Связи между таблицами в SQL Server играют ключевую роль в организации данных и обеспечении их целостности. Основные типы связей, которые мы будем рассматривать, включают первичные ключи, внешние ключи и ссылочные ограничения. Все эти механизмы позволяют поддерживать правильное взаимодействие между разрозненными наборами данных, избегая дублирования и нарушений в базе данных.
Для создания связи между таблицами необходимо использовать внешний ключ (foreign key). Он устанавливает ссылку на первичный ключ другой таблицы, что гарантирует, что данные в дочерней таблице всегда будут корректными по отношению к родительской. Важно помнить, что внешний ключ не только обеспечивает логическую целостность, но и помогает улучшить производительность запросов за счет использования индексирования.
Рассмотрим пример на SQL Server: если у вас есть таблицы «Заказы» и «Клиенты», для того чтобы связать их, необходимо определить внешний ключ в таблице «Заказы», который будет указывать на первичный ключ таблицы «Клиенты». Простейший запрос для создания связи будет выглядеть так:
ALTER TABLE Заказы ADD CONSTRAINT FK_Заказы_Клиенты FOREIGN KEY (КлиентID) REFERENCES Клиенты(КлиентID);
Эта конструкция гарантирует, что в таблице «Заказы» могут быть только те записи, для которых существует соответствующий клиент в таблице «Клиенты». Важно учитывать, что внешний ключ может иметь дополнительные параметры, такие как ON DELETE CASCADE или ON UPDATE CASCADE, которые управляют поведением базы данных при удалении или обновлении записей в родительской таблице.
Правильное использование связей между таблицами – это основа для построения гибкой и масштабируемой базы данных, которая будет поддерживать эффективную работу приложения и обеспечивать защиту от логических ошибок и дублирования данных.
Выбор типа связи: один к одному, один ко многим, многие ко многим

При проектировании базы данных в SQL Server важно правильно выбрать тип связи между таблицами, так как это определяет структуру данных, оптимизацию запросов и целостность базы. Рассмотрим три основных типа связей: один к одному, один ко многим и многие ко многим.
Один к одному
Связь «один к одному» используется, когда одной записи в первой таблице соответствует ровно одна запись во второй таблице. Этот тип связи применяется, когда необходимо разделить данные на две таблицы по причинам нормализации или безопасности. Например, информация о пользователе может быть разделена на таблицу с личными данными и таблицу с дополнительной информацией (например, паспортные данные).
- Каждая таблица должна иметь уникальный идентификатор (обычно первичный ключ), который также является внешним ключом в другой таблице.
- Связь реализуется через внешние ключи, и чаще всего они индексируются для повышения производительности.
- Возможны ситуации, когда связь один к одному – это не оптимальное решение, если данные можно хранить в одной таблице.
Один ко многим
Связь «один ко многим» – наиболее часто используемый тип связи в реляционных базах данных. Он подразумевает, что каждой записи в первой таблице может соответствовать несколько записей во второй таблице, но каждой записи во второй таблице соответствует только одна запись в первой таблице. Этот тип используется, например, в случае связи между таблицами «Клиенты» и «Заказы», где один клиент может сделать несколько заказов.
- Первичная таблица содержит уникальный идентификатор, который используется как внешний ключ в связанной таблице.
- Внешний ключ обычно индексируется для ускорения запросов и улучшения производительности при соединении таблиц.
- Может потребоваться дополнительная проверка целостности данных, чтобы избежать «висячих» внешних ключей.
Многие ко многим
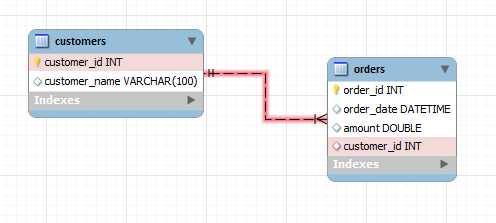
Связь «многие ко многим» предполагает, что каждой записи в первой таблице может соответствовать несколько записей во второй, и наоборот. Такой тип связи требует создания промежуточной таблицы, которая будет хранить пары идентификаторов из обеих таблиц. Это часто используется для моделирования сложных отношений, например, между таблицами «Студенты» и «Курсы», где один студент может проходить несколько курсов, а курс может быть посещаем несколькими студентами.
- Промежуточная таблица содержит два внешних ключа, каждый из которых ссылается на первичные ключи исходных таблиц.
- Рекомендуется добавлять уникальные индексы на сочетания внешних ключей в промежуточной таблице, чтобы предотвратить дублирование данных.
- Связь многие ко многим требует внимательного подхода к проектированию, особенно в случае необходимости добавления дополнительных атрибутов в промежуточную таблицу.
Каждый тип связи имеет свои особенности и предпочтения для различных сценариев. Важно выбирать тот тип, который соответствует логике бизнес-процесса и минимизирует избыточность данных при соблюдении нормализации базы данных.
Создание внешнего ключа для связи таблиц
Внешний ключ (foreign key) в SQL Server используется для создания связей между таблицами, обеспечивая ссылочную целостность данных. Внешний ключ устанавливает зависимость между столбцом в одной таблице и первичным ключом или уникальным столбцом в другой таблице. Это позволяет гарантировать, что значения в поле внешнего ключа всегда будут присутствовать в другой таблице или останутся пустыми (если задано разрешение на null).
Для создания внешнего ключа в SQL Server используется оператор ALTER TABLE, который добавляет ограничение FOREIGN KEY. Основные шаги включают выбор столбца для внешнего ключа, указание родительской таблицы и столбца, на который ссылается внешний ключ. Пример синтаксиса:
ALTER TABLE имя_таблицы
ADD CONSTRAINT имя_ограничения
FOREIGN KEY (столбец_внешнего_ключа)
REFERENCES родительская_таблица (столбец_первичного_ключа);Важные моменты:
- Типы данных должны совпадать. Столбцы, участвующие в связи, должны иметь одинаковые типы данных, чтобы избежать ошибок при создании внешнего ключа.
- Поддержка каскадных операций. Можно настроить каскадные операции обновления или удаления данных, чтобы изменения в родительской таблице автоматически отражались в дочерней. Для этого добавляют ключевые слова
ON DELETE CASCADEилиON UPDATE CASCADE. - Индексы на столбцы внешнего ключа. Для улучшения производительности запросов, связанных с внешними ключами, рекомендуется создавать индекс на столбце внешнего ключа, если он используется в операциях выборки или соединения.
Пример создания внешнего ключа с каскадным удалением:
ALTER TABLE заказы
ADD CONSTRAINT fk_заказы_покупатели
FOREIGN KEY (покупатель_id)
REFERENCES покупатели (id)
ON DELETE CASCADE;Этот пример связывает таблицы заказы и покупатели, где при удалении записи из таблицы покупатели все связанные заказы будут автоматически удалены.
Необходимо учитывать, что при удалении или изменении данных в родительской таблице могут возникнуть ограничения, если в дочерней таблице существуют записи, ссылающиеся на эти данные. В таких случаях необходимо либо использовать каскадные операции, либо настроить правило на отклонение изменений через ON DELETE RESTRICT или ON UPDATE RESTRICT.
Также важно следить за порядком добавления ограничений. Создание внешнего ключа возможно только тогда, когда значения в столбце внешнего ключа уже существуют в родительской таблице, иначе запрос завершится ошибкой.
Использование первичного ключа для уникальной идентификации записей
При проектировании таблицы важно правильно выбрать столбец или набор столбцов для первичного ключа. Чаще всего для этой роли выбираются столбцы с уникальными значениями, такие как идентификаторы (например, «ID»). Для этого поля не допускаются NULL-значения, что обеспечивает полную уникальность каждой строки.
Использование автоинкрементируемых значений для первичных ключей является одной из распространенных практик. В SQL Server это реализуется через тип данных INT или BIGINT с настройкой свойства IDENTITY. Такой подход исключает необходимость вручную задавать уникальные значения, автоматически увеличивая число при добавлении новой записи.
Однако при выборе первичного ключа следует учитывать несколько факторов. Он должен быть компактным, поскольку это влияет на производительность при индексации и поиске. Желательно, чтобы первичный ключ был числовым, так как операции с числами выполняются быстрее, чем с текстовыми значениями. Если ключ состоит из нескольких столбцов, это может увеличить сложность запросов и негативно сказаться на производительности.
Одним из важных аспектов является использование первичного ключа в качестве ссылки в других таблицах для создания связей. Внешний ключ, ссылающийся на первичный, помогает поддерживать целостность данных между связанными таблицами. Например, в таблице заказов может быть столбец с внешним ключом, ссылающимся на таблицу клиентов через их уникальный идентификатор.
Важно помнить, что при изменении значения первичного ключа в таблице может возникнуть необходимость обновить внешние ключи в других таблицах, ссылающихся на него. Чтобы избежать сложных и ресурсоемких операций, в большинстве случаев рекомендуется использовать стабильные, неизменяемые значения в качестве первичного ключа.
Как настроить ограничение ON DELETE и ON UPDATE
Ограничения ON DELETE и ON UPDATE управляют поведением внешних ключей при изменении данных в связанных таблицах. Эти ограничения позволяют контролировать, что происходит с записями в дочерних таблицах, когда в родительской таблице выполняются операции удаления или обновления. Для их настройки используется ключевое слово REFERENCES в запросах создания или изменения таблицы.
Каждое ограничение может быть задано для операций удаления или обновления и может иметь различные действия, такие как:
- CASCADE – изменение или удаление записи в родительской таблице автоматически применяется к записям в дочерней таблице.
- SET NULL – при удалении или обновлении записи в родительской таблице поле во внешнем ключе дочерней таблицы будет установлено в
NULL, если оно допускает такие значения. - SET DEFAULT – при удалении или обновлении записи в родительской таблице дочерняя запись получит значение по умолчанию для поля внешнего ключа.
- NO ACTION – операция в родительской таблице не выполняется, если она нарушает ссылочную целостность в дочерней таблице.
- RESTRICT – аналогично
NO ACTION, но проверка целостности происходит немедленно, и операция отклоняется сразу.
Пример создания ограничения ON DELETE CASCADE:
CREATE TABLE Orders (
OrderID int PRIMARY KEY,
CustomerID int,
CONSTRAINT FK_Customer
FOREIGN KEY (CustomerID)
REFERENCES Customers(CustomerID)
ON DELETE CASCADE
);
В этом примере, если запись о клиенте в таблице Customers будет удалена, все заказы этого клиента в таблице Orders также будут удалены.
Пример использования ON UPDATE SET NULL:
CREATE TABLE Employees (
EmployeeID int PRIMARY KEY,
ManagerID int,
CONSTRAINT FK_Manager
FOREIGN KEY (ManagerID)
REFERENCES Managers(ManagerID)
ON UPDATE SET NULL
);
В этом примере, если запись о менеджере в таблице Managers будет обновлена, поле ManagerID в таблице Employees будет установлено в NULL для всех сотрудников, у которых этот менеджер был указан.
Для добавления ограничений к существующей таблице используется команда ALTER TABLE:
ALTER TABLE Orders
ADD CONSTRAINT FK_Customer
FOREIGN KEY (CustomerID)
REFERENCES Customers(CustomerID)
ON DELETE SET NULL
ON UPDATE CASCADE;
В этом примере при удалении записи о клиенте поле CustomerID в таблице Orders будет установлено в NULL, а при обновлении значения в Customers – изменения автоматически отразятся в Orders.
Рекомендуется тщательно продумывать логику работы ограничений ON DELETE и ON UPDATE, так как неправильная настройка может привести к нежелательным последствиям, таким как потеря данных или нарушение целостности базы данных.
Использование индексов для улучшения производительности связей
В первую очередь стоит обратить внимание на создание индексов на колонках, участвующих в операциях JOIN. Например, если в запросах часто используется соединение по полям, таким как внешний ключ или индексируемый столбец, то создание соответствующего индекса на этих столбцах помогает SQL Server быстрее находить необходимые строки. Индексы на внешних ключах часто оказываются наиболее эффективными, так как они уменьшают количество операций поиска в родительской таблице.
Однако важно помнить, что индексы не всегда полезны. Например, если в запросах используются фильтры или сортировки по столбцам, не связанным с операциями JOIN, то индекс на столбцах для соединений может не повлиять на производительность. В таких случаях стоит использовать составные индексы, которые включают в себя как столбцы для JOIN, так и дополнительные столбцы для фильтров или сортировки. Это позволяет SQL Server эффективно использовать индекс для нескольких операций одновременно.
Для оптимизации работы с внешними ключами стоит использовать кластеризованные индексы. Кластеризованный индекс на столбце внешнего ключа помогает SQL Server быстро находить строки в таблице, где есть ссылки на другие таблицы. Важно, чтобы внешний ключ был индексирован до применения связей, чтобы избежать дорогостоящих операций поиска строк в больших таблицах.
Рекомендуется также учитывать размер таблиц и частоту изменений данных. В таблицах с большим объемом данных создание уникальных или составных индексов, которые охватывают несколько столбцов, может существенно ускорить выполнение запросов, но требует дополнительных ресурсов при вставке, обновлении или удалении данных. В таких случаях стоит проанализировать частоту выполнения запросов и выбрать подходящую стратегию для индексирования, чтобы избежать негативного влияния на производительность операций записи.
Использование полнотекстовых индексов для улучшения производительности связей может быть полезным в случаях, когда выполняются сложные фильтрации по текстовым данным. Это особенно актуально при соединении таблиц, где необходимо выполнить поиск по текстовым строкам. В таких случаях полнотекстовые индексы позволяют значительно ускорить выполнение запросов с фильтрацией по тексту, улучшая производительность в контексте связей.
Роль каскадных операций при обновлении и удалении данных
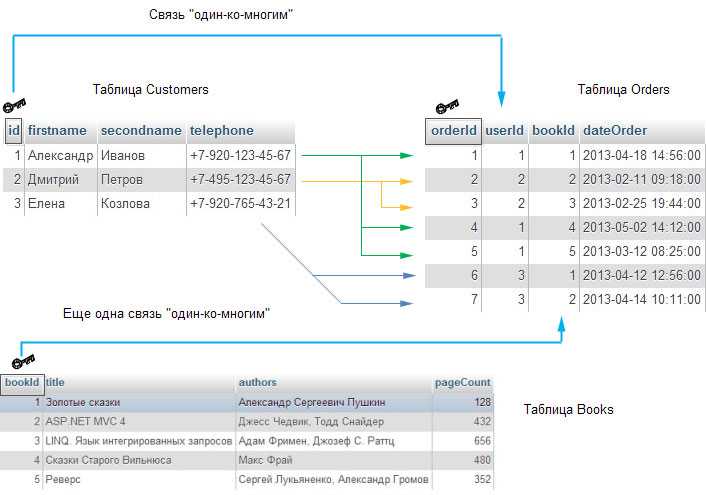
Каскадные операции (CASCADE) в SQL Server играют важную роль в поддержании целостности данных при изменении или удалении строк в связанных таблицах. Они автоматически применяются к дочерним записям, если это предусмотрено внешним ключом с соответствующими опциями обновления или удаления.
При использовании каскадных операций важно четко понимать, как они влияют на данные в базе данных. Например, при удалении записи в родительской таблице, каскадное удаление приведет к автоматическому удалению всех связанных записей в дочерних таблицах. Это снижает риск возникновения «осиротевших» данных, которые могут нарушить целостность системы. Такая операция устраняет необходимость в дополнительных запросах для удаления всех зависимых строк.
В случае обновления данных каскадное обновление используется для изменения значений в дочерних таблицах при изменении значения внешнего ключа в родительской таблице. Это может быть полезно, когда необходимо обновить ключевые значения в нескольких связанных таблицах без дополнительных сложных операций.
Однако использование каскадных операций требует осторожности. Неправильно настроенные каскадные операции могут привести к неожиданным последствиям, например, к массовому удалению или изменению данных. Рекомендуется всегда тестировать каскадные действия в тестовой среде перед применением в рабочей базе данных.
Типы каскадных операций:
- CASCADE DELETE: Удаление записи в родительской таблице вызывает автоматическое удаление всех связанных записей в дочерних таблицах.
- CASCADE UPDATE: Изменение значения внешнего ключа в родительской таблице приводит к автоматическому обновлению соответствующих значений в дочерних таблицах.
Рекомендуется использовать каскадные операции в случаях, когда связи между таблицами действительно требуют синхронных обновлений или удалений данных, чтобы избежать нарушений целостности. Для операций, которые не требуют каскадных действий, можно использовать такие параметры, как SET NULL или SET DEFAULT для управления поведением в случае удаления или обновления данных.
Как создать связи через промежуточные таблицы (многие ко многим)
Когда две таблицы имеют отношение «многие ко многим», необходимо использовать промежуточную таблицу для правильного установления связи между ними. Примером может служить ситуация, когда один студент может записаться на несколько курсов, а курс может быть выбран множеством студентов. В этом случае связь «многие ко многим» реализуется через дополнительную таблицу, которая будет содержать ключи обеих таблиц.
Промежуточная таблица должна включать как минимум два столбца, которые будут внешними ключами для двух исходных таблиц. Эти ключи создают связь между записями в обеих таблицах. Также желательно добавить дополнительную информацию, которая может характеризовать связь, например, дата регистрации студента на курс или оценка.
Пример создания таких таблиц:
1. Создадим таблицы для студентов и курсов:
CREATE TABLE Students ( StudentID INT PRIMARY KEY, Name NVARCHAR(100) ); CREATE TABLE Courses ( CourseID INT PRIMARY KEY, CourseName NVARCHAR(100) );
2. Создаем промежуточную таблицу для связи студентов с курсами:
CREATE TABLE StudentCourses ( StudentID INT, CourseID INT, EnrollmentDate DATETIME, PRIMARY KEY (StudentID, CourseID), FOREIGN KEY (StudentID) REFERENCES Students(StudentID), FOREIGN KEY (CourseID) REFERENCES Courses(CourseID) );
3. В этой промежуточной таблице каждый студент будет связан с одним или несколькими курсами. Строки в таблице StudentCourses будут содержать пары значений: идентификатор студента и курс, на который он записан, а также дополнительную информацию, такую как дата записи.
4. Для вставки данных в промежуточную таблицу используется обычный SQL-запрос:
INSERT INTO StudentCourses (StudentID, CourseID, EnrollmentDate) VALUES (1, 101, '2025-04-23'), (1, 102, '2025-04-24'), (2, 101, '2025-04-22');
5. Для извлечения информации о студентах и курсах с помощью SQL-запроса можно использовать JOIN:
SELECT s.Name, c.CourseName, sc.EnrollmentDate FROM StudentCourses sc JOIN Students s ON sc.StudentID = s.StudentID JOIN Courses c ON sc.CourseID = c.CourseID;
Такая структура позволяет гибко управлять отношениями «многие ко многим» и облегчает выполнение запросов для получения информации о связанных данных. Важно помнить, что правильное использование индексов и внешних ключей в промежуточной таблице ускоряет выполнение запросов и поддерживает целостность данных.
Проверка целостности данных при изменении связей между таблицами
Для защиты от нарушения целостности данных при изменении связей между таблицами необходимо использовать параметры ON DELETE и ON UPDATE в определении внешнего ключа. Они могут быть настроены следующим образом:
- CASCADE: автоматическое удаление или обновление связанных записей при изменении записи в родительской таблице. Этот вариант полезен в случаях, когда связанные данные должны быть удалены или изменены одновременно.
- SET NULL: установка значений в NULL в случае удаления или обновления записей в родительской таблице. Это предотвращает потерю информации, но требует, чтобы соответствующие столбцы допускали значение NULL.
- SET DEFAULT: установка значения по умолчанию при удалении или обновлении родительской записи. Важно, чтобы в столбце был задан дефолтный параметр.
- NO ACTION: отсутствие изменений в дочерней таблице. Это означает, что если нарушается ограничение целостности, операция будет отклонена.
- RESTRICT: предотвращение удаления или обновления записи в родительской таблице, если существуют связанные записи в дочерней таблице.
Выбор стратегии зависит от бизнес-логики. Например, в случае с каскадными операциями (CASCADE) могут возникать непредвиденные последствия, если пользователи случайно удаляют важные данные. Поэтому рекомендуется тщательно проанализировать поведение системы при использовании таких операций.
Помимо настройки внешних ключей, для обеспечения целостности данных стоит использовать транзакции. Это позволяет отменить изменения, если при обновлении или удалении данных возникают ошибки. В SQL Server для этого используется команда BEGIN TRANSACTION, которая открывает транзакцию. Если операция прошла успешно, применяется команда COMMIT, а в случае ошибки – ROLLBACK.
Кроме того, для проверки целостности данных важно регулярно выполнять тестирование базы данных с помощью скриптов, которые проверяют, не нарушены ли связи между таблицами. Это может быть полезным инструментом для предотвращения ошибок, связанных с неправильным изменением данных.
Одним из дополнительных методов является использование триггеров, которые могут отслеживать и контролировать изменения в таблицах, на которых заданы внешние ключи. Триггеры могут быть настроены на события INSERT, UPDATE и DELETE, что даёт дополнительный уровень контроля за целостностью данных. Однако важно помнить, что чрезмерное использование триггеров может снизить производительность базы данных, поэтому их использование должно быть обоснованным.
Правильная настройка связей между таблицами и контроль целостности данных требуют комплексного подхода, включающего как правильное использование внешних ключей, так и дополнительные механизмы, такие как транзакции и триггеры. Важно также регулярно проверять и тестировать логику работы с данными, чтобы предотвратить возможные проблемы с целостностью данных в будущем.
Вопрос-ответ:
Что такое внешний ключ и зачем он нужен?
Внешний ключ — это столбец или набор столбцов в таблице базы данных, который ссылается на первичный ключ другой таблицы. Его основная цель — обеспечить целостность данных, то есть предотвратить добавление записей в таблицу, которые не могут быть связаны с записями в другой таблице. Внешний ключ помогает поддерживать связь между таблицами и упрощает работу с данными, особенно при выполнении операций с несколькими таблицами.