Для эффективного управления данными в базе данных SQL важным аспектом является создание уникальных полей, которые обеспечивают целостность и оптимизацию запросов. Уникальные поля позволяют исключить дублирование данных, что особенно важно при работе с большими объемами информации. В SQL это можно реализовать с помощью ограничения UNIQUE, которое накладывает запрет на повторяющиеся значения в указанном столбце.
Применение UNIQUE может быть полезно для различных типов данных, например, для номеров телефонов, email-адресов или идентификаторов, где повторение значений недопустимо. Для добавления уникального поля при создании таблицы используется следующая конструкция: CREATE TABLE с указанием столбца с ограничением UNIQUE. Пример кода:
CREATE TABLE users (
user_id INT PRIMARY KEY,
email VARCHAR(255) UNIQUE
);Также можно добавлять уникальные ограничения к существующим таблицам с помощью команды ALTER TABLE. Важно понимать, что UNIQUE не обязательно требует создания отдельного индекса, так как SQL автоматически создает индекс для уникальных полей. Однако в некоторых случаях индекс может понадобиться для улучшения производительности при больших объемах данных.
Помимо этого, в некоторых случаях требуется наложить несколько ограничений уникальности сразу на несколько столбцов. Для этого используется составной уникальный индекс, который создается с помощью команды ALTER TABLE или прямо при создании таблицы. Пример:
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
product_id INT,
UNIQUE (customer_id, product_id)
);В данном случае уникальность данных обеспечивается для каждой комбинации customer_id и product_id, что предотвращает повторные заказы одного и того же клиента на тот же товар.
Определение уникального поля в таблице SQL
Чтобы определить уникальное поле, достаточно при создании или изменении таблицы указать UNIQUE для соответствующего столбца. Важно, что это ограничение может быть применено как к одному столбцу, так и к комбинации нескольких столбцов, обеспечивая уникальность их сочетаний.
Пример создания уникального поля в таблице:
CREATE TABLE employees ( id INT PRIMARY KEY, email VARCHAR(255) UNIQUE );
В этом примере поле email будет уникальным, и SQL не позволит вставить в таблицу два одинаковых значения для этого столбца.
Для применения уникального ограничения к нескольким столбцам, можно использовать следующий синтаксис:
CREATE TABLE orders ( order_id INT, product_id INT, UNIQUE (order_id, product_id) );
Здесь уникальность обеспечивается для каждой пары значений в столбцах order_id и product_id.
При попытке вставить строку с повторяющимися значениями в уникальном поле, SQL выбросит ошибку и отклонит запрос. Это обеспечивает целостность данных и предотвращает их избыточность.
Кроме того, при необходимости можно добавить уникальность уже в существующую таблицу с помощью команды ALTER TABLE:
ALTER TABLE employees ADD CONSTRAINT unique_email UNIQUE (email);
Использование уникальных полей помогает не только в обеспечении целостности данных, но и в оптимизации работы с таблицей, ускоряя выполнение запросов благодаря индексам.
Использование ключевого слова UNIQUE для создания уникальности
Ключевое слово UNIQUE в SQL используется для гарантии того, что все значения в определённом столбце или комбинации столбцов будут уникальными. Это позволяет избежать дублирования данных и обеспечить целостность информации в базе данных. Применение UNIQUE важно, когда необходимо, чтобы каждое значение или сочетание значений в поле было уникальным, например, для идентификаторов или email-адресов пользователей.
Для использования UNIQUE в SQL необходимо указать его при создании или изменении таблицы. Важно понимать, что UNIQUE не предотвращает значения NULL, которые могут встречаться в столбцах, определённых с этим ограничением. Однако если в столбце используется NOT NULL, то дублирование значений будет полностью исключено.
Пример создания уникального поля с использованием UNIQUE:
CREATE TABLE users (
user_id INT PRIMARY KEY,
email VARCHAR(255) UNIQUE
);В данном примере столбец email будет содержать уникальные значения. Это означает, что два разных пользователя не могут иметь одинаковые email-адреса. Однако несколько строк могут иметь значение NULL, так как оно не считается дублирующимся.
Также UNIQUE можно использовать для комбинации нескольких столбцов, что позволит обеспечить уникальность только при совместном наличии значений в нескольких полях. Такой подход полезен, например, при учёте, что только сочетание данных в нескольких столбцах делает строку уникальной.
Пример использования UNIQUE для нескольких столбцов:
CREATE TABLE orders (
order_id INT,
user_id INT,
product_id INT,
UNIQUE(user_id, product_id)
);Здесь комбинация значений user_id и product_id должна быть уникальной, что предотвращает возможность того, чтобы один и тот же пользователь заказал один и тот же продукт несколько раз. Важно помнить, что если в одном из столбцов будет NULL, то сочетание будет считаться уникальным, если нет других строк с таким же NULL в соответствующем столбце.
Использование UNIQUE помогает обеспечить целостность данных, особенно в системах, где необходимо строго контролировать уникальность информации. Однако следует быть внимательным при проектировании схемы базы данных, чтобы избежать ненужных ограничений на производительность и сложности в обновлении данных.
Как задать уникальность при создании таблицы
Для того чтобы задать уникальность при создании таблицы в SQL, используется ограничение UNIQUE. Это ограничение гарантирует, что значения в указанном столбце или комбинации столбцов будут уникальными в пределах всей таблицы.
Чтобы задать уникальность при создании таблицы, необходимо указать ограничение UNIQUE в определении столбца. Например:
CREATE TABLE employees ( id INT PRIMARY KEY, email VARCHAR(255) UNIQUE, name VARCHAR(100) );
В этом примере для столбца email задается ограничение уникальности. Это означает, что в таблице не может быть двух строк с одинаковым значением в столбце email.
Если уникальность должна быть установлена для комбинации нескольких столбцов, это можно сделать следующим образом:
CREATE TABLE orders ( order_id INT, customer_id INT, product_id INT, UNIQUE (customer_id, product_id) );
Здесь уникальность будет проверяться для каждой комбинации значений в столбцах customer_id и product_id.
Важно учитывать, что ограничение UNIQUE можно задать только при создании таблицы, но также его можно добавить позже с помощью команды ALTER TABLE:
ALTER TABLE employees ADD CONSTRAINT unique_email UNIQUE (email);
Установка уникальности через команду ALTER TABLE дает возможность добавить ограничение к уже существующему столбцу, если это необходимо.
Также стоит отметить, что ограничение UNIQUE не позволяет вставлять строки с одинаковыми значениями в уникальные столбцы, но оно допускает наличие NULL значений, которые считаются уникальными между собой. Это поведение стоит учитывать при проектировании схемы данных.
Добавление уникального ограничения к существующему столбцу
Чтобы добавить уникальное ограничение к существующему столбцу в SQL, нужно использовать команду ALTER TABLE с подкомандой ADD CONSTRAINT. Это позволяет установить ограничение на значения в столбце, гарантируя, что они будут уникальными по всей таблице.
Пример синтаксиса для добавления уникального ограничения:
ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения UNIQUE (имя_столбца);
Важно учитывать, что столбец, к которому добавляется уникальное ограничение, должен быть уже заполнен данными, которые могут соответствовать этому требованию. Если в столбце уже есть дублирующиеся значения, попытка добавить уникальное ограничение приведет к ошибке.
Перед добавлением уникального ограничения стоит проверить данные в столбце на наличие дубликатов с помощью запроса:
SELECT имя_столбца, COUNT(*) FROM имя_таблицы GROUP BY имя_столбца HAVING COUNT(*) > 1;
Если дубли найдены, необходимо сначала удалить или обновить эти строки, чтобы обеспечить уникальность значений. После этого можно безопасно применить уникальное ограничение.
Еще один момент – если столбец уже содержит индекс, можно добавить уникальное ограничение на существующий индекс, создав его с помощью команды ALTER INDEX. Однако в большинстве случаев проще добавить новое ограничение через ALTER TABLE.
При использовании уникальных ограничений важно помнить, что они могут влиять на производительность операций вставки и обновления данных, так как система будет проверять каждое новое значение на уникальность. Поэтому важно учитывать это при проектировании структуры таблиц в больших базах данных.
Работа с уникальными индексами в SQL
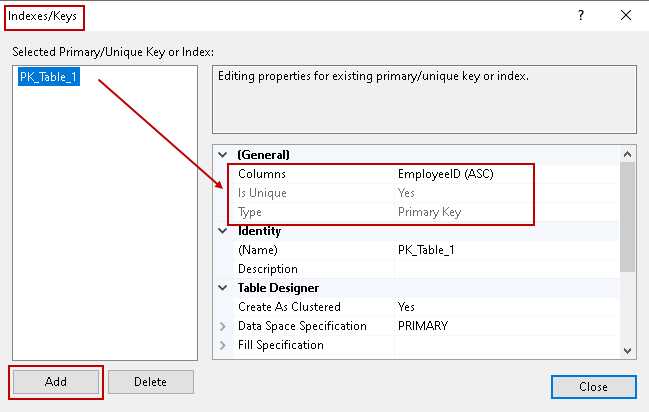
Уникальные индексы в SQL позволяют гарантировать, что значения в определённых столбцах таблицы будут уникальными. Это важный инструмент для обеспечения целостности данных, который предотвращает создание дублирующихся записей. Уникальные индексы создаются с использованием команды CREATE UNIQUE INDEX.
Для создания уникального индекса используется следующий синтаксис:
CREATE UNIQUE INDEX имя_индекса ON имя_таблицы(столбец1, столбец2, ...);Важно помнить, что уникальный индекс можно создавать на одном или нескольких столбцах. Если индекс создан на несколько столбцов, то его уникальность будет определяться комбинацией значений этих столбцов. Например, комбинация значений столбцов имя и фамилия может быть уникальной, но сами по себе имя и фамилия могут повторяться.
Важная особенность уникальных индексов: они автоматически создаются на столбцах, для которых определено ограничение UNIQUE в схеме таблицы. Например, при создании таблицы с ограничением уникальности на столбец email будет создан уникальный индекс на этот столбец:
CREATE TABLE users (
id INT PRIMARY KEY,
email VARCHAR(255) UNIQUE
);Когда необходимо контролировать уникальность нескольких столбцов, стоит использовать уникальные индексы, так как они обеспечат эффективную проверку и повышают производительность. Например, для таблицы заказов можно создать уникальный индекс на комбинацию столбцов user_id и order_date, чтобы предотвратить повторение заказов пользователя в один и тот же день:
CREATE UNIQUE INDEX idx_user_order ON orders(user_id, order_date);После создания уникального индекса база данных будет автоматически проверять, что новые записи не нарушают установленную уникальность, что снижает вероятность ошибок и улучшает производительность запросов.
В случае попытки вставить дубликат в индексированный столбец, СУБД вернёт ошибку, сообщая о нарушении уникальности. Эта особенность может быть полезна, когда важно предотвратить внесение избыточных данных в систему. Однако стоит помнить, что использование уникальных индексов накладывает дополнительные затраты на запись данных, так как система должна проверять уникальность каждого нового значения.
Для удаления уникального индекса применяется команда DROP INDEX. Например:
DROP INDEX idx_user_order; Уникальные индексы также могут быть использованы в условиях JOIN и WHERE для улучшения производительности запросов. Понимание того, как и когда использовать уникальные индексы, позволяет эффективно управлять данными и улучшать работу системы при большом объеме информации.
Проверка уникальности данных в SQL с помощью SELECT
Для проверки уникальности данных в SQL можно использовать запросы с оператором SELECT. Это позволяет определить, есть ли в базе данных повторяющиеся записи в конкретных столбцах или группах столбцов. Один из самых эффективных способов – использование агрегатных функций, таких как COUNT(), в сочетании с группировкой данных через GROUP BY.
Например, чтобы проверить, встречаются ли одинаковые значения в столбце email таблицы users, можно выполнить следующий запрос:
SELECT email, COUNT(*)
FROM users
GROUP BY email
HAVING COUNT(*) > 1;Этот запрос вернет все повторяющиеся email в таблице, а условие HAVING COUNT(*) > 1 фильтрует только те записи, которые появляются более одного раза.
Если необходимо проверить уникальность комбинации нескольких столбцов, например, first_name и last_name, запрос можно модифицировать следующим образом:
SELECT first_name, last_name, COUNT(*)
FROM users
GROUP BY first_name, last_name
HAVING COUNT(*) > 1;Этот подход позволит выявить случаи, когда одинаковые сочетания значений first_name и last_name встречаются более одного раза.
Также можно использовать подзапросы для более сложных проверок. Например, чтобы найти записи, которые не уникальны по сочетанию email и phone, можно выполнить следующий запрос:
SELECT *
FROM users
WHERE (email, phone) IN
(SELECT email, phone
FROM users
GROUP BY email, phone
HAVING COUNT(*) > 1);Этот запрос вернет все строки из таблицы users, которые имеют повторяющиеся значения в столбцах email и phone.
Использование таких методов помогает не только выявить дубликаты, но и оптимизировать дальнейшую работу с данными, предотвращая ошибки при добавлении или обновлении информации в базе данных.
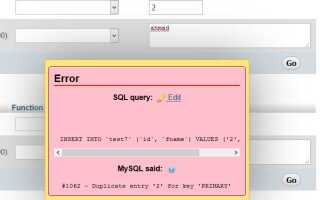
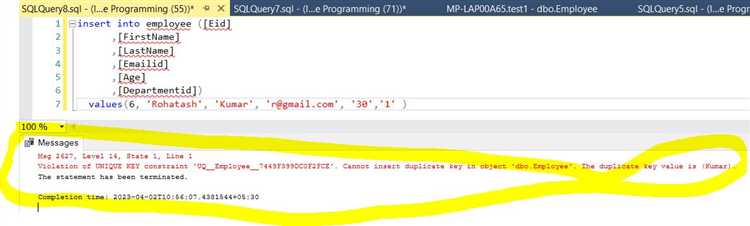
Ошибки при нарушении уникальности и их обработка
Наиболее распространенные ошибки при нарушении уникальности:
- Ошибка нарушения уникальности – чаще всего представлена как ошибка с кодом
1062в MySQL или23505в PostgreSQL. Эта ошибка указывает на то, что новое значение нарушает ограничение уникальности. - Ошибка при вставке с дублирующим значением – возникает, если пытаются вставить запись с уже существующим значением в поле, которое должно быть уникальным.
- Ошибка при обновлении записи – аналогичная ошибка возникает, если обновление записи приводит к нарушению уникальности значений в одном или нескольких полях.
Чтобы избежать подобных ошибок и правильно их обрабатывать, можно использовать несколько подходов:
- Использование операции
INSERT ... ON DUPLICATE KEY UPDATE(MySQL) – этот способ позволяет не генерировать ошибку при нарушении уникальности, а обновлять существующую запись. Например: INSERT INTO users (id, name) VALUES (1, 'John') ON DUPLICATE KEY UPDATE name = 'John';- Использование оператора
ON CONFLICT(PostgreSQL) – аналогичный подход для PostgreSQL, который позволяет управлять поведением при нарушении уникальности: INSERT INTO users (id, name) VALUES (1, 'John') ON CONFLICT (id) DO UPDATE SET name = 'John';- Использование транзакций – заключение операций вставки и обновления в транзакцию позволяет контролировать ситуацию и откатывать изменения, если возникает ошибка уникальности.
Кроме того, важно учитывать, что в некоторых случаях можно применить проверку на уникальность до попытки вставки или обновления, например, через запрос SELECT, чтобы избежать лишних операций с базой данных. Это особенно актуально для случаев с высокой нагрузкой на базу данных.
Неправильная обработка ошибок может привести к несогласованности данных и нарушению целостности базы данных, поэтому важно заранее разработать стратегию обработки подобных ситуаций.
Вопрос-ответ:
Что такое уникальное поле в SQL и зачем оно нужно?
Уникальное поле в SQL – это поле в таблице, значения которого не могут повторяться. Каждый элемент в этом поле должен быть уникальным для каждой строки. Это часто используется для хранения идентификаторов, таких как номера телефонов, email-адреса или другие данные, которые должны быть уникальными для каждого пользователя или записи. Использование уникальных полей помогает обеспечить целостность данных и предотвращает ошибки, связанные с дублированием информации.
Что произойдет, если попытаться вставить дублирующееся значение в уникальное поле?
Если попытаться вставить дублирующееся значение в поле, для которого установлено уникальное ограничение, SQL-сервер вернет ошибку. Например, если в таблице уже есть запись с таким значением, выполнение запроса на добавление нового значения вызовет ошибку и вставка не будет выполнена. Это происходит для того, чтобы обеспечить целостность данных и предотвратить появление одинаковых значений в поле, которое должно оставаться уникальным.