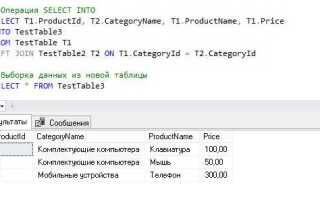
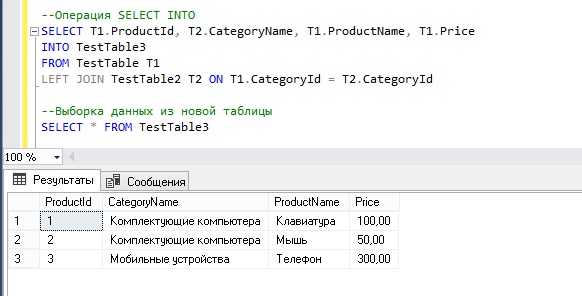
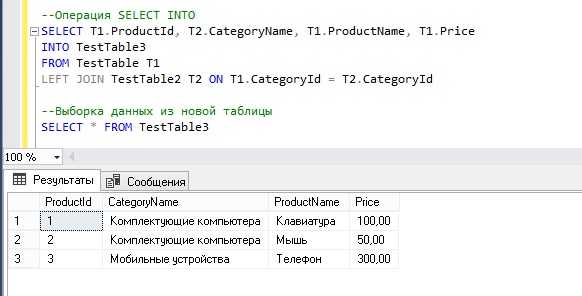
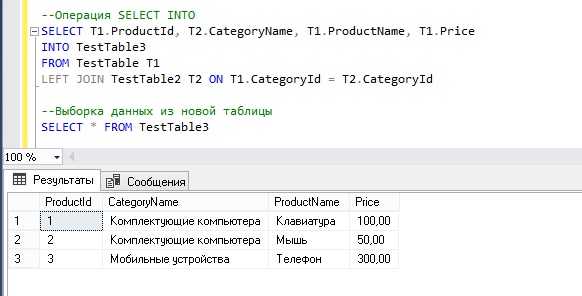
Создание таблицы в SQL – это одна из основных операций при работе с базами данных. Знание структуры и синтаксиса команды CREATE TABLE позволяет эффективно работать с данными и проектировать схемы хранения информации. В этом руководстве мы рассмотрим пошаговый процесс создания таблицы в SQL, уделяя внимание важным аспектам, которые помогут избежать распространённых ошибок.
Первым шагом в создании таблицы является выбор подходящего типа данных для каждого столбца. Важно учитывать требования к объему данных, их формату и особенностям работы с ними. Например, для хранения текстовой информации используется тип VARCHAR, а для числовых значений – INT или DECIMAL. Неверно выбранный тип данных может привести к излишнему расходу памяти или потерям информации при вводе данных.
После определения типов данных для каждого столбца, следующим шагом будет указание ограничений. Это могут быть PRIMARY KEY для уникальных идентификаторов, NOT NULL для обязательных полей, а также FOREIGN KEY для обеспечения связности таблиц. Такие ограничения помогают обеспечить целостность данных и избежать их несоответствия.
Следует также обратить внимание на индексы, которые могут значительно ускорить поиск и сортировку данных в таблице. Индексы создаются с помощью команды CREATE INDEX и используются для оптимизации запросов. Однако важно понимать, что излишнее количество индексов может замедлить операции вставки и обновления данных, поэтому стоит подходить к их использованию с умом.
Выбор подходящего типа данных для столбцов
Неверно выбранный тип данных может привести к потере производительности, некорректному хранению информации и ошибкам при обработке запросов. Прежде чем создавать таблицу, проанализируйте, какие данные будут храниться в каждом столбце, и выберите тип с учетом объема, точности и предполагаемой нагрузки.
- Целочисленные значения: Используйте
SMALLINT,INTилиBIGINTв зависимости от диапазона. Например, если значение никогда не превысит 32 767, достаточноSMALLINT(2 байта). Для больших чисел используйтеBIGINT(8 байт). - Денежные значения: Избегайте
FLOATиREALиз-за возможной потери точности. Предпочтительнее использоватьDECIMAL(p, s)илиNUMERIC(p, s), гдеp– общее количество цифр,s– количество цифр после запятой. - Дата и время: Для фиксированных точек времени используйте
DATETIMEилиTIMESTAMP. Если нужно только дата без времени –DATE. Для хранения интервалов –INTERVAL, если поддерживается. - Текст: Короткие строки –
VARCHAR(n), гдеnне превышает реальную длину значений. Фиксированную длину (например, коды стран) –CHAR(n). Длинные тексты –TEXT, но избегайте частого доступа к ним в условиях WHERE и JOIN. - Булевы значения: Используйте
BOOLEAN, если поддерживается, илиTINYINTс ограничением значений (0, 1). - Идентификаторы: Для автоинкремента –
SERIALилиIDENTITY, в зависимости от СУБД. Для уникальных значений без последовательности –UUID.
Учитывайте особенности конкретной СУБД. Например, в PostgreSQL VARCHAR и TEXT не различаются по производительности, а в MySQL – да. Не задавайте избыточные размеры строк и чисел: они не увеличивают емкость, но могут снизить эффективность хранения и сортировки.
Определение первичного ключа для таблицы
Основные правила:
1. Первичный ключ должен состоять из одного или нескольких столбцов, которые вместе обеспечивают уникальность строк в таблице.
2. Каждый столбец первичного ключа должен содержать только уникальные значения и не может быть пустым.
3. Если используется несколько столбцов для создания первичного ключа, это называется составным ключом. Например, можно использовать сочетание столбцов «ID_заказа» и «ID_продукта», чтобы гарантировать уникальность каждой строки в таблице заказов.
Как указать первичный ключ при создании таблицы:
Для добавления первичного ключа в SQL-выражение CREATE TABLE, необходимо использовать конструкцию PRIMARY KEY. Вот пример:
CREATE TABLE Заказы ( ID_заказа INT, Дата DATE, ID_продукта INT, Количество INT, PRIMARY KEY (ID_заказа, ID_продукта) );
В данном примере первичный ключ состоит из двух столбцов: «ID_заказа» и «ID_продукта». Это позволяет уникально идентифицировать каждую строку в таблице заказов, даже если в одном заказе могут быть несколько продуктов.
Использование автоинкремента:
Если столбец, который вы выбираете для первичного ключа, должен автоматически увеличиваться с каждой новой записью, используется атрибут AUTO_INCREMENT (для MySQL) или SERIAL (для PostgreSQL). Это особенно полезно для числовых идентификаторов:
CREATE TABLE Пользователи ( ID INT AUTO_INCREMENT, Имя VARCHAR(50), Электронная_почта VARCHAR(100), PRIMARY KEY (ID) );
В этом случае столбец «ID» будет автоматически увеличиваться с каждой новой записью, гарантируя уникальность значений.
Что происходит при попытке вставить дублирующиеся значения в первичный ключ:
Если при попытке вставить строку в таблицу значения первичного ключа уже существуют, SQL-система выдаст ошибку, предотвращая вставку дубликата. Это поддерживает целостность данных и исключает возможные конфликты.
Важно помнить, что первичный ключ играет ключевую роль в структуре базы данных, влияя на производительность запросов и поддержку целостности данных. Поэтому его выбор должен быть осознанным и учитывать специфику используемой системы управления базами данных (СУБД).
Установка ограничений на столбцы таблицы
Ограничения на столбцы в SQL играют важную роль в обеспечении целостности данных и предотвращении ошибок при их вводе. Они помогают контролировать допустимые значения в столбцах и обеспечивают соблюдение бизнес-правил. В SQL можно использовать несколько типов ограничений для столбцов: NOT NULL, UNIQUE, CHECK, DEFAULT, PRIMARY KEY и FOREIGN KEY.
NOT NULL – это ограничение, которое предотвращает вставку пустых значений в столбец. Оно используется, когда для столбца обязательна информация. Например, если столбец «email» не может быть пустым, используйте:
CREATE TABLE users ( email VARCHAR(255) NOT NULL );
UNIQUE ограничение гарантирует, что все значения в столбце будут уникальными. Это полезно, когда необходимо избежать дублирования данных, например, для столбца «id» пользователя:
CREATE TABLE users ( user_id INT UNIQUE );
CHECK ограничение используется для проверки значений столбца по заданному условию. Например, можно установить, что возраст пользователя не может быть меньше 18 лет:
CREATE TABLE users ( age INT CHECK (age >= 18) );
DEFAULT позволяет задать значение по умолчанию для столбца, если при вставке данных оно не указано. Например, можно установить значение по умолчанию для столбца «status» как «active»:
CREATE TABLE users ( status VARCHAR(20) DEFAULT 'active' );
PRIMARY KEY – это комбинация ограничений UNIQUE и NOT NULL. Он идентифицирует уникальные строки в таблице. Каждый столбец, который является частью первичного ключа, не может содержать пустых значений и должен быть уникальным:
CREATE TABLE users ( user_id INT PRIMARY KEY );
FOREIGN KEY ограничение используется для связи одной таблицы с другой, обеспечивая ссылочную целостность данных. Оно гарантирует, что значение в столбце, относящемся к внешнему ключу, будет соответствовать значению в столбце, на который ссылается этот внешний ключ:
CREATE TABLE orders ( user_id INT, FOREIGN KEY (user_id) REFERENCES users(user_id) );
Каждое из этих ограничений играет важную роль в поддержке качества данных. При проектировании таблицы важно правильно выбирать ограничения в зависимости от требований к данным, чтобы минимизировать возможность ошибок и повысить производительность запросов.
Создание внешних ключей для связей между таблицами
Внешние ключи (foreign keys) используются для установления связей между таблицами базы данных. Они обеспечивают целостность данных, ограничивая значения в одном столбце только теми, которые присутствуют в другом столбце другой таблицы. Внешний ключ устанавливается на поле в дочерней таблице и ссылается на уникальное или первичное поле родительской таблицы.
Пример создания внешнего ключа в SQL выглядит следующим образом:
CREATE TABLE Orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES Customers(customer_id)
);В данном примере поле customer_id в таблице Orders ссылается на поле customer_id в таблице Customers. Это означает, что значения в столбце customer_id таблицы Orders могут быть только теми, которые уже существуют в столбце customer_id таблицы Customers.
Создание внешних ключей требует внимательности к следующим аспектам:
- Типы данных: Типы данных на столбцах, участвующих в внешнем ключе, должны совпадать. Например, если
customer_idв таблицеCustomersимеет типINT, то и в таблицеOrdersсоответствующий столбец тоже должен быть типаINT. - Индекс на внешнем ключе: Внешний ключ автоматически создает индекс на столбце дочерней таблицы. Этот индекс ускоряет операции поиска и связи.
- Ограничения целостности: Внешний ключ предотвращает вставку или обновление значений в дочерней таблице, которые не существуют в родительской. Также можно настроить каскадное удаление или обновление с помощью параметров
ON DELETE CASCADEилиON UPDATE CASCADE.
Пример с каскадным удалением:
CREATE TABLE Orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
FOREIGN KEY (customer_id)
REFERENCES Customers(customer_id)
ON DELETE CASCADE
);Этот код означает, что при удалении записи из таблицы Customers, все связанные заказы в таблице Orders будут удалены автоматически.
Важно помнить, что внешний ключ можно добавить и после создания таблицы с помощью команды ALTER TABLE:
ALTER TABLE Orders
ADD CONSTRAINT fk_customer
FOREIGN KEY (customer_id)
REFERENCES Customers(customer_id);
Внешние ключи – это мощный инструмент для поддержания целостности и корректности данных в реляционных базах данных. Правильное использование внешних ключей позволяет избежать многих логических ошибок, особенно в крупных и сложных системах.
Использование индексов для улучшения производительности запросов
Индексы в SQL позволяют ускорить выполнение запросов, минимизируя время поиска данных в таблице. Они представляют собой структуру данных, которая обеспечивает быстрый доступ к строкам таблицы, аналогично указателю в книге. Без индексов СУБД должна сканировать всю таблицу, что значительно замедляет выполнение запросов, особенно при работе с большими объемами данных.
Основные типы индексов включают:
- B-деревья – наиболее распространенный тип индекса, используемый для оптимизации поиска по значениям в столбцах. Подходит для равенства и диапазонных запросов.
- Хэш-индексы – оптимальны для запросов, использующих операторы равенства. Они обеспечивают мгновенный доступ к данным по хешированным значениям.
- Индексы на основе полнотекстового поиска – используются для поиска текстовой информации внутри больших текстовых полей.
Для улучшения производительности важно правильно выбирать, какие столбцы индексировать. Наиболее подходящие кандидаты – это столбцы, которые часто используются в условиях WHERE, JOIN или ORDER BY. Индексы значительно ускоряют запросы на выборку, но могут замедлить операции вставки, обновления и удаления, поскольку каждая такая операция требует обновления индекса.
Особенно важно индексировать столбцы, которые участвуют в фильтрации запросов. Например, если часто выполняются запросы с условиями типа `WHERE status = ‘active’`, то индекс на столбце `status` позволит существенно ускорить поиск строк с данным значением.
В случае использования многоколоночных индексов (composite index) следует учитывать порядок столбцов в индексе. Столбцы, которые чаще встречаются в запросах в первом месте, должны располагаться первыми в индексе. Например, если запросы часто используют фильтрацию по столбцам `country` и `age`, правильный порядок в индексе будет `country, age`.
Чтобы избежать излишней нагрузки на СУБД, важно не создавать избыточные индексы. Создание индексов на каждом столбце может привести к снижению производительности при добавлении или обновлении данных. Оптимальный выбор – создание индексов только на тех столбцах, которые действительно требуются для ускорения наиболее частых операций.
Также стоит помнить о тех случаях, когда индексы могут не дать значительного прироста производительности. Это может происходить при использовании SELECT-запросов, которые возвращают большое количество строк (например, с ограничениями на выборку или агрегатными функциями), поскольку даже с индексом СУБД всё равно может потребуется обработать множество строк.
В целом, индексы – мощный инструмент для оптимизации запросов, но их использование должно быть сбалансированным. Каждый индекс следует создавать с учетом конкретных запросов, которые часто выполняются, а также характера обновлений данных в таблице.
Проверка структуры таблицы после её создания

После создания таблицы в SQL необходимо убедиться, что её структура соответствует вашим ожиданиям и требованиям. Для этого можно использовать несколько методов проверки.
- Использование команды DESCRIBE
DESCRIBE имя_таблицы;
Это даст подробную информацию о каждой колонке, включая её тип данных, NULL/NOT NULL ограничения, а также возможные индексы.
- Использование INFORMATION_SCHEMA
Для более детализированной информации можно обратиться к системной таблице INFORMATION_SCHEMA. В частности, запрос к таблице COLUMNS позволит получить всю информацию о колонках таблицы, включая их типы, дефолтные значения и другие параметры:
SELECT COLUMN_NAME, DATA_TYPE, IS_NULLABLE, COLUMN_DEFAULT FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_NAME = 'имя_таблицы';
Это позволяет получить полный список колонок с их характеристиками.
- Проверка ограничений
После создания таблицы важно проверить, что ограничения (например, PRIMARY KEY, UNIQUE, FOREIGN KEY) были правильно установлены. Для этого можно использовать запросы к системным таблицам, например, в MySQL:
SHOW CREATE TABLE имя_таблицы;
Этот запрос вернёт полный SQL код для создания таблицы, включая ограничения и индексы.
- Проверка индексов
Чтобы убедиться, что таблица имеет необходимые индексы, можно использовать команду SHOW INDEXES. Эта команда покажет все индексы, установленные в таблице:
SHOW INDEXES FROM имя_таблицы;
Индексы могут существенно повлиять на производительность запросов, особенно при работе с большими объёмами данных.
- Использование графических интерфейсов
Если вы используете графические интерфейсы для работы с базами данных (например, phpMyAdmin, pgAdmin), можно легко просматривать структуру таблицы с помощью визуальных инструментов. Это позволяет убедиться в корректности типов данных, ограничений и связей между таблицами.
Регулярная проверка структуры таблицы помогает поддерживать целостность данных и предотвращать ошибки при дальнейшей работе с базой данных.
Вопрос-ответ:
Что такое типы данных в SQL и как они влияют на создание таблицы?
Типы данных в SQL определяют, какие значения могут храниться в столбцах таблицы. Например, тип `INT` используется для хранения целых чисел, `VARCHAR` — для строк переменной длины, а `DATE` — для хранения дат. Каждый тип данных влияет на размер памяти, который будет использован для хранения данных, и на допустимые операции с этими данными. Выбирая правильный тип данных, можно гарантировать корректность работы с таблицей и экономию ресурсов.