Создание витрины данных SQL – это процесс, который требует точности и продуманности, чтобы данные могли быть использованы для анализа с максимальной эффективностью. Витрина данных представляет собой структурированный набор данных, который интегрирует информацию из различных источников, обеспечивая удобный доступ для аналитиков и бизнес-пользователей. Основная цель витрины – упростить извлечение нужной информации и оптимизировать выполнение запросов для аналитических нужд.
Для эффективного построения витрины данных необходимо учитывать несколько ключевых аспектов. Во-первых, важно правильно выбрать источники данных, которые будут интегрированы в систему. Если данные поступают из разных таблиц и баз, стоит заранее продумать, как их объединить, используя такие операции, как JOIN или UNION. Рекомендуется создавать представления (views), которые будут агрегировать данные и обеспечивать быстрый доступ к ним.
Второй важный шаг – это оптимизация производительности запросов. Если витрина будет обрабатывать большие объемы данных, использование индексов и материализованных представлений значительно ускорит время отклика системы. Например, создание индексов на поля, по которым часто выполняются фильтрации и сортировки, поможет ускорить выполнение запросов. Важно помнить, что создание индексов должно быть сбалансированным процессом, так как чрезмерное количество индексов может замедлить процессы вставки и обновления данных.
Кроме того, для создания эффективной витрины данных важно правильно организовать хранение информации. Разделение данных на логические блоки и использование архивирования старых данных позволят снизить нагрузку на систему, не теряя при этом важной информации. Один из популярных подходов – это использование принципа ETL (Extract, Transform, Load), который помогает обеспечить качественную подготовку данных для анализа, преобразуя их в нужный формат перед загрузкой в витрину.
Не забывайте, что витрина данных должна быть не только эффективной с точки зрения производительности, но и гибкой для изменения. Структура данных и бизнес-логика могут изменяться со временем, поэтому система должна позволять легко адаптироваться к этим изменениям, не затрудняя пользователей в доступе к актуальной информации.
Как создать витрину данных SQL для анализа
Первая задача – это проектирование архитектуры данных. Важно четко определить, какие данные будут поступать в витрину, а какие из них следует агрегировать или изменять. Рекомендуется использовать метод ETL (Extract, Transform, Load), где данные извлекаются из исходных систем, проходят преобразование и затем загружаются в витрину для дальнейшего использования.
Оптимизация запросов – ключевая задача при создании витрины данных. Для этого необходимо использовать индексы для ускорения выборки часто используемых данных и придерживаться принципа минимизации вложенных запросов. Также важно учитывать, что слишком сложные соединения таблиц (JOIN) могут существенно снизить скорость выполнения запросов.
Агрегация данных должна происходить на уровне SQL-запросов или в процессе загрузки данных. Это позволяет уменьшить объем данных, с которыми работают конечные пользователи. Например, для анализа продаж можно заранее агрегировать данные по дням, месяцам или кварталам, что значительно ускоряет запросы для анализа динамики.
Для улучшения производительности можно использовать материализованные представления, которые хранят результаты запросов в базе данных. Это позволяет значительно ускорить выполнение сложных запросов, поскольку результат не вычисляется каждый раз заново, а извлекается из предварительно сохраненной версии.
Очень важным элементом является выбор оптимальных типов данных для хранения информации. Например, для числовых данных лучше использовать типы данных с фиксированной точностью, такие как DECIMAL, вместо стандартных FLOAT или DOUBLE, чтобы избежать погрешностей в расчетах.
Не стоит забывать о регулярной интеграции данных. Витрина данных должна быть динамичной и обновляться по мере поступления новых данных из источников. Это можно настроить с помощью планировщика задач или триггеров, которые будут автоматически запускать процессы загрузки и обновления.
Наконец, следует помнить о безопасности данных. Для доступа к витрине данных необходимо реализовать четкую систему прав, чтобы ограничить доступ к чувствительным данным. Использование ролей и пользователей с ограниченными правами на чтение и запись поможет минимизировать риски утечек данных.
Выбор структуры данных для витрины: какую модель использовать?
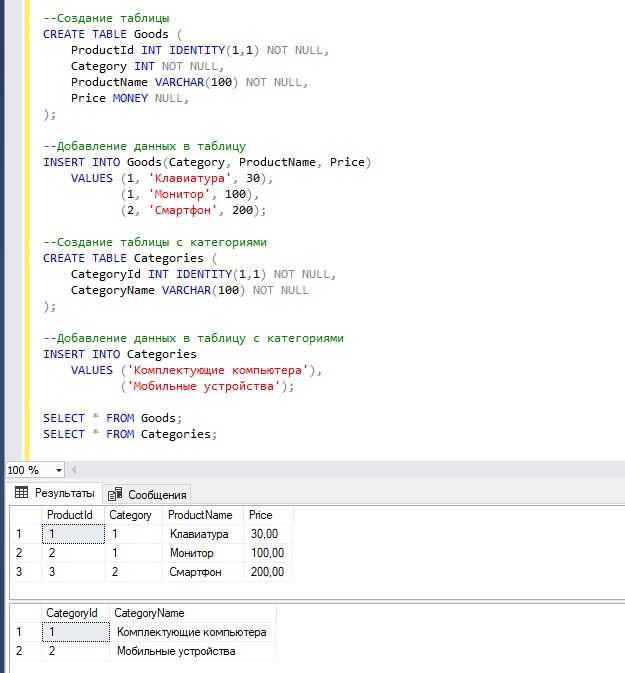
Для создания эффективной витрины данных важно правильно выбрать структуру данных, которая будет оптимально поддерживать аналитические запросы и обеспечивать быструю обработку больших объемов информации. Рассмотрим несколько популярных моделей и их применения.
Модель звезды (Star Schema) — одна из самых распространённых структур для витрины данных. Она предполагает наличие центральной фактовой таблицы, которая содержит измеряемые показатели (например, объем продаж, количество клиентов), и нескольких таблиц измерений, которые описывают различные аспекты данных (например, время, географическое местоположение, товар). Такая модель облегчает понимание и анализ данных, однако с ростом данных она может потребовать дополнительной оптимизации.
Модель снежинки (Snowflake Schema) — вариация модели звезды, где таблицы измерений дополнительно нормализованы. Это помогает уменьшить избыточность данных, но усложняет структуру запросов и повышает нагрузку на систему. Модель снежинки подходит для случаев, когда требуется высокая степень нормализации и минимизация повторений информации.
Инкрементная загрузка и полная перезагрузка данных – два подхода к обновлению данных в витрине. Инкрементная загрузка позволяет обрабатывать только новые или изменённые записи, что снижает нагрузку на систему и уменьшает время загрузки. Однако она требует хорошей настройки механизмов отслеживания изменений в источниках данных. Полная перезагрузка проще в реализации, но может занять больше времени и ресурсов.
Выбор между моделью звезды и снежинки зависит от конкретных задач. Модель звезды подходит для быстрой и эффективной работы с большими объёмами данных, где важна простота запросов и аналитических операций. Модель снежинки используется, когда необходима высокая степень нормализации и снижение избыточности данных, но при этом запросы могут стать более сложными.
Гибридные модели, сочетание подходов модели звезды и снежинки, также становятся популярными. Например, можно использовать модель звезды для большинства измерений и применять нормализацию в отдельных областях, где это критически важно для уменьшения дублирования данных.
При выборе модели необходимо учитывать несколько факторов: количество данных, частоту обновлений, сложность запросов и требования к скорости обработки. Важно провести тщательное тестирование, чтобы определить, какая модель будет наиболее эффективной в вашем конкретном случае.
Как спроектировать таблицы для хранения данных в витрине?
1. Выбор типа хранения данных
Витрина данных обычно использует две основные модели хранения: звездную и снежинку. В звездной модели таблица фактов (основная таблица, содержащая измерения) соединена с несколькими таблицами измерений. В модели снежинки таблицы измерений могут быть нормализованы, что снижает избыточность, но увеличивает сложность запросов. Выбор зависит от объема данных и частоты обновлений.
2. Проектирование таблицы фактов
Таблица фактов должна содержать агрегированные данные, такие как суммы, средние значения, количество и другие метрики. Она также должна включать ключи для соединений с таблицами измерений. Для оптимизации хранения и производительности стоит использовать числовые индексы для этих ключей и избегать хранения избыточной информации.
3. Проектирование таблицы измерений
Таблицы измерений содержат атрибуты, которые описывают факты. Важно определить, какие данные будут использоваться для аналитики, и избегать включения атрибутов, которые не будут использоваться для запросов. В зависимости от бизнеса, таблицы измерений могут быть денормализованы, чтобы ускорить запросы (например, адрес, который может включать город, страну и почтовый индекс в одном поле).
4. Использование суррогатных ключей
Суррогатные ключи (псевдоключи) применяются для связки таблиц фактов и измерений. Это позволяет избежать проблем с изменяющимися значениями в ключах (например, изменяющиеся коды стран). В таблице измерений следует использовать уникальные идентификаторы для каждого записи, которые будут связываться с таблицей фактов.
5. Инкрементальные обновления
Витрина данных обычно не обновляется в реальном времени. Использование инкрементальных обновлений, например, с добавлением только новых или измененных записей, помогает сократить время загрузки данных и избежать повторного перерасчета уже агрегированных данных.
6. Использование индексов и партиционирования
Для улучшения производительности запросов можно использовать индексы по ключам таблиц и часто запрашиваемым атрибутам. Партиционирование таблиц по временным меткам или другим критериям помогает ускорить выполнение запросов и управления большими объемами данных.
7. Обеспечение качества данных
Важно предусмотреть механизмы очистки и валидации данных, чтобы они соответствовали нужным стандартам перед загрузкой в витрину. Необходимо поддерживать согласованность данных, например, при изменении записей в таблицах измерений или фактов.
8. Историзация данных
Для хранения исторических данных, таких как изменения в клиентах или продуктах, необходимо проектировать таблицы с поддержкой истории. Важно определить, какие поля будут подвергаться изменениям, и хранить старые значения с датой их изменения. Это позволит отслеживать изменения во времени и анализировать их в контексте.
В целом, проектирование таблиц для витрины данных должно учитывать особенности бизнес-анализа и требования к производительности, обеспечивая быстрый доступ и точные результаты.
Методы извлечения данных из источников для витрины SQL

Одним из распространенных методов является использование ETL-процессов (Extract, Transform, Load). При этом данные извлекаются из разных источников, очищаются и преобразуются, прежде чем быть загруженными в витрину. ETL-цели включают стандартизацию форматов данных, устранение дублирования и агрегирование информации для удобства анализа.
Для работы с большими объемами данных стоит использовать параллельное извлечение с разделением на пакеты. Это позволяет минимизировать время отклика при извлечении и обеспечивать высокую производительность системы. Применение подходов, таких как инкрементальные загрузки, значительно снижает нагрузку на исходные системы, так как данные извлекаются только за последний период времени, а не полностью.
В случае работы с базами данных важен выбор метода соединения: синхронное или асинхронное извлечение. Синхронное извлечение подходит для малых объемов данных, но для крупных систем эффективнее применять асинхронные методы, которые позволяют извлекать данные в фоновом режиме и не блокировать другие операции.
Взаимодействие с внешними источниками, такими как веб-API или другие сервисы, требует правильной настройки запросов для минимизации задержек и ошибок. Рекомендуется использовать API с поддержкой пакетной обработки, а также методы обработки ошибок, чтобы снизить вероятность потери данных и ускорить процесс извлечения.
Оптимизация запросов является важным аспектом извлечения данных. Применение индексов, использование ограничений на выборку и настройка кэширования позволяют снизить нагрузку на базу данных и повысить скорость извлечения. Важно также настроить таймауты на запросы, чтобы предотвратить зависание процессов извлечения.
Интеграция с системами мониторинга и логирования позволит отслеживать процесс извлечения данных, анализировать производительность и своевременно выявлять проблемы. Это особенно важно при извлечении данных из нескольких источников с различными схемами и правилами работы.
Оптимизация запросов в витрине данных для повышения производительности
Эффективность работы витрины данных напрямую зависит от того, как настроены запросы для извлечения информации. Оптимизация запросов помогает снизить нагрузку на базу данных, улучшить время отклика и повысить производительность анализа. Рассмотрим ключевые стратегии оптимизации запросов для витрины данных.
- Использование индексов – Индексы существенно ускоряют поиск по таблицам, снижая время выполнения запросов. Для часто используемых столбцов в WHERE, JOIN и ORDER BY следует создавать индексы. Важно выбирать индекс по наиболее часто запрашиваемым данным, чтобы не перегружать систему лишними вычислениями.
- Сокращение объема данных – Использование
SELECTс выбором только нужных столбцов вместоSELECT *значительно снижает нагрузку на систему. Также важно минимизировать количество строк в выборке с помощьюWHEREиLIMIT. - Оптимизация JOIN-ов – В витринах данных часто используются объединения таблиц. Рекомендуется заранее анализировать, какие поля будут участвовать в объединении. Использование подходящих индексов на колонках, участвующих в
JOIN, ускоряет выполнение. Кроме того, порядок объединений имеет значение – сначала объединяются меньшие таблицы, если это возможно. - Использование агрегаций с умом – Агрегирующие функции, такие как
SUM,AVGилиCOUNT, часто приводят к значительному увеличению времени выполнения запросов. Для их ускорения следует использовать предварительные агрегации на уровне ETL-процессов или специализированные агрегационные индексы. - Параллельная обработка запросов – Современные СУБД поддерживают параллельное выполнение запросов. Разделение запроса на несколько частей и выполнение их параллельно позволяет значительно ускорить обработку больших объемов данных.
- Оптимизация подзапросов – Подзапросы могут быть ресурсозатратными, особенно если их результат используется несколько раз в главном запросе. Рекомендуется избегать подзапросов в SELECT и вместо этого использовать временные таблицы или CTE (Common Table Expressions), которые позволяют уменьшить количество вычислений.
- Использование кэширования – Кэширование результатов часто выполняемых запросов значительно ускоряет их выполнение. Важно правильно настроить механизмы кэширования на уровне СУБД или использовать внешние кэш-системы, такие как Redis, для хранения промежуточных данных.
- Разбиение таблиц (Partitioning) – Разбиение больших таблиц на более мелкие позволяет эффективно работать с ними, особенно если запросы часто обращаются к данным в определенном диапазоне (например, по датам). Использование партиционирования по ключу позволяет уменьшить объем данных, которые нужно обрабатывать в одном запросе.
- Использование материализованных представлений – Материализованные представления позволяют заранее вычислить и сохранить результаты сложных запросов. Это особенно полезно для часто выполняемых агрегированных запросов, которые могут быть дорогостоящими при выполнении в реальном времени.
- Обновление статистики базы данных – СУБД использует статистику для планирования выполнения запросов. Регулярное обновление статистики помогает СУБД выбирать более эффективные планы выполнения, что снижает время отклика запросов.
Каждая из этих стратегий требует тщательной настройки и мониторинга. Важно учитывать как особенности работы витрины данных, так и нагрузки, которые она должна поддерживать. Оптимизация запросов – это не одноразовая задача, а процесс, который должен учитывать изменения в структуре данных и в запросах пользователей.
Как правильно настроить индексы в витрине данных SQL?
Настройка индексов в витрине данных SQL критически важна для обеспечения высокой производительности запросов, особенно в условиях больших объемов данных. Правильный выбор и настройка индексов могут значительно ускорить операции выборки, но неверно выбранные индексы могут замедлить работу и привести к ненужным расходам ресурсов. Рассмотрим, как эффективно настроить индексы для витрины данных.
Основные принципы настройки индексов:
- Использование индексов для часто запрашиваемых столбцов. Индексы особенно полезны для столбцов, которые участвуют в операциях фильтрации, соединениях и сортировке. Например, столбцы в WHERE или JOIN-условиях должны быть проиндексированы.
- Индексы для внешних ключей. Создание индекса на столбцах внешних ключей улучшает производительность соединений и целостность данных. Это помогает ускорить выполнение запросов, где используются связи между таблицами.
- Использование составных индексов. Если запросы часто используют несколько столбцов, полезно создать составной индекс. Однако важно помнить, что составные индексы эффективны только в случае, если запрос использует столбцы в том же порядке, что и в индексе.
- Избегайте избыточных индексов. Каждый индекс требует затрат на обновление данных при вставке, удалении или изменении записей. Избыточные индексы могут замедлить эти операции, поэтому важно создавать индексы только для наиболее часто используемых запросов.
Стратегии оптимизации индексов:
- Использование фильтрованных индексов. Если запросы часто фильтруют данные по определенному условию, например, по дате или статусу, можно использовать фильтрованные индексы, которые индексируют только часть данных, что улучшает производительность и снижает накладные расходы.
- Анализ запросов с помощью EXPLAIN. Использование команды EXPLAIN помогает понять, как оптимизатор запросов выбирает индексы, и позволяет настроить индексы под реальные запросы. Это поможет выявить узкие места и переоценить необходимость некоторых индексов.
- Регулярная реорганизация и обновление статистики. Индексы со временем могут фрагментироваться, что влияет на их производительность. Регулярная реорганизация и обновление статистики позволяет поддерживать их эффективность.
Типы индексов, которые стоит использовать:
- B-tree индексы. Наиболее распространенный тип индексов, который эффективно работает с операциями равенства и диапазонными запросами. Применяется к большинству типов данных, включая числа и строки.
- Bitmap индексы. Подходят для столбцов с малым числом уникальных значений, таких как статусы или категории. Они позволяют существенно сэкономить место при индексировании таких столбцов.
- Hash индексы. Используются для быстрого поиска по ключу, но не поддерживают диапазонные запросы, поэтому могут быть полезны в случаях, когда нужно быстро находить точное совпадение.
Ошибки при настройке индексов:
- Неоптимальное использование индексов. Например, создание индекса на каждом столбце может привести к значительным накладным расходам. Индексы должны быть настроены так, чтобы они соответствовали конкретным запросам, а не создавались без учета реальных потребностей.
- Создание индексов на столбцах с высокой кардинальностью. Например, создание индекса на столбцах с уникальными значениями может привести к излишним затратам на хранение и обновление индексов без заметного увеличения производительности.
Правильная настройка индексов в витрине данных SQL требует внимательного подхода и анализа. Постоянная оптимизация индексов и использование инструментов для мониторинга производительности обеспечат максимальную эффективность работы с данными в долгосрочной перспективе.
Планирование и настройка обновлений данных в витрине
Определение частоты обновлений
Частота обновлений зависит от потребностей бизнеса и характеристик данных. Если данные изменяются ежедневно, то обновления должны происходить с таким же интервалом. Однако для некоторых данных, например, финансовых или логистических, обновления могут требовать выполнения в реальном времени или с минимальными задержками. Важно предусмотреть механизмы, которые позволят обновлять только измененные данные, чтобы снизить нагрузку на систему.
Типы обновлений данных
Существуют несколько типов обновлений данных: полное, инкрементальное и смешанное. Полное обновление подразумевает замену всех данных в витрине, что подходит для небольших объемов информации, но может быть затратным для больших наборов данных. Инкрементальное обновление включает только изменения, что значительно ускоряет процесс и снижает нагрузку на систему. Смешанный метод сочетает оба подхода, применяя полное обновление для определенных категорий данных и инкрементальное для других.
Механизмы управления обновлениями
Для автоматизации обновлений следует настроить механизм ETL (Extract, Transform, Load) с учетом зависимости между источниками данных. Это обеспечит более предсказуемую работу витрины и уменьшит вероятность ошибок. При настройке ETL важно настроить мониторинг, чтобы оперативно выявлять ошибки или задержки в обновлениях. Кроме того, стоит интегрировать систему оповещений для своевременного реагирования на проблемы.
Обработка ошибок и откатов
Каждое обновление должно предусматривать возможность отката на предыдущую версию данных в случае сбоя. Необходимо настроить механизм логирования, чтобы отслеживать любые отклонения от нормальной работы и анализировать их причины. Важно, чтобы в случае ошибки процесс обновления не нарушал доступность витрины данных для пользователей.
Оптимизация и тестирование обновлений
Перед внедрением механизма обновлений на продуктивной системе необходимо провести тестирование с использованием исторических данных. Это позволит выявить потенциальные проблемы с производительностью и скоростью обновлений, а также оценить влияние на нагрузку. Оптимизация обновлений может включать использование параллельных процессов или выделенных ресурсов для обработки данных.
Выбор технологии для обновлений
В зависимости от размера и сложности данных, выбор технологии для обновлений может варьироваться. Для крупных проектов может подойти использование потоковых данных (streaming), таких как Apache Kafka или AWS Kinesis, для быстрого обновления в реальном времени. Для менее сложных проектов можно использовать традиционные подходы с базами данных SQL, которые предоставляют механизмы для инкрементальных обновлений через триггеры или временные таблицы.
Вопрос-ответ:
Что такое витрина данных и зачем она нужна?
Витрина данных — это структура, предназначенная для хранения и представления информации, оптимизированной для анализа и отчетности. Она обычно формируется на основе данных из различных источников, обеспечивая пользователям удобный доступ к информации, агрегированной и подготовленной для анализа. Витрина данных позволяет ускорить процесс получения инсайтов, минимизируя нагрузку на основную базу данных и улучшая производительность аналитических запросов.
Как выбрать правильные данные для витрины?
При создании витрины данных необходимо выбирать только те данные, которые реально понадобятся для анализа. Это могут быть ключевые показатели, данные из различных систем, агрегированные показатели за определённый период. Важно учитывать, что витрина не должна содержать всего объема данных, доступных в источниках, а лишь те данные, которые будут использоваться в отчетах и анализах, чтобы не перегружать систему и улучшить быстродействие.
Какие SQL техники применяются для создания витрины данных?
Для создания витрины данных в SQL часто используют методы агрегации, объединения данных (JOIN), фильтрацию (WHERE), а также создание представлений (VIEW) для удобства работы с данными. Также могут применяться оконные функции для вычисления дополнительных показателей, таких как накопительные суммы или проценты. Ключевыми моментами являются оптимизация запросов для быстрого извлечения данных и их предварительная обработка перед представлением в витрине.
Как обеспечить обновление данных в витрине?
Обновление данных в витрине происходит в зависимости от специфики бизнеса и частоты изменений в источниках данных. На практике используют различные методы, такие как автоматические задачи по обновлению данных с помощью SQL-скриптов, планировщиков заданий или ETL-процессов. Также возможна настройка инкрементальных обновлений, при которых добавляются только измененные или новые данные, чтобы не перегружать систему.
Какие проблемы могут возникнуть при создании витрины данных?
Основные проблемы при создании витрины данных связаны с оптимизацией запросов и эффективностью обработки больших объемов информации. Неправильно настроенные индексы, избыточные данные или сложные агрегированные вычисления могут значительно замедлить работу витрины. Также важно следить за качеством исходных данных — если они содержат ошибки или неструктурированные данные, это может привести к некорректным результатам в витрине.
Что такое витрина данных SQL и зачем она нужна?
Витрина данных SQL — это специализированная структура данных, которая предназначена для организации и хранения информации таким образом, чтобы облегчить её анализ и извлечение. Она позволяет объединить данные из различных источников и представить их в удобном формате для работы с аналитическими инструментами, предоставляя быстрый доступ к нужной информации. Создание витрины данных помогает повысить качество и скорость принятия решений, поскольку аналитики могут работать с уже обработанными и структурированными данными без необходимости постоянно обращаться к сырым данным в операционных системах.