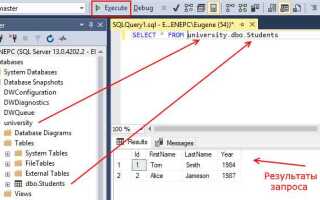
Работа с базами данных начинается с понимания структуры таблиц и умения формулировать точные запросы. SQL-запрос на выборку – это способ получить только те строки и столбцы, которые действительно нужны. Чтобы извлечь данные из таблицы users, достаточно использовать оператор SELECT с указанием нужных полей, например: SELECT name, email FROM users. Такой подход минимизирует нагрузку на базу и ускоряет обработку.
При наличии условий применяется WHERE. Он фильтрует строки по заданным критериям: SELECT * FROM orders WHERE status = ‘shipped’. Условие должно быть логически точным, иначе можно получить некорректный результат или пропустить нужные данные. Для сравнения дат стоит использовать формат ‘YYYY-MM-DD’ и учитывать временные зоны, если данные содержат временные метки.
Чтобы избежать дублирования записей, используется DISTINCT: SELECT DISTINCT country FROM customers. Это особенно полезно при аналитике и построении отчетов, где важно исключить повторяющиеся значения. При использовании агрегатных функций, таких как COUNT() или AVG(), всегда стоит добавлять GROUP BY, если выборка идет по нескольким категориям.
Чтение данных из нескольких таблиц требует понимания JOIN-операторов. Например, INNER JOIN позволяет получить только те строки, где есть соответствие в обеих таблицах: SELECT users.name, orders.total FROM users INNER JOIN orders ON users.id = orders.user_id. Важно указывать точные поля для соединения, иначе результат будет искажен или не вернет ни одной строки.
Как выбрать конкретные столбцы из таблицы
Чтобы получить только нужные поля из таблицы, необходимо в операторе SELECT явно указать имена столбцов. Это позволяет избежать лишней нагрузки при передаче и обработке данных, особенно при работе с большими таблицами.
- Указывайте имена столбцов через запятую:
SELECT имя, фамилия, дата_рождения FROM сотрудники; - Если столбец принадлежит конкретной таблице в объединении, используйте псевдоним:
SELECT a.имя, b.отдел FROM сотрудники a JOIN отделы b ON a.отдел_id = b.id; - Для избежания конфликтов имен и повышения читаемости применяйте
AS:SELECT имя AS Имя_сотрудника, дата_рождения AS ДатаРождения FROM сотрудники; - При работе с подзапросами также указывайте нужные поля:
SELECT имя FROM (SELECT * FROM сотрудники WHERE стаж > 5) sub; - Не используйте
SELECT *, если нет необходимости в получении всех полей – это замедляет запрос и усложняет анализ результатов.
Точное указание столбцов делает код более понятным, упрощает сопровождение и снижает риски при изменении структуры таблиц.
Как задать условия выборки с помощью WHERE
Ключевое предназначение оператора WHERE – ограничение набора возвращаемых строк. Он используется сразу после FROM или JOIN и применяет логические выражения к строкам таблицы.
Сравнение выполняется с помощью операторов: =, <>, >, >=, <, <=. Например, чтобы выбрать сотрудников с зарплатой выше 50000: SELECT * FROM employees WHERE salary > 50000;
Для фильтрации по строкам используют LIKE с шаблонами. Пример: SELECT name FROM clients WHERE name LIKE 'А%'; – выберет клиентов, чьё имя начинается с «А».
Чтобы указать сразу несколько условий, применяют логические операторы AND и OR. SELECT * FROM orders WHERE status = 'shipped' AND total > 1000; – вернёт только дорогие отправленные заказы.
Для значений из списка – IN. Пример: SELECT * FROM products WHERE category_id IN (2, 4, 7);
Проверка на пустые значения – IS NULL и IS NOT NULL: SELECT * FROM users WHERE last_login IS NULL;
Между двумя значениями – BETWEEN: SELECT * FROM sales WHERE date BETWEEN '2024-01-01' AND '2024-12-31';
Учитывайте, что WHERE фильтрует строки до выполнения агрегатных функций и группировки. Для фильтрации агрегированных результатов используйте HAVING.
Как отсортировать результаты с использованием ORDER BY
Пример: чтобы отсортировать список сотрудников по фамилии в алфавитном порядке:
SELECT фамилия, имя FROM сотрудники ORDER BY фамилия;
SELECT имя, зарплата FROM сотрудники ORDER BY зарплата DESC;
Если нужно отсортировать по нескольким полям, указывается порядок приоритета. Например, по отделу, затем по зарплате в убывающем порядке:
SELECT имя, отдел, зарплата FROM сотрудники ORDER BY отдел ASC, зарплата DESC;
Для числовых значений сортировка учитывает реальное значение. Для строк – используется лексикографический порядок с учётом регистра, если это не переопределено настройками СУБД.
Сортировка может значительно замедлить выполнение запроса при больших объёмах данных. Для оптимизации используйте индексы на полях, участвующих в ORDER BY.
Не используйте ORDER BY по алиасу из SELECT, если он создаётся функцией агрегации, без использования GROUP BY – это вызовет ошибку в некоторых СУБД.
При использовании LIMIT сортировка обязательна, если важен определённый порядок первых N строк:
SELECT имя FROM сотрудники ORDER BY дата_приёма ASC LIMIT 10;
Как ограничить количество строк с помощью LIMIT
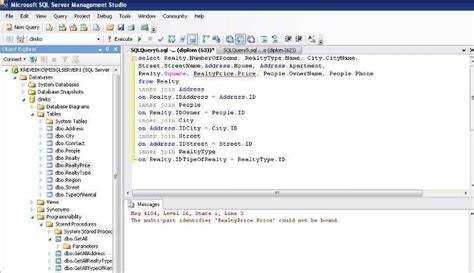
Оператор LIMIT используется для строгого ограничения количества возвращаемых строк. Он особенно полезен при работе с большими таблицами, когда необходимо получить только часть результатов.
Синтаксис предельно простой:
SELECT столбцы FROM таблица LIMIT количество;Например, чтобы получить первые 5 записей из таблицы users:
SELECT * FROM users LIMIT 5;Чтобы пропустить первые N строк и начать выборку позже, используется форма с двумя аргументами:
SELECT * FROM users LIMIT смещение, количество;Пример: пропустить 10 строк и вернуть следующие 5:
SELECT * FROM users LIMIT 10, 5;В PostgreSQL альтернативный синтаксис с OFFSET:
SELECT * FROM users LIMIT 5 OFFSET 10;Использование LIMIT без ORDER BY возвращает строки в произвольном порядке, что может привести к непредсказуемым результатам. Чтобы гарантировать последовательность, всегда указывайте критерий сортировки:
SELECT * FROM users ORDER BY created_at DESC LIMIT 10;Для постраничной навигации:
| Страница | Смещение | LIMIT-запрос |
|---|---|---|
| 1 | 0 | LIMIT 0, 10 |
| 2 | 10 | LIMIT 10, 10 |
| 3 | 20 | LIMIT 20, 10 |
Если требуется вывести ровно одну строку, используйте LIMIT 1. Это минимизирует нагрузку при проверке существования записи:
SELECT 1 FROM users WHERE email = 'example@example.com' LIMIT 1;При использовании вложенных запросов LIMIT можно применять как во внутреннем, так и во внешнем уровне. Однако важно учитывать порядок выполнения запросов, чтобы не получить ложные результаты.
Как объединить таблицы с помощью JOIN
Оператор JOIN используется для объединения строк из двух или более таблиц на основе логического условия. Наиболее распространённые типы объединений: INNER JOIN, LEFT JOIN, RIGHT JOIN и FULL JOIN. Каждый тип определяет, какие строки будут включены в результирующий набор.
INNER JOIN возвращает только те строки, у которых есть совпадения в обеих таблицах. Например, если требуется получить список заказов с именами клиентов, нужно объединить таблицы заказов и клиентов по идентификатору клиента: SELECT o.id, c.name FROM orders o INNER JOIN clients c ON o.client_id = c.id.
LEFT JOIN возвращает все строки из левой таблицы, даже если соответствующих строк в правой таблице нет. Если требуется список всех клиентов и, при наличии, их заказы: SELECT c.name, o.id FROM clients c LEFT JOIN orders o ON c.id = o.client_id. При отсутствии заказов значения из таблицы заказов будут NULL.
RIGHT JOIN работает аналогично LEFT JOIN, но сохраняет все строки из правой таблицы. Применяется реже, поскольку большинство СУБД ориентированы на LEFT JOIN. Пример: SELECT c.name, o.id FROM orders o RIGHT JOIN clients c ON o.client_id = c.id.
FULL JOIN объединяет результаты LEFT и RIGHT JOIN – включает все строки из обеих таблиц, подставляя NULL, если соответствий нет. Используется, когда важно сохранить полный контекст обеих таблиц: SELECT a.col1, b.col2 FROM table_a a FULL JOIN table_b b ON a.key = b.key.
Важно указывать алиасы таблиц и явно прописывать условия соединения в секции ON. Без этого высок риск получить декартово произведение с избыточным числом строк. Кроме того, при объединении по нескольким полям необходимо использовать логические операторы: ... ON t1.a = t2.a AND t1.b = t2.b.
Перед использованием JOIN убедитесь, что поля соединения индексированы. Это существенно снижает время выполнения запроса, особенно на больших объемах данных.
Как сгруппировать данные с использованием GROUP BY и агрегатных функций
Оператор GROUP BY используется для группировки строк, которые имеют одинаковые значения в одном или нескольких столбцах. Это позволяет агрегировать данные, например, вычислять суммы, средние значения, максимумы или минимумы для каждой группы.
Основная структура запроса с GROUP BY выглядит так:
SELECT столбец_группировки, агрегатная_функция(столбец) FROM таблица GROUP BY столбец_группировки;
При использовании GROUP BY важно учитывать, что в SELECT могут быть только те столбцы, которые либо участвуют в GROUP BY, либо являются результатом агрегатных функций. Например, если вы хотите подсчитать количество заказов для каждого клиента, запрос будет следующим:
SELECT client_id, COUNT(*) FROM orders GROUP BY client_id;
Агрегатные функции включают:
- COUNT() – подсчитывает количество строк в группе.
- SUM() – суммирует значения столбца в группе.
- AVG() – вычисляет среднее значение.
- MIN() – находит минимальное значение.
- MAX() – находит максимальное значение.
Если необходимо использовать несколько агрегатных функций, они могут быть комбинированы в одном запросе. Например, для подсчета общего количества заказов и суммы по каждому клиенту можно использовать следующий запрос:
SELECT client_id, COUNT(*), SUM(order_amount) FROM orders GROUP BY client_id;
GROUP BY можно использовать с несколькими столбцами. В таком случае строки будут группироваться по комбинации значений этих столбцов. Пример для группировки заказов по клиенту и дате:
SELECT client_id, order_date, SUM(order_amount) FROM orders GROUP BY client_id, order_date;
Для фильтрации данных по агрегированным значениям применяется HAVING. В отличие от WHERE, который фильтрует строки до группировки, HAVING фильтрует уже сгруппированные данные. Например, чтобы отфильтровать клиентов, у которых сумма заказов больше 1000:
SELECT client_id, SUM(order_amount) FROM orders GROUP BY client_id HAVING SUM(order_amount) > 1000;
С использованием GROUP BY можно эффективно анализировать данные и получать сводную информацию по различным категориям. Важно помнить, что использование агрегатных функций на больших объемах данных может потребовать оптимизации запросов для повышения производительности.