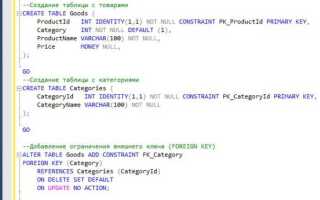
Создание таблицы в SQL – ключевая часть работы с базами данных, поскольку именно в таблицах хранится вся информация. Процесс создания таблицы подразумевает выбор подходящей структуры данных и правильное определение типов для каждого столбца. Это требует понимания того, какие данные будут храниться и как они будут использоваться. Основной задачей является обеспечение целостности данных и оптимизация запросов.
Основной синтаксис для создания таблицы в SQL выглядит следующим образом:
CREATE TABLE имя_таблицы ( имя_столбца1 тип_данных1, имя_столбца2 тип_данных2, ... );
Каждый столбец в таблице должен быть тщательно спланирован. Например, если столбец хранит только числовые значения, то тип данных должен быть числовым (например, INT или DECIMAL). Для строковых данных лучше использовать типы, такие как VARCHAR или TEXT, в зависимости от предполагаемого объема данных. Важно также учитывать ограничения, такие как NOT NULL, которые обеспечивают обязательность значения в столбце.
Для повышения производительности запросов и обеспечения уникальности данных в таблице, целесообразно использовать индексы. Один из самых распространенных методов – создание первичного ключа с помощью команды PRIMARY KEY. Этот ключ гарантирует, что каждый записанный в таблицу элемент будет уникальным. Например, если таблица хранит информацию о пользователях, то столбец с идентификатором пользователя можно сделать первичным ключом.
Не забывайте также об отношениях между таблицами. Когда данные одной таблицы ссылаются на данные другой, следует использовать внешние ключи. Это помогает поддерживать целостность базы данных, предотвращая появление «осиротевших» записей. Внешний ключ определяет связь между столбцами двух таблиц и может быть добавлен с помощью команды FOREIGN KEY.
Выбор типа данных для столбцов таблицы
Тип данных определяет, какие значения могут храниться в столбце и как они обрабатываются. Неправильный выбор замедляет запросы, увеличивает объём базы и ограничивает функциональность.
Числовые значения. Для целых чисел используйте INT, если диапазон от –2 147 483 648 до 2 147 483 647 подходит. При меньших значениях достаточно SMALLINT или TINYINT. Для больших чисел – BIGINT. Если предполагается работа только с положительными числами, применяйте модификатор UNSIGNED.
Десятичные числа. Для финансовых данных используйте DECIMAL(precision, scale). Например, DECIMAL(10,2) хранит значения с двумя знаками после запятой до 99999999.99. Для приближённых значений, таких как измерения, подходит FLOAT или DOUBLE, но учитывайте возможные ошибки округления.
Строки. Если длина ограничена и известна заранее – CHAR(n). Он всегда использует фиксированное количество байт. Для переменной длины – VARCHAR(n). Не задавайте n «с запасом»: это влияет на использование памяти и индексацию.
Дата и время. DATE хранит значения от ‘1000-01-01’ до ‘9999-12-31’. DATETIME включает время. Если требуется только текущее время без даты – TIME. Для временных меток применяйте TIMESTAMP, учитывая автоматическую конвертацию по часовому поясу сервера.
Булевы значения. Используйте TINYINT(1): значение 0 трактуется как FALSE, 1 – как TRUE. Многие СУБД не имеют отдельного логического типа.
Идентификаторы и ключи. Для автоинкремента чаще всего выбирается INT UNSIGNED AUTO_INCREMENT. При использовании UUID – CHAR(36) или BINARY(16), второй вариант экономнее по памяти и быстрее индексируется.
Определение первичного ключа в таблице
- Выбирайте столбец с уникальными значениями. Чаще всего это ID с автоинкрементом:
id INT PRIMARY KEY AUTO_INCREMENT(в MySQL) илиSERIAL PRIMARY KEY(в PostgreSQL). - Избегайте использования полей, значение которых может измениться (например, email или имя пользователя).
- Если уникальная идентификация невозможна одним столбцом, используйте составной ключ:
PRIMARY KEY (user_id, product_id)– полезно в таблицах связей (например, заказы или лайки). - Убедитесь, что тип данных выбранного поля подходит для быстрого поиска и индексации (например,
INTпредпочтительнееVARCHARдля ключей).
Для создания первичного ключа при создании таблицы:
CREATE TABLE users (
id SERIAL PRIMARY KEY,
username VARCHAR(50) NOT NULL
);Для добавления ключа в уже существующую таблицу:
ALTER TABLE users ADD PRIMARY KEY (id);Первичный ключ автоматически индексируется, поэтому отдельный индекс на это поле создавать не нужно.
Установка ограничений на столбцы (NOT NULL, UNIQUE и другие)
Ограничение NOT NULL исключает возможность записи значения NULL в столбец. Его следует использовать для обязательных полей, например, имени пользователя или идентификатора. Пример: name VARCHAR(100) NOT NULL.
UNIQUE требует, чтобы значения в столбце не повторялись. Это полезно для адресов электронной почты, логинов и других уникальных идентификаторов, не являющихся первичными ключами. Пример: email VARCHAR(255) UNIQUE.
PRIMARY KEY автоматически объединяет NOT NULL и UNIQUE. Он используется для определения основного идентификатора записи. Обычно применяется к столбцу id: id INT PRIMARY KEY.
DEFAULT задаёт значение по умолчанию, если оно не указано явно. Пример: created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP.
CHECK позволяет задать условие, которому должно соответствовать значение. Например: age INT CHECK (age >= 18).
FOREIGN KEY используется для ссылки на столбец в другой таблице. Он обеспечивает целостность данных. Пример: user_id INT REFERENCES users(id).
Каждое ограничение следует выбирать в зависимости от требований к данным. Лишние ограничения усложняют вставку и обновление, недостаток – увеличивает риск ошибок и дублирования.
Создание внешних ключей для связей между таблицами
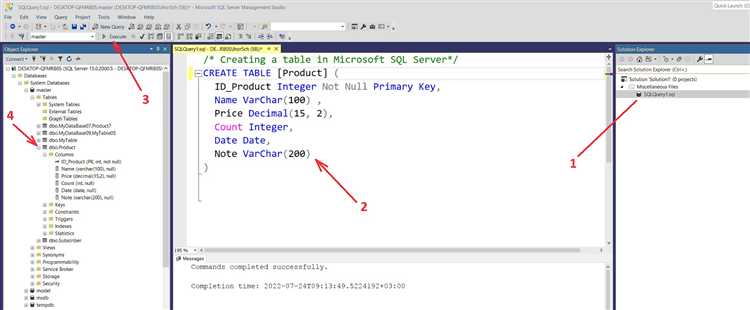
Внешний ключ обеспечивает ссылочную целостность между таблицами. Он указывает, что значения в одном столбце должны соответствовать значениям первичного ключа в другой таблице.
- Внешний ключ можно задать при создании таблицы с помощью конструкции
FOREIGN KEY. - Связь создаётся между полем текущей таблицы и полем таблицы-источника, которое обязательно должно быть уникальным.
Пример:
CREATE TABLE orders (
id INT PRIMARY KEY,
customer_id INT,
FOREIGN KEY (customer_id) REFERENCES customers(id)
);Если таблица уже создана, внешний ключ добавляется через ALTER TABLE:
ALTER TABLE orders
ADD CONSTRAINT fk_customer
FOREIGN KEY (customer_id) REFERENCES customers(id);- Для управления действиями при удалении или изменении записей используется
ON DELETEиON UPDATE.
Примеры поведения:
ON DELETE CASCADE– удаление записи в родительской таблице приведёт к удалению связанных записей.ON DELETE SET NULL– поле во внешней таблице обнуляется при удалении родительской записи.ON DELETE RESTRICT– запрет на удаление, если есть связанные записи.
Перед созданием внешнего ключа убедитесь, что:
- Типы данных совпадают.
- Поле в родительской таблице индексировано и содержит уникальные значения.
- Значения во внешнем ключе соответствуют уже существующим значениям в целевой таблице.
Использование индексов для ускорения поиска данных
Создание простого индекса:
CREATE INDEX idx_users_email ON users(email);
Такой индекс ускорит выборку по адресу электронной почты. Если используются условия по нескольким столбцам, эффективнее задать составной индекс:
CREATE INDEX idx_orders_user_date ON orders(user_id, order_date);
Составной индекс работает только при соблюдении порядка колонок. В данном случае он ускорит запросы, в которых указаны user_id или одновременно user_id и order_date. Использование только order_date не даст прироста скорости.
Для уникальных значений лучше использовать уникальные индексы:
CREATE UNIQUE INDEX idx_users_username ON users(username);
Индексы полезны, но их чрезмерное количество увеличивает нагрузку на вставку и обновление данных. Следует индексировать только те поля, которые действительно участвуют в частых запросах. Рекомендуется использовать EXPLAIN для анализа эффективности запросов и выявления, где индекс используется, а где – нет.
Автоматически создаваемые индексы есть на первичных ключах и уникальных ограничениях. При проектировании структуры таблицы это нужно учитывать, чтобы избежать дублирования.
Настройка автоинкрементирования значений в столбцах
Автоинкремент позволяет автоматически увеличивать значение в столбце при добавлении новой строки. Это удобно для создания уникальных идентификаторов. В большинстве СУБД автоинкремент применяется только к целочисленным типам данных.
В MySQL достаточно добавить модификатор AUTO_INCREMENT к целочисленному столбцу. Пример:
CREATE TABLE users (
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
name VARCHAR(100),
PRIMARY KEY (id)
);В PostgreSQL используется тип SERIAL или BIGSERIAL, либо явное создание последовательности:
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(100)
);Альтернативный способ – определить последовательность вручную:
CREATE SEQUENCE user_id_seq;
CREATE TABLE users (
id INT DEFAULT nextval('user_id_seq') PRIMARY KEY,
name VARCHAR(100)
);В SQL Server используется ключевое слово IDENTITY:
CREATE TABLE users (
id INT IDENTITY(1,1) PRIMARY KEY,
name NVARCHAR(100)
);В SQLite автоинкремент работает при использовании INTEGER PRIMARY KEY. Дополнительное указание AUTOINCREMENT меняет поведение генерации, но не требуется в большинстве случаев:
CREATE TABLE users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT
);Автоинкремент нельзя применять к нескольким столбцам одновременно. Обычно он используется только для одного ключевого идентификатора. Изменить значение счётчика можно через соответствующие механизмы СУБД, например, командой ALTER SEQUENCE в PostgreSQL или DBCC CHECKIDENT в SQL Server.
Обработка ошибок при создании таблицы в SQL
Перед выполнением запроса CREATE TABLE важно учитывать возможные ошибки, которые могут прервать выполнение скрипта или привести к некорректной структуре данных. Один из частых случаев – попытка создать таблицу с уже существующим именем. В таких ситуациях используется конструкция IF NOT EXISTS, которая предотвращает дублирование:
CREATE TABLE IF NOT EXISTS users (…);
Неверные типы данных – ещё одна причина сбоев. Например, попытка использовать несуществующий тип (вроде INTT вместо INT) приведёт к ошибке синтаксиса. Проверка типов и ограничений перед выполнением скрипта снижает риск подобных ситуаций.
Ошибки могут возникать при указании внешних ключей, если таблица, на которую ссылается внешний ключ, не существует или не содержит нужного столбца. Для избежания таких проблем порядок создания таблиц должен учитывать зависимости. Сначала создаются родительские таблицы, затем – дочерние с внешними ключами.
Также следует учитывать, что имя таблицы и имена столбцов должны соответствовать правилам конкретной СУБД: например, в PostgreSQL чувствительность к регистру и ограничение на длину имени могут привести к неожиданным ошибкам. В случае необходимости стоит использовать кавычки для точного указания имени:
CREATE TABLE «UserData» (…);
При автоматическом выполнении скриптов полезно оборачивать операции создания таблиц в блоки обработки исключений, если это поддерживается СУБД (например, BEGIN…EXCEPTION…END в PL/pgSQL для PostgreSQL). Это позволяет перехватывать ошибки и продолжать выполнение других операций без прерывания.
Пример создания таблицы с несколькими столбцами и связями
Рассмотрим структуру базы данных для учёта заказов. Потребуются три таблицы: customers, orders и products. Каждая из них содержит набор столбцов с определёнными типами данных и логическими связями.
Создание таблицы клиентов:
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(100) NOT NULL,
email VARCHAR(100) UNIQUE,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);Создание таблицы товаров:
CREATE TABLE products (
product_id INT PRIMARY KEY,
name VARCHAR(100) NOT NULL,
price DECIMAL(10,2) CHECK (price >= 0)
);Создание таблицы заказов с внешними ключами:
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
product_id INT,
quantity INT CHECK (quantity > 0),
order_date DATE NOT NULL,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id),
FOREIGN KEY (product_id) REFERENCES products(product_id)
);Для исключения дублирования заказов можно добавить составной уникальный индекс:
CREATE UNIQUE INDEX idx_customer_product ON orders(customer_id, product_id, order_date);Эта структура позволяет связать заказ с конкретным клиентом и товаром. Проверки на уровне базы данных исключают ввод некорректных значений, а внешние ключи обеспечивают согласованность данных между таблицами.