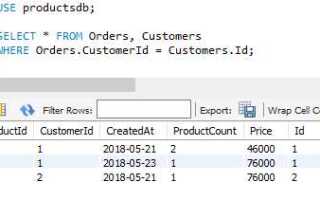
Связь таблиц в SQL осуществляется с помощью операторов JOIN, позволяющих формировать выборки на основе логических связей между данными. Один из ключевых инструментов – INNER JOIN, который возвращает только те строки, где значения объединяемых столбцов совпадают. Например, при объединении таблиц orders и customers по полю customer_id, результат включает только заказы, для которых существует соответствующий клиент.
Чтобы избежать потери данных из одной из таблиц, применяют LEFT JOIN или RIGHT JOIN. Первый сохраняет все строки из левой таблицы, даже если в правой нет соответствующих значений. Это критично, если необходимо отследить, например, пользователей без заказов. В таких случаях NULL будет обозначать отсутствие данных во второй таблице.
Использование ON и USING при определении условий объединения требует понимания различий: ON предоставляет гибкость в указании любых логических выражений, а USING упрощает синтаксис при одинаковых названиях столбцов. Предпочтительнее ON, если необходимо более точное управление логикой связи или при разных названиях колонок.
Работа с JOIN требует учета индексации: соединение по неиндексированным столбцам резко снижает производительность. Поэтому при проектировании схемы базы данных важно заранее продумать, какие поля будут использоваться для связей, и создать для них соответствующие индексы.
Когда использовать INNER JOIN и что произойдёт при совпадении и несовпадении значений
INNER JOIN применяется, когда необходимо получить только те строки, которые имеют совпадения по заданному условию соединения в обеих таблицах. Это соединение исключает все строки, у которых нет соответствий в одной из таблиц, тем самым гарантируя целостность связанного результата.
Если, например, соединяются таблицы orders и customers по полю customer_id, то результат INNER JOIN будет включать только те заказы, для которых найден соответствующий клиент. Если в orders есть строка с customer_id = 102, но в customers такой записи нет, эта строка будет исключена из результата.
Используйте INNER JOIN, когда нужны только взаимосвязанные данные. Это особенно важно при построении отчетов, где отсутствие связи может искажать агрегированные значения. Например, при подсчёте выручки по клиентам важно исключать заказы с некорректной или устаревшей ссылкой на клиента, иначе отчёт будет неточным.
Как LEFT JOIN возвращает строки из первой таблицы при отсутствии соответствий во второй
LEFT JOIN позволяет извлекать все строки из первой (левой) таблицы, даже если во второй (правой) таблице отсутствуют соответствующие значения. Это особенно важно при анализе неполных данных или выявлении пропущенных связей между сущностями.
Если во второй таблице не найдено совпадений по условию соединения, то в результирующем наборе данных поля из второй таблицы заполняются значением NULL. Это даёт возможность быстро определить, какие строки первой таблицы не имеют соответствий. Например, при соединении таблицы users с таблицей orders по users.id = orders.user_id, можно выявить пользователей без заказов.
Используйте конструкцию LEFT JOIN в сочетании с фильтром WHERE orders.user_id IS NULL, чтобы получить только те строки из первой таблицы, которые не находят соответствий во второй. Такой подход полезен при построении отчетов об активности, проверке целостности данных или поиске логических ошибок в связях между таблицами.
LEFT JOIN не изменяет количество строк в первой таблице – каждая строка включается хотя бы один раз, вне зависимости от наличия соответствий. Это делает его удобным инструментом для создания устойчивых запросов, не теряющих данные из основной таблицы при отсутствии внешних связей.
Что делает RIGHT JOIN и когда он полезен при работе с внешними данными
RIGHT JOIN выполняет объединение двух таблиц, где все строки из правой таблицы (той, которая указана после ключевого слова RIGHT JOIN) сохраняются, а из левой таблицы включаются только те строки, для которых есть совпадения. Если в левой таблице нет соответствующих строк, то в результате будут возвращены NULL-значения для её полей. Это полезно, когда важно сохранить все данные из правой таблицы, независимо от того, есть ли у них соответствующие записи в левой таблице.
RIGHT JOIN особенно эффективен, когда необходимо сохранить все записи из таблицы, которая является «основной» в контексте запроса, например, при анализе внешних данных или при необходимости увидеть все элементы из внешнего источника, даже если для некоторых из них нет точных совпадений в локальной базе данных. Такой тип соединения может использоваться в отчётах, где важно не потерять информацию о всех элементах правой таблицы, независимо от их наличия в левой.
Примером может служить запрос для анализа продаж, когда данные о товарах хранятся в одной таблице, а информация о заказах – в другой. В случае использования RIGHT JOIN, запрос вернёт все товары, даже если они не были проданы, в отличие от INNER JOIN, который исключит такие товары.
RIGHT JOIN подходит, когда правая таблица является основным источником данных или когда она содержит важную информацию, которая должна быть сохранена в результате запроса, несмотря на отсутствие совпадений в левой таблице.
FULL OUTER JOIN: как объединить всё при наличии и отсутствии соответствий
FULL OUTER JOIN в SQL используется для объединения данных из двух таблиц таким образом, чтобы сохранить все строки из обеих таблиц, включая те, для которых нет совпадений. Результатом будет таблица, в которой строки из обеих таблиц объединены по ключу, а отсутствующие значения будут заменены на NULL.
Когда выполняется FULL OUTER JOIN, запрос возвращает все строки из первой и второй таблицы. Для строк, где нет соответствующих данных во второй таблице, в результирующем наборе данных будут отображены значения NULL для столбцов второй таблицы. Аналогично, для строк из второй таблицы, где нет совпадений в первой, будут выведены значения NULL для столбцов первой таблицы.
Пример использования FULL OUTER JOIN:
SELECT A.id, A.name, B.salary FROM employees A FULL OUTER JOIN salaries B ON A.id = B.employee_id;
В этом запросе, если для некоторых сотрудников нет информации о зарплате в таблице «salaries», или наоборот, если в «salaries» отсутствуют данные по какому-то сотруднику, в итоговом наборе данных будут присутствовать строки с NULL в соответствующих столбцах.
FULL OUTER JOIN полезен, когда необходимо не только получить все совпадения, но и выявить строки, которые не имеют соответствий. Например, если вы работаете с данными о заказах и клиентах, и хотите видеть всех клиентов, независимо от того, сделали ли они заказ, или все заказы, независимо от того, были ли они сделаны клиентами, вам поможет FULL OUTER JOIN.
Важно помнить, что этот тип объединения может быть более ресурсоемким, чем другие типы JOIN, такие как INNER JOIN или LEFT JOIN, особенно если таблицы содержат большое количество данных. Поэтому стоит использовать FULL OUTER JOIN только тогда, когда это действительно необходимо, чтобы избежать ненужных нагрузок на базу данных.
Оптимизация запросов с FULL OUTER JOIN включает в себя правильное индексирование столбцов, участвующих в объединении, что поможет ускорить выполнение запроса и снизить нагрузку на сервер.
Как задать условие соединения через ON и чем оно отличается от WHERE
В SQL условие соединения через ON и фильтрация через WHERE выполняют разные функции, несмотря на внешнее сходство. Понимание этих различий помогает правильно строить запросы и оптимизировать их выполнение.
ON используется для определения условий, по которым две таблицы будут связаны друг с другом. Оно указывает, как строки из обеих таблиц должны совпасть для выполнения соединения. Например:
SELECT *
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id;
В данном примере условие ON o.customer_id = c.customer_id указывает, что соединение будет происходить по совпадению значений столбца customer_id в обеих таблицах.
С другой стороны, WHERE применяется после выполнения соединения для фильтрации результатов. Это условие ограничивает набор строк, которые возвращаются из уже соединенных таблиц. Например:
SELECT *
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id
WHERE o.order_date > '2025-01-01';
Здесь соединение все равно выполняется на основе столбца customer_id, но WHERE дополнительно фильтрует только те заказы, дата которых позже 1 января 2025 года.
Главные различия:
- Когда применяются:
ONопределяет, как именно происходят соединения, аWHEREфильтрует результаты после выполнения соединений. - Воздействие на тип соединения:
ONможет быть использован для указания условий, которые касаются соединения, например, для работы сLEFT JOIN, чтобы сохранить все строки из левой таблицы, даже если нет соответствующих строк в правой таблице.WHEREвлияет на окончательный результат, исключая те строки, которые не удовлетворяют условиям. - Поведение с NULL: при использовании
ONсLEFT JOINусловие соединения может включать строки, содержащиеNULL, если условие соединения не выполнено. В отличие от этого, условие вWHEREисключит строки сNULL, так как логические операторы сNULLне дают истинного результата.
Пример:
Для LEFT JOIN с условием в ON:
SELECT o.order_id, c.customer_name
FROM orders o
LEFT JOIN customers c ON o.customer_id = c.customer_id AND c.status = 'active';
В этом случае строки из таблицы orders будут отображаться даже без соответствующих строк в таблице customers, но только если статус клиента – «active». Если же это условие было бы в WHERE, строки с NULL в столбце customer_name были бы исключены.
Резюмируя: использование ON необходимо для указания условий самого соединения, тогда как WHERE применяется для фильтрации результатов уже после того, как соединение между таблицами выполнено.
Объединение по нескольким столбцам: как правильно писать сложные условия JOIN
Когда требуется объединить таблицы на основе нескольких столбцов, это возможно сделать с помощью сложных условий в SQL. Для этого используют оператор JOIN, который позволяет уточнять, по каким столбцам должна происходить связь. Например, если нужно объединить таблицы по сочетанию двух или более полей, необходимо указать несколько условий в разделе ON.
Пример базового синтаксиса объединения по нескольким столбцам:
SELECT *
FROM table1 AS t1
JOIN table2 AS t2
ON t1.column1 = t2.column1
AND t1.column2 = t2.column2;
В данном примере происходит соединение таблиц table1 и table2 по двум столбцам: column1 и column2. Условие AND задает обязательное совпадение значений этих столбцов. Использование нескольких условий дает возможность точнее фильтровать данные и избегать ошибок при соединении.
Когда в объединении участвует несколько столбцов, важно учитывать следующие моменты:
- Убедитесь, что типы данных столбцов одинаковы, чтобы избежать ошибок преобразования данных.
- Если объединение по нескольким столбцам не дает нужного результата, проверьте, что все пары значений в обеих таблицах имеют соответствие.
- Использование логических операторов
ANDиORв комбинации сJOINпозволяет уточнять условия соединения, но может привести к значительному увеличению времени выполнения запроса на больших объемах данных.
Для более сложных случаев можно комбинировать объединения с условиями фильтрации WHERE или добавлять дополнительные связи с другими таблицами, создавая запросы, которые могут эффективно работать с несколькими соединениями.
Кроме того, важно помнить о порядке соединений, особенно когда используются разные типы JOIN (например, INNER JOIN, LEFT JOIN, RIGHT JOIN). Каждый тип соединения имеет свои особенности, влияющие на результаты.
Что происходит при одинаковых названиях столбцов и как использовать псевдонимы

При использовании SQL JOIN для объединения таблиц может возникнуть ситуация, когда обе таблицы содержат столбцы с одинаковыми названиями. Например, если обе таблицы имеют столбец «id», это приведет к конфликту, так как SQL не сможет определить, к какому столбцу относится значение. В таком случае необходимо указать, какой столбец из какой таблицы следует использовать.
Для разрешения таких конфликтов используется метод псевдонимов. Псевдоним – это временное имя для таблицы или столбца, которое позволяет избежать неоднозначности в запросе.
Как использовать псевдонимы для столбцов
- Присваивайте псевдонимы столбцам в SELECT части запроса, используя ключевое слово AS. Например, если в обеих таблицах есть столбец «id», можно задать псевдонимы:
SELECT table1.id AS id_table1, table2.id AS id_table2. - При этом псевдонимы не изменяют реальные названия столбцов в базе данных, а только предоставляют удобные имена для работы в текущем запросе.
Как использовать псевдонимы для таблиц
- Псевдонимы можно присваивать и таблицам, что особенно полезно при работе с несколькими таблицами. Например:
SELECT t1.id, t2.name FROM table1 AS t1 JOIN table2 AS t2 ON t1.id = t2.id. - В данном примере таблицы «table1» и «table2» получают псевдонимы «t1» и «t2» соответственно, что делает запрос более компактным и улучшает читаемость.
Рекомендации
- Используйте псевдонимы для повышения ясности, особенно когда работаете с несколькими таблицами, содержащими одинаковые столбцы.
- Применяйте короткие, но информативные псевдонимы, чтобы не терять контекста при чтении запроса.
- В случае использования JOIN, всегда проверяйте, чтобы все неоднозначные столбцы были явно указаны с соответствующими псевдонимами.
- Для улучшения читаемости не забывайте ставить пробелы перед и после ключевых слов SQL, особенно при использовании псевдонимов для столбцов и таблиц.
Использование псевдонимов делает запросы более понятными и удобными, особенно когда таблицы содержат схожие или одинаковые столбцы. Важно помнить, что псевдонимы должны быть логичными и отражать смысл данных, с которыми они работают.
Вопрос-ответ:
Как можно объединить две таблицы в SQL?
Для того чтобы связать две таблицы в SQL, используется оператор JOIN. Он позволяет объединить данные из разных таблиц, основываясь на общем поле. Например, если у вас есть таблицы «сотрудники» и «отделы», можно объединить их по полю «id отдела», которое есть в обеих таблицах. В SQL можно использовать различные типы JOIN, такие как INNER JOIN, LEFT JOIN и RIGHT JOIN, в зависимости от того, какие данные вы хотите извлечь.
Что делает INNER JOIN и когда его использовать?
INNER JOIN — это тип соединения таблиц, который выбирает только те строки, где существует совпадение по указанному полю в обеих таблицах. Например, если у вас есть таблицы с данными о заказах и клиентах, и вы хотите получить только те заказы, которые привязаны к существующим клиентам, используйте INNER JOIN. Этот оператор исключит все заказы, не имеющие соответствующего клиента, и покажет только те строки, где есть совпадение в обеих таблицах.
Как LEFT JOIN отличается от INNER JOIN?
LEFT JOIN (или LEFT OUTER JOIN) возвращает все строки из левой таблицы и только те строки из правой таблицы, которые соответствуют условию соединения. Если в правой таблице нет соответствующих строк, результат будет содержать NULL для всех столбцов правой таблицы. В отличие от INNER JOIN, который возвращает только строки с совпадениями, LEFT JOIN позволяет получить все данные из левой таблицы, даже если нет совпадений в правой таблице. Например, если у вас есть таблица «сотрудники» и таблица «отделы», LEFT JOIN покажет всех сотрудников, даже тех, кто не привязан к отделу.
Можно ли использовать несколько JOIN в одном запросе?
Да, в SQL можно использовать несколько JOIN в одном запросе, чтобы объединить больше чем две таблицы. Например, вы можете сначала объединить таблицы «сотрудники» и «отделы», а затем добавить еще одну таблицу, например, «зарплаты», чтобы получить полную информацию о сотрудниках, их отделах и зарплатах. В таком случае просто добавляется еще один JOIN, и вы можете указать дополнительные условия соединения для каждой новой таблицы. Важно следить за правильным порядком JOIN и условиями соединения, чтобы избежать ошибок в результатах запроса.