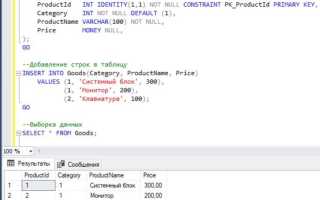
Операция суммирования значений в SQL – один из базовых, но критически важных инструментов при работе с реляционными базами данных. Функция SUM() позволяет агрегировать числовые данные в рамках одного столбца, предоставляя быстрый способ получения итоговых значений для финансовых, аналитических и управленческих отчетов.
Прямая форма использования выглядит просто: SELECT SUM(название_столбца) FROM название_таблицы; Однако в реальных сценариях зачастую требуется дополнительная логика. Например, фильтрация по дате или по типу транзакции с помощью WHERE, или группировка по категориям с GROUP BY. Эти элементы обеспечивают гибкость и точность в получении необходимых сумм.
Особое внимание стоит уделять типу данных. Попытка суммировать строки, содержащие текст или NULL-значения, приведёт к некорректным результатам или ошибкам. Рекомендуется использовать конструкции COALESCE() или ISNULL() для обработки неопределённых значений, особенно в отчетах, где отсутствие данных не должно влиять на общий итог.
При объединении таблиц через JOIN важно учитывать возможное дублирование строк, приводящее к завышенным итогам. Решается это через подзапросы или функцию DISTINCT внутри SUM(). Каждая из этих стратегий должна применяться с пониманием структуры данных и предполагаемой логики суммирования.
Как использовать функцию SUM() для одного столбца
Функция SUM() применяется для вычисления общего значения по числовому столбцу. Она игнорирует NULL и не влияет на строки с нечисловыми данными.
- Синтаксис:
SELECT SUM(имя_столбца) FROM имя_таблицы; - Поддерживаются арифметические выражения:
SELECT SUM(цена * количество) FROM продажи; - Для фильтрации строк используйте
WHERE:SELECT SUM(сумма) FROM заказы WHERE статус = 'оплачен';
При использовании с GROUP BY происходит агрегация по группам:
SELECT клиент_id, SUM(сумма)
FROM заказы
GROUP BY клиент_id;Чтобы избежать искажений, проверьте, что поле не содержит дубликатов, если их не предполагается учитывать.
- Убедитесь, что столбец имеет числовой тип:
INT,DECIMAL,FLOAT. - Исключайте строки с ошибочными значениями через
WHEREилиIS NOT NULL. - Не используйте
SUM()на строковых или логических полях.
Если нужно округлить результат:
SELECT ROUND(SUM(стоимость), 2) FROM услуги;Функция SUM() не модифицирует данные, её можно безопасно применять в подзапросах и представлениях.
Суммирование с условием через WHERE
Для подсчёта суммы значений с фильтрацией применяется конструкция SUM() в сочетании с оператором WHERE. Это позволяет учитывать только те строки, которые удовлетворяют заданному условию.
SELECT SUM(суммируемый_столбец) FROM имя_таблицы WHERE условие;– базовый синтаксис.- Условие может включать фильтрацию по дате, диапазону чисел, текстовым значениям, логическим флагам.
Примеры:
SELECT SUM(amount) FROM payments WHERE status = 'paid';– сумма только оплаченных платежей.SELECT SUM(price) FROM orders WHERE created_at >= '2024-01-01';– сумма заказов, сделанных с начала 2024 года.SELECT SUM(salary) FROM employees WHERE department_id = 5;– суммарная зарплата по отделу с ID 5.
Рекомендации:
- Для строк с возможными
NULL-значениями используйтеCOALESCE()внутриSUM(), чтобы избежать некорректных результатов. - При работе с датами всегда указывайте формат в ISO-стиле:
'YYYY-MM-DD'. - Фильтруйте до агрегирования – условия в
WHEREотрабатывают доSUM().
Для более сложной логики используйте CASE внутри SUM() вместо WHERE, если нужно агрегировать по нескольким условиям в одном запросе.
Суммирование значений по группам с GROUP BY
Оператор GROUP BY используется для агрегации данных по категориям. Его задача – разбить строки на группы и применить агрегатные функции к каждой из них отдельно. Чаще всего используется с функцией SUM() для подсчёта итогов по определённым признакам.
Пример: чтобы узнать суммарные продажи по каждому товару, используйте запрос:
SELECT product_id, SUM(amount) AS total_sales
FROM sales
GROUP BY product_id;Важно: все столбцы в SELECT, не обёрнутые агрегатной функцией, должны быть указаны в GROUP BY. Иначе запрос вызовет ошибку. Исключение составляют поля, определённые как функциональные зависимости в некоторых СУБД, например в PostgreSQL с GROUP BY с использованием выражений.
Для группировки по нескольким признакам используйте список столбцов:
SELECT region, product_id, SUM(amount) AS total
FROM sales
GROUP BY region, product_id;Убедитесь, что поля группировки соответствуют цели анализа. Ошибочная группировка может привести к некорректным результатам, особенно при наличии дубликатов или несогласованных данных.
Фильтрацию данных до группировки выполняйте с помощью WHERE, а после – через HAVING. Например, чтобы получить только те товары, у которых продажи превысили 1000:
SELECT product_id, SUM(amount) AS total
FROM sales
GROUP BY product_id
HAVING SUM(amount) > 1000;При использовании JOIN обращайте внимание на кратность соединения: дублирование строк перед GROUP BY может искусственно завысить сумму. Для точных расчётов предварительно проверьте результат JOIN.
Суммирование уникальных значений с DISTINCT
При необходимости суммировать только уникальные значения в столбце SQL-запроса используется комбинация функций SUM и DISTINCT. Такая конструкция применима, если требуется исключить дубликаты перед агрегированием. Синтаксис: SELECT SUM(DISTINCT column_name) FROM table_name;
Важно учитывать, что DISTINCT применяется только к значениям столбца, переданным в SUM. Если в таблице повторяются строки, но значения в указанном столбце различаются, они не будут удалены. Пример: при наличии значений 10, 10, 20, 30 результатом станет 60, а не 70.
Не стоит использовать DISTINCT без необходимости: он увеличивает нагрузку на сервер из-за предварительной сортировки или хеширования. Применяйте его только тогда, когда гарантировано наличие дубликатов, влияющих на итоговую сумму.
Если требуется учесть уникальные комбинации нескольких столбцов, DISTINCT используется внутри подзапроса: SELECT SUM(amount) FROM (SELECT DISTINCT user_id, amount FROM payments) AS uniq; Это позволяет агрегировать по уникальным парам значений, игнорируя повторы одной суммы от одного пользователя.
Использование DISTINCT в SUM уместно при расчёте уникальных затрат, доходов или других показателей, зависящих от исключения повторов. Проверяйте планы выполнения запросов для анализа производительности, особенно на больших объемах данных.
Обработка NULL при суммировании

Функция SUM() в SQL автоматически игнорирует значения NULL, поэтому они не влияют на итоговую сумму. Однако это может привести к искажению результатов, если NULL символизирует нулевое значение, а не отсутствие данных. Для точного подсчёта рекомендуется использовать функцию COALESCE(), подставляющую значение по умолчанию.
Пример:
SELECT SUM(COALESCE(стоимость, 0)) AS итого
FROM продажи;Если необходимо определить, сколько строк не участвовало в суммировании из-за NULL, используйте:
SELECT COUNT(*) - COUNT(стоимость) AS null_значения
FROM продажи;Если NULL сигнализирует об ошибке в данных, такие строки следует исключать явно:
SELECT SUM(стоимость)
FROM продажи
WHERE стоимость IS NOT NULL;Для анализа доли NULL в контексте всех записей:
SELECT
COUNT(стоимость) AS заполненные,
COUNT(*) AS всего,
COUNT(*) - COUNT(стоимость) AS пропущенные
FROM продажи;При объединении таблиц с возможными NULL значениями, важно учитывать тип соединения. LEFT JOIN может вернуть NULL при отсутствии соответствующих записей, что также скажется на сумме.
Суммирование после объединения таблиц через JOIN
При работе с несколькими связанными таблицами, использование оператора JOIN позволяет объединять данные для более детального анализа. Когда необходимо выполнить суммирование значений, важным шагом становится правильное использование агрегатных функций после объединения таблиц.
Для суммирования значений в объединённых таблицах следует использовать SQL-запрос с операторами JOIN и агрегатной функцией SUM(). Ключевым моментом является то, как влияет тип соединения на итоговые результаты. Рассмотрим пример, когда требуется суммировать данные о продажах из таблиц «orders» и «products», где «orders» содержит информацию о заказах, а «products» – данные о товарах.
Пример запроса:
SELECT p.product_name, SUM(o.amount) AS total_sales FROM orders o JOIN products p ON o.product_id = p.product_id GROUP BY p.product_name;
В этом запросе используется INNER JOIN, который возвращает только те строки, где существует совпадение между таблицами. Суммирование происходит по полю «amount», и результат группируется по наименованию товара. Это позволяет получить общую сумму продаж для каждого продукта.
Важно помнить, что при использовании LEFT JOIN, который включает все записи из левой таблицы и соответствующие записи из правой, могут появляться NULL-значения, если для некоторых товаров нет данных о продажах. Чтобы корректно обработать такие случаи, можно воспользоваться функцией COALESCE для замены NULL на 0, чтобы избежать ошибок при подсчете суммы.
Пример с LEFT JOIN:
SELECT p.product_name, COALESCE(SUM(o.amount), 0) AS total_sales FROM products p LEFT JOIN orders o ON p.product_id = o.product_id GROUP BY p.product_name;
В данном случае, даже если товар не был продан, в результирующей строке для него будет указано 0 вместо NULL. Это полезно, когда важно сохранить информацию обо всех товарах, независимо от наличия продаж.
Для выполнения суммирования после объединения таблиц важно внимательно следить за условиями соединения, чтобы избежать неправильных результатов, таких как дублирование строк или неправильное количество суммируемых значений. Всегда проверяйте данные и используйте корректные функции для обработки NULL-значений и других аномалий.
Сравнение SUM() с подзапросами
Функция SUM() и подзапросы в SQL выполняют схожие задачи, но их подходы к решению могут значительно отличаться по эффективности и сложности. SUM() используется для агрегации данных в пределах одного запроса, часто при фильтрации с условиями. Подзапросы же дают возможность выполнения дополнительной логики или сложных вычислений, но могут быть менее производительными, если их неправильно использовать.
При использовании SUM() агрегированные данные вычисляются непосредственно в основном запросе, что снижает накладные расходы на выполнение, так как исключаются дополнительные обращения к базе данных. Это делает SUM() предпочтительным вариантом в большинстве случаев, когда требуется просто посчитать сумму значений, например, при подсчете общего дохода по заказам в таблице продаж.
Подзапросы же могут использоваться для более сложных операций, например, если нужно агрегировать данные по подмножествах и затем сравнить их с другими значениями. В этом случае подзапросы могут быть полезными, но они увеличивают нагрузку на систему, поскольку каждый подзапрос выполняется отдельно и может вызывать повторные обращения к базе данных. Это может замедлить выполнение запроса при больших объемах данных.
Пример: если нужно посчитать сумму значений в столбце по определённым условиям, использование SUM() будет простым и быстрым решением:
SELECT SUM(sales_amount) FROM sales WHERE sale_date BETWEEN '2025-01-01' AND '2025-12-31';
Если же необходимо выполнить более сложное условие, например, фильтровать суммы по нескольким категориям в разных подзапросах, то подзапросы могут быть оправданы. Однако, в этом случае важно следить за производительностью, так как каждый подзапрос может выполнять дополнительные вычисления, что приводит к избыточным операциям:
SELECT (SELECT SUM(sales_amount) FROM sales WHERE product_category = 'A') AS category_a_sales, (SELECT SUM(sales_amount) FROM sales WHERE product_category = 'B') AS category_b_sales;
Таким образом, при простых задачах агрегации лучше использовать SUM() напрямую. Подзапросы стоит применять для более сложных вычислений, когда их использование оправдано логикой запроса, но следует учитывать возможные потери в производительности при больших объемах данных.
Суммирование в оконных функциях
Оконные функции в SQL позволяют производить агрегацию данных, не сводя их к единому результату. Для суммирования значений столбца внутри оконной функции используется оператор SUM(), который выполняет подсчёт суммы для каждой строки в окне, не изменяя структуру результата запроса.
Основное отличие оконной функции от обычной агрегации заключается в том, что результат не сводится к единой строке. Каждая строка сохраняет свою позицию, а функция работает в пределах заданного окна, которое может изменяться в зависимости от условий. Чтобы использовать суммирование с оконной функцией, необходимо определить окно с помощью OVER(), а также опционально указать параметры сортировки и разделения строк.
Пример использования суммы в оконной функции:
SELECT id, сумма, SUM(сумма) OVER (PARTITION BY категория ORDER BY дата) AS сумма_по_категории FROM продажи;
В данном примере вычисляется сумма по столбцу сумма для каждой строки с учётом разделения данных по категории и сортировки по дате. Это позволяет отслеживать накопленную сумму для каждой категории товаров, не сводя все данные к единой строке.
Если не указывать параметры сортировки или разделения, функция будет вычислять сумму по всему набору данных. Однако, в большинстве случаев, использование PARTITION BY и ORDER BY помогает получить более точные и информативные результаты.
Важно помнить, что оконные функции могут значительно повлиять на производительность при работе с большими наборами данных, так как они выполняются для каждой строки в окне. Оптимизация запросов с оконными функциями должна учитывать размер данных, а также индексы, которые могут ускорить выполнение агрегации.