

Сравнение данных между двумя столбцами – частая задача при проверке целостности, выявлении дубликатов или построении аналитических запросов. В SQL это реализуется с помощью логических операторов: =, <>, IS, IS NOT, а также функций NULLIF() и COALESCE().
Если оба столбца могут содержать NULL, прямое сравнение через = не даст ожидаемого результата. Например, выражение WHERE col1 = col2 исключит строки, в которых оба значения NULL, поскольку в SQL NULL = NULL возвращает UNKNOWN. Для таких случаев используется WHERE col1 IS NOT DISTINCT FROM col2 (в PostgreSQL) или комбинация WHERE (col1 = col2 OR (col1 IS NULL AND col2 IS NULL)).
Для поиска расхождений между двумя столбцами часто применяют WHERE col1 <> col2. Однако, если важна точность при наличии NULL, добавляют явную проверку: WHERE NOT (col1 = col2 OR (col1 IS NULL AND col2 IS NULL)).
При работе с числовыми данными возможны случаи, когда значения визуально совпадают, но различаются по типу (например, INTEGER и DECIMAL). Чтобы избежать ложных несовпадений, рекомендуется использовать приведение типов: CAST(col1 AS DECIMAL) = col2.
Сравнение строк требует учета регистра и возможных пробелов. Для унификации значений перед сравнением применяют TRIM(), LOWER() или UPPER(). Пример: WHERE TRIM(LOWER(col1)) = TRIM(LOWER(col2)).
Если задача включает поиск частичных совпадений, используют LIKE или CHARINDEX() (в SQL Server) и POSITION() (в PostgreSQL). Это актуально, например, при сверке email-домена или префиксов номеров телефонов.
Как сравнить значения столбцов в одном и том же ряду
Для сравнения значений двух столбцов в пределах одной строки используется простое условие в блоке WHERE или SELECT. Пример:
SELECT * FROM employees WHERE salary > bonus;
Это условие возвращает только те строки, где значение в столбце salary превышает значение в bonus. Аналогично работают другие операторы: =, !=, <, <=, >=.
Если необходимо учесть возможные NULL, используйте функцию COALESCE, чтобы задать значение по умолчанию:
SELECT * FROM payments WHERE COALESCE(amount, 0) < COALESCE(expected_amount, 0);
Для логического сравнения можно использовать CASE:
SELECT id, CASE WHEN column_a = column_b THEN ‘равны’ ELSE ‘различны’ END AS сравнение FROM data;
Сравнение строк чувствительно к регистру. Чтобы избежать этого, используйте LOWER или UPPER:
SELECT * FROM users WHERE LOWER(first_name) = LOWER(nickname);
Числовые сравнения не требуют преобразования типов, но при работе с типами данных VARCHAR и INT следует привести значения к одному типу, чтобы избежать ошибок:
SELECT * FROM logs WHERE CAST(event_id AS VARCHAR) = event_code;
При необходимости сравнения значений с плавающей точкой избегайте прямого сравнения, используйте допуск:
SELECT * FROM results WHERE ABS(score1 — score2) < 0.0001;
Поиск несовпадений между двумя столбцами в таблице
Для выявления строк, в которых значения в двух столбцах одной таблицы различаются, используется конструкция с оператором сравнения. Пример:
SELECT * FROM имя_таблицы WHERE столбец1 <> столбец2;
Этот запрос вернёт все строки, где данные в указанных столбцах не совпадают. Если требуется учитывать возможные значения NULL, следует использовать более точную проверку:
SELECT * FROM имя_таблицы WHERE (столбец1 IS DISTINCT FROM столбец2);
Конструкция IS DISTINCT FROM корректно сравнивает значения, даже если один из столбцов содержит NULL. Поддерживается в PostgreSQL и некоторых других СУБД. В MySQL можно использовать:
SELECT * FROM имя_таблицы WHERE NOT (столбец1 <=> столбец2);
Оператор <=> – безопасный для NULL вариант сравнения. При необходимости фильтрации только по определённому условию (например, один из столбцов должен содержать конкретное значение), добавляется дополнительная часть:
SELECT * FROM имя_таблицы WHERE столбец1 <> столбец2 AND столбец1 = 'значение';
Для массовой проверки в рамках отладки данных удобно использовать агрегацию и группировку:
SELECT столбец1, столбец2, COUNT(*) FROM имя_таблицы WHERE столбец1 <> столбец2 GROUP BY столбец1, столбец2;
Фильтрация строк, где один из столбцов содержит NULL
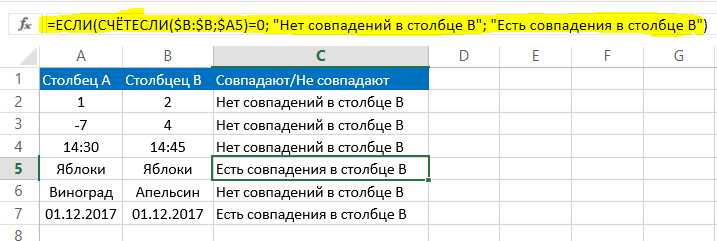
При сравнении значений двух столбцов важно учитывать случаи, когда один из них содержит NULL. В SQL сравнение с NULL не возвращает TRUE или FALSE, а даёт результат UNKNOWN, что влияет на фильтрацию данных.
Для выборки строк, где хотя бы один из двух столбцов содержит NULL, используйте логическое условие IS NULL:
SELECT *
FROM таблица
WHERE столбец1 IS NULL OR столбец2 IS NULL;
Если нужно отобрать строки, в которых один из столбцов не содержит NULL, а второй – NULL, добавьте уточнение:
SELECT *
FROM таблица
WHERE (столбец1 IS NULL AND столбец2 IS NOT NULL)
OR (столбец2 IS NULL AND столбец1 IS NOT NULL);
При сравнении значений, исключая строки с NULL, используйте фильтрацию до сравнения:
SELECT *
FROM таблица
WHERE столбец1 IS NOT NULL
AND столбец2 IS NOT NULL
AND столбец1 = столбец2;
Если необходимо учитывать строки, где оба значения NULL, используйте IS NOT DISTINCT FROM (поддерживается в PostgreSQL):
SELECT *
FROM таблица
WHERE столбец1 IS NOT DISTINCT FROM столбец2;
В MySQL аналогичный результат даёт функция NULL-safe equals:
SELECT *
FROM таблица
WHERE столбец1 <=> столбец2;
Учитывайте особенности СУБД: в стандартном SQL NULL не равен ничему, даже самому себе, поэтому простое сравнение может пропустить нужные строки без явной фильтрации.
Сравнение значений с учётом регистра символов
При сравнении строк в SQL поведение зависит от используемой collation. В MySQL, например, utf8_general_ci игнорирует регистр, а utf8_bin учитывает. Для точного сопоставления строк с учётом регистра необходимо указать соответствующую collation или использовать бинарное сравнение.
Пример для MySQL:
SELECT * FROM users WHERE BINARY username = BINARY email;
В SQL Server сравнение по умолчанию не чувствительно к регистру. Чтобы изменить это, задаётся collation в выражении:
SELECT * FROM users WHERE username COLLATE Latin1_General_CS_AS = email COLLATE Latin1_General_CS_AS;
В PostgreSQL сравнение чувствительно к регистру по умолчанию. Для нечувствительного сравнения используется ILIKE, а для чувствительного – обычный знак равенства:
SELECT * FROM users WHERE username = email;
В SQLite регистр игнорируется при использовании LIKE, но сохраняется при =, если не подключены дополнительные модули. Для строгого сравнения предпочтительнее использовать =.
Рекомендация: всегда явно указывайте нужное поведение через collation или конструкции BINARY, чтобы избежать неоднозначности, особенно при переносе запросов между СУБД.
Сравнение чисел с плавающей запятой между столбцами
При сравнении значений типа FLOAT или DOUBLE между двумя столбцами в SQL возникают сложности из-за особенностей представления чисел в памяти. Бинарная арифметика приводит к неточностям, поэтому прямое сравнение с помощью оператора = часто возвращает ложные результаты, даже если числа выглядят одинаково.
Для корректного сравнения используется допустимая погрешность (эпсилон). Пример с использованием PostgreSQL:
WHERE ABS(col1 - col2) < 0.00001
В MySQL синтаксис аналогичный. Значение эпсилон зависит от контекста задачи и точности исходных данных. Чем больше разрядов, тем меньше должна быть погрешность. Например, при работе с денежными суммами допустимо использовать 1e-6, при физическом моделировании – 1e-10 и меньше.
Если используется тип DECIMAL, подобные проблемы возникают реже, так как этот тип хранит значения точно. Но при приведении типов (например, при операциях между DECIMAL и FLOAT) точность снова теряется.
Для устойчивых сравнений стоит приводить оба значения к типу с более высокой точностью или использовать округление:
WHERE ROUND(col1, 5) = ROUND(col2, 5)
Рекомендуется явно документировать в коде, почему применяется округление или эпсилон, чтобы избежать недоразумений при сопровождении запросов.
Сравнение столбцов из разных таблиц через JOIN
При необходимости сравнить данные из разных таблиц в SQL, используется операция JOIN. Основная цель – объединить строки из двух таблиц по условию, после чего можно сравнивать значения столбцов. Существует несколько типов JOIN, которые позволяют выполнить это в зависимости от требований запроса.
Наиболее часто применяемыми являются следующие типы соединений:
INNER JOIN– выбирает строки, которые имеют совпадение в обеих таблицах.RIGHT JOIN(илиRIGHT OUTER JOIN) – аналогичноLEFT JOIN, но все строки берутся из правой таблицы.FULL JOIN– объединяет данные из обеих таблиц, включая строки, которые не имеют соответствий в другой таблице.
Пример сравнения столбцов из двух таблиц:
SELECT A.column1, B.column2 FROM table1 A JOIN table2 B ON A.id = B.id WHERE A.column1 = B.column2;
Здесь происходит сравнение значений столбца column1 из таблицы table1 и column2 из таблицы table2 по условию, что идентификаторы в обеих таблицах совпадают. Такой запрос выберет только те строки, где значения в этих столбцах совпадают.
Если необходимо выполнить сравнение с другими операторами (например, != или >), условие в WHERE может быть адаптировано:
SELECT A.column1, B.column2 FROM table1 A JOIN table2 B ON A.id = B.id WHERE A.column1 != B.column2;
С помощью JOIN можно эффективно сравнивать столбцы разных таблиц, но важно помнить о производительности запросов. Чем больше данных в таблицах и чем сложнее соединения, тем дольше будет выполняться запрос. Чтобы оптимизировать работу, стоит индексировать те столбцы, которые участвуют в операциях соединения.
Вопрос-ответ:
Как сравнивать значения двух столбцов в SQL?
Для сравнения значений двух столбцов в SQL используется оператор `=`. Например, запрос: `SELECT * FROM таблица WHERE столбец1 = столбец2;` вернет все строки, где значения в `столбец1` и `столбец2` равны. Это простой способ для выполнения такого сравнения.
Можно ли использовать операторы больше или меньше для сравнения столбцов в SQL?
Да, можно. Операторы сравнения `>`, `<`, `>=`, `<=`, и `<>` также применимы к столбцам в SQL. Например, запрос: `SELECT * FROM таблица WHERE столбец1 > столбец2;` вернет строки, где значения в `столбец1` больше значений в `столбец2`. Это полезно, когда нужно проверить условия больше или меньше для данных в двух столбцах.
Как сравнивать значения двух столбцов с учетом NULL в SQL?
В SQL значения `NULL` нельзя напрямую сравнивать с помощью операторов `=` или `<>`. Для проверки, например, на равенство с `NULL`, используется выражение `IS NULL` или `IS NOT NULL`. Чтобы корректно сравнить два столбца, учитывая `NULL`, можно использовать конструкцию `COALESCE`, которая заменяет `NULL` на определенное значение. Например, запрос: `SELECT * FROM таблица WHERE COALESCE(столбец1, 0) = COALESCE(столбец2, 0);` сравнивает столбцы, считая `NULL` за 0.
Какие существуют методы сравнения строковых данных в разных столбцах в SQL?
Для сравнения строк в SQL используется оператор `=`, который проверяет, равны ли строки в двух столбцах. Однако стоит учитывать регистр символов, так как SQL по умолчанию может быть чувствителен к регистру в некоторых СУБД. Для игнорирования регистра можно использовать функцию `LOWER()` или `UPPER()`. Например, запрос: `SELECT * FROM таблица WHERE LOWER(столбец1) = LOWER(столбец2);` сравнит строки без учета регистра.





