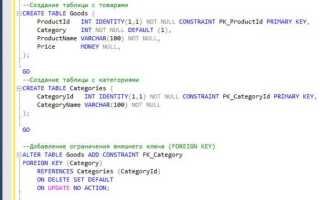
Для создания таблицы в SQL используется команда CREATE TABLE, которая позволяет задать структуру данных для хранения информации. Важно правильно определить типы данных для каждого столбца и задать необходимые ограничения, чтобы обеспечить целостность и корректность данных. Рассмотрим, как на практике создать таблицу с различными типами данных и параметрами.
Основная форма запроса выглядит так: CREATE TABLE имя_таблицы (столбец1 тип_данных [ограничения], столбец2 тип_данных [ограничения], ...);. Важно правильно выбрать типы данных, так как они влияют на производительность и точность хранения. Например, для числовых значений лучше использовать INT или DECIMAL, а для строк – VARCHAR или TEXT, в зависимости от длины данных.
Одним из важных аспектов является использование ограничений, таких как PRIMARY KEY, NOT NULL, FOREIGN KEY, которые помогают организовать связи между таблицами и предотвратить введение некорректных данных. Например, столбец с ограничением NOT NULL не позволит вставить пустое значение, а PRIMARY KEY гарантирует уникальность значений в этом столбце.
Не забывайте о нормализации базы данных, которая помогает избежать избыточности и улучшить производительность запросов. Разделение данных на несколько таблиц и правильная настройка связей между ними делает структуру более логичной и упрощает управление данными в будущем.
Основы команды CREATE TABLE для создания таблицы
Команда CREATE TABLE используется для создания новой таблицы в базе данных. Минимальный синтаксис включает имя таблицы и список столбцов с указанием их типов данных. Каждый столбец должен быть описан с максимальной точностью, включая тип, ограничения и правила хранения.
Пример базового запроса:
CREATE TABLE сотрудники (id INT PRIMARY KEY, имя VARCHAR(100) NOT NULL, должность VARCHAR(50), зарплата DECIMAL(10,2));
Тип INT используется для хранения целых чисел. VARCHAR(n) подходит для строк длиной до n символов. DECIMAL(p,s) хранит точные числовые значения, где p – общее количество цифр, а s – количество цифр после запятой.
Ключ PRIMARY KEY задаёт уникальность значений в столбце. Ограничение NOT NULL запрещает хранение пустых значений. Если необходимо автоматическое увеличение чисел, можно использовать AUTOINCREMENT (SQLite) или AUTO_INCREMENT (MySQL), либо SERIAL (PostgreSQL).
Учитывайте совместимость типов данных с конкретной СУБД. Например, в MySQL допустим тип TINYINT, тогда как в PostgreSQL – SMALLINT или INTEGER. Также различаются способы задания значений по умолчанию и синтаксис ограничения внешних ключей.
Избегайте дублирования названий столбцов и не используйте зарезервированные слова в качестве имён. Всегда указывайте ограничения целостности на этапе создания таблицы, чтобы обеспечить стабильную структуру данных и минимизировать ошибки в будущем.
Выбор типа данных для столбцов таблицы
Правильный выбор типа данных для столбцов таблицы критичен для производительности базы данных и предотвращения ошибок при хранении и обработке данных.
При создании таблицы важно учитывать не только размер данных, но и особенности их использования. Рассмотрим основные категории типов данных и их применение.
- Целочисленные типы: Используются для хранения целых чисел. Выбор конкретного типа зависит от ожидаемого диапазона значений. Например, для чисел в пределах от -32,768 до 32,767 подойдет
SMALLINT, а для значений от 0 до 4,294,967,295 –INT UNSIGNED. - Числовые типы с плавающей точкой: Применяются для хранения вещественных чисел. Типы
FLOATиDOUBLEподходят для вычислений с неограниченной точностью, но для точных вычислений, например, в финансовых приложениях, лучше использоватьDECIMALилиNUMERIC, поскольку они обеспечивают фиксированную точность. - Строковые типы:
CHARиVARCHARчасто используются для хранения текстовых данных.CHARфиксированной длины эффективно работает с короткими строками, но может занимать лишнюю память, если длина строк варьируется.VARCHAR– более гибкий вариант для строк переменной длины, экономящий место. - Дата и время: Для хранения временных значений лучше использовать
DATE,TIME,DATETIMEилиTIMESTAMP, в зависимости от необходимости учитывать только дату или полный временной штамп.DATEзанимает меньше памяти, чемDATETIME, но не включает время. - Логические значения: Для хранения булевых данных используется тип
BOOLEAN. Это тип, который хранит значенияTRUEилиFALSE, что особенно полезно для флагов и состояний. - Бинарные данные: Типы
BLOBиVARBINARYпредназначены для хранения двоичных данных, таких как изображения или документы.BLOBлучше подходит для хранения больших файлов, так как его размер может варьироваться.
Для повышения производительности и уменьшения объема данных важно выбирать типы с учетом специфики данных. Например, использование INT для хранения идентификаторов пользователей, которые всегда положительные и не превышают миллиарда, оптимально по производительности и памяти. Для строковых данных, которые не превышают 255 символов, можно использовать VARCHAR(255), а не TEXT, чтобы избежать излишнего расхода памяти.
Также важно учитывать возможные изменения в будущем. Например, если предполагается, что диапазон чисел может со временем увеличиться, стоит выбрать тип с большими возможностями (например, BIGINT вместо INT), чтобы избежать необходимости в реорганизации таблицы.
Как задать ограничения на значения столбцов (NOT NULL, UNIQUE и другие)
Ограничения в SQL позволяют контролировать данные, которые могут быть вставлены в таблицу, обеспечивая их соответствие определённым требованиям. Для этого используются ключевые слова, такие как NOT NULL, UNIQUE, CHECK, DEFAULT и другие.
Один из самых распространённых типов ограничений – это NOT NULL, которое гарантирует, что столбец не может содержать пустые значения. Это ограничение указывается при создании столбца и может быть добавлено даже позже с помощью команды ALTER TABLE. Пример:
CREATE TABLE employees ( id INT NOT NULL, name VARCHAR(100) NOT NULL, salary DECIMAL(10, 2) NOT NULL );
Ограничение UNIQUE заставляет значения столбца быть уникальными по отношению к другим записям в таблице. Это ограничение полезно для данных, которые не должны повторяться, например, для email-адресов пользователей или номеров телефонов. Пример использования:
CREATE TABLE employees ( id INT PRIMARY KEY, email VARCHAR(100) UNIQUE );
Если столбец имеет ограничение PRIMARY KEY, то значения в этом столбце автоматически должны быть уникальными и не могут быть NULL, так как они идентифицируют каждую строку в таблице.
Ограничение CHECK позволяет задать условия, которым должны удовлетворять значения в столбце. Например, можно ограничить диапазон значений для зарплаты или возраста. Пример использования:
CREATE TABLE employees ( id INT PRIMARY KEY, age INT CHECK (age >= 18 AND age <= 65) );
Кроме того, можно использовать ограничение DEFAULT, чтобы задать значение по умолчанию для столбца, если при вставке данных не указано значение для этого столбца. Пример:
CREATE TABLE employees ( id INT PRIMARY KEY, name VARCHAR(100), hire_date DATE DEFAULT CURRENT_DATE );
С помощью FOREIGN KEY можно установить ссылочную целостность, ограничив значения столбца такими, которые присутствуют в другом столбце другой таблицы. Пример:
CREATE TABLE departments ( id INT PRIMARY KEY, name VARCHAR(100) NOT NULL ); CREATE TABLE employees ( id INT PRIMARY KEY, name VARCHAR(100), department_id INT, FOREIGN KEY (department_id) REFERENCES departments(id) );
Каждое из этих ограничений помогает создать более стабильную и безопасную структуру базы данных, предотвращая ввод некорректных или нежелательных данных.
Определение первичного ключа для таблицы
Для определения первичного ключа в SQL используется ключевое слово PRIMARY KEY. Первичный ключ можно задать как на этапе создания таблицы, так и позже, добавив его с помощью команды ALTER TABLE.
Пример создания таблицы с первичным ключом:
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
hire_date DATE
);В данном примере столбец employee_id является первичным ключом. Он уникален для каждого сотрудника, что позволяет точно идентифицировать каждую запись.
Если нужно использовать несколько столбцов в качестве первичного ключа, их можно указать через запятую. Такой ключ называется составным. Пример создания составного первичного ключа:
CREATE TABLE orders (
order_id INT,
product_id INT,
quantity INT,
PRIMARY KEY (order_id, product_id)
);Здесь первичный ключ состоит из двух столбцов: order_id и product_id, что позволяет уникально идентифицировать каждую строку в таблице по сочетанию этих двух значений.
Первичный ключ не может содержать NULL значения, так как каждый столбец должен быть уникальным и идентифицировать конкретную запись. Если в столбце первичного ключа появляется NULL, это нарушает правила целостности базы данных.
Важно также помнить, что создание первичного ключа на часто используемых в запросах столбцах может улучшить производительность, так как индексы, связанные с этим ключом, ускоряют поиск и сортировку данных.
Добавление внешних ключей для связи с другими таблицами
Внешние ключи (foreign keys) используются для создания связей между таблицами в базе данных. Они обеспечивают целостность данных, гарантируя, что значения в одной таблице будут соответствовать значениям в другой. Для добавления внешнего ключа в SQL используется ограничение FOREIGN KEY.
Чтобы добавить внешние ключи при создании таблицы, необходимо указать поле, которое будет ссылаться на первичный ключ другой таблицы. Например, если у вас есть таблица orders, которая должна ссылаться на таблицу customers, то внешний ключ будет ссылаться на идентификатор клиента из таблицы customers:
CREATE TABLE orders ( order_id INT PRIMARY KEY, order_date DATE, customer_id INT, FOREIGN KEY (customer_id) REFERENCES customers(customer_id) );
В данном примере customer_id является внешним ключом, который ссылается на поле customer_id в таблице customers. Это гарантирует, что каждый заказ будет связан с существующим клиентом.
Кроме того, важно учитывать поведение внешних ключей при изменении или удалении записей в родительской таблице. Для этого можно задать действия, которые будут выполняться при удалении или обновлении строк в родительской таблице, например, ON DELETE CASCADE или ON UPDATE RESTRICT:
CREATE TABLE orders ( order_id INT PRIMARY KEY, order_date DATE, customer_id INT, FOREIGN KEY (customer_id) REFERENCES customers(customer_id) ON DELETE CASCADE ON UPDATE RESTRICT );
Здесь ON DELETE CASCADE означает, что при удалении записи из таблицы customers все связанные заказы будут автоматически удалены, а ON UPDATE RESTRICT ограничивает обновление customer_id в таблице customers, если на этот столбец есть ссылки.
Важно: если внешний ключ не имеет соответствующего значения в родительской таблице, операция вставки будет отклонена. Это предотвращает создание «висячих» записей, которые ссылаются на несуществующие данные.
Использование внешних ключей помогает поддерживать целостность базы данных и упрощает управление связями между таблицами, предотвращая ошибки, связанные с неконсистентными данными.
Использование автоинкремента для числовых столбцов
Для создания автоинкрементного столбца необходимо указать это свойство в момент определения таблицы. Например, в MySQL это делается с помощью ключевого слова AUTO_INCREMENT. Тип данных для автоинкрементируемого столбца, как правило, INT или BIGINT, в зависимости от предполагаемого объема данных.
Пример создания таблицы с автоинкрементом в MySQL:
CREATE TABLE users (
id INT AUTO_INCREMENT,
name VARCHAR(100),
email VARCHAR(100),
PRIMARY KEY (id)
);В данном примере столбец id будет автоматически увеличиваться при каждом добавлении новой строки. Значение начнется с 1 и будет увеличиваться на 1 с каждым новым добавлением записи.
Важно учитывать, что автоинкремент работает только для столбцов, которые являются уникальными или могут быть использованы в качестве первичного ключа. Также, стоит помнить, что в некоторых СУБД возможны различные параметры автоинкремента, такие как начальное значение или шаг увеличения. Например, в MySQL можно настроить начальное значение с помощью команды:
ALTER TABLE users AUTO_INCREMENT = 100;Для PostgreSQL аналогичный механизм называется SERIAL. В отличие от MySQL, где автоинкремент задается прямо в определении столбца, в PostgreSQL SERIAL является типом данных, который автоматически создает последовательность чисел. Пример:
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100)
);В PostgreSQL последовательности используются для управления значениями автоинкремента, и можно настраивать их параметры через команду ALTER SEQUENCE.
В SQL Server автоинкремент обозначается ключевым словом IDENTITY. Для указания шага и начального значения используется следующая форма:
CREATE TABLE users (
id INT IDENTITY(1,1),
name VARCHAR(100),
email VARCHAR(100),
PRIMARY KEY (id)
);Здесь IDENTITY(1,1) указывает, что первое значение будет равно 1, а шаг увеличения составит 1.
Использование автоинкремента значительно упрощает работу с таблицами, где необходимо уникально идентифицировать строки. Однако следует помнить, что автоинкрементируемые столбцы не могут принимать NULL-значения, и в некоторых случаях, например, при восстановлении данных или при миграции между базами данных, могут возникнуть проблемы с согласованностью последовательности чисел.
Определение индексов для ускорения поиска в таблице
Типы индексов: В SQL существуют несколько видов индексов, каждый из которых подходит для определённых задач. Наиболее популярными являются:
- Одинарный индекс – индексируется один столбец таблицы. Используется, когда запросы часто обращаются к конкретному столбцу (например, по ID или имени).
- Составной индекс – индексируется несколько столбцов. Это полезно для запросов, в которых используются несколько полей для фильтрации или сортировки данных.
- Уникальный индекс – обеспечивает уникальность значений в столбце или наборе столбцов. Его использование снижает вероятность ошибок, связанных с дублированием данных.
- Полнотекстовый индекс – используется для ускорения поиска по текстовым данным, например, при выполнении поиска по ключевым словам в больших текстовых полях.
Рекомендации по определению индексов:
1. Определите часто используемые столбцы для поиска: Если в запросах часто встречаются фильтрация или сортировка по определённым столбцам, имеет смысл создать индекс для этих столбцов. Например, если часто выполняются запросы на выборку данных по столбцу "email", индекс по этому столбцу значительно ускорит работу с таблицей.
2. Не индексируйте каждый столбец: Индексы занимают место на диске, и их обновление при вставке, обновлении или удалении данных может замедлить эти операции. Лучше всего создавать индексы только для столбцов, которые действительно активно используются в запросах.
3. Используйте составные индексы с умом: Индексы, состоящие из нескольких столбцов, ускоряют выполнение запросов, если фильтрация данных происходит по этим столбцам одновременно. Однако составные индексы не всегда эффективны для отдельных столбцов. Например, если запрос часто использует только первый столбец из составного индекса, остальные столбцы будут игнорироваться, и индекс может не принести ожидаемой выгоды.
4. Будьте осторожны с уникальными индексами: Хотя уникальные индексы обеспечивают целостность данных, их использование может замедлить операции вставки и обновления, так как системе необходимо проверять уникальность каждого значения при внесении изменений.
Пример создания индекса:
Для создания индекса на столбце "email" в таблице "users" используется следующий запрос:
CREATE INDEX idx_email ON users (email);Если нужно создать составной индекс на столбцы "first_name" и "last_name", запрос будет выглядеть так:
CREATE INDEX idx_name ON users (first_name, last_name);Для уникального индекса на столбце "email" можно использовать следующий запрос:
CREATE UNIQUE INDEX idx_unique_email ON users (email);Каждый индекс требует времени на создание, но при правильном подходе они могут существенно повысить производительность работы с данными.
Пример полного запроса для создания таблицы в SQL
Пример полного запроса для создания таблицы в SQL включает все необходимые компоненты для определения структуры базы данных. Вот пример такого запроса:
CREATE TABLE employees ( employee_id INT PRIMARY KEY, first_name VARCHAR(50) NOT NULL, last_name VARCHAR(50) NOT NULL, hire_date DATE NOT NULL, salary DECIMAL(10, 2), department_id INT, FOREIGN KEY (department_id) REFERENCES departments(department_id) );
В этом примере создается таблица employees, которая хранит информацию о сотрудниках. Рассмотрим ключевые части запроса:
- employee_id INT PRIMARY KEY – колонка для идентификатора сотрудника, который будет уникальным и использоваться как первичный ключ таблицы.
- first_name VARCHAR(50) NOT NULL – строковое поле для имени сотрудника. Ограничение
NOT NULLгарантирует, что имя не может быть пустым. - last_name VARCHAR(50) NOT NULL – строковое поле для фамилии сотрудника. Также не может быть пустым.
- hire_date DATE NOT NULL – дата принятия на работу. Это обязательное поле, которое не может быть пустым.
- salary DECIMAL(10, 2) – поле для хранения зарплаты сотрудника с точностью до двух знаков после запятой. Максимальная длина числа составляет 10 цифр, включая два знака после запятой.
- department_id INT – идентификатор отдела, к которому принадлежит сотрудник.
- FOREIGN KEY (department_id) REFERENCES departments(department_id) – внешний ключ, который связывает поле
department_idс полемdepartment_idв таблицеdepartments. Это обеспечивает ссылочную целостность данных.
Такой запрос создаст таблицу, где можно хранить информацию о сотрудниках и их зарплатах, а также связывать сотрудников с определенными отделами. Важно соблюдать правильный порядок определения колонок, чтобы запрос был корректным и работал эффективно.