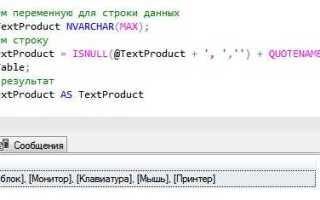
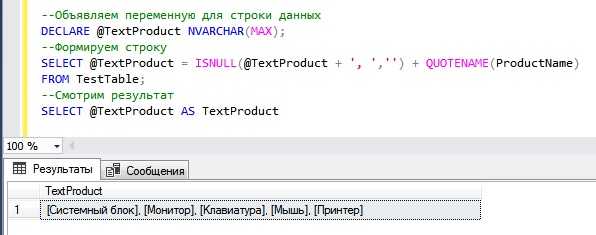
Для работы с данными в реляционных базах данных часто возникает необходимость изменить структуру таблицы, преобразовав строки в столбцы. Это может понадобиться в случаях, когда данные хранятся в одном ряду, но нужно представить их в более удобной форме для анализа или отчётности. Такая операция называется «развёртывание» таблицы, и её реализация требует понимания SQL-запросов и правильного подхода.
Один из самых распространённых способов развернуть таблицу в SQL – это использование оператора PIVOT. Этот инструмент позволяет преобразовать значения одной колонки в заголовки столбцов, сохраняя остальные данные в строках. Однако стоит помнить, что не все СУБД поддерживают PIVOT напрямую. В таких случаях приходится использовать другие методы, например, агрегацию с условными операторами или подзапросы.
Для успешного развёртывания важно учитывать несколько факторов: структура исходных данных, типы агрегируемых данных и требуемое количество столбцов в результате. Например, если требуется развернуть таблицу с информацией о продажах по месяцам, нужно правильно выбрать ключи для группировки и корректно обработать NULL-значения, чтобы не потерять данные. Кроме того, использование индексов может ускорить процесс выполнения запросов при работе с большими объемами данных.
В следующем разделе мы рассмотрим несколько конкретных примеров, которые помогут понять, как эффективно использовать SQL для развёртывания таблиц и избежать распространённых ошибок при работе с данным инструментом.
Подготовка данных для разворота таблицы в SQL
Перед разворотом таблицы важно тщательно подготовить данные, чтобы избежать ошибок в процессе. Основные шаги подготовки включают очистку, агрегацию и структуру данных, соответствующую требованиям SQL-запросов.
Первое, что необходимо сделать – это удостовериться, что данные в таблице упорядочены по ключевым столбцам. Обычно для этого используется уникальный идентификатор или временная метка. Например, если вы планируете разворачивать данные по месяцам, данные должны быть отсортированы по датам с соответствующими значениями для каждого месяца.
Вторым шагом будет агрегирование данных, если это необходимо. Часто для разворота требуется, чтобы все данные по одной категории были сгруппированы в одну строку. Используйте функции агрегации, такие как SUM(), AVG(), MAX(), если требуется подсчитать суммы или средние значения. Также важно правильно настроить фильтры WHERE, чтобы исключить из анализа нерелевантные записи.
Важный аспект – отсутствие дублирующихся строк, которые могут создать проблемы при развороте. Перед развертыванием проверяйте таблицу на дубли с помощью функции DISTINCT или комбинируйте с GROUP BY, чтобы данные были уникальными для каждой группы.
Если данные содержат значения, которые могут быть представлены в виде категорий, например, товары, регионы или сотрудники, убедитесь, что каждый уникальный элемент имеет одно значение в каждой строке для корректного разворота. Это обеспечит точность результата.
Наконец, для успешного разворота таблицы часто требуется создать вспомогательные таблицы или временные таблицы. Это особенно важно, если данные сложные или если требуется предварительная обработка. Например, вы можете использовать подзапросы для фильтрации и подгона данных под нужный формат.
Подготовка данных – это ключевой этап, от которого зависит корректность и скорость выполнения запроса для разворота таблицы.
Использование оператора CASE для переворота значений в столбцах
Оператор CASE в SQL позволяет гибко изменять данные в запросах, включая переворот значений в столбцах. Это особенно полезно, когда необходимо изменить отображение данных в зависимости от условий, например, инвертировать значения или менять их местами в зависимости от конкретных значений.
Для переворота значений в столбце можно использовать следующую структуру запроса:
SELECT
CASE
WHEN column_name = 'значение1' THEN 'значение2'
WHEN column_name = 'значение2' THEN 'значение1'
ELSE column_name
END AS reversed_column
FROM table_name;Здесь для каждого значения в столбце column_name будет выполнена замена: если значение равно «значение1», оно будет заменено на «значение2», и наоборот. Все остальные значения остаются без изменений.
Для работы с более сложными случаями можно добавлять дополнительные условия. Например, если необходимо перевернуть значения в зависимости от других столбцов, можно комбинировать CASE с условиями на другие колонки:
SELECT
CASE
WHEN column_name = 'значение1' AND another_column = 'условие' THEN 'значение2'
WHEN column_name = 'значение2' AND another_column = 'условие' THEN 'значение1'
ELSE column_name
END AS reversed_column
FROM table_name;Для повышения читаемости и удобства работы с данными можно также использовать CASE в комбинации с другими агрегатными функциями, например, для переворота значений внутри групп. Например, если нужно перевернуть значения для каждого уникального идентификатора:
SELECT
id,
CASE
WHEN column_name = 'значение1' THEN 'значение2'
WHEN column_name = 'значение2' THEN 'значение1'
ELSE column_name
END AS reversed_column
FROM table_name
GROUP BY id;Такой подход помогает сохранить гибкость запросов и уменьшить сложность, позволяя выполнять перевороты значений без необходимости использования дополнительных временных таблиц или подзапросов. Использование оператора CASE позволяет значительно упростить логику обработки данных в SQL-запросах, что делает его мощным инструментом при работе с трансформациями данных.
Реализация поворота таблицы с помощью агрегатных функций
Для выполнения поворота таблицы в SQL, используя агрегатные функции, можно использовать комбинацию операций GROUP BY, CASE и агрегатных функций (например, SUM, COUNT, MAX, MIN). Этот подход позволяет трансформировать строки в столбцы, а также агрегацию данных для каждого нового столбца.
Рассмотрим пример. У нас есть таблица с продажами товаров, где каждый товар записан в отдельной строке:
CREATE TABLE sales ( product_id INT, product_name VARCHAR(50), sale_date DATE, amount INT );
Предположим, нам нужно перевести данные по продажам в формат, где строки будут представлять товары, а столбцы – продажи по месяцам. Для этого применим агрегатные функции и оператор CASE для каждого месяца:
SELECT product_name, SUM(CASE WHEN EXTRACT(MONTH FROM sale_date) = 1 THEN amount ELSE 0 END) AS January, SUM(CASE WHEN EXTRACT(MONTH FROM sale_date) = 2 THEN amount ELSE 0 END) AS February, SUM(CASE WHEN EXTRACT(MONTH FROM sale_date) = 3 THEN amount ELSE 0 END) AS March, ... FROM sales GROUP BY product_name;
Здесь:
EXTRACT(MONTH FROM sale_date)извлекает номер месяца из даты продажи;CASEиспользуется для выборки данных по каждому месяцу;SUMагрегирует количество продаж для каждого месяца.
Для обеспечения гибкости и масштабируемости подхода можно использовать динамическое построение SQL-запроса, если количество месяцев или других категорий переменно. Такой метод особенно полезен в отчетах с меняющейся структурой данных.
Рекомендации:
- Используйте
CASEдля условной агрегации, что позволяет легко обрабатывать разные категории (например, месяцы или регионы). - Будьте внимательны при использовании функций на датах, так как в зависимости от СУБД могут быть различные синтаксисы для извлечения даты.
- Агрегатные функции, такие как
SUM,COUNTилиAVG, обеспечивают гибкость при анализе данных по категориям. - Не забывайте про индексы на поля, которые активно участвуют в группировках, чтобы ускорить выполнение запросов.
Применение этого подхода эффективно, когда необходимо агрегировать данные по множеству параметров, одновременно переворачивая таблицу для более наглядного представления информации.
Применение оператора PIVOT в SQL для развертывания данных
Оператор PIVOT в SQL позволяет преобразовать строки в столбцы, что эффективно используется для развертывания данных в удобный для анализа формат. Это особенно полезно при работе с агрегированными данными, когда необходимо показать результаты для различных категорий в виде отдельных столбцов.
Основной синтаксис оператора PIVOT следующий:
SELECT <поля>
FROM (
SELECT <поля_для_агрегации>, <категории_для_развертывания>
FROM <таблица>
) AS source_table
PIVOT (
<агрегатная_функция>(<значение_для_агрегации>)
FOR <категория> IN (<список_категорий>)
) AS pivot_table;
На практике, часто применяют агрегатные функции такие как SUM(), AVG(), COUNT() для вычисления суммарных значений, среднего или количества в развернутых столбцах. Например, можно использовать PIVOT для вычисления продаж по месяцам для каждого товара:
SELECT product, Jan, Feb, Mar
FROM (
SELECT product, MONTH(sale_date) AS sale_month, sales_amount
FROM sales
) AS source_table
PIVOT (
SUM(sales_amount)
FOR sale_month IN (1, 2, 3)
) AS pivot_table;
В этом примере данные о продажах группируются по товарам, а столбцы отображают суммы продаж по месяцам (январь, февраль, март). Метод PIVOT помогает визуализировать информацию о динамике продаж, не усложняя запрос.
Несмотря на свою мощность, оператор PIVOT имеет ограничения, которые стоит учитывать. Во-первых, в SQL Server для использования PIVOT необходимо заранее знать возможные значения, которые будут использоваться в развернутых столбцах (категориях). Если возможных категорий слишком много или они изменяются динамически, то использование PIVOT может быть нецелесообразным. В таких случаях лучше использовать динамическое SQL или другие методы агрегации.
Для динамической генерации SQL-запросов с PIVOT можно использовать следующий подход:
DECLARE @cols AS NVARCHAR(MAX), @query AS NVARCHAR(MAX);
SELECT @cols = STRING_AGG(QUOTENAME(MONTH(sale_date)), ',')
FROM sales
GROUP BY MONTH(sale_date);
SET @query = 'SELECT product, ' + @cols + ' FROM (
SELECT product, MONTH(sale_date) AS sale_month, sales_amount
FROM sales
) AS source_table
PIVOT (
SUM(sales_amount)
FOR sale_month IN (' + @cols + ')
) AS pivot_table';
EXEC sp_executesql @query;
В этом примере динамически генерируется список месяцев для использования в запросе. Такой подход позволяет работать с переменными категориями и таблицами с нестабильной структурой.
Основное преимущество оператора PIVOT заключается в том, что он позволяет легко сводить информацию из длинных списков в компактные и наглядные таблицы. Это особенно полезно для аналитиков, которым важно быстро получать сводные данные по различным категориям, например, по регионам, продуктам или временным интервалам.
Перевод строк в столбцы с помощью динамического SQL
При необходимости преобразования строк в столбцы в SQL, динамический SQL предоставляет гибкость для выполнения этой задачи в зависимости от структуры данных и условий. Основная сложность заключается в том, что количество столбцов может изменяться, что требует генерации SQL-запросов в зависимости от данных.
Чтобы преобразовать строки в столбцы, следует воспользоваться функцией `PIVOT` или написать запрос с динамическим SQL. Динамический SQL позволяет создавать запросы на лету, что особенно полезно, когда количество столбцов заранее неизвестно. Рассмотрим пример, как это можно реализовать в SQL Server.
Предположим, у нас есть таблица с результатами продаж, где строки представляют собой записи о продажах по месяцам для разных товаров. Нам нужно преобразовать данные, чтобы каждый товар стал отдельным столбцом с суммой продаж по каждому месяцу.
Пример исходной таблицы:
| Товар | Месяц | Продажи | |--------|---------|---------| | Товар1 | Январь | 100 | | Товар1 | Февраль | 150 | | Товар2 | Январь | 200 | | Товар2 | Февраль | 250 |
Шаги для динамического перевода строк в столбцы:
DECLARE @cols AS NVARCHAR(MAX), @query AS NVARCHAR(MAX);
-- Получаем список товаров для использования в качестве столбцов
SELECT @cols = STRING_AGG(QUOTENAME(Товар), ', ')
FROM (SELECT DISTINCT Товар FROM продажи) AS tmp;
-- Формируем динамический SQL запрос
SET @query = N'SELECT Месяц, ' + @cols + '
FROM (SELECT Месяц, Товар, Продажи
FROM продажи) AS src
PIVOT (SUM(Продажи) FOR Товар IN (' + @cols + ')) AS pvt
ORDER BY Месяц';
-- Выполняем динамический SQL
EXEC sp_executesql @query;
Здесь:
STRING_AGG(QUOTENAME(Товар), ', ')используется для получения списка всех уникальных товаров, которые будут использоваться как столбцы.PIVOTпозволяет агрегировать данные, преобразуя строки в столбцы.sp_executesqlвыполняет сгенерированный запрос.
Результатом выполнения этого запроса будет таблица, где каждый товар представлен отдельным столбцом с суммой продаж по каждому месяцу:
| Месяц | Товар1 | Товар2 | |---------|--------|--------| | Январь | 100 | 200 | | Февраль | 150 | 250 |
Важные рекомендации при использовании динамического SQL:
- Старайтесь избегать SQL-инъекций, особенно если значения для динамического SQL поступают от пользователей. Используйте функции, такие как
QUOTENAMEдля экранирования идентификаторов. - Убедитесь, что динамически сгенерированный SQL не будет слишком длинным, иначе возникнут ошибки при выполнении запроса.
- Проверяйте количество столбцов, особенно если таблица может содержать большое количество уникальных значений, так как это может повлиять на производительность.
Динамический SQL – мощный инструмент для гибкого преобразования данных, но его использование требует внимательности и хорошего понимания структуры данных.
Типичные ошибки при развороте таблицы и как их избежать
Разворот таблицы в SQL может быть сложным процессом, если не учитывать определённые нюансы. Основные ошибки чаще всего связаны с неверным использованием функций, неправильной настройкой агрегатов или неправильно выбранными типами данных. Рассмотрим наиболее частые ошибки и способы их предотвращения.
1. Ошибки при использовании функции PIVOT
Функция PIVOT является мощным инструментом для преобразования строк в столбцы. Однако, её неправильное использование может привести к некорректным результатам.
- Неправильный выбор агрегатной функции: Часто выбирается агрегат, который не подходит для типа данных (например, использование
SUMдля строковых данных). Чтобы избежать ошибки, используйте соответствующие агрегатные функции для каждого столбца. - Отсутствие фильтрации данных: Если заранее не отфильтровать строки, могут попасть ненужные данные в результирующую таблицу. Используйте
WHEREдля фильтрации данных перед применением PIVOT. - Неверное использование
INв списке значений: Параметры в спискеINдолжны быть уникальными. Повторяющиеся значения могут привести к дублированию столбцов в результате.
2. Проблемы с типами данных
При развороте таблицы важным аспектом является согласованность типов данных между исходными и результирующими столбцами.
- Неопределённость типа данных: Если исходные данные не имеют явного типа, это может вызвать ошибку при попытке агрегировать их. Используйте явное приведение типов, например,
CASTилиCONVERT, чтобы избежать несоответствий. - Типы данных при агрегации: При агрегации данных нужно учитывать типы данных агрегируемых столбцов. Например, если используется строка в числовом контексте, результат может быть ошибочным. Перед агрегацией конвертируйте данные в нужный тип.
3. Ошибки при использовании GROUP BY
Группировка данных играет ключевую роль при развороте, но неправильное её использование может привести к непредсказуемым результатам.
- Неучёт всех столбцов в
GROUP BY: Если в запросе используются столбцы, которые не участвуют в агрегатах, это может привести к ошибке. Убедитесь, что все столбцы, не являющиеся агрегатами, указаны вGROUP BY. - Неверный порядок группировки: Порядок, в котором столбцы указаны в
GROUP BY, может повлиять на результаты. Следите за логикой группировки, чтобы не получить неожиданных результатов.
4. Проблемы с NULL-значениями
NULL-значения могут быть проблемой при развороте таблицы, так как они могут повлиять на агрегацию и итоговые результаты.
- Игнорирование NULL: Если не учитывать NULL-значения в запросах, это может привести к потере данных или некорректным результатам. Используйте функции для обработки NULL, такие как
COALESCEилиIFNULL, чтобы заменить их на значения по умолчанию. - Необработанные NULL в агрегатах: При использовании агрегатных функций такие значения могут быть проигнорированы, что повлияет на итоговые суммы или вычисления. Убедитесь, что NULL обрабатывается перед агрегацией.
5. Ошибки при обработке большого объёма данных
Разворот таблицы с большим количеством данных требует аккуратности в плане производительности.
- Отсутствие индексов: При работе с большими таблицами, отсутствие индексов на столбцах, используемых для группировки или фильтрации, может значительно замедлить выполнение запроса. Добавляйте индексы на часто используемые столбцы.
- Низкая производительность запроса: При сложных операциях разворота возможно ухудшение производительности. Для оптимизации можно использовать временные таблицы или разбиение данных на части для поэтапной обработки.
6. Неучёт специфики БД
Каждая СУБД имеет свои особенности работы с запросами и агрегатами. Ошибки, связанные с этим, могут быть крайне разнообразными.
- Неоптимизированные запросы для конкретной СУБД: Разные СУБД могут по-разному обрабатывать запросы. Ознакомьтесь с документацией вашей СУБД для оптимизации запросов, особенно при использовании специфичных функций разворота.
- Использование неподдерживаемых функций: Некоторые СУБД могут не поддерживать функции, например,
PIVOTв старых версиях SQL Server. Проверяйте доступные функции и их аналоги для вашей платформы.
Правильное понимание и внимание к деталям помогут избежать этих ошибок и эффективно развернуть таблицы в SQL. Рекомендуется тщательно тестировать запросы на небольших наборах данных перед их применением к большим объёмам, чтобы убедиться в корректности результата.
Как развернуть таблицу с несколькими уровнями группировки
Рассмотрим пример, где требуется развернуть таблицу продаж по регионам и категориям товаров. Мы создадим таблицу, в которой сначала сгруппируем данные по регионам, затем по категориям товаров, и выведем результаты в развернутом виде, где каждый уровень группировки будет представлен отдельным столбцом.
Пример SQL-запроса для этого:
SELECT region, category, SUM(sales_amount) AS total_sales, COUNT(*) AS sales_count FROM sales_data GROUP BY region, category ORDER BY region, category;
В этом примере данные сгруппированы по регионам и категориям, а агрегация выполняется по сумме продаж и количеству транзакций. Однако если необходимо развернуть данные, чтобы отображать каждый уровень группировки в отдельном столбце, можно использовать оконные функции.
Чтобы создать развернутую таблицу с несколькими уровнями группировки, можно использовать запрос с оконными функциями для создания дополнительного уровня детализации. Например:
WITH sales_ranks AS ( SELECT region, category, SUM(sales_amount) AS total_sales, ROW_NUMBER() OVER (PARTITION BY region ORDER BY category) AS rank_by_category FROM sales_data GROUP BY region, category ) SELECT region, MAX(CASE WHEN rank_by_category = 1 THEN total_sales END) AS category_1_sales, MAX(CASE WHEN rank_by_category = 2 THEN total_sales END) AS category_2_sales, MAX(CASE WHEN rank_by_category = 3 THEN total_sales END) AS category_3_sales FROM sales_ranks GROUP BY region ORDER BY region;
В этом запросе сначала выполняется группировка по регионам и категориям, после чего в оконной функции ROW_NUMBER() присваиваются уникальные номера каждой категории внутри региона. После этого данные «разворачиваются» в отдельные столбцы для каждой категории. Таким образом, в развернутом виде для каждого региона будут отображены продажи по каждому уровню категории товаров.
Рекомендации:
- Используйте оконные функции, чтобы избежать дублирования строк и сохранить данные о каждом уровне группировки.
- Когда количество групп нефиксировано, для динамического создания столбцов можно использовать CASE WHEN в сочетании с оконными функциями.
- Учитывайте возможное увеличение времени выполнения запроса при использовании оконных функций на больших объемах данных. Для оптимизации можно воспользоваться индексами на полях, которые участвуют в группировке и фильтрации.
Оптимизация запросов для развернутых таблиц в SQL
Когда таблица развернута, ее структура может стать менее эффективной для выполнения запросов. Для оптимизации таких запросов важно учитывать несколько факторов: индексы, выборочные фильтры, агрегирование данных и избегание избыточных операций.
1. Использование индексов
Индексы – ключевое средство для ускорения запросов, особенно когда работаете с развернутыми таблицами. Важно создавать индексы по столбцам, которые часто участвуют в фильтрации или сортировке. Однако нужно избегать излишнего создания индексов, так как это увеличивает время на их обновление при изменении данных. Рекомендуется создавать комбинированные индексы, если несколько столбцов часто используются вместе в условиях запроса.
2. Снижение количества данных в запросах
Часто запросы к развернутым таблицам извлекают больше данных, чем необходимо. Использование WHERE для точного фильтра данных позволяет значительно ускорить выполнение запроса. Применение JOIN и подзапросов должно быть оправдано, а не использоваться без явной необходимости. Пример:
SELECT product_name, SUM(sales) FROM sales_data WHERE region = 'Europe' GROUP BY product_name;
В данном запросе важно сразу ограничить данные регионом, чтобы избежать работы с избыточной информацией.
3. Использование агрегатных функций эффективно
Когда работаете с развернутыми таблицами, важно оптимизировать использование агрегатных функций, таких как COUNT(), SUM(), AVG(). Эти функции могут значительно замедлить запрос, если данные не ограничены на ранней стадии. Например, вместо того чтобы сразу считать агрегированные данные по всей таблице, можно сначала ограничить выборку с помощью WHERE и потом применять агрегатные функции.
4. Избегание SELECT *
Использование SELECT * в запросах к развернутым таблицам часто приводит к извлечению лишних данных, что замедляет работу. Лучше указывать только те столбцы, которые действительно нужны для выполнения задачи. Это особенно важно, если таблица содержит множество колонок.
5. Оптимизация подзапросов
Подзапросы могут быть неэффективными, особенно если они выполняются многократно. Вместо подзапросов можно использовать временные таблицы или CTE (Common Table Expressions), которые помогут избежать повторных вычислений и ускорить выполнение. Пример использования CTE:
WITH filtered_sales AS ( SELECT product_id, sales FROM sales_data WHERE region = 'Europe' ) SELECT product_id, SUM(sales) FROM filtered_sales GROUP BY product_id;
Это позволяет оптимизировать запрос, отделяя фильтрацию данных от агрегации.
6. Правильное использование оконных функций
Оконные функции (например, ROW_NUMBER(), RANK()) могут быть полезны для работы с развернутыми таблицами. Однако они требуют грамотного применения, так как их производительность может снижаться при большом объеме данных. Для повышения эффективности стоит использовать оконные функции только в случае, если они действительно необходимы для решения задачи, и предварительно фильтровать данные.
7. Уменьшение числа JOIN-ов
Когда развернутая таблица содержит большое количество колонок, использование множественных JOIN операций может значительно снизить производительность. Рекомендуется ограничить количество объединений и применять их только в случае, если это оправдано структурой запроса. При необходимости объединения таблиц лучше использовать индексы и правильно их настраивать для ускорения работы.
Вопрос-ответ:
Что такое разворачивание таблицы в SQL и зачем это нужно?
Разворачивание таблицы в SQL – это процесс преобразования данных, представленных в строках, в столбцы. Это часто используется для улучшения восприятия данных, а также для более удобной работы с ними в отчетах. Например, если в таблице хранится информация о продажах товаров по месяцам, развернув таблицу, можно получить каждую колонку с данными о продажах для каждого месяца. Это помогает сделать отчетность более понятной и упрощает анализ.
В чем разница между операциями `PIVOT` и `CASE` при развертывании таблицы?
Основное различие между `PIVOT` и `CASE` заключается в том, что `PIVOT` — это более прямолинейный способ преобразования строк в столбцы, доступный в некоторых СУБД, таких как SQL Server. Он автоматически группирует данные и превращает строки в столбцы. В то время как `CASE` требует явного указания условий для каждой строки и столбца, что дает большую гибкость, но может быть менее удобным для сложных операций.
Когда стоит использовать разворачивание таблицы, а когда лучше оставить данные в строках?
Решение о том, разворачивать ли таблицу, зависит от цели анализа. Если необходимо визуализировать данные для отчета или провести сравнительный анализ по нескольким категориям, развернутая таблица будет удобнее. Однако если данные имеют множество уникальных значений или в них много пустых ячеек, лучше оставить таблицу в исходном виде, чтобы не создать сложностей с интерпретацией данных.
Какие могут быть проблемы при разворачивании таблицы в SQL?
Основная проблема при разворачивании таблицы — это возможное большое количество пустых ячеек в новых столбцах, особенно если некоторые категории данных отсутствуют в определенных строках. Также может возникнуть сложность при работе с большим объемом данных, что может снизить производительность запроса. Чтобы избежать таких проблем, рекомендуется заранее фильтровать данные или использовать агрегатные функции для обработки пустых значений.