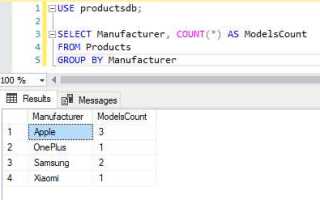
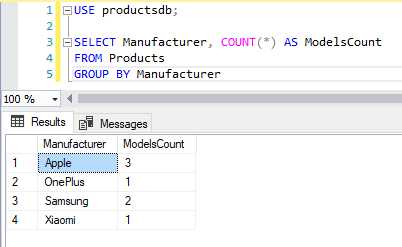
В SQL оператор GROUP BY применяется для группировки строк в таблице, что позволяет выполнить агрегирование данных по определенным критериям. Это один из ключевых инструментов, используемых для анализа больших объемов информации, особенно когда необходимо суммировать, подсчитать или вычислить другие статистические показатели для подмножеств данных.
При использовании GROUP BY важно правильно выбрать столбцы, по которым будет происходить группировка. Все столбцы в SELECT-запросе, не являющиеся агрегатными функциями, должны быть указаны в списке GROUP BY. Например, если вам нужно получить общее количество заказов для каждого клиента, вы группируете данные по идентификатору клиента, а для вычисления суммы заказов используете функцию SUM().
Кроме стандартных агрегатных функций, таких как SUM(), AVG(), COUNT(), MIN() и MAX(), SQL позволяет комбинировать GROUP BY с фильтрацией через HAVING. Это позволяет не только группировать, но и фильтровать результаты агрегирования. Например, можно сгруппировать заказы по месяцу и выбрать только те, где общая сумма превышает определенную величину.
Как сгруппировать данные по одному столбцу с использованием GROUP BY
Для агрегации данных по одному столбцу с помощью оператора GROUP BY в SQL необходимо указать столбец, по которому будет происходить группировка. Группировка позволяет агрегировать данные по категориям, объединяя строки с одинаковыми значениями в указанном столбце. Рассмотрим базовый синтаксис:
SELECT столбец, агрегатная_функция(другой_столбец)
FROM таблица
GROUP BY столбец;Пример: если есть таблица заказов с полями product_id (идентификатор продукта) и order_amount (сумма заказа), и нужно подсчитать общую сумму заказов для каждого продукта, запрос будет выглядеть так:
SELECT product_id, SUM(order_amount)
FROM orders
GROUP BY product_id;В этом запросе product_id – это столбец, по которому осуществляется группировка, а SUM – агрегатная функция, которая вычисляет суммарное значение для каждого уникального значения product_id.
Группировка по одному столбцу может также включать другие агрегатные функции, такие как AVG (среднее значение), COUNT (количество строк), MAX (максимальное значение), MIN (минимальное значение). Пример с функцией COUNT:
SELECT product_id, COUNT(*)
FROM orders
GROUP BY product_id;Этот запрос покажет, сколько заказов было сделано для каждого продукта. Важно помнить, что все столбцы в SELECT, которые не являются агрегатными функциями, должны быть указаны в GROUP BY.
Группировка данных по одному столбцу полезна для анализа распределения и подсчета, например, количества проданных единиц, суммы дохода по категориям или других агрегированных данных. Правильное использование GROUP BY помогает эффективно обрабатывать и анализировать большие объемы данных в SQL.
Использование агрегатных функций вместе с GROUP BY: SUM, AVG, COUNT
Агрегатные функции в SQL, такие как SUM, AVG и COUNT, позволяют собирать информацию по группам данных. Когда применяется оператор GROUP BY, эти функции позволяют получать сводные данные, например, сумму, среднее значение или количество записей в каждой группе.
Функция SUM() используется для вычисления суммы значений в каждой группе. Например, если вам нужно посчитать общий доход по каждому отделу компании, запрос может выглядеть так:
SELECT department, SUM(salary) FROM employees GROUP BY department;
Этот запрос вернёт сумму зарплат сотрудников для каждого отдела.
Функция AVG() рассчитывает среднее значение по каждой группе. Она полезна, когда необходимо получить среднее значение, например, среднюю зарплату по каждому отделу. Пример запроса:
SELECT department, AVG(salary) FROM employees GROUP BY department;
В этом случае будет вычислено среднее значение зарплат для сотрудников каждого отдела.
Функция COUNT() используется для подсчёта количества строк в каждой группе. Это может быть полезно, когда нужно узнать, сколько сотрудников работает в каждом отделе:
SELECT department, COUNT(*) FROM employees GROUP BY department;
Этот запрос покажет, сколько сотрудников есть в каждом отделе.
Для более сложных запросов можно комбинировать несколько агрегатных функций. Например, если нужно узнать не только среднюю зарплату, но и количество сотрудников в каждом отделе, можно использовать следующий запрос:
SELECT department, COUNT(*), AVG(salary) FROM employees GROUP BY department;
Важно помнить, что агрегатные функции работают с результатами, сгруппированными с помощью GROUP BY, и их использование требует, чтобы все столбцы, не являющиеся агрегатными функциями, были включены в оператор GROUP BY.
Как группировать данные по нескольким столбцам одновременно
Для группировки данных по нескольким столбцам в SQL используется конструкция GROUP BY с перечислением нескольких полей, которые будут участвовать в агрегации. Это позволяет более точно анализировать данные, выявлять закономерности и формировать отчеты с большим уровнем детализации.
Пример базового запроса с группировкой по нескольким столбцам:
SELECT категория, производитель, SUM(количество)
FROM товары
GROUP BY категория, производитель;
В этом примере данные группируются сначала по категория, затем по производитель. Результат покажет общую сумму количества товаров для каждой комбинации категории и производителя.
Важно, что порядок столбцов в GROUP BY имеет значение. Группировка данных происходит слева направо, и это может повлиять на структуру итогового результата. Например, группировка по полям категория, а затем производитель, даст один результат, в то время как наоборот – другой.
В запросах с несколькими группировками часто используются функции агрегирования, такие как SUM(), AVG(), COUNT(). Пример с подсчетом количества товаров по категориям и производителям:
SELECT категория, производитель, COUNT(товар_id)
FROM товары
GROUP BY категория, производитель;
Для корректной работы с несколькими столбцами в группировке важно, чтобы все выбранные поля, не являющиеся агрегатными функциями, были указаны в GROUP BY.
Можно также комбинировать условия с HAVING, чтобы фильтровать результаты после выполнения группировки. Например, если нужно отфильтровать те группы, где количество товаров больше 100:
SELECT категория, производитель, SUM(количество)
FROM товары
GROUP BY категория, производитель
HAVING SUM(количество) > 100;
Группировка по нескольким столбцам полезна, когда нужно анализировать данные по нескольким критериям одновременно. Этот подход дает точные и информативные результаты, которые могут быть полезны для построения отчетности и принятия управленческих решений.
Фильтрация результатов после агрегации с помощью HAVING
Оператор HAVING в SQL используется для фильтрации данных, которые были агрегированы с помощью функций, таких как COUNT(), SUM(), AVG(), MIN() или MAX(). В отличие от WHERE, который применяется до агрегации, HAVING действует после того, как данные были сгруппированы.
Когда вы используете GROUP BY для группировки строк, часто необходимо применить условия к агрегированным результатам. Для этого и используется HAVING.
- Пример: Получить список сотрудников, чьи продажи превышают 100 000 единиц за месяц.
Пример запроса:
SELECT employee_id, SUM(sales)
FROM sales_data
GROUP BY employee_id
HAVING SUM(sales) > 100000;Здесь HAVING фильтрует группы по условию, что сумма продаж для каждого сотрудника должна быть больше 100 000.
Важно помнить, что HAVING не может быть использован без предварительного использования GROUP BY, так как он работает именно с агрегированными результатами. Для простых фильтров на уровне строк до агрегации применяется WHERE.
Еще один пример: если вы хотите отфильтровать группы с количеством товаров, превышающим 10 единиц:
SELECT product_id, COUNT(*) AS product_count
FROM inventory
GROUP BY product_id
HAVING COUNT(*) > 10;В этом случае результат запроса покажет только те товары, которые есть в наличии больше 10 раз. Это позволяет гибко фильтровать данные, применяя агрегацию и затем наложив условия.
Рекомендации:
- Используйте
HAVINGтолько для фильтрации агрегированных данных. - Если вам нужно фильтровать строки до агрегации, применяйте
WHERE. - Если условие фильтрации сложное, комбинируйте
HAVINGс несколькими агрегатными функциями, например,AVG()иMAX().
В сочетании с GROUP BY, HAVING позволяет эффективно ограничивать результаты запроса по конкретным агрегированным данным, что существенно повышает точность и производительность анализа.
Объединение GROUP BY с сортировкой результатов: ORDER BY

Когда в запросе используется GROUP BY для агрегации данных, часто возникает необходимость в сортировке этих данных для более удобного анализа. Это можно сделать с помощью оператора ORDER BY, который сортирует результаты после применения группировки. Такое объединение позволяет не только сгруппировать данные по определенному признаку, но и упорядочить их по конкретным колонкам или результатам агрегации.
Рассмотрим пример, когда нужно сгруппировать данные о продажах по месяцам и отсортировать их по сумме продаж в убывающем порядке. Запрос может выглядеть так:
SELECT месяц, SUM(продажа) FROM продажи GROUP BY месяц ORDER BY SUM(продажа) DESC;
Здесь SUM(продажа) является агрегирующей функцией, которая суммирует продажи по каждому месяцу, а ORDER BY SUM(продажа) DESC сортирует эти результаты от максимальных значений к минимальным. Такой подход помогает легко выявить месяца с наибольшими продажами.
При использовании ORDER BY можно также сортировать по нескольким столбцам. Например, если нужно отсортировать сначала по сумме продаж, а затем по названию месяца в алфавитном порядке, запрос будет таким:
SELECT месяц, SUM(продажа) FROM продажи GROUP BY месяц ORDER BY SUM(продажа) DESC, месяц ASC;
В этом примере сортировка будет происходить в два этапа: сначала по убыванию суммы продаж, затем по возрастанию месяца, если суммы продаж равны.
Важно помнить, что ORDER BY применяется после выполнения агрегации, и если не указать ORDER BY в запросе, результаты могут быть возвращены в произвольном порядке. Следовательно, для обеспечения нужного порядка всегда следует явно указывать сортировку.
Также стоит учитывать, что ORDER BY может быть полезен в сочетании с различными функциями, такими как COUNT(), AVG(), MAX(), и MIN(), для более точного анализа данных. Например, для подсчета количества продуктов, проданных в каждом месяце, с сортировкой по этому количеству:
SELECT месяц, COUNT(продукт) FROM продажи GROUP BY месяц ORDER BY COUNT(продукт) DESC;
Таким образом, использование ORDER BY в запросах с GROUP BY позволяет не только организовать и агрегировать данные, но и структурировать результаты таким образом, чтобы извлечь из них наиболее важную информацию.
Как использовать GROUP BY с датами: агрегация по дням, месяцам и годам
SQL предоставляет мощные средства для агрегации данных, включая работу с датами. С помощью оператора GROUP BY можно группировать записи по различным временным интервалам, таким как дни, месяцы или годы. Рассмотрим, как это делать на практике.
Агрегация данных по датам позволяет легко анализировать изменения в показателях с течением времени, например, для подсчета продаж, посещаемости или других метрик.
Агрегация по дням
Для группировки данных по дням обычно используется функция DATE(), которая извлекает только дату из временного значения, игнорируя время. Пример запроса:
SELECT DATE(order_date) AS order_day, COUNT(*) AS order_count
FROM orders
GROUP BY DATE(order_date)
ORDER BY order_day;
Этот запрос вернет количество заказов для каждого дня. Важно, чтобы в столбце order_date хранились точные временные метки (включая время), но мы группируем их по дням.
Агрегация по месяцам

Чтобы сгруппировать данные по месяцам, используется функция MONTH() для извлечения номера месяца и YEAR() для извлечения года. Пример запроса:
SELECT YEAR(order_date) AS order_year, MONTH(order_date) AS order_month, COUNT(*) AS order_count
FROM orders
GROUP BY YEAR(order_date), MONTH(order_date)
ORDER BY order_year, order_month;
Этот запрос позволяет подсчитать количество заказов по месяцам и годам. Такое группирование полезно для анализа сезонных колебаний или долгосрочных трендов.
Агрегация по годам
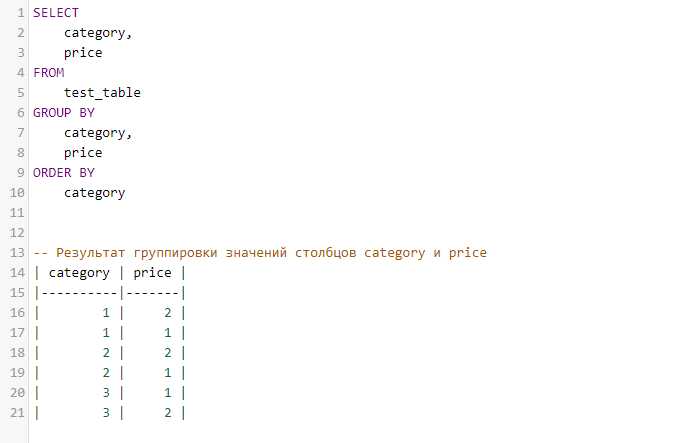
Для группировки по годам можно использовать функцию YEAR(). Пример запроса:
SELECT YEAR(order_date) AS order_year, COUNT(*) AS order_count
FROM orders
GROUP BY YEAR(order_date)
ORDER BY order_year;
Этот запрос группирует все заказы по годам, что может быть полезно для долгосрочного анализа, например, для оценки роста или спада в продажах за несколько лет.
Использование агрегации с несколькими временными интервалами
Иногда бывает необходимо комбинировать несколько временных уровней, например, группировка по месяцам внутри года. Это достигается через использование нескольких функций YEAR() и MONTH(). Пример:
SELECT YEAR(order_date) AS order_year, MONTH(order_date) AS order_month, DAY(order_date) AS order_day, COUNT(*) AS order_count
FROM orders
GROUP BY YEAR(order_date), MONTH(order_date), DAY(order_date)
ORDER BY order_year, order_month, order_day;
Этот запрос даст представление о количестве заказов в разрезе года, месяца и дня. Такой подход используется, когда необходимо получить данные с высокой степенью детализации.
Рекомендации при работе с датами
- Всегда учитывайте формат хранения даты в базе данных. Например, если в столбце дата и время, а вам нужно сгруппировать только по дате, используйте функцию
DATE(). - Для агрегации по месяцу или году полезно иметь индекс на поле даты, чтобы ускорить выполнение запросов.
- При группировке по годам или месяцам можно использовать
DATE_TRUNC()в некоторых СУБД, чтобы округлить дату до нужного уровня (например, до начала месяца).
Примеры агрегации данных с условиями в WHERE до GROUP BY
Когда необходимо выполнить агрегацию данных, но только для определённой выборки, условие в WHERE применяется до GROUP BY. Это важно, чтобы ограничить набор данных перед группировкой, что ускоряет выполнение запроса и уменьшает объём обрабатываемых данных.
Пример 1: Нахождение средней зарплаты сотрудников в компании, работающих в определённом отделе.
Если вам нужно посчитать среднюю зарплату только для сотрудников, работающих в отделе маркетинга, то фильтрация происходит на этапе WHERE:
SELECT department, AVG(salary) FROM employees WHERE department = 'Marketing' GROUP BY department;
Здесь фильтрация по отделу выполняется до того, как данные группируются по департаментам, что исключает ненужные строки из дальнейших вычислений.
Пример 2: Подсчёт количества заказов, сделанных клиентами из определённого города.
Для подсчёта количества заказов клиентов из Москвы необходимо сначала отфильтровать по городу, а затем сгруппировать данные по каждому клиенту:
SELECT customer_id, COUNT(order_id) FROM orders WHERE city = 'Moscow' GROUP BY customer_id;
Фильтрация по городу позволяет уменьшить количество данных, которые будут обработаны в процессе агрегации.
Пример 3: Вычисление общего объёма продаж для товаров, которые были проданы за последние три месяца.
Если нужно агрегировать данные только для недавно проданных товаров, фильтрация по дате происходит до группировки:
SELECT product_id, SUM(sales_amount) FROM sales WHERE sale_date > '2025-01-01' GROUP BY product_id;
Такой подход позволяет сосредоточиться только на данных за нужный период времени и избежать избыточной обработки старых записей.
Использование WHERE до GROUP BY улучшает производительность запросов, ограничивая число строк, которые должны быть сгруппированы. Это особенно важно, когда данные хранятся в больших таблицах и требуется эффективность.
Как применять GROUP BY в подзапросах для более сложной агрегации
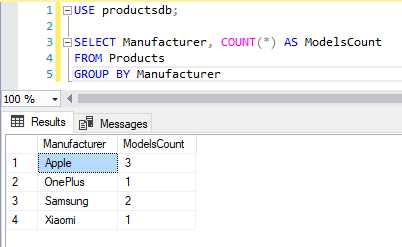
Когда стандартное использование оператора GROUP BY не позволяет решить задачу агрегации данных, можно прибегнуть к использованию подзапросов. Это особенно полезно при необходимости выполнения нескольких уровней агрегации или когда требуется агрегация по данным, уже агрегированным в другом подзапросе.
Для начала важно понимать, что подзапросы в SQL позволяют выполнять агрегацию на одном уровне, а затем результат можно использовать на другом. Это позволяет комбинировать различные уровни агрегации и фильтрации, что невозможно сделать с помощью простого GROUP BY на одном уровне.
Пример: допустим, у нас есть таблица sales, где хранятся данные о продажах товаров по регионам и датам. Мы хотим узнать средний доход по каждому товару, но только среди товаров, которые продаются в определённом регионе. Здесь мы можем использовать подзапрос.
SELECT product_id, AVG(total_sales) AS avg_sales FROM ( SELECT product_id, region, SUM(sales_amount) AS total_sales FROM sales GROUP BY product_id, region ) AS regional_sales WHERE region = 'Europe' GROUP BY product_id;
В данном примере подзапрос выполняет агрегацию данных по каждому товару и региону, суммируя продажи. Внешний запрос затем фильтрует результат по региону «Europe» и вычисляет среднюю сумму продаж для каждого товара в этом регионе. Такой подход позволяет использовать несколько уровней агрегации с различными условиями.
Также можно комбинировать GROUP BY с условиями в HAVING, что позволяет более гибко управлять агрегированными результатами. Например, если нужно отфильтровать товары, чьи средние продажи превышают определённый порог, это также можно сделать на уровне подзапроса:
SELECT product_id, AVG(total_sales) AS avg_sales FROM ( SELECT product_id, region, SUM(sales_amount) AS total_sales FROM sales GROUP BY product_id, region ) AS regional_sales WHERE region = 'Europe' GROUP BY product_id HAVING AVG(total_sales) > 5000;
Использование подзапросов с GROUP BY позволяет гораздо гибче работать с данными, когда необходимо провести сложную агрегацию по нескольким уровням или фильтрацию уже агрегированных данных. Это решение открывает дополнительные возможности для аналитики, минимизируя потребность в сложных соединениях или дополнительных таблицах.
Вопрос-ответ:
Что такое SQL GROUP BY и зачем он нужен?
SQL GROUP BY используется для агрегации данных в таблице, группируя строки по одному или нескольким столбцам. Это позволяет выполнять операции, такие как суммирование, подсчет, нахождение среднего значения и другие агрегатные функции, для каждой группы данных. Например, с помощью GROUP BY можно подсчитать общее количество заказов для каждого клиента или вычислить среднюю цену товаров в каждой категории.