP BY может быть менее производительным, если запрос включает агрегатные функции. DISTINCT может быть быстрее, если требуется просто исключить дубликаты.
Когда использовать?
- Используйте DISTINCT, когда вам нужно просто удалить дубликаты и нет необходимости в дополнительных вычислениях или группировке.
- Используйте GROUP BY, если вам необходимо выполнять агрегатные вычисления или группировать данные по нескольким столбцам.
Ошибки и ловушки при использовании DISTINCT
При использовании оператора DISTINCT важно учитывать несколько распространённых ошибок, которые могут существенно повлиять на производительность запросов и на их результаты.
Одна из самых частых проблем – излишнее использование DISTINCT. Это может привести к дополнительной нагрузке на систему. В случае, если уникальность данных обеспечивается другими средствами, например, в рамках схемы данных или на уровне индексов, применение DISTINCT будет неэффективным и может снизить скорость выполнения запроса.
При работе с несколькими столбцами важно помнить, что DISTINCT учитывает уникальные комбинации значений всех указанных столбцов. Это может привести к неожиданным результатам, если разработчик ожидает уникальные значения только по одному из столбцов. Например, если запрос включает несколько столбцов, DISTINCT вернёт все уникальные комбинации, что не всегда соответствует первоначальному запросу.
Также, если в запросе присутствуют вычисляемые поля, функции или операции с данными, результат может оказаться непредсказуемым. В таких случаях важно проверять, как именно работают функции и их влияние на уникальность строк. Например, использование функции округления или преобразования данных может изменить результаты DISTINCT, так как разные данные могут быть интерпретированы как одинаковые.
Не стоит забывать и о производительности. DISTINCT может быть ресурсоёмким, особенно при работе с большими объемами данных. Вместо того чтобы использовать его по умолчанию, лучше подумать о других способах фильтрации данных, таких как использование агрегатных функций (например, COUNT, MAX) или индексов для ускорения поиска уникальных записей.
Наконец, стоит учитывать работу с NULL-значениями. DISTINCT считает NULL-значения одинаковыми, что иногда может вызывать путаницу при ожидании других результатов. Например, если в столбце есть несколько строк с NULL, DISTINCT отфильтрует их как одно значение, что может противоречить логике запроса.
Практические примеры использования DISTINCT в реальных задачах

Оператор DISTINCT часто используется для удаления дублирующихся записей из результатов запросов. Рассмотрим несколько примеров его применения в реальных задачах.
1. Получение списка уникальных клиентов. В базе данных интернет-магазина может быть несколько заказов одного и того же клиента. Для анализа общего числа клиентов, сделавших покупки, необходимо извлечь только уникальные значения из столбца с идентификаторами клиентов. Пример запроса:
SELECT DISTINCT customer_id FROM orders;
2. Анализ различных товаров, заказанных в определённый период. Допустим, требуется получить список уникальных товаров, которые были заказаны в течение месяца. Запрос с использованием DISTINCT поможет убрать дублирующиеся товары из списка:
SELECT DISTINCT product_id FROM order_items WHERE order_date BETWEEN '2025-04-01' AND '2025-04-30';
3. Поиск уникальных комбинаций данных. В случаях, когда нужно получить уникальные сочетания значений нескольких полей, DISTINCT помогает сократить избыточность. Например, в базе сотрудников компании требуется получить уникальные комбинации отдела и должности:
SELECT DISTINCT department, position FROM employees;
4. Подсчёт уникальных значений в выборке. В некоторых случаях необходимо подсчитать количество уникальных записей в столбце. Это можно сделать с помощью COUNT в комбинации с DISTINCT. Например, для подсчёта уникальных городов, в которых расположены клиенты компании:
SELECT COUNT(DISTINCT city) FROM clients;
5. Оптимизация выборки данных в отчётах. В отчёте по продажам может потребоваться информация о уникальных продажах на определённую дату. Вместо того чтобы повторно учитывать одни и те же транзакции, можно использовать DISTINCT для сокращения выборки:
SELECT DISTINCT sale_date FROM sales WHERE sale_date >= '2025-01-01';
6. Работа с агрегированными данными. DISTINCT используется в сочетании с агрегатными функциями для подсчёта уникальных значений в выборке. Например, если нужно посчитать количество уникальных товаров в заказах за последний месяц:
SELECT COUNT(DISTINCT product_id) FROM order_items WHERE order_date >= '2025-04-01';
Каждый из этих примеров иллюстрирует, как DISTINCT помогает уменьшить избыточность данных и делает результаты запросов более точными для анализа. Однако важно помнить, что излишнее использование DISTINCT может негативно сказаться на производительности запроса, особенно при работе с большими объемами данных.
Вопрос-ответ:
Что такое оператор DISTINCT в SQL и для чего он используется?
Оператор DISTINCT в SQL используется для удаления повторяющихся строк в результате запроса. Когда мы выполняем запрос, например, на выборку всех значений из столбца, оператор DISTINCT гарантирует, что в результирующем наборе данных будут только уникальные значения. Это особенно полезно, когда нужно узнать, какие именно значения присутствуют в таблице, без лишних повторений.
Как DISTINCT влияет на производительность запроса в SQL?
Применение DISTINCT может повлиять на производительность запроса, особенно когда работаете с большими таблицами или сложными объединениями (JOIN). Это связано с тем, что для получения уникальных значений сервер базы данных должен выполнить дополнительные операции, такие как сортировка или создание временных индексов. Поэтому важно учитывать размер данных и необходимость в уникальности результатов перед использованием DISTINCT в запросах, где это может быть ресурсозатратно.
Можно ли использовать DISTINCT для нескольких столбцов в SQL?
Да, оператор DISTINCT можно применять не только к одному столбцу, но и к нескольким. Если в запросе указано несколько столбцов, DISTINCT будет учитывать комбинации значений из всех этих столбцов. Например, запрос SELECT DISTINCT column1, column2 FROM table вернёт только уникальные пары значений, где одновременно и column1, и column2 будут уникальными в каждой строке результата.
Что произойдёт, если применить DISTINCT к столбцу, который содержит только одинаковые значения?
Если в столбце содержатся только одинаковые значения и применяется оператор DISTINCT, то в результирующем наборе данных будет только одна строка с этим значением. Например, если столбец «цвет» содержит только значения «красный», то запрос SELECT DISTINCT цвет FROM таблица вернёт одну строку с «красным». Это поведение гарантирует, что повторяющиеся значения не будут выводиться несколько раз.
Можно ли использовать DISTINCT вместе с другими операторами, такими как WHERE или ORDER BY?
Да, оператор DISTINCT можно комбинировать с другими операторами, такими как WHERE или ORDER BY. Например, можно использовать WHERE для фильтрации строк перед применением DISTINCT, чтобы исключить ненужные данные, и затем отсортировать результат с помощью ORDER BY. Пример: SELECT DISTINCT столбец FROM таблица WHERE условие ORDER BY столбец. Это позволяет сначала получить уникальные значения по определенному фильтру и затем отсортировать результат по нужному столбцу.