

В большинстве баз данных SQL первичный ключ (PRIMARY KEY) используется для обеспечения уникальности строк в таблице. Однако при проектировании сложных схем данных часто возникает необходимость использования нескольких столбцов в качестве составного первичного ключа. Это позволяет эффективно решать задачи, связанные с уникальностью данных, которые не могут быть выражены через один столбец.
Реализация составных первичных ключей обычно применяется в случаях, когда каждый столбец, входящий в состав ключа, сам по себе не может гарантировать уникальность. Например, для таблицы с данными о заказах в интернет-магазине, где каждое соединение товара с заказом должно быть уникальным, можно использовать составной ключ, включающий в себя идентификатор заказа и идентификатор товара.
При реализации нескольких первичных ключей важно учитывать, что SQL стандарт не допускает наличие нескольких колонок с назначением первичного ключа в одной таблице. Однако возможна ситуация, когда один из столбцов будет частью составного ключа, а другие будут выступать в роли внешних ключей, ссылаясь на другие таблицы. При таком подходе ключи могут эффективно работать с несколькими таблицами, повышая целостность и производительность запросов.
Использование составных первичных ключей также помогает избежать избыточности данных. Вместо создания отдельных уникальных индексов для каждого столбца можно построить один индекс на составной ключ, что снижает нагрузку на базу данных и ускоряет выполнение операций. Тем не менее, необходимо внимательно подходить к выбору столбцов для составного ключа, чтобы обеспечить максимальную производительность запросов.
Почему в SQL нельзя использовать несколько первичных ключей в одной таблице

Технически, первичный ключ – это совокупность одного или нескольких столбцов, которые вместе гарантируют уникальность каждой строки. Если бы в таблице могло быть несколько первичных ключей, это создавало бы неопределенность в вопросе, какой именно из них следует использовать для обеспечения уникальности и ссылок. Такой подход нарушает целостность данных, так как каждый из первичных ключей мог бы быть интерпретирован как возможный идентификатор строки, что делает невозможным корректное управление связями между таблицами.
Кроме того, ограничение на наличие только одного первичного ключа позволяет автоматически создавать индекс для столбцов, которые входят в этот ключ, что повышает производительность запросов. В случае использования нескольких первичных ключей возникала бы необходимость создания нескольких индексов, что могло бы ухудшить производительность системы. Таким образом, наличие единого первичного ключа способствует оптимизации работы базы данных.
Для реализации различных уникальных идентификаторов, когда необходимо обеспечить несколько уникальных комбинаций столбцов, используется концепция уникальных ключей (UNIQUE). Уникальные ключи могут быть использованы в таблице параллельно с первичным ключом, обеспечивая уникальность в других сочетаниях столбцов, не нарушая принципов нормализации и целостности данных.
Таким образом, невозможно использовать несколько первичных ключей в одной таблице из-за требований к уникальности строк, а также из-за возможных проблем с производительностью и логикой работы с данными. Вместо этого следует использовать уникальные ключи и индексы для обеспечения дополнительной уникальности, не нарушая структуры базы данных.
Чем отличается составной первичный ключ от нескольких отдельных ключей
Составной первичный ключ представляет собой комбинацию нескольких столбцов, которые вместе уникально идентифицируют запись в таблице. Это позволяет использовать более одного столбца для обеспечения уникальности записи, что полезно, когда один столбец не может гарантировать уникальность данных. Например, в таблице «Заказы» составной ключ может включать два столбца: номер_заказа и код_товара, чтобы различать одинаковые заказы с разными товарами.
При этом, когда мы говорим о нескольких отдельных первичных ключах, имеется в виду, что каждый из столбцов используется как отдельный уникальный идентификатор, без их объединения в одну структуру. Такой подход может привести к ошибкам в проектировании базы данных, так как не будет гарантирована уникальность строки в случае, если используются несколько отдельных ключей. Например, если в таблице «Пользователи» используются отдельные ключи на столбцы идентификатор_пользователя и адрес_электронной_почты, то возможно наличие одинаковых пользователей с одинаковыми адресами почты, но с разными идентификаторами.
Основное различие между этими подходами заключается в том, что составной ключ гарантирует уникальность записи с учётом нескольких параметров, в то время как отдельные ключи могут привести к дублированию данных, если их комбинация не обеспечит уникальность на уровне всей таблицы. В случае нескольких отдельных ключей, таблица может быть создана с ограничениями, например, добавлением уникальных индексов на каждый из столбцов, но для этой цели составной ключ является более предпочтительным инструментом.
Рекомендация: При проектировании базы данных необходимо тщательно оценивать, какой из подходов будет наиболее оптимальным в зависимости от бизнес-логики и требований к данным. Составной ключ лучше подходит для случаев, когда необходимо учитывать несколько столбцов для уникальности данных. Отдельные ключи могут быть полезны, если каждый столбец имеет свою уникальность, но в общем случае они требуют более сложного контроля за дублированием данных.
Как реализовать уникальность нескольких полей без нескольких первичных ключей

Чтобы обеспечить уникальность комбинации нескольких полей в таблице SQL, не прибегая к созданию нескольких первичных ключей, можно использовать ограничение уникальности (UNIQUE). Это ограничение позволяет гарантировать, что значения в наборе столбцов остаются уникальными для каждой строки, но не требует назначения нескольких первичных ключей.
Решение состоит в том, чтобы определить уникальное ограничение на несколько столбцов одновременно. В SQL это можно сделать следующим образом:
ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения UNIQUE (столбец_1, столбец_2);
Этот подход подходит для случаев, когда комбинация данных в двух или более столбцах должна быть уникальной, но каждый столбец сам по себе не требует первичного ключа. Уникальное ограничение позволяет сохранить целостность данных, предотвращая дублирование комбинаций значений, и при этом сохраняет структуру данных простой и эффективной.
Ещё одной опцией может быть использование индексов. Если уникальное ограничение накладывается на несколько полей, индекс создается автоматически. Для повышения производительности запросов, которые часто обращаются к этим столбцам, можно вручную создать индекс на этих полях:
CREATE UNIQUE INDEX имя_индекса ON имя_таблицы (столбец_1, столбец_2);
Этот индекс будет работать аналогично уникальному ограничению, обеспечивая, что данные остаются уникальными, а также улучшая скорость выполнения операций выборки.
Если в таблице несколько полей, которые могут требовать уникальности, но они не должны быть частью одного первичного ключа, то комбинированные уникальные ограничения и индексы позволяют легко управлять такими случаями, не нарушая нормализации базы данных.
Важный момент – уникальные ограничения и индексы не накладывают ограничений на значения NULL. Для полей, в которых могут встречаться NULL-значения, может возникнуть ситуация, когда несколько строк имеют NULL в этих полях, и это не нарушает уникальность. В таких случаях важно заранее учитывать возможные ситуации с NULL-значениями, если это необходимо для бизнес-логики.
Когда использовать уникальные ограничения вместо нескольких первичных ключей
Уникальные ограничения (UNIQUE) могут быть предпочтительнее нескольких первичных ключей в случаях, когда нужно обеспечить уникальность значений в столбце или наборе столбцов без необходимости привязывать их к основному идентификатору строки. Отличие заключается в том, что уникальные ограничения позволяют поддерживать уникальность, но при этом не требуют использования столбца в качестве основного идентификатора записи.
Обычно первичный ключ выполняет роль уникального идентификатора записи и автоматически создает индекс. В отличие от этого, уникальное ограничение гарантирует, что значения в столбце будут уникальными, но без назначения этого столбца в качестве основного ключа таблицы. Это может быть полезно, если нужно контролировать уникальность для нескольких столбцов, но без создания нескольких зависимостей на уровне таблицы.
Использование уникальных ограничений может быть оправдано в следующих ситуациях:
1. Когда требуется уникальность, но не идентификация записи. Если вам нужно контролировать уникальность данных в столбцах, но эти данные не должны играть роль первичного ключа, то лучше использовать уникальные ограничения. Например, уникальность номера телефона пользователя в таблице пользователей, при этом не назначая его первичным ключом.
2. Когда необходимо комбинировать несколько столбцов для уникальности. В отличие от первичного ключа, который может быть только один, уникальные ограничения можно применять к комбинациям столбцов. Это может быть полезно, когда уникальность важна для нескольких атрибутов, но эти атрибуты не должны быть частью основной идентификации записи.
3. Когда требуется поддержка нескольких уникальных наборов. В случае нескольких первичных ключей таблица будет ограничена одним столбцом в качестве основного идентификатора. Уникальные ограничения же позволяют создавать несколько уникальных наборов данных. Это подходит для приложений, где важна уникальность нескольких параметров, но без необходимости в дополнительном сложном управлении идентификаторами.
4. Когда важна гибкость. В некоторых случаях использование уникальных ограничений дает больше гибкости в проектировании схемы базы данных, поскольку они не обязывают к созданию конкретного идентификатора записи, как это происходит с первичными ключами.
Таким образом, уникальные ограничения эффективны, когда нужно поддерживать уникальность без привязки к главному идентификатору, что позволяет более гибко управлять данными и схемой базы данных.
Практика моделирования: обход ограничений с помощью связных таблиц
Когда речь идет о проектировании баз данных, часто возникает необходимость обойти ограничения, связанные с использованием нескольких первичных ключей в одной таблице. Один из распространенных подходов – использование связных таблиц для реализации сложных взаимосвязей между сущностями, особенно в случаях, когда структура данных требует гибкости.
Связные таблицы представляют собой посредников между сущностями, позволяя моделировать многие-ко-многим (many-to-many) отношения, которые невозможно выразить только с помощью первичных ключей в одной таблице. Это позволяет избежать дублирования данных и упрощает управление связями, сохраняя данные в нормализованном виде.
Примером может служить схема «пользователи – группы», где один пользователь может принадлежать нескольким группам, а одна группа может включать нескольких пользователей. В этом случае прямое использование двух первичных ключей в таблице пользователей или групп приведет к излишнему дублированию. Вместо этого используется связная таблица, содержащая два внешних ключа: один ссылается на таблицу пользователей, другой – на таблицу групп.
Для реализации такого подхода важно правильно определить состав связной таблицы. Каждый внешний ключ должен указывать на уникальный идентификатор другой таблицы, а комбинация этих внешних ключей в связной таблице будет служить составным первичным ключом. Это позволяет эффективно управлять связями и минимизировать избыточность.
Один из недостатков этого подхода – увеличение сложности запросов. Для извлечения полной информации о пользователе и его группах потребуется выполнение дополнительных соединений. Однако это компенсируется гибкостью в моделировании данных и возможностью масштабирования. Особенно это актуально при больших объемах данных, где необходимо избежать перегрузки таблиц и ускорить операции поиска и обновления.
Применяя связные таблицы, стоит учитывать производительность базы данных. Каждый дополнительный запрос, включающий соединение нескольких таблиц, может повлиять на скорость работы системы. Поэтому важно периодически анализировать схемы данных и оптимизировать запросы с учетом реальной нагрузки на систему.
Важным аспектом при использовании связных таблиц является поддержка ссылочной целостности. Ожидается, что все внешние ключи будут корректно указывать на существующие записи в родительских таблицах, и при удалении или обновлении записей в родительских таблицах, эти изменения должны автоматически отражаться в связанных таблицах.
Таким образом, связные таблицы – это мощный инструмент для обхода ограничений, связанных с несколькими первичными ключами, обеспечивающий гибкость и нормализацию данных. Однако их использование требует внимательного подхода к проектированию и оптимизации запросов, чтобы избежать потенциальных проблем с производительностью и целостностью данных.
Ошибки проектирования при попытке задать несколько первичных ключей
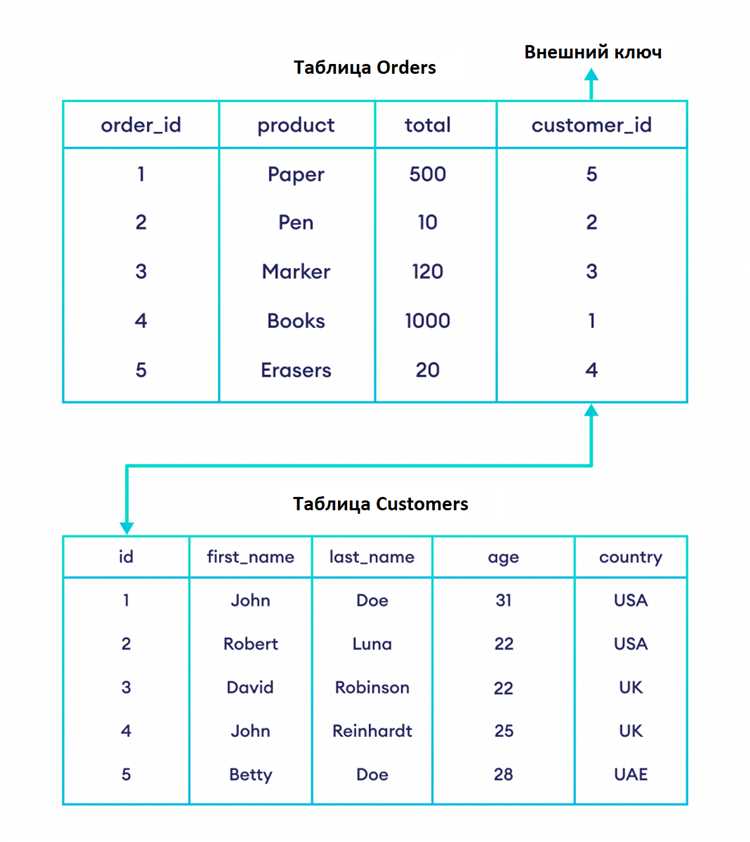
Один из основных принципов нормализации базы данных заключается в том, чтобы таблица имела только один первичный ключ. Однако в процессе проектирования иногда возникает соблазн использовать несколько первичных ключей для одной таблицы, что может привести к ряду проблем.
Ниже перечислены ключевые ошибки, которые могут возникнуть при попытке задать несколько первичных ключей:
- Невозможность задать несколько первичных ключей: В SQL-системах поддержка только одного первичного ключа на таблицу является стандартом. Вместо этого, для реализации уникальности данных можно использовать составные ключи или уникальные индексы. Невозможность создать несколько первичных ключей – это не ограничение системы, а неправильное понимание концепции.
- Проблемы с поддержанием целостности данных: Использование нескольких первичных ключей или их неправильная замена может нарушить логику целостности базы данных. Например, при попытке создать несколько уникальных ограничений на одну и ту же таблицу, возникает путаница в том, как именно обрабатываются дубликаты и как действует механизм обновлений и удалений.
- Нарушение принципа простоты: Один первичный ключ – это средство, которое однозначно идентифицирует запись. Попытки использовать несколько ключей для одного объекта увеличивают сложность запросов и уменьшают эффективность работы базы данных. Это приводит к повышению вероятности ошибок и увеличению затрат на поддержку базы данных в будущем.
- Неправильная организация внешних ключей: Внешние ключи предполагают ссылку на первичный ключ другой таблицы. Если попытаться использовать несколько первичных ключей, возникает путаница с установлением связей между таблицами, что усложняет структуру базы данных и делает её менее гибкой.
- Ошибки в структуре запросов: Наличие нескольких первичных ключей может привести к некорректной логике составления SQL-запросов. Для одного объекта данных только один ключ может быть использован для быстрого поиска, в то время как несколько ключей могут вызвать неоднозначности в выборках и привести к ошибкам.
Вместо того, чтобы пытаться создать несколько первичных ключей в одной таблице, лучше использовать:
- Составной ключ: Когда несколько столбцов вместе создают уникальный идентификатор записи. Это оптимальный способ, когда необходимо учесть несколько атрибутов для уникальности, но при этом сохранить целостность данных.
- Уникальные индексы: Если требуется уникальность в нескольких столбцах, но они не должны быть частью первичного ключа, уникальные индексы являются идеальным решением. Это позволяет повысить производительность поиска и упрощает структуру базы данных.
Итак, попытка создания нескольких первичных ключей не только нарушает основные принципы проектирования базы данных, но и ведет к множеству технических проблем, таких как потеря производительности, сложности с запросами и трудности в поддержке базы данных в будущем. Важно помнить, что корректная модель данных всегда должна быть логичной и понятной как для разработчиков, так и для системы управления базами данных.
Вопрос-ответ:
Можно ли создать несколько первичных ключей в одной таблице SQL?
В SQL в одной таблице может быть только один первичный ключ. Однако этот ключ может быть составным, то есть включать несколько столбцов. Таким образом, можно использовать несколько столбцов в одном первичном ключе, но нельзя создать несколько отдельных первичных ключей.
Можно ли использовать уникальные ключи для обеспечения уникальности в таблице SQL, если первичный ключ уже существует?
Да, можно. В таблице может быть только один первичный ключ, но несколько уникальных ключей. Уникальный ключ выполняет ту же функцию, что и первичный, то есть гарантирует уникальность значений в столбце или группе столбцов. Однако в отличие от первичного ключа, уникальные ключи могут содержать значения NULL, если это необходимо.





