Создание таблицы в MS SQL Server – это фундаментальный процесс, необходимый для организации данных в реляционной базе данных. Каждый столбец в таблице имеет свой тип данных, что позволяет эффективно хранить и обрабатывать информацию. Процесс создания таблицы начинается с выбора правильной структуры и типа данных, соответствующих целям вашего проекта.
Шаг 1: Определение структуры таблицы. Прежде чем приступить к созданию таблицы, важно точно понять, какие данные вы будете хранить. Для этого создайте список всех необходимых атрибутов (столбцов) и решите, какие типы данных лучше всего подходят для каждого столбца. Например, для хранения даты используйте тип DATE, для числовых значений – INT или DECIMAL.
Шаг 2: Написание команды CREATE TABLE. Основной командой для создания таблицы в MS SQL Server является CREATE TABLE. Пример синтаксиса для создания таблицы:
CREATE TABLE имя_таблицы (
id INT PRIMARY KEY,
имя VARCHAR(50),
дата_рождения DATE
);В этом примере создается таблица с тремя столбцами: id (тип данных INT), имя (тип данных VARCHAR(50)) и дата_рождения (тип данных DATE).
Шаг 3: Определение ограничений. Одним из важнейших аспектов является установка ограничений на столбцы, чтобы обеспечить целостность данных. Например, столбец id можно сделать первичным ключом с помощью PRIMARY KEY, что гарантирует уникальность значений. Также можно использовать NOT NULL для столбцов, значения которых не могут быть пустыми.
Шаг 4: Выполнение SQL-команды. После того как SQL-запрос готов, его можно выполнить в MS SQL Server. Для этого используйте SQL Server Management Studio (SSMS) или другой инструмент для работы с SQL Server. В результате выполнения команды будет создана таблица с указанными аттрибутами и ограничениями.
Этот процесс можно дополнить другими элементами, такими как внешние ключи, индексы и триггеры, в зависимости от специфики базы данных и бизнес-логики проекта.
Выбор типа данных для столбцов таблицы
Типы данных определяют, какие значения могут храниться в столбцах таблицы, и влияют на производительность, хранимые данные и поддержку целостности. При выборе типа данных нужно учитывать несколько факторов: предполагаемый объем данных, требования к точности и производительности запросов.
Основные категории типов данных:
- Числовые типы: Используются для хранения целых чисел и чисел с плавающей запятой. Например,
INTдля целых чисел иDECIMALдля чисел с фиксированной точностью. Важно выбрать подходящий диапазон чисел, чтобы не расходовать излишние ресурсы. ИспользованиеBIGINTпри малых значениях может привести к неэффективному использованию памяти. - Строковые типы:
VARCHARиCHAR– основные типы для хранения текстовых данных.VARCHARпредпочтительнее, так как он экономит место, храня только фактическую длину строки.CHARиспользуется, если строка всегда имеет фиксированную длину. - Типы для даты и времени: Для хранения дат и времени используйте
DATETIME,DATEилиTIME, в зависимости от необходимости. Если нужно хранить только дату без времени, лучше выбратьDATE, чтобы уменьшить объем данных. - Логические типы: Тип
BITиспользуется для хранения логических значений (0 или 1). Он занимает минимум памяти и подходит для флагов или булевых значений. - Типы для хранения больших объектов:
TEXT,NTEXT,IMAGEиспользуются для хранения больших текстовых или бинарных данных. Однако для текстов предпочтительнее использоватьVARCHAR(MAX)иNVARCHAR(MAX), так как они более эффективны.
При выборе типа данных также учитывайте:
- Масштабируемость: Тип данных должен быть гибким для будущего роста. Например, если возможно увеличение числа записей в таблице, лучше использовать более компактные типы данных (например,
SMALLINTвместоINT), если этого достаточно для текущих данных. - Целостность данных: Используйте подходящие типы данных для обеспечения точности и надежности хранения. Например,
DECIMALилиNUMERICпредпочтительны для финансовых данных, где важно сохранять точность до определенной цифры после запятой. - Производительность: Избыточное использование типов данных, занимающих много памяти, может снизить производительность запросов. Например, для строк длиной до 50 символов лучше использовать
VARCHAR(50), чемVARCHAR(MAX). - Совместимость с другими системами: Если база данных будет взаимодействовать с другими системами или использоваться для импорта данных, убедитесь, что выбранные типы данных совместимы с этими системами.
Использование правильных типов данных помогает не только сэкономить место в базе данных, но и улучшить производительность запросов, обеспечивая корректное хранение и обработку данных.
Создание таблицы через SQL-запрос
Для создания таблицы в MS SQL Server используется команда CREATE TABLE, которая определяет структуру новой таблицы в базе данных. Важно указать название таблицы, а также типы данных для каждого столбца. Пример синтаксиса запроса:
CREATE TABLE имя_таблицы (
имя_столбца1 тип_данных1 [ограничения],
имя_столбца2 тип_данных2 [ограничения],
...
);Основные элементы запроса:
- имя_таблицы – это уникальное имя таблицы в базе данных.
- имя_столбца – имя каждого столбца, которое должно быть уникальным в пределах одной таблицы.
- тип_данных – тип данных, который будет храниться в столбце (например,
INT,VARCHAR,DATEи другие). - ограничения – дополнительные условия для столбца, такие как
NOT NULL,PRIMARY KEY,FOREIGN KEYи другие.
Пример создания таблицы с несколькими столбцами:
CREATE TABLE Employees (
EmployeeID INT PRIMARY KEY,
FirstName VARCHAR(50) NOT NULL,
LastName VARCHAR(50) NOT NULL,
HireDate DATE,
Salary DECIMAL(10, 2)
);В этом примере создается таблица Employees, содержащая столбцы:
EmployeeID– целочисленный идентификатор сотрудника, который является первичным ключом;FirstNameиLastName– строки для хранения имени и фамилии сотрудника, с ограничением на обязательное заполнение;HireDate– дата приема на работу сотрудника;Salary– зарплата с двумя знаками после запятой.
Для создания таблицы важно соблюдать правильный порядок и синтаксис. Также следует учитывать ограничения для каждого столбца, такие как размер данных для строковых типов (например, VARCHAR(50)) или точность для числовых типов (например, DECIMAL(10, 2)).
При необходимости можно добавлять дополнительные параметры для внешних ключей, уникальных ограничений и индексов. Например, чтобы связать таблицу сотрудников с таблицей отделов, можно использовать внешний ключ:
CREATE TABLE Departments (
DepartmentID INT PRIMARY KEY,
DepartmentName VARCHAR(100) NOT NULL
);
CREATE TABLE Employees (
EmployeeID INT PRIMARY KEY,
FirstName VARCHAR(50) NOT NULL,
LastName VARCHAR(50) NOT NULL,
HireDate DATE,
Salary DECIMAL(10, 2),
DepartmentID INT,
FOREIGN KEY (DepartmentID) REFERENCES Departments(DepartmentID)
);Таким образом, SQL-запрос для создания таблицы с внешним ключом обеспечивает связность данных между таблицами и предотвращает нарушение целостности данных.
Добавление ограничений на столбцы (NOT NULL, UNIQUE, и другие)
При создании таблиц в MS SQL Server важно правильно настроить ограничения на столбцы. Это помогает обеспечить целостность данных и оптимизировать работу с базой данных. Рассмотрим, как добавить такие ограничения, как NOT NULL, UNIQUE и другие.
NOT NULL — это ограничение, которое запрещает вставку пустых значений (NULL) в столбец. Это полезно, когда данные в столбце должны всегда присутствовать. Для добавления этого ограничения при создании таблицы используется следующий синтаксис:
CREATE TABLE Employees ( EmployeeID INT NOT NULL, Name VARCHAR(100) NOT NULL );
В этом примере столбцы EmployeeID и Name не могут содержать NULL-значения.
UNIQUE — ограничение, которое гарантирует, что все значения в столбце или группе столбцов будут уникальными. Это полезно для предотвращения дублирования данных, например, в столбце, содержащем номера телефонов или идентификаторы. Чтобы добавить ограничение UNIQUE, можно использовать такой синтаксис:
CREATE TABLE Employees ( EmployeeID INT NOT NULL UNIQUE, Email VARCHAR(100) UNIQUE );
В данном примере Email не может повторяться в таблице, а EmployeeID должен быть уникальным.
PRIMARY KEY — это комбинированное ограничение, которое включает в себя NOT NULL и UNIQUE. Он используется для определения уникального идентификатора записи в таблице. Обычно столбец с первичным ключом служит для связей между таблицами. Пример:
CREATE TABLE Employees ( EmployeeID INT PRIMARY KEY, Name VARCHAR(100) );
В этом случае столбец EmployeeID будет уникальным и не может содержать NULL.
FOREIGN KEY — ограничение, которое связывает данные в одном столбце с данными в другом. Это важно для поддержания ссылочной целостности. Например, в таблице заказов можно ссылаться на идентификатор сотрудника в таблице сотрудников:
CREATE TABLE Orders ( OrderID INT PRIMARY KEY, EmployeeID INT, FOREIGN KEY (EmployeeID) REFERENCES Employees(EmployeeID) );
Ограничение FOREIGN KEY гарантирует, что значения в столбце EmployeeID таблицы Orders будут существовать в таблице Employees.
CHECK — ограничение, которое позволяет установить условия для значений столбца. Например, если нужно гарантировать, что возраст сотрудника не может быть меньше 18 лет:
CREATE TABLE Employees ( EmployeeID INT PRIMARY KEY, Age INT CHECK (Age >= 18) );
Здесь добавлено ограничение, которое проверяет, что значение в столбце Age всегда будет не менее 18.
DEFAULT — ограничение, которое задает значение по умолчанию для столбца, если оно не указано при вставке записи. Например, можно задать значение по умолчанию для столбца, который хранит дату создания записи:
CREATE TABLE Employees ( EmployeeID INT PRIMARY KEY, HireDate DATETIME DEFAULT GETDATE() );
В этом случае, если при добавлении записи не указана дата, то автоматически будет установлена текущая дата и время.
Правильное использование ограничений помогает повысить безопасность и производительность базы данных, предотвращая ошибочные или неполные данные.
Настройка первичного ключа для таблицы
Для создания первичного ключа можно использовать SQL-запрос или графический интерфейс SQL Server Management Studio (SSMS). Рассмотрим оба способа.
1. С использованием SQL-запроса:
Для добавления первичного ключа при создании таблицы используется следующая конструкция:
CREATE TABLE НазваниеТаблицы ( ID INT NOT NULL, НазваниеСтолбца1 VARCHAR(255), НазваниеСтолбца2 DATETIME, CONSTRAINT PK_НазваниеТаблицы PRIMARY KEY (ID) );
В этом примере столбец ID установлен как первичный ключ для таблицы. Обратите внимание, что в столбце с первичным ключом не могут быть NULL-значения.
2. Добавление первичного ключа в уже существующую таблицу:
Если таблица уже создана, но необходимо добавить первичный ключ, это можно сделать с помощью следующего запроса:
ALTER TABLE НазваниеТаблицы ADD CONSTRAINT PK_НазваниеТаблицы PRIMARY KEY (ID);
В случае, если первичный ключ должен быть составным (состоящим из нескольких столбцов), указываются все нужные столбцы в списке:
ALTER TABLE НазваниеТаблицы ADD CONSTRAINT PK_НазваниеТаблицы PRIMARY KEY (ID, НазваниеСтолбца2);
3. С использованием SSMS:
Для задания первичного ключа через графический интерфейс откройте SSMS, выберите таблицу, щелкните правой кнопкой мыши и выберите «Design». Затем, для столбца, который должен стать частью первичного ключа, установите свойство «Is Identity» и установите флаг на «Yes». После этого выберите столбец и назначьте его как первичный ключ, выбрав «Set Primary Key» в контекстном меню.
Важно помнить, что столбцы с первичным ключом должны быть уникальными и не содержать NULL-значений. Установка первичного ключа на несколько столбцов требует, чтобы все значения комбинации этих столбцов были уникальными для каждой записи.
Настройка первичного ключа помогает поддерживать целостность данных и ускоряет выполнение запросов, которые используют этот ключ для поиска и связи данных в других таблицах.
Создание внешнего ключа для связи с другими таблицами
Внешний ключ (FOREIGN KEY) используется для установления связи между таблицами в базе данных, обеспечивая целостность данных и гарантируя, что значения в одном столбце (внешнем ключе) соответствуют значениям в другом столбце (первичном ключе) другой таблицы. Для добавления внешнего ключа в таблицу в MS SQL Server нужно выполнить несколько шагов.
1. Определите столбец, который будет служить внешним ключом. Этот столбец должен иметь тот же тип данных, что и столбец, ссылающийся на первичный ключ другой таблицы.
2. Используйте команду ALTER TABLE для добавления внешнего ключа. Синтаксис для создания внешнего ключа следующий:
ALTER TABLE <имя_таблицы> ADD CONSTRAINT <имя_ограничения> FOREIGN KEY (<имя_столбца_внешнего_ключа>) REFERENCES <имя_другой_таблицы> (<имя_столбца_первичного_ключа>);
3. Проверьте корректность данных. Все значения в столбце внешнего ключа должны соответствовать значениям в столбце первичного ключа в другой таблице, иначе добавление внешнего ключа приведет к ошибке.
4. При необходимости укажите правила каскадного удаления или обновления данных, чтобы обеспечить автоматическое обновление или удаление строк в связанных таблицах. Это можно сделать с помощью ключевых слов ON DELETE CASCADE или ON UPDATE CASCADE. Например:
ALTER TABLE <имя_таблицы> ADD CONSTRAINT <имя_ограничения> FOREIGN KEY (<имя_столбца_внешнего_ключа>) REFERENCES <имя_другой_таблицы> (<имя_столбца_первичного_ключа>) ON DELETE CASCADE ON UPDATE CASCADE;
5. Для удаления внешнего ключа используйте команду ALTER TABLE с параметром DROP CONSTRAINT:
ALTER TABLE <имя_таблицы> DROP CONSTRAINT <имя_ограничения>;
Рекомендуется всегда явно указывать имена ограничений, чтобы избежать путаницы при изменении схемы базы данных. Внешние ключи могут существенно улучшить структуру базы данных, обеспечивая целостность и предотвращая неконсистентность данных.
Определение индексов для ускорения поиска данных
При создании индексов важно учитывать, какие поля чаще всего используются в операциях фильтрации (WHERE), сортировки (ORDER BY) и объединений (JOIN). Для таких полей следует создавать индексы, чтобы минимизировать затраты времени на поиск данных. Наиболее эффективными являются так называемые «кластеризованные индексы», которые определяют физический порядок данных в таблице.
Если таблица часто используется для поиска по одному или нескольким полям, создайте некластеризованный индекс. Такой индекс позволяет быстрее выполнять поиск по этим полям, не меняя порядок строк в таблице. Важно помнить, что индекс необходимо создавать на тех столбцах, которые участвуют в запросах, а не на всех подряд.
Индексы могут быть как уникальными, так и неуникальными. Уникальный индекс гарантирует, что значения в столбце или наборе столбцов будут уникальными, что также ускоряет поиск, так как сервер не тратит время на проверку дубликатов.
Использование составных индексов (индексов на несколько столбцов) может существенно повысить производительность запросов, если в запросах часто используются фильтры по комбинации столбцов. Однако важно соблюдать осторожность: составные индексы могут замедлить операции вставки, обновления и удаления, так как обновление индекса требует большего времени.
Для оптимизации работы индексов полезно периодически проводить их реорганизацию или перестроение. Индексы могут фрагментироваться из-за частых операций добавления, удаления и обновления данных. Реорганизация индексов помогает устранить фрагментацию и поддерживать их эффективность.
Необходимо следить за количеством создаваемых индексов. Избыточное количество индексов может ухудшить производительность при изменении данных, так как каждый индекс требует дополнительной обработки при вставке, обновлении или удалении записей.
Добавление комментариев к таблице и её столбцам
В MS SQL Server добавление комментариев к таблицам и столбцам помогает улучшить понимание структуры базы данных для разработчиков и администраторов. Эти комментарии можно использовать для описания назначения таблицы или столбца, ограничения значений или других особенностей. Комментарии не влияют на производительность, но делают структуру базы данных более удобной для работы.
Для добавления комментария к таблице в SQL Server используется команда sp_addextendedproperty. Эта процедура позволяет добавлять метаданные, включая описание таблицы. Пример добавления комментария:
EXEC sp_addextendedproperty
@name = N'MS_Description',
@value = N'Таблица для хранения информации о клиентах',
@level0type = N'SCHEMA', @level0name = dbo,
@level1type = N'TABLE', @level1name = Customers;Этот запрос добавляет описание таблицы Customers в схеме dbo. Важно помнить, что имя свойства должно быть уникальным для каждого объекта. В данном случае используется MS_Description, что является стандартом для комментариев в SQL Server.
Добавление комментариев к столбцам осуществляется аналогичным способом, но с указанием уровня столбца:
EXEC sp_addextendedproperty
@name = N'MS_Description',
@value = N'Фамилия клиента',
@level0type = N'SCHEMA', @level0name = dbo,
@level1type = N'TABLE', @level1name = Customers,
@level2type = N'COLUMN', @level2name = LastName;В этом примере добавлен комментарий к столбцу LastName в таблице Customers.
Для просмотра добавленных комментариев можно использовать команду fn_listextendedproperty, которая извлекает метаданные:
SELECT
objname, value
FROM fn_listextendedproperty (NULL, 'SCHEMA', 'dbo', 'TABLE', 'Customers', NULL, NULL);Эта команда возвращает все комментарии для таблицы Customers в схеме dbo.
Удалить комментарий можно с помощью команды sp_dropextendedproperty:
EXEC sp_dropextendedproperty
@name = N'MS_Description',
@level0type = N'SCHEMA', @level0name = dbo,
@level1type = N'TABLE', @level1name = Customers;Правильное использование комментариев повышает читаемость кода и облегчает поддержку базы данных. Особенно полезно это для больших проектов, где таблицы могут иметь сложную структуру и множество связей между ними.
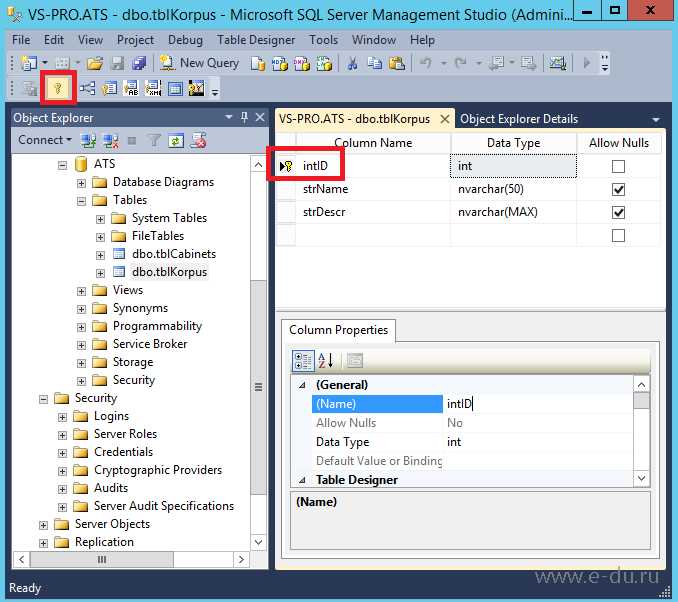
Использование GUI в SQL Server Management Studio для создания таблицы
SQL Server Management Studio (SSMS) предоставляет удобный графический интерфейс для создания таблиц, что значительно упрощает процесс разработки базы данных. Вместо написания SQL-запросов можно использовать визуальные инструменты, позволяющие быстро настроить структуру таблицы.
Чтобы создать таблицу через GUI, выполните следующие шаги:
1. Откройте SQL Server Management Studio и подключитесь к серверу базы данных.
2. В объектном проводнике найдите базу данных, в которой хотите создать таблицу. Разверните её, затем правой кнопкой мыши кликните на папку Tables и выберите пункт New Table….
3. Откроется окно для редактирования структуры таблицы. В этом окне можно добавлять столбцы, определять их типы данных и свойства.
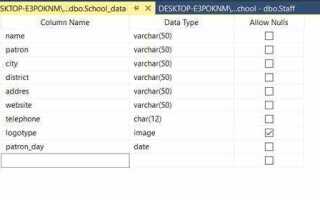
4. Для каждого столбца задайте следующие параметры:
- Name – имя столбца.
- Data Type – тип данных, например, INT, VARCHAR(50), DATETIME и т.д.
- Allow Nulls – выбор, будет ли столбец принимать значения NULL. Если этот параметр не установлен, то столбец будет обязательным для заполнения.
- Primary Key – установите флажок для указания столбца как первичного ключа, если это необходимо.
5. После того как структура таблицы настроена, можно сохранить изменения. Для этого нажмите Save или используйте комбинацию клавиш Ctrl + S. Вам будет предложено ввести имя таблицы.
6. При необходимости можно настроить дополнительные параметры, такие как индексы или ограничения, используя вкладки в окне создания таблицы.
7. После сохранения таблица будет отображаться в папке Tables в объектном проводнике. Теперь её можно использовать для добавления данных или выполнения других операций.
Использование GUI в SSMS позволяет минимизировать ошибки и ускорить процесс создания таблиц, особенно для пользователей, не знакомых с SQL-синтаксисом. Однако для сложных операций и более гибкой настройки рекомендуется также использовать T-SQL.