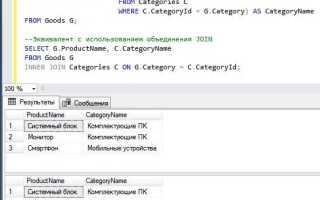
Правильное составление SQL-запроса – это ключевое умение для работы с базами данных. SQL позволяет эффективно взаимодействовать с данными, но для получения нужного результата необходимо понимать основы синтаксиса и принципы работы с запросами. Основные операции, которые часто используются в SQL, включают выборку данных, вставку, обновление и удаление данных. Разберём, как построить правильный запрос, учитывая различные особенности.
Когда вы начинаете работать с SQL-запросами, первым шагом является определение структуры данных. Для этого важно точно понимать, какие таблицы в базе данных и какие поля вам необходимы. Например, если требуется извлечь информацию о сотрудниках, то запрос может выглядеть так:
SELECT имя, должность, зарплата FROM сотрудники WHERE должность = ‘менеджер’;
Здесь важно обратить внимание на правильность указания имен таблиц и столбцов. Также следует учитывать, что запрос может быть чувствителен к регистру, особенно в системах, где регистр имеет значение. В таких случаях избегайте ошибок, проверяя правильность написания всех элементов.
Не менее важно использовать условие WHERE, чтобы ограничить количество извлекаемых данных. Применение правильных фильтров помогает избежать избыточной нагрузки на систему и ускоряет выполнение запроса. Важно помнить, что с помощью оператора JOIN можно объединить несколько таблиц для получения более сложных данных, что значительно расширяет возможности работы с базой.
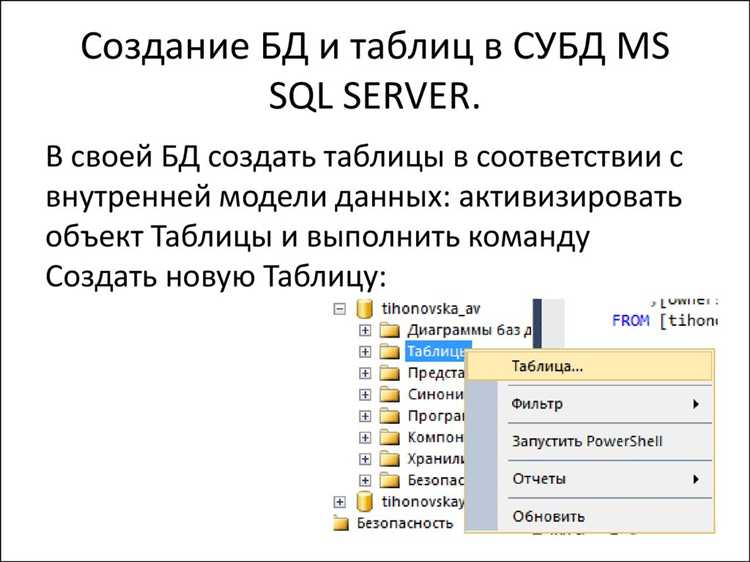
Как выбрать подходящий тип SQL запроса для решения задачи
Правильный выбор типа SQL запроса зависит от конкретной задачи и данных, с которыми предстоит работать. Важно учитывать, какие операции нужно выполнить с базой данных, и какие ресурсы для этого будут необходимы.
Если требуется извлечь данные из базы, используется запрос SELECT. Для простых выборок с минимальной фильтрацией достаточно простого SELECT с WHERE. Для сложных запросов, которые включают объединение нескольких таблиц, следует использовать JOIN, определяя тип соединения (INNER, LEFT, RIGHT). При необходимости сортировки данных следует добавить оператор ORDER BY, а для ограничения количества результатов – LIMIT или TOP.
Если задача требует обновления данных, то используется запрос UPDATE. Важно правильно указать условие в WHERE, чтобы обновления касались только нужных записей. Без WHERE все строки могут быть изменены, что приведет к нежелательным последствиям.
Для добавления новых данных используется запрос INSERT. Важно четко указывать столбцы, в которые будут вставляться значения, чтобы избежать ошибок, связанных с несовпадением типов данных или количества значений. При массовом добавлении данных можно использовать команду INSERT INTO с несколькими наборами значений для повышения производительности.
Удаление данных производится с помощью DELETE. Подобно UPDATE, следует использовать WHERE для ограничения области действия запроса, чтобы избежать случайного удаления всех записей в таблице. В случае необходимости быстрого удаления всех записей без учета ограничений, можно использовать команду TRUNCATE, которая работает быстрее, но не может быть откатана в случае ошибок.
Для создания структуры базы данных, такие запросы как CREATE TABLE и ALTER TABLE позволяют определить или изменить таблицы и их столбцы. Важно точно указать типы данных для каждого столбца и определять индексы для оптимизации поиска и сортировки.
Для сложных аналитических задач часто используется запрос SELECT с агрегатными функциями (SUM, AVG, COUNT, MIN, MAX). Эти функции позволяют подсчитывать значения по группам, для чего используется GROUP BY. Если нужно извлечь только уникальные значения, применяется DISTINCT.
Если нужно работать с транзакциями, важно использовать команды COMMIT и ROLLBACK для контроля изменения данных в рамках одной операции. Это особенно важно при сложных и многократных обновлениях данных, где необходима атомарность операции.
Тип запроса следует выбирать исходя из объема данных, требований к скорости выполнения и точности работы. Правильное использование индексов, условий и операторов существенно влияет на производительность запросов.
Как правильно использовать операторы SELECT, INSERT, UPDATE и DELETE
Работа с реляционными базами данных невозможна без уверенного владения основными SQL-операторами. Ниже приведены чёткие рекомендации по их эффективному применению.
- SELECT
- Всегда указывайте только необходимые столбцы:
SELECT имя, дата_рождения FROM пользователи. ИзбегайтеSELECT *, если нет явной необходимости. - Фильтрация должна быть конкретной:
WHERE возраст >= 18предпочтительнее, чем расплывчатые условия. - Используйте алиасы для читаемости:
SELECT имя AS пользователь FROM клиенты. - Для сложных запросов применяйте подзапросы или JOIN с явным указанием связей:
INNER JOIN заказы ON клиенты.id = заказы.клиент_id.
- Всегда указывайте только необходимые столбцы:
- INSERT
- Всегда указывайте список столбцов:
INSERT INTO товары (название, цена) VALUES ('Книга', 500). - Избегайте вставки дубликатов с помощью
INSERT IGNOREилиINSERT ... ON DUPLICATE KEY UPDATE. - Проверяйте типы данных перед вставкой, особенно для дат и чисел.
- Всегда указывайте список столбцов:
- UPDATE
- Никогда не выполняйте
UPDATEбезWHERE, если не обновляете все записи осознанно. - Используйте конкретные условия:
UPDATE сотрудники SET должность = 'менеджер' WHERE отдел = 'продажи'. - Обновление с JOIN – мощный инструмент:
UPDATE заказы z JOIN клиенты k ON z.клиент_id = k.id SET z.статус = 'отправлен' WHERE k.регион = 'Москва'.
- Никогда не выполняйте
- DELETE
- Удаление всегда требует
WHERE:DELETE FROM пользователи WHERE неактивен = 1. - Перед удалением проверяйте выборку через
SELECTс теми же условиями. - Для массового удаления с условий на связанных таблицах используйте
DELETE с JOIN, но с особой осторожностью.
- Удаление всегда требует
Применение этих рекомендаций минимизирует риски потери данных и повышает читаемость запросов.
Какие параметры влияют на правильность условий WHERE
Индексация влияет на производительность. Условия должны использовать индексируемые поля. Условие WHERE LOWER(name) = 'иван' отключает индекс, так как функция применяется к столбцу. Лучше использовать приведение в коде или хранить данные в унифицированном виде.
NULL требует отдельной логики. Выражения вида WHERE column = NULL всегда возвращают false. Используйте IS NULL или IS NOT NULL для корректной фильтрации.
Логические операторы AND и OR должны быть сгруппированы с помощью скобок. Без этого порядок выполнения может исказить логику фильтрации. Например, WHERE a = 1 OR b = 2 AND c = 3 не эквивалентно WHERE (a = 1 OR b = 2) AND c = 3.
Сравнение строк чувствительно к регистру и локали. В PostgreSQL сравнение WHERE name = 'Иван' не совпадёт с 'иван', если не использовать ILIKE или специальные коллации. Учитывайте настройки сопоставления символов.
Дата и время требуют точного формата. Условие WHERE created_at = '2024-01-01' не включит записи с временем. Лучше использовать диапазон: WHERE created_at >= '2024-01-01' AND created_at < '2024-01-02'.
Подзапросы в WHERE должны возвращать корректные множества. Условие WHERE id = (SELECT id FROM ...) упадёт с ошибкой, если подзапрос вернёт более одной строки. В таких случаях применяйте IN или EXISTS.
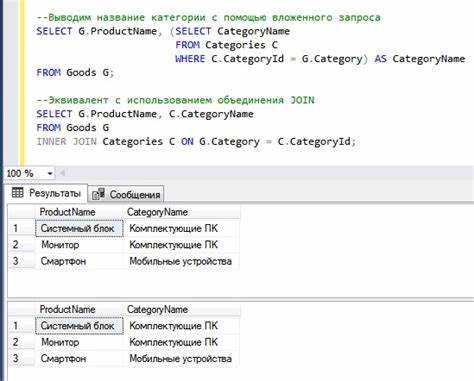
Как использовать JOIN для объединения данных из нескольких таблиц
Оператор JOIN позволяет связать строки из разных таблиц по логическим условиям. Например, при наличии таблиц orders и customers, связанных по полю customer_id, можно получить заказы с именами клиентов:
SELECT orders.id, customers.name FROM orders JOIN customers ON orders.customer_id = customers.id;
Важно выбирать нужный тип JOIN. INNER JOIN возвращает только совпадающие строки. LEFT JOIN добавляет строки из левой таблицы даже при отсутствии соответствий в правой. Это полезно, если нужно увидеть все заказы, включая те, у которых не указан клиент:
SELECT orders.id, customers.name FROM orders LEFT JOIN customers ON orders.customer_id = customers.id;
Если в выборке участвуют поля с одинаковыми названиями, необходимо указывать имя таблицы или использовать псевдонимы:
SELECT o.id, c.name FROM orders AS o JOIN customers AS c ON o.customer_id = c.id;
При объединении более двух таблиц нужно учитывать порядок JOIN и фильтры, чтобы избежать избыточных или некорректных результатов. Используйте EXPLAIN для анализа производительности запроса и индексы по ключам соединения для ускорения выполнения.
Как обрабатывать данные с помощью агрегации (COUNT, SUM, AVG и др.)
Агрегатные функции позволяют эффективно анализировать данные, сводя большие объемы информации к ключевым показателям. Ниже – конкретные приемы использования основных агрегатных функций SQL.
- COUNT() – считает количество строк. Чтобы получить число заказов по каждому клиенту:
SELECT client_id, COUNT(*) FROM orders GROUP BY client_id; - SUM() – вычисляет сумму значений. Общая выручка по каждому товару:
SELECT product_id, SUM(total_price) FROM sales GROUP BY product_id; - AVG() – среднее значение. Средняя зарплата по отделам:
SELECT department, AVG(salary) FROM employees GROUP BY department; - MIN() и MAX() – минимальное и максимальное значение. Самый дешевый и дорогой товар:
SELECT MIN(price), MAX(price) FROM products;
Важно:
- Всегда используйте
GROUP BYпри применении агрегатных функций к сгруппированным данным. Без него агрегаты применяются ко всей таблице. - Для фильтрации сгруппированных данных используйте
HAVINGвместоWHERE. Пример:
SELECT client_id, SUM(amount) FROM payments GROUP BY client_id HAVING SUM(amount) > 10000; - Агрегация по нескольким уровням:
SELECT region, store, COUNT(*) FROM sales GROUP BY region, store;– группировка сначала по региону, затем по магазину.
Не агрегируйте несвязанные данные – это приведет к логическим ошибкам. Используйте JOIN до агрегации, если требуется объединить несколько таблиц.
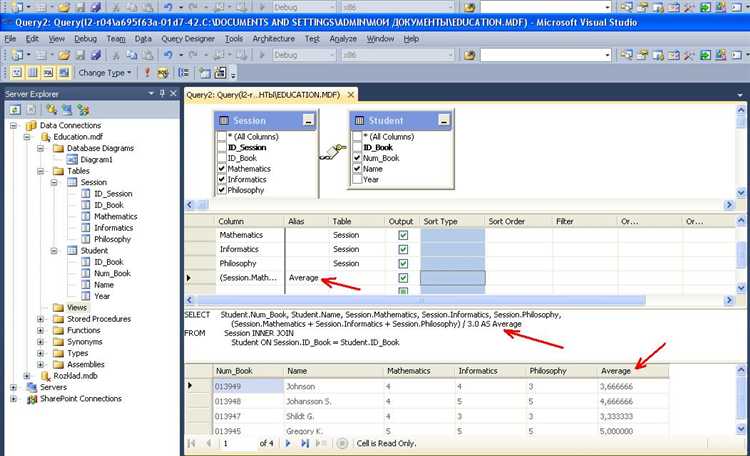
Как работать с подзапросами в SQL запросах
SELECT name FROM employees WHERE department_id IN (SELECT id FROM departments WHERE budget > 1000000);
Подзапрос в SELECT позволяет добавлять вычисляемые значения. Пример – количество заказов клиента:
SELECT name, (SELECT COUNT(*) FROM orders WHERE customer_id = customers.id) AS order_count FROM customers;
Подзапрос в FROM требует присвоения псевдонима и используется как временная таблица. Это удобно при агрегации и фильтрации:
SELECT dept_id, avg_salary FROM (SELECT department_id AS dept_id, AVG(salary) AS avg_salary FROM employees GROUP BY department_id) AS dept_avg WHERE avg_salary > 50000;
Следует избегать подзапросов, которые можно заменить JOIN, особенно при больших объемах данных. Например, для выборки товаров с категориями предпочтительнее использовать INNER JOIN, а не подзапрос в SELECT.
Подзапрос должен возвращать одно значение при использовании с операторами сравнения (=, <, > и др.). Иначе возникнет ошибка. Например:
SELECT name FROM products WHERE price = (SELECT MAX(price) FROM products);
Для повышения читаемости ограничивай глубину вложенности и используй псевдонимы для всех подзапросов. Подзапросы эффективны при необходимости пошаговых вычислений и фильтрации по результатам других выборок.
Как использовать индексы для оптимизации запросов
Индексы позволяют существенно сократить время выполнения SQL-запросов, особенно при работе с большими объемами данных. Основное назначение индексов – ускорение поиска строк, соответствующих условиям запроса. Однако неправильное использование может привести к ухудшению производительности и увеличению объема занимаемой памяти.
Создавайте индексы на столбцы, которые часто используются в условиях WHERE, JOIN и ORDER BY. Например, если запрос регулярно фильтрует по полю created_at, индекс на этом столбце ускорит выборку. Но если поле имеет малую кардинальность (например, булевый тип), индекс будет малоэффективен.
Для составных условий используйте составные индексы. При этом порядок столбцов имеет значение. Индекс по полям (user_id, status) подойдет для фильтрации по user_id или по user_id AND status, но не только по status.
Не создавайте избыточные индексы. Каждый дополнительный индекс замедляет операции INSERT, UPDATE и DELETE, так как требует обновления структуры. Используйте команду EXPLAIN для анализа, какой индекс используется при выполнении запроса.
Для текстовых полей типа VARCHAR или TEXT используйте префиксные индексы или полнотекстовые, в зависимости от типа поиска. Например, индекс по первым 10 символам (INDEX(name(10))) уменьшит объем индекса, но все еще обеспечит прирост скорости при начальном совпадении.
Регулярно пересматривайте индексы при изменении логики приложения или запросов. Устаревшие или неиспользуемые индексы увеличивают нагрузку на систему и могут препятствовать оптимизации планов выполнения.
Как исключить ошибки при составлении сложных SQL запросов
Избегайте подзапросов внутри WHERE и SELECT, если их можно заменить JOIN. Особенно это критично при работе с большими объёмами данных: подзапросы обрабатываются медленнее и сложнее отлаживаются. Вместо:
SELECT name FROM employees
WHERE department_id IN (SELECT id FROM departments WHERE region = 'EU');предпочтительно использовать:
SELECT e.name
FROM employees e
JOIN departments d ON e.department_id = d.id
WHERE d.region = 'EU';При использовании агрегатных функций применяйте группировку строго по необходимым полям. Избыточное добавление полей в GROUP BY приводит к ошибкам агрегирования и неочевидным результатам. Всегда проверяйте логику HAVING – часто туда ошибочно попадают условия, которые должны быть в WHERE.
Если запрос содержит несколько JOIN, указывайте алиасы для таблиц и полей. Это избавляет от неоднозначностей и облегчает чтение. Например, вместо:
SELECT id, name, id
FROM users
JOIN orders ON users.id = orders.user_id;используйте:
SELECT u.id AS user_id, u.name, o.id AS order_id
FROM users u
JOIN orders o ON u.id = o.user_id;Избегайте использования SELECT * в сложных запросах. Явное указание нужных полей уменьшает нагрузку на сеть, упрощает понимание структуры данных и предотвращает ошибки при изменении схемы таблиц.
При использовании оконных функций проверьте совместимость версий СУБД и правильно указывайте PARTITION BY и ORDER BY – ошибки в этих конструкциях приводят к неверной агрегации и нарушению бизнес-логики.
Никогда не тестируйте изменения в продуктивной базе. Используйте изолированные среды и реальные данные в ограниченном объёме для отладки. Даже один необдуманный UPDATE без WHERE может повредить данные без возможности восстановления.
Вопрос-ответ:
Чем отличается SELECT * от выборки конкретных столбцов?
Запрос `SELECT *` выбирает все столбцы из таблицы. Это удобно при первоначальной работе с данными, когда нужно быстро посмотреть всю информацию. Однако при работе с большим количеством данных или в сложных приложениях лучше явно указывать нужные столбцы. Это снижает нагрузку на сервер, ускоряет обработку данных и упрощает читаемость запроса.
Почему мой запрос с JOIN возвращает слишком много строк?
Чаще всего это связано с тем, что условие объединения таблиц написано неправильно или не ограничивает результат должным образом. Например, если использовать INNER JOIN без указания точных совпадающих значений, база объединит все строки из одной таблицы со всеми совпадающими строками из другой — даже если таких совпадений несколько. Чтобы избежать этого, нужно внимательно проверять условия объединения и при необходимости использовать дополнительные фильтры в разделе WHERE.
Можно ли использовать подзапросы в WHERE и как это работает?
Да, подзапросы можно использовать в разделе WHERE, особенно когда нужно сравнить значения с результатами другого запроса. Например, `SELECT name FROM employees WHERE department_id IN (SELECT id FROM departments WHERE location = 'Москва')`. Здесь сначала выбираются отделы, находящиеся в Москве, а затем — все сотрудники, работающие в этих отделах. Это удобно, когда информация разбита на связанные таблицы и нужно использовать промежуточные данные для фильтрации.
Что делать, если запрос долго выполняется?
Если SQL-запрос работает медленно, можно начать с анализа используемых индексов. Без них поиск нужных строк может занять много времени. Также стоит пересмотреть структуру самого запроса — возможно, там есть избыточные JOIN’ы, подзапросы или сортировки. Для диагностики можно воспользоваться инструментами профилирования запросов, которые показывают, какие операции занимают больше всего времени.
Когда стоит использовать группировку через GROUP BY?
Группировка применяется, когда нужно объединить строки с одинаковыми значениями в определённом столбце. Это особенно полезно при подсчёте статистики, например количества заказов по каждому клиенту. GROUP BY позволяет свести множество строк к агрегированному результату, например — общая сумма, среднее значение или максимальное. При этом можно комбинировать с HAVING для фильтрации уже сгруппированных данных.