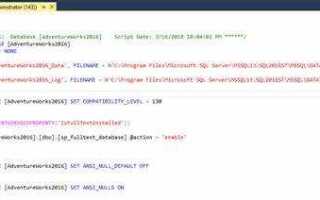
Процесс создания скрипта базы данных в SQL начинается с четкого понимания структуры данных и требований к базе. Основной задачей скрипта является создание всех необходимых объектов: таблиц, индексов, ограничений и связей между ними. Без правильного планирования и организации это может привести к проблемам с производительностью и масштабируемостью базы данных в будущем.
Первым шагом является проектирование структуры таблиц. Это включает определение колонок, типов данных для каждой колонки и, если необходимо, ограничений (например, NOT NULL, UNIQUE, CHECK). Важно заранее решить, какие поля будут являться ключами, и определить первичные и внешние ключи для обеспечения целостности данных.
Затем можно перейти к созданию скрипта. Он должен включать команды CREATE TABLE, ALTER TABLE и другие SQL-конструкции для создания нужных объектов. Например, для создания таблицы с двумя полями: id и name, где id будет первичным ключом, SQL запрос будет выглядеть следующим образом:
CREATE TABLE users ( id INT PRIMARY KEY, name VARCHAR(100) NOT NULL );
Для улучшения производительности базы данных важно также включать в скрипт создание индексов, особенно на тех полях, которые часто используются в операциях SELECT или в условиях фильтрации. Пример создания индекса:
CREATE INDEX idx_users_name ON users (name);
Важный момент: скрипт должен быть адаптирован под конкретную СУБД (систему управления базами данных), поскольку разные системы могут иметь небольшие различия в синтаксисе или в поддерживаемых типах данных. Например, в MySQL тип INT может использоваться для хранения чисел, но в PostgreSQL для более широких диапазонов чисел может потребоваться BIGINT.
После создания скрипта важно протестировать его в различных сценариях, чтобы убедиться в корректности работы базы данных при разных нагрузках. Это поможет избежать ошибок на этапе эксплуатации.
Определение структуры базы данных и выбор типа таблиц
Перед созданием базы данных важно четко определить её структуру. Это включает в себя решение о том, какие данные будут храниться, как они будут связаны между собой и какие типы таблиц использовать для хранения этих данных.
Основным шагом является анализ предметной области. Нужно определить, какие сущности (например, пользователи, заказы, продукты) должны быть представлены в базе данных, и какие атрибуты эти сущности будут иметь. Важно провести нормализацию данных, чтобы избежать избыточности и обеспечить целостность данных. Применение нормальных форм (до 3-й, в большинстве случаев) помогает устранить дублирование и упрощает работу с данными в будущем.
Выбор типа таблицы зависит от требований к хранению данных. В реляционных базах данных таблицы используют строго заданную структуру с определенными типами данных для каждого столбца. Например, если необходимо хранить данные о датах, тип данных будет DATE. Для числовых значений можно использовать INT или DECIMAL в зависимости от точности.
В некоторых случаях, например, для обработки больших объемов данных, может понадобиться использование индексированных таблиц или разделение таблиц на несколько частей с использованием партиционирования. Это позволяет ускорить выполнение запросов и улучшить производительность базы данных. Однако для небольших и средних проектов можно ограничиться стандартными таблицами с правильно настроенными индексами.
Особое внимание стоит уделить выбору ключей для таблиц. Первичный ключ (PRIMARY KEY) должен однозначно идентифицировать каждую запись. Если существуют связи между таблицами, для их реализации используются внешние ключи (FOREIGN KEY), которые обеспечивают целостность данных. Стоит также учитывать, что таблицы не всегда должны быть связаны между собой напрямую. В некоторых случаях могут быть использованы вспомогательные таблицы для реализации многих ко многим отношений.
Не менее важным аспектом является выбор между денормализованными и нормализованными структурами. Для баз, где требуется высокая производительность чтения, денормализация может ускорить работу запросов за счет избыточности данных. Однако в большинстве случаев нормализация предпочтительнее, так как она упрощает поддержку базы данных и уменьшает вероятность ошибок при вводе данных.
Написание SQL-запросов для создания таблиц

Для создания таблицы в SQL используется команда CREATE TABLE. С её помощью можно задать структуру таблицы, определить типы данных для каждого столбца и установить ограничения, такие как уникальность или обязательность значений.
Основной синтаксис запроса следующий:
CREATE TABLE имя_таблицы ( имя_столбца_1 тип_данных_1 [ограничения], имя_столбца_2 тип_данных_2 [ограничения], ... );
Каждое поле в таблице должно иметь уникальное имя и соответствующий тип данных. Типы данных варьируются в зависимости от СУБД, но наиболее часто встречаются следующие:
- INT – целочисленные значения;
- VARCHAR(255) – строковые данные переменной длины (в данном случае до 255 символов);
- DATE – дата;
- BOOLEAN – логический тип (истинно/ложно);
- DECIMAL – числа с фиксированной точностью.
Важно выбирать тип данных, соответствующий хранимой информации. Например, для цены лучше использовать DECIMAL, а не INT, чтобы избежать потерь точности.
Кроме того, часто полезно установить ограничения для столбцов:
- NOT NULL – запрещает вставку пустых значений;
- UNIQUE – обеспечивает уникальность значений в столбце;
- PRIMARY KEY – задаёт столбец как основной ключ (сочетает ограничения NOT NULL и UNIQUE);
- FOREIGN KEY – устанавливает связь с другим столбцом в другой таблице (внешний ключ);
- DEFAULT – задаёт значение по умолчанию, если в запросе не указано значение для поля.
Пример создания таблицы с ограничениями:
CREATE TABLE employees ( employee_id INT PRIMARY KEY, first_name VARCHAR(50) NOT NULL, last_name VARCHAR(50) NOT NULL, hire_date DATE DEFAULT CURRENT_DATE, salary DECIMAL(10, 2) CHECK (salary > 0) );
В данном примере столбец employee_id является основным ключом, а hire_date автоматически получает текущую дату, если при добавлении записи не указана конкретная дата. Также столбец salary проверяется на значение больше нуля.
Обратите внимание на использование ограничения CHECK для столбца salary, которое позволяет задать более сложные условия. Это ограничение гарантирует, что в таблицу будут вставляться только корректные данные.
Помимо стандартных типов данных и ограничений, существуют дополнительные особенности, такие как создание индексов, использование автогенерации значений (например, автоинкремент для уникальных идентификаторов) и создание триггеров для автоматического выполнения операций при изменении данных. Тем не менее, знание основ синтаксиса для создания таблиц является первым шагом в эффективной работе с базами данных.
Создание связей между таблицами с помощью внешних ключей
Внешний ключ (FOREIGN KEY) используется для установления связей между двумя таблицами в базе данных. Он ссылается на первичный ключ другой таблицы, обеспечивая целостность данных и предотвращая нарушение связей между таблицами.
При создании внешнего ключа важно соблюдать несколько принципов. Во-первых, столбец, к которому будет привязан внешний ключ, должен иметь индекс (чаще всего это первичный ключ). Во-вторых, тип данных в обоих столбцах должен совпадать. Это гарантирует корректную работу ссылочной целостности.
Для создания внешнего ключа в SQL используется конструкция FOREIGN KEY. Пример синтаксиса:
CREATE TABLE Заказы ( id INT PRIMARY KEY, клиент_id INT, дата DATE, FOREIGN KEY (клиент_id) REFERENCES Клиенты(id) );
В данном примере таблица Заказы имеет внешний ключ, ссылающийся на поле id таблицы Клиенты. Это позволяет каждому заказу быть привязанным к конкретному клиенту.
Кроме базовой связи, можно определить действия при удалении или обновлении записей. Для этого используются опции ON DELETE и ON UPDATE. Например:
CREATE TABLE Заказы ( id INT PRIMARY KEY, клиент_id INT, дата DATE, FOREIGN KEY (клиент_id) REFERENCES Клиенты(id) ON DELETE CASCADE ON UPDATE RESTRICT );
В этом примере, если клиент будет удален, все его заказы также будут удалены (ON DELETE CASCADE). Если же пытаемся обновить идентификатор клиента, это действие будет запрещено, если существуют зависимые записи в таблице заказов (ON UPDATE RESTRICT).
Важно помнить, что внешние ключи могут улучшить целостность данных, но они также могут замедлить выполнение операций вставки, обновления и удаления из-за необходимости проверки этих связей. Поэтому важно учитывать нагрузку на базу данных при проектировании схемы с использованием внешних ключей.
Добавление индексов для ускорения поиска данных
Наиболее эффективным индексы будут для столбцов, по которым часто выполняются операции поиска, сортировки или объединения таблиц. Например, если часто ищется информация по уникальному идентификатору или дате, имеет смысл добавить индекс на эти столбцы.
В SQL существуют различные типы индексов. Наиболее популярные из них:
- UNIQUE INDEX – обеспечивает уникальность значений в столбце. Он автоматически создаётся при добавлении ограничения UNIQUE.
- PRIMARY KEY INDEX – индекс, создаваемый при добавлении ограничения PRIMARY KEY. Он гарантирует уникальность значений и улучшает поиск по основному ключу.
- COMPOSITE INDEX – индекс, созданный на нескольких столбцах. Он полезен, когда часто выполняются запросы с условиями, затрагивающими несколько столбцов.
При создании индекса важно учитывать, что индексы не всегда могут значительно ускорить запросы. Например, если таблица содержит мало данных, наличие индекса может не иметь заметного эффекта. В случае, когда запросы часто возвращают большое количество строк, индексы могут быть неэффективны. В таких случаях стоит обратить внимание на стратегию кеширования или оптимизацию структуры данных.
Для создания индекса используется команда CREATE INDEX. Рассмотрим пример создания индекса на столбец «email» в таблице «users»:
CREATE INDEX idx_users_email ON users (email);
Если необходимо создать составной индекс на несколько столбцов, запрос будет выглядеть так:
CREATE INDEX idx_users_name_email ON users (name, email);
При добавлении индексов следует помнить, что индексы занимают место в памяти, и с увеличением объема данных их производительность может снижаться. Рекомендуется регулярно проводить анализ использования индексов с помощью EXPLAIN и оптимизировать их при необходимости.
Кроме того, создание индексов для часто изменяемых столбцов может привести к снижению производительности, так как каждый раз при вставке, обновлении или удалении данных необходимо обновлять соответствующие индексы. В таких случаях следует выбирать стратегию индексации с учётом особенностей работы с данными.
Описание ограничений данных с использованием CHECK и UNIQUE
Ограничение CHECK в SQL позволяет задать условие, которое проверяет данные перед их сохранением в таблице. Оно гарантирует, что значения, вводимые в столбцы, соответствуют определённым правилам или диапазонам. Например, для столбца «возраст» можно использовать ограничение CHECK, которое будет проверять, что значение находится в пределах от 18 до 100 лет:
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100),
age INT CHECK (age BETWEEN 18 AND 100)
);При попытке вставить значение за пределами этого диапазона, система выбросит ошибку. Это полезно для предотвращения ошибок при вводе данных, таких как некорректные или нежелательные значения.
Ограничение UNIQUE используется для обеспечения уникальности значений в одном или нескольких столбцах таблицы. Это ограничение гарантирует, что каждый элемент в указанном столбце или комбинации столбцов будет уникальным. Например, если нужно гарантировать, что email каждого пользователя в таблице будет уникальным, можно использовать следующий синтаксис:
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100) UNIQUE
);При попытке вставить строку с уже существующим значением в поле «email» система вернёт ошибку, предотвращая дублирование данных. Ограничение UNIQUE может быть также применено к нескольким столбцам одновременно, что позволяет обеспечивать уникальность комбинаций значений:
CREATE TABLE user_logs (
user_id INT,
log_date DATE,
UNIQUE (user_id, log_date)
);В таком случае гарантируется, что для каждого пользователя существует только один лог на определённую дату.
Написание запросов для вставки, обновления и удаления данных
Вставка данных
Запрос для вставки данных выполняется с помощью команды INSERT INTO. Синтаксис прост, но важно помнить, что порядок значений должен соответствовать порядку столбцов в таблице, если не указаны имена столбцов. Пример запроса:
INSERT INTO employees (name, position, salary)
VALUES ('Иван Иванов', 'Менеджер', 50000);
Если необходимо вставить данные в таблицу с указанием только некоторых столбцов, можно опустить остальные. Важно, чтобы количество и порядок значений совпадали с указанными столбцами:
INSERT INTO employees (name, salary)
VALUES ('Анна Смирнова', 60000);
Обновление данных
Для изменения существующих данных используется команда UPDATE. С помощью этой команды можно обновить одно или несколько полей в строках, удовлетворяющих определённому условию. Пример запроса:
UPDATE employees SET salary = 55000 WHERE name = 'Иван Иванов';
Если условие WHERE не указано, обновление будет выполнено для всех строк таблицы, что может привести к ошибке, поэтому всегда важно тщательно проверять условия. Чтобы обновить несколько столбцов, можно указать их через запятую:
UPDATE employees SET position = 'Руководитель', salary = 70000 WHERE name = 'Анна Смирнова';
Удаление данных
Для удаления данных применяется команда DELETE. Также как и в случае с UPDATE, следует использовать условие WHERE, чтобы избежать удаления всех строк. Пример запроса для удаления конкретной записи:
DELETE FROM employees WHERE name = 'Иван Иванов';
Если условие не задано, запрос удалит все строки таблицы, что крайне нежелательно. Например, запрос без условия удалит все записи:
DELETE FROM employees;
Важно помнить, что в большинстве СУБД операции INSERT, UPDATE и DELETE могут быть откатаны с помощью транзакций, если они выполняются внутри транзакции. Это позволяет вернуть базу данных в предыдущие состояния в случае ошибки. Поэтому для безопасности всегда используйте транзакции, если операция включает несколько запросов или влияет на важные данные.
Организация миграций и обновлений схемы базы данных
Основной задачей миграций является обеспечение возможности быстрого восстановления состояния базы данных на любом этапе её эволюции. Это достигается через хранение всех изменений в виде последовательных файлов миграций, которые могут быть применены к базе данных поочерёдно.
Основные рекомендации по организации миграций:
- Использование инструментов для миграций. Для автоматизации процесса обновления схемы базы данных рекомендуется использовать специализированные инструменты, такие как Flyway, Liquibase, Alembic или миграции в рамках ORM (например, Django Migrations, Rails ActiveRecord Migrations). Эти инструменты позволяют отслеживать изменения и применять их в нужной последовательности.
- Версионирование миграций. Каждая миграция должна быть привязана к уникальной версии. Например, с использованием нумерации или временных меток. Это позволяет точно определить, какие изменения были внесены на каждом этапе, и избежать конфликтов при одновременной работе нескольких разработчиков.
- Порядок применения миграций. Миграции должны применяться в чётком порядке. Это важно для корректной работы базы данных, так как изменения могут зависеть друг от друга. Например, добавление нового столбца в таблицу должно происходить до удаления старого столбца, если они связаны.
- Избежание потерь данных. Важно предусмотреть сценарии, когда в процессе обновления базы данных данные могут быть потеряны или изменены. Лучше всего заранее подготовить резервные копии и тестировать миграции на отдельной среде, прежде чем применять их в продакшн.
- Обратимость миграций. Каждая миграция должна иметь возможность отката. Это нужно для того, чтобы можно было восстановить базу данных до предыдущего состояния в случае ошибок или неудачного обновления. Откат миграции должен быть такой же прозрачный и безопасный, как и её применение.
- Документирование изменений. Важно, чтобы каждая миграция была снабжена описанием её цели и подробным объяснением внесённых изменений. Это улучшает понимание миграций другими разработчиками и помогает избежать ошибок при их применении в будущем.
- Использование тестовой среды. Применяйте миграции сначала в тестовом окружении, а затем в продакшн. Это даст возможность выявить ошибки до того, как они затронут реальную базу данных.
- Реализация атомарности. Миграции должны быть атомарными, т.е. все изменения внутри миграции должны быть выполнены или отменены вместе. Это гарантирует целостность данных при применении миграций.
- Управление зависимостями. Иногда миграции могут зависеть друг от друга. Чтобы избежать ошибок, стоит использовать механизм зависимостей для применения миграций в правильном порядке, а также предусматривать зависимости на уровне данных (например, создание индексов после добавления столбцов в таблицы).
Реализация этих принципов позволяет сделать процесс обновления базы данных более контролируемым и предсказуемым, минимизируя риск возникновения ошибок и потери данных.
Вопрос-ответ:
Какие основные моменты нужно учитывать при написании скрипта базы данных в SQL?
При написании скрипта базы данных важно учитывать несколько ключевых аспектов. Во-первых, нужно правильно определить типы данных для каждого столбца. Например, для текстовых данных можно использовать VARCHAR, для числовых — INT или DECIMAL. Во-вторых, следует внимательно продумать структуру таблиц и их связи (например, использовать внешние ключи для обеспечения целостности данных). Третьим моментом является создание индексов для ускорения запросов на чтение данных. Наконец, важно учитывать вопросы безопасности, такие как защита данных, особенно в случаях, когда база используется для хранения чувствительной информации. Также необходимо продумать, как будут обрабатываться ошибки и исключения в запросах.