

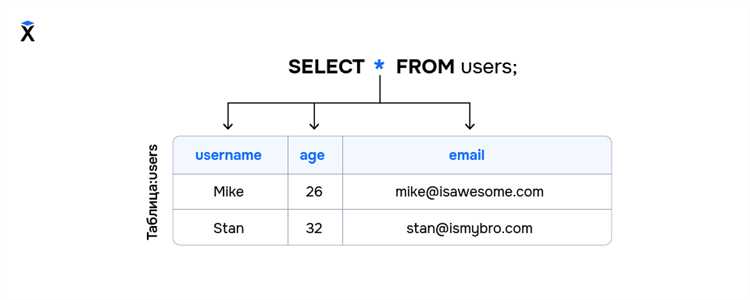
SQL-запрос SELECT является основой работы с базами данных. Его основная цель – извлечение информации из одной или нескольких таблиц с помощью заданных критериев. Запрос SELECT позволяет не только получить все данные из таблицы, но и фильтровать, сортировать и агрегировать их по различным параметрам.
Конструкция SELECT проста, но требует внимательности к деталям. Пример базового запроса выглядит следующим образом:
SELECT column1, column2 FROM table_name;Здесь column1 и column2 – это имена столбцов, а table_name – название таблицы, из которой извлекаются данные. Однако в реальной практике запросы часто содержат дополнительные операторы, такие как WHERE, ORDER BY, GROUP BY, позволяющие контролировать, какие именно данные будут возвращены.
Один из важнейших аспектов SELECT – это использование условий фильтрации с помощью оператора WHERE, который позволяет задать критерии выбора данных. Например, запрос для извлечения всех записей, где возраст сотрудников больше 30 лет, будет выглядеть так:
SELECT * FROM employees WHERE age > 30;Если нужно отсортировать результаты, применяется оператор ORDER BY. Например, для сортировки данных по возрасту сотрудников в порядке убывания:
SELECT * FROM employees ORDER BY age DESC;Таким образом, запрос SELECT является мощным инструментом для работы с данными в базе. Знание его ключевых элементов и особенностей поможет точно и эффективно извлекать нужную информацию.
Что происходит при выполнении простого SELECT запроса

При выполнении простого SQL запроса SELECT происходит несколько этапов, которые обеспечивают извлечение данных из базы данных. На первом этапе сервер базы данных анализирует запрос и определяет, какие таблицы и поля нужно выбрать, а также как обрабатывать условия фильтрации (если они есть).
Далее система проверяет наличие индексов, которые могут ускорить выполнение запроса. Индексы позволяют избежать полного сканирования таблицы, что существенно сокращает время выполнения операции. Если индекс существует для поля, по которому происходит поиск, сервер использует его для быстрого доступа к нужным строкам.
После выбора данных сервер выполняет операцию фильтрации строк в соответствии с условиями запроса (например, через оператор WHERE). При этом возможно использование нескольких типов фильтрации, таких как сравнение значений, логические операторы и выражения с подзапросами.
Затем происходит сортировка, если в запросе указаны условия сортировки (например, с использованием ORDER BY). Этот этап помогает упорядочить результаты согласно заданным критериям, будь то по возрастанию или убыванию значений в одном или нескольких столбцах.
После сортировки выполняется операция группировки данных (если используется GROUP BY). В этом случае строки с одинаковыми значениями в указанных столбцах объединяются, и вычисляются агрегатные функции, такие как COUNT, SUM, AVG, MIN, MAX для каждой группы.
Когда данные подготовлены, сервер возвращает их в том виде, в котором они соответствуют запросу. Если указан LIMIT, то сервер ограничивает количество возвращаемых строк. Весь этот процесс выполняется за счет различных оптимизаций и обработки запросов сервером, что минимизирует нагрузку и ускоряет выполнение операции.
Использование WHERE для фильтрации данных в SELECT

Оператор WHERE в SQL используется для фильтрации данных, которые извлекаются с помощью SELECT. Он позволяет сузить выборку, определяя условия, которым должны удовлетворять строки в базе данных. Применение WHERE повышает точность и эффективность запросов, ограничивая результат только нужными значениями.
Основные элементы, которые можно использовать в WHERE:
- Операторы сравнения: =, <>, >, <, >=, <=. Эти операторы позволяют сравнивать значения в столбцах с конкретными значениями или другими столбцами.
- Логические операторы: AND, OR, NOT. Они используются для комбинирования нескольких условий. AND требует выполнения всех условий, OR – хотя бы одного, а NOT инвертирует условие.
- Шаблоны и диапазоны: LIKE, BETWEEN, IN. LIKE позволяет искать по шаблону (например, с использованием символа подстановки %), BETWEEN ограничивает значения определенным диапазоном, а IN проверяет, содержится ли значение в списке.
- NULL: IS NULL, IS NOT NULL. Эти операторы проверяют, содержит ли столбец пустые значения.
Пример использования WHERE:
SELECT * FROM employees WHERE age > 30 AND department = 'IT';
Этот запрос извлечет данные о сотрудниках, возраст которых больше 30 лет и которые работают в отделе «IT».
Когда нужно учитывать несколько условий, важно правильно расставлять приоритет с помощью скобок. Например:
SELECT * FROM orders WHERE (status = 'Shipped' OR status = 'Delivered') AND order_date >= '2025-01-01';
Здесь сначала фильтруются заказы, которые имеют статус «Shipped» или «Delivered», а затем выбираются только те, которые были сделаны после 1 января 2025 года.
Использование оператора WHERE помогает оптимизировать запросы, значительно сокращая количество извлекаемых данных, что особенно важно при работе с большими объемами информации.
Сортировка результатов SELECT с помощью ORDER BY
Команда ORDER BY позволяет упорядочить результаты SQL-запроса в определённом порядке. Сортировка может быть выполнена по одному или нескольким столбцам, как по возрастанию, так и по убыванию.
Синтаксис команды:
SELECT столбцы FROM таблица ORDER BY столбец1 [ASC|DESC], столбец2 [ASC|DESC], ...;
- ASC – сортировка по возрастанию (по умолчанию);
- DESC – сортировка по убыванию.
Пример сортировки по одному столбцу:
SELECT имя, возраст FROM пользователи ORDER BY возраст ASC;
В этом примере пользователи будут отсортированы по возрасту в порядке возрастания.
Если нужно отсортировать результаты по нескольким столбцам, можно указать их через запятую:
SELECT имя, город, возраст FROM пользователи ORDER BY город ASC, возраст DESC;
Здесь результаты будут сначала отсортированы по городу по возрастанию, а затем, в случае одинаковых городов, по возрасту в порядке убывания.
Для сортировки строк, содержащих текстовые значения, используется порядок, зависящий от локализации базы данных. Важно учитывать, что строковые значения могут сортироваться с учётом регистра символов, что влияет на результат сортировки.
Когда требуется сортировка по вычисляемым значениям, можно использовать выражения в ORDER BY. Например:
SELECT имя, зарплата, бонус FROM сотрудники ORDER BY (зарплата + бонус) DESC;
Для ускорения работы с большими объёмами данных можно создавать индексы на столбцах, по которым часто выполняется сортировка.
Следует помнить, что в случае сортировки по нескольким столбцам, порядок сортировки по умолчанию задаётся слева направо. Если для некоторых столбцов требуется особый порядок, нужно явно указать ASC или DESC для каждого из них.
Применение LIMIT для ограничения количества возвращаемых строк
Оператор LIMIT используется в SQL-запросах для ограничения числа строк, которые возвращаются в результате выполнения SELECT-запроса. Это позволяет ускорить обработку данных и избежать перегрузки памяти при работе с большими таблицами.
Синтаксис LIMIT прост: он указывается в конце запроса и принимает два параметра – количество строк и, при необходимости, смещение. Пример базового использования:
SELECT * FROM таблица LIMIT 10;
Этот запрос вернёт только первые 10 строк из результата. Если необходимо пропустить несколько строк и затем вернуть ограниченное количество, используется второй параметр – смещение:
SELECT * FROM таблица LIMIT 5 OFFSET 10;
В данном примере будут пропущены первые 10 строк, а из оставшихся будет возвращено только 5 строк. Смещение полезно для реализации постраничной навигации при работе с большими наборами данных.
LIMIT позволяет эффективно ограничить объём данных, что важно в сценариях, когда требуется быстрое извлечение подмножества информации, например, для отображения на веб-странице или для анализа небольших выборок данных. Это особенно актуально при работе с базами данных, содержащими миллионы записей, где извлечение всех строк может занять слишком много времени и ресурсов.
Некоторые СУБД (системы управления базами данных) также позволяют использовать LIMIT в комбинации с ORDER BY для упорядочивания данных перед ограничением количества строк. Например, для получения самых последних записей:
SELECT * FROM таблица ORDER BY дата DESC LIMIT 5;
Этот запрос вернёт последние 5 записей, упорядоченные по убыванию даты. Использование LIMIT в таких случаях помогает эффективно работать с большими объёмами данных, извлекая только нужную информацию, что снижает нагрузку на систему и ускоряет обработку запроса.
Работа с несколькими таблицами через JOIN в SELECT
Когда требуется извлечь данные из нескольких таблиц, для связи между ними используется оператор JOIN. Он позволяет комбинировать строки из разных таблиц по общему условию, определённому в ON. Наиболее популярные типы JOIN – INNER JOIN, LEFT JOIN, RIGHT JOIN и FULL JOIN. Каждый из них имеет свои особенности при объединении строк.
INNER JOIN – самый распространённый тип соединения. Он возвращает только те строки, где существует совпадение в обеих таблицах. Например, если в одной таблице указаны данные о заказах, а в другой – о клиентах, INNER JOIN вернёт только те заказы, для которых существуют соответствующие клиенты.
Пример запроса для получения информации о заказах с указанием данных клиентов:
SELECT orders.id, customers.name, orders.amount FROM orders INNER JOIN customers ON orders.customer_id = customers.id;
LEFT JOIN возвращает все строки из левой таблицы (первой), а соответствующие строки из правой (второй) таблицы. Если совпадений в правой таблице нет, возвращаются NULL-значения. Это полезно, если нужно получить все данные из основной таблицы, даже если для них нет связанных записей в другой таблице.
Пример запроса, который возвращает все заказы, включая те, для которых нет соответствующего клиента:
SELECT orders.id, customers.name, orders.amount FROM orders LEFT JOIN customers ON orders.customer_id = customers.id;
RIGHT JOIN работает аналогично LEFT JOIN, но возвращает все строки из правой таблицы, а из левой – только те, которые имеют совпадения. Этот тип используется реже, так как часто его можно заменить LEFT JOIN с перевёрнутыми таблицами.
Пример с RIGHT JOIN, где вернутся все клиенты, а также те заказы, которые у них есть:
SELECT orders.id, customers.name, orders.amount FROM orders RIGHT JOIN customers ON orders.customer_id = customers.id;
FULL JOIN включает все строки из обеих таблиц. Если для строки из одной таблицы нет соответствия в другой, в местах отсутствующих данных будут стоять NULL. Этот тип соединения полезен, когда нужно получить полную картину, даже если для некоторых записей нет соответствующих данных в обеих таблицах.
Пример запроса с FULL JOIN для извлечения всех данных из заказов и клиентов, даже если между ними нет совпадений:
SELECT orders.id, customers.name, orders.amount FROM orders FULL JOIN customers ON orders.customer_id = customers.id;
Для оптимизации запросов с JOIN важно учитывать индексирование полей, используемых в условиях соединения. Это ускоряет выполнение запросов, особенно при работе с большими объёмами данных.
Также стоит помнить, что JOIN может быть комбинирован с другими фильтрами, например, WHERE и GROUP BY, для более точной выборки данных.
Как использовать агрегатные функции в SELECT для анализа данных
Агрегатные функции в SQL позволяют выполнять вычисления над набором данных, возвращаемых запросом, и обрабатывать их для получения сводной информации. Эти функции полезны для анализа данных, таких как подсчёт, сумма, среднее значение и другие метрики, которые помогают выявить скрытые закономерности и тренды.
Для использования агрегатных функций достаточно применить их в операторе SELECT, указав название функции и соответствующее поле. Основные агрегатные функции: COUNT(), SUM(), AVG(), MIN(), MAX(). Каждая из этих функций выполняет специфическую задачу.
COUNT() подсчитывает количество строк в выборке, соответствующих условию. Например, для подсчёта числа заказов можно использовать запрос:
SELECT COUNT(*) FROM orders WHERE status = 'completed';
SUM() суммирует значения указанного столбца. Это полезно для анализа общих объёмов продаж или других числовых данных. Пример запроса для вычисления общей суммы продаж:
SELECT SUM(total_amount) FROM sales WHERE date BETWEEN '2025-01-01' AND '2025-03-31';
AVG() вычисляет среднее значение по числовому столбцу. Например, для вычисления среднего чека за период:
SELECT AVG(order_amount) FROM orders WHERE status = 'completed';
MIN() и MAX() используются для нахождения минимальных и максимальных значений в столбце. Пример запроса для поиска самой дешёвой и самой дорогой продажи:
SELECT MIN(price), MAX(price) FROM products;
Агрегатные функции можно комбинировать с другими операторами, такими как GROUP BY, чтобы группировать результаты по определённым признакам. Например, для анализа суммы продаж по каждому сотруднику можно использовать:
SELECT employee_id, SUM(sales_amount) FROM sales GROUP BY employee_id;
Использование агрегатных функций с фильтрами HAVING позволяет исключать группы, не удовлетворяющие заданному условию. Например, если нужно отобрать сотрудников, чьи продажи превышают определённый порог:
SELECT employee_id, SUM(sales_amount) FROM sales GROUP BY employee_id HAVING SUM(sales_amount) > 10000;
Такие запросы помогают получить точные данные для анализа и принятия решений на основе больших объёмов информации. Агрегатные функции позволяют не только извлекать нужные сведения, но и производить вычисления, которые существенно упрощают обработку данных в SQL.
Вложенные SELECT запросы: подзапросы и их применение
Основные типы подзапросов:
1. Подзапросы в WHERE – применяются для фильтрации данных. В таком случае подзапрос выполняется для каждой строки главного запроса и возвращает одно или несколько значений, которые используются в условии фильтрации. Пример:
SELECT имя, возраст FROM сотрудники WHERE департамент_id IN (SELECT id FROM департамент WHERE название = 'HR');
Этот запрос извлекает имена и возраста сотрудников, работающих в департаменте HR, используя подзапрос для получения id департамента.
2. Подзапросы в SELECT – используются для вычисления значений, которые не могут быть получены напрямую из таблиц. Они могут вернуть одно или несколько значений, которые затем используются в главном запросе. Пример:
SELECT имя, (SELECT MAX(зарплата) FROM зарплаты WHERE сотрудник_id = сотрудники.id) AS максимальная_зарплата FROM сотрудники;
Здесь подзапрос в SELECT возвращает максимальную зарплату для каждого сотрудника, основанную на данных из другой таблицы.
3. Подзапросы в FROM – чаще всего используются для объединения временных таблиц. Подзапрос возвращает набор данных, который затем используется как источник для дальнейших операций. Пример:
SELECT t1.имя, t2.средняя_зарплата FROM сотрудники t1 JOIN (SELECT сотрудник_id, AVG(зарплата) AS средняя_зарплата FROM зарплаты GROUP BY сотрудник_id) t2 ON t1.id = t2.сотрудник_id;
Здесь подзапрос в секции FROM создаёт временную таблицу со средней зарплатой для каждого сотрудника, и эта таблица используется для соединения с основной таблицей сотрудников.
Важно помнить, что подзапросы могут значительно замедлить выполнение запроса, особенно если они используют агрегатные функции или выполняются многократно для каждой строки главного запроса. Чтобы улучшить производительность, можно рассмотреть оптимизацию подзапросов с помощью индексов или преобразования подзапросов в соединения (JOIN).
Ещё одной рекомендацией является использование подзапросов с ограничением на возвращаемые строки (например, с LIMIT или WHERE), чтобы минимизировать объём обрабатываемых данных и ускорить выполнение запросов.
Нередко встречаются коррелированные подзапросы, которые ссылаются на внешнюю таблицу изнутри подзапроса. Это требует более внимательной проработки, так как каждый подзапрос выполняется для каждой строки внешнего запроса, что может значительно повлиять на производительность.
Оптимизация SELECT запросов: советы и рекомендации

Оптимизация SELECT запросов – ключевая задача для повышения производительности работы с базами данных. Один неэффективно составленный запрос может сильно нагрузить сервер, особенно при больших объемах данных. Рассмотрим несколько эффективных подходов к оптимизации.
1. Используйте индексы для ускорения поиска
Индексы играют важную роль в быстром поиске строк в таблицах. Они значительно сокращают время выполнения запросов, особенно когда нужно извлечь данные по часто используемым полям. Важно создать индексы на столбцы, которые участвуют в WHERE или JOIN условиях, а также на тех, которые активно используются в операциях сортировки или фильтрации.
2. Избегайте использования SELECT *
Запрос SELECT * может вернуть больше данных, чем нужно, что замедляет выполнение и увеличивает нагрузку на сервер. Указывайте только те столбцы, которые действительно требуются в результате запроса.
3. Используйте агрегатные функции с умом
Использование агрегатных функций (например, COUNT(), SUM(), AVG()) может существенно замедлить выполнение запроса, особенно при обработке больших наборов данных. Старайтесь ограничивать диапазоны данных для агрегирования с помощью условий WHERE или предварительной фильтрации в подзапросах.
4. Применяйте LIMIT и OFFSET для сокращения объема данных
Если вам не нужно извлечь все строки, используйте LIMIT для ограничения числа строк в результатах. Это особенно полезно при пагинации данных на сайте или в приложении. Оператор OFFSET позволяет пропустить определенное количество строк, что помогает эффективно работать с большими объемами данных.
5. Используйте JOIN вместо подзапросов
Подзапросы могут замедлить выполнение запроса, так как каждый подзапрос выполняется отдельно. Использование JOIN может значительно улучшить производительность, особенно если данные из нескольких таблиц связаны по индексированным столбцам.
6. Оптимизируйте запросы с использованием EXPLAIN
Для анализа и оптимизации запросов используйте команду EXPLAIN. Она предоставляет информацию о том, как база данных будет выполнять запрос, какие индексы будут использованы и в каком порядке. Это помогает выявить узкие места и найти способы улучшения.
7. Минимизируйте использование сложных функций в WHERE
Функции в условиях WHERE могут замедлить выполнение запроса, поскольку они часто требуют дополнительных вычислений для каждой строки. Когда возможно, избегайте использования функций, таких как LOWER(), UPPER(), или вычислений в условиях, так как это может привести к отказу от использования индексов.
8. Правильно настройте кэширование
Многие СУБД поддерживают кэширование результатов запросов. Когда запросы часто выполняются с одинаковыми параметрами, кэширование может существенно ускорить их выполнение. Обратите внимание на настройку кэширования в вашей СУБД и подходы к его очистке.
9. Избегайте дублирования данных в таблицах
Для улучшения производительности работы с данными минимизируйте дублирование информации в таблицах. Нормализуйте структуру базы данных, чтобы избежать избыточных данных, которые необходимо обрабатывать в запросах.
10. Регулярно проводите анализ и реорганизацию базы данных
При работе с большими объемами данных важно регулярно проводить реорганизацию индексов и таблиц. Например, в PostgreSQL это можно сделать с помощью команды VACUUM, которая очищает таблицы от неиспользуемого пространства и улучшает производительность.
Вопрос-ответ:
Что такое SQL запрос SELECT и для чего он используется?
SQL запрос SELECT применяется для извлечения данных из базы данных. С его помощью можно выбрать необходимые столбцы и строки, основываясь на различных условиях. Это основной инструмент работы с данными в реляционных базах данных. Запрос позволяет указать, какие именно данные мы хотим получить, а также сортировать и фильтровать информацию.
Как работает SQL-запрос SELECT для извлечения данных из базы данных?
SQL-запрос SELECT используется для извлечения данных из таблиц базы данных. С его помощью можно выбрать конкретные столбцы или все данные в таблице. Запрос SELECT имеет несколько ключевых компонентов: выбор столбцов, имя таблицы и различные фильтры для ограничений, таких как WHERE, которые позволяют извлекать только нужную информацию. Например, запрос SELECT * FROM users извлечет все строки и столбцы из таблицы «users». Также можно добавлять операторы сортировки (ORDER BY), группировки (GROUP BY) и объединения (JOIN), чтобы управлять результатами выборки и получать только те данные, которые необходимы для анализа или отображения.





