Одной из распространённых проблем при работе с данными в SQL является наличие дубликатов, которые могут искажать результаты выборок и затруднять анализ информации. Удаление дубликатов – это не просто задача для улучшения внешнего вида данных, но и необходимая мера для обеспечения точности отчетности и оптимизации запросов. Важно понимать, что разные подходы к решению этой проблемы зависят от структуры базы данных и специфики запроса.
Основным инструментом для удаления дубликатов является оператор DISTINCT, который позволяет исключить повторяющиеся строки из результата выборки. Однако использование DISTINCT требует осторожности: на больших объемах данных его применение может замедлить выполнение запроса из-за дополнительных вычислительных затрат. В таких случаях целесообразно проанализировать, какие именно колонки вносят дублирование, и ограничить их число, что значительно повысит производительность.
Другим методом является использование GROUP BY, который, помимо удаления дубликатов, позволяет агрегировать данные. Этот подход подходит в тех случаях, когда необходимо не только устранить повторения, но и выполнить агрегацию по определённым критериям, например, посчитать сумму или среднее значение. Однако GROUP BY также имеет свои ограничения: например, не всегда удаётся сохранить все столбцы в их исходной форме, особенно если необходимо работать с данными, которые не участвуют в агрегации.
Если задачи удаления дубликатов связаны с модификацией данных, то на помощь приходит DELETE с использованием подзапросов. Этот метод позволяет выбрать только те строки, которые являются дубликатами, и удалить их, оставив оригинальные записи. Это может быть полезно в случаях, когда необходимо не просто исключить дубликаты из выборки, но и очистить таблицу от лишних записей.
Удаление дубликатов в SQL требует внимательности и понимания особенностей работы с данными. Важно не только выбрать правильный метод, но и учитывать специфику работы с конкретной СУБД, поскольку оптимизация запросов и индексация могут значительно повлиять на результаты.
Как удалить дубликаты с помощью оператора DISTINCT
Оператор DISTINCT в SQL используется для удаления дубликатов из выборки данных. При его применении запрос возвращает только уникальные строки, исключая повторяющиеся значения.
Простейший пример использования DISTINCT: если необходимо получить все уникальные значения из столбца, запрос может выглядеть так:
SELECT DISTINCT column_name FROM table_name;Этот запрос вернёт все уникальные значения в столбце column_name из таблицы table_name. Если же необходимо выбрать уникальные комбинации нескольких столбцов, можно указать их через запятую:
SELECT DISTINCT column1, column2 FROM table_name;В этом случае результат будет содержать только уникальные сочетания значений в столбцах column1 и column2.
Стоит помнить, что использование DISTINCT может снизить производительность при работе с большими таблицами, поскольку для вычисления уникальности SQL-серверу приходится выполнять дополнительные операции сортировки или хеширования данных. Поэтому важно учитывать размер таблицы и оптимизировать запросы, если требуется частое удаление дубликатов.
Также стоит отметить, что DISTINCT работает только на уровне строки. Если в таблице есть строка, где все значения одинаковы, то она будет возвращена только один раз, даже если дублируется по всем столбцам.
Для выполнения более сложных операций по удалению дубликатов можно сочетать DISTINCT с другими функциями SQL, например, с JOIN или GROUP BY, чтобы дополнительно агрегировать данные и устранять дубликаты на более глубоком уровне.
Использование GROUP BY для удаления повторяющихся строк
Использование оператора GROUP BY в SQL позволяет эффективно удалять повторяющиеся строки, агрегируя данные по указанным столбцам. Этот метод особенно полезен, когда требуется избавиться от дубликатов, не используя дополнительные средства, такие как DISTINCT или подзапросы.
При использовании GROUP BY SQL группирует строки с одинаковыми значениями в указанных столбцах в одну строку. Это позволяет агрегировать данные, устраняя их дублирование. Например, если в таблице содержатся несколько строк с одинаковыми значениями в столбцах «имя» и «фамилия», можно использовать GROUP BY, чтобы оставить только одну строку для каждой уникальной комбинации этих значений.
Пример запроса, который группирует данные по столбцам «имя» и «фамилия», и устраняет дубли:
SELECT имя, фамилия FROM сотрудники GROUP BY имя, фамилия;
В результате выполнения этого запроса для каждой уникальной пары «имя» и «фамилия» будет выведена только одна строка. Важно помнить, что при группировке можно использовать только те столбцы, которые включены в операторы агрегирования или перечислены в GROUP BY.
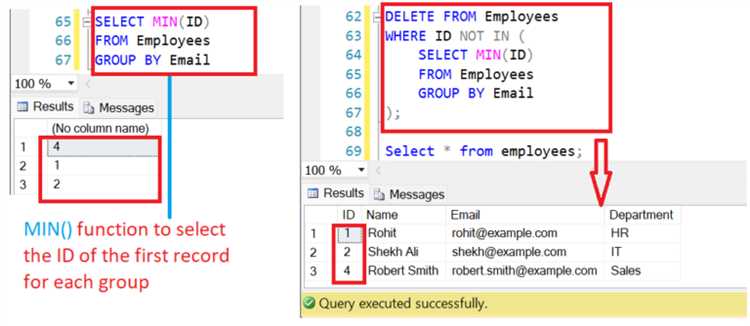
Этот метод имеет ограничение: он позволяет удалить только дубликаты, которые полностью совпадают по указанным столбцам. Если требуется удалить строки, где повторяется только часть данных, необходимо использовать дополнительные фильтры или агрегатные функции, такие как COUNT, MAX или MIN.
GROUP BY также полезен, когда нужно не только удалить дубликаты, но и произвести агрегацию данных. Например, можно вычислить сумму или среднее значение для каждой уникальной группы.
Пример с агрегированием данных:
SELECT имя, фамилия, COUNT(*) FROM сотрудники GROUP BY имя, фамилия;
Этот запрос покажет количество строк для каждой уникальной пары «имя» и «фамилия». Таким образом, GROUP BY можно использовать не только для удаления дубликатов, но и для более сложных анализов данных.
Основное преимущество метода заключается в его простоте и эффективности, особенно при работе с большими объемами данных, где другие методы могут быть менее производительными.
Как применить подзапросы для фильтрации дубликатов
Для эффективного удаления дубликатов с помощью подзапросов в SQL можно использовать различные подходы, в зависимости от структуры данных и требуемых результатов. Один из самых простых методов – использование подзапросов в сочетании с операторами сравнения.
Предположим, у нас есть таблица с заказами, в которой могут быть дублирующиеся записи. Для того чтобы оставить только уникальные записи, можно использовать подзапрос для фильтрации дубликатов по определённому столбцу. Пример запроса:
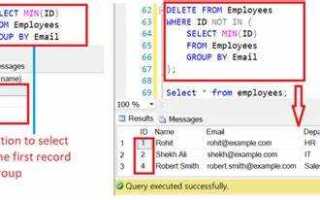
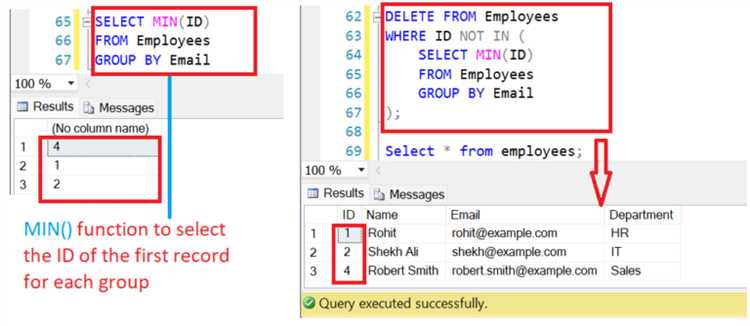
SELECT id, customer_id, order_date FROM orders WHERE order_date IN ( SELECT MIN(order_date) FROM orders GROUP BY customer_id );
В данном примере подзапрос выбирает минимальную дату для каждого клиента, и основной запрос возвращает все заказы, которые соответствуют этим датам. Это позволяет фильтровать только уникальные записи для каждого клиента.
Другим распространённым методом является использование подзапросов с конструкцией `DISTINCT`. Это позволяет выбирать уникальные значения в рамках подзапроса и исключать дубликаты в основной выборке. Пример:
SELECT DISTINCT customer_id, order_date FROM orders WHERE customer_id IN ( SELECT customer_id FROM orders GROUP BY customer_id HAVING COUNT(*) > 1 );
Этот запрос находит всех клиентов, у которых есть несколько заказов, и возвращает только уникальные пары `customer_id` и `order_date` для каждого из них. Такой подход эффективен, если требуется исключить дубли по нескольким столбцам.
Кроме того, использование подзапросов в разделе `FROM` может быть полезным для фильтрации дубликатов в более сложных запросах. Например, можно создать виртуальную таблицу, которая будет содержать только уникальные строки, а затем работать с этой таблицей:
SELECT t1.customer_id, t1.order_date FROM ( SELECT customer_id, order_date FROM orders GROUP BY customer_id, order_date ) AS t1;
В этом примере подзапрос в блоке `FROM` сначала сгруппирует данные, устраняя дубликаты, и только затем основной запрос извлекает необходимые поля.
При работе с подзапросами важно помнить, что сложные подзапросы могут существенно влиять на производительность, особенно при работе с большими объёмами данных. В таких случаях стоит внимательно следить за индексацией столбцов и оптимизацией запросов.
Удаление дубликатов с помощью оконных функций
Оконные функции в SQL позволяют эффективно обрабатывать дубликаты данных, не прибегая к использованию подзапросов или объединений. Для удаления дубликатов с помощью оконных функций часто используется функция ROW_NUMBER(), которая помогает нумеровать строки в пределах определённых окон.
Пример применения оконной функции ROW_NUMBER() для удаления дубликатов:
WITH RankedData AS ( SELECT *, ROW_NUMBER() OVER (PARTITION BY column1, column2 ORDER BY id) AS row_num FROM table_name ) DELETE FROM RankedData WHERE row_num > 1;
В данном примере:
PARTITION BYделит строки на группы, основываясь на значениях колонок, по которым нужно удалить дубликаты (например,column1иcolumn2);ROW_NUMBER()нумерует строки внутри каждой группы;- Запрос удаляет все строки, имеющие номер больше 1, то есть оставляет только уникальные записи по указанным колонкам.
Преимущества такого подхода:
- Меньше вычислительных ресурсов, чем при использовании традиционных способов с
DISTINCTилиGROUP BY; - Упрощённый код без необходимости создания временных таблиц или сложных объединений;
- Гибкость в удалении дубликатов на основе нескольких колонок с возможностью добавления условий сортировки.
Другой вариант – использование функции DENSE_RANK(), если необходимо сохранять все записи, но помечать их рангом. В дальнейшем можно удалить строки с определённым рангом.
WITH RankedData AS ( SELECT *, DENSE_RANK() OVER (PARTITION BY column1, column2 ORDER BY id) AS rank FROM table_name ) DELETE FROM RankedData WHERE rank > 1;
Это полезно, когда важно учитывать последовательность записей, но при этом избежать пропуска уникальных комбинаций данных.
Важно помнить, что использование оконных функций требует от базы данных достаточных ресурсов для обработки больших объёмов данных, особенно в случаях, когда таблицы содержат множество записей. Однако, при правильном применении, этот метод может существенно ускорить удаление дубликатов, не прибегая к сложным операциям.
Оптимизация SQL запросов для устранения дубликатов
Устранение дубликатов в SQL запросах критически важно для обеспечения эффективности работы с базой данных, особенно при больших объемах данных. Для оптимизации таких запросов необходимо учитывать несколько ключевых факторов: выбор метода устранения дубликатов, правильное использование индексов и анализ производительности запросов.
Первым шагом в оптимизации является использование оператора DISTINCT. Он позволяет выбрать уникальные строки, исключая дубликаты на уровне результата. Однако важно понимать, что DISTINCT может быть дорогостоящим с точки зрения производительности, особенно если применяется к большим таблицам. Чтобы снизить нагрузку на сервер, лучше ограничить его использование только теми столбцами, по которым действительно необходима уникальность, а не ко всем столбцам таблицы.
Для более эффективного устранения дубликатов в больших данных можно использовать оператор GROUP BY, который группирует строки по указанным столбцам. Это полезно, когда нужно не просто исключить дубликаты, но и агрегировать данные, например, для подсчета суммы или среднего значения. В случае группировки важно индексировать столбцы, по которым происходит группировка, что ускоряет выполнение запроса.
Если необходимо удалить дубликаты в самой таблице, рекомендуется использовать подзапросы с операторами ROW_NUMBER(), RANK() или DENSE_RANK(). Эти функции позволяют нумеровать строки и отфильтровывать только уникальные значения, оставляя одну строку с минимальным или максимальным номером. Пример запроса:
WITH cte AS ( SELECT *, ROW_NUMBER() OVER (PARTITION BY column_name ORDER BY column_name) AS rn FROM table_name ) DELETE FROM cte WHERE rn > 1;
Этот подход позволяет не только удалить дубликаты, но и более точно контролировать, какие строки остаются. Кроме того, важно использовать индексы на столбцы, по которым осуществляется фильтрация или группировка, чтобы повысить скорость выполнения таких операций.
Другим методом для предотвращения появления дубликатов является использование уникальных индексов. Если данные в таблице должны быть уникальными по определенным столбцам, создание уникального индекса на этих столбцах поможет избежать повторений при вставке новых строк. Индексы не только обеспечивают уникальность, но и значительно ускоряют поиск и удаление дубликатов.
Также стоит учитывать, что использование JOIN для объединения таблиц может привести к появлению дубликатов, если ключи объединения не уникальны. В таких случаях стоит использовать INNER JOIN или LEFT JOIN в сочетании с дополнительными условиями, чтобы минимизировать вероятность повторения строк в результате.
Наконец, всегда следует мониторить выполнение запросов. Использование EXPLAIN PLAN позволяет анализировать, какие части запроса являются узкими местами, и как они влияют на производительность. Регулярный анализ и оптимизация запросов с устранением дубликатов являются важной частью эффективной работы с базой данных.
Как избежать появления дубликатов при вставке данных в таблицу
Для предотвращения появления дубликатов при вставке данных в таблицу необходимо грамотно использовать возможности SQL и конструкции, которые позволяют минимизировать вероятность вставки одинаковых строк. Вот несколько методов, которые помогут достичь этой цели:
1. Использование уникальных ограничений (UNIQUE)
Одним из самых эффективных способов защиты от дубликатов является создание уникальных ограничений на столбцы, которые должны содержать только уникальные значения. Например, можно определить уникальные ключи для столбцов, таких как email или номер телефона, чтобы избежать дублирования этих данных при вставке:
CREATE TABLE users ( id INT PRIMARY KEY, email VARCHAR(255) UNIQUE, phone VARCHAR(20) UNIQUE );
Если будет попытка вставить строку с уже существующим значением в столбец, уникальное ограничение предотвратит это.
2. Использование оператора INSERT IGNORE
Оператор INSERT IGNORE позволяет вставить данные, если они не нарушают уникальные ограничения. В случае нарушения уникальности запрос просто игнорирует вставку, не приводя к ошибке. Это удобно, когда необходимо избежать появления дубликатов, но при этом не останавливать выполнение запроса.
INSERT IGNORE INTO users (email, phone) VALUES ('user@example.com', '1234567890');
3. Использование оператора ON DUPLICATE KEY UPDATE
Если вы хотите не только избежать дубликатов, но и обновить данные, если они уже существуют, можно использовать конструкцию ON DUPLICATE KEY UPDATE. Этот метод позволяет обновлять существующие записи вместо их повторной вставки:
INSERT INTO users (email, phone)
VALUES ('user@example.com', '1234567890')
ON DUPLICATE KEY UPDATE phone = VALUES(phone);
В этом примере, если запись с таким email уже существует, будет обновлен номер телефона, а не добавлена новая строка.
4. Проверка на дубликаты перед вставкой
Иногда бывает полезно заранее проверить, существует ли запись с такими же данными в базе. Для этого можно использовать запрос SELECT, который проверит наличие дубликатов перед вставкой. Если данные уже есть, вставка не происходит:
SELECT 1 FROM users WHERE email = 'user@example.com' LIMIT 1;
Если результат запроса пустой, можно выполнить вставку. Такой подход особенно полезен в случаях, когда нет уникальных ограничений на столбцы, но необходимо предотвратить дублирование.
5. Использование транзакций для контроля последовательности операций
В некоторых случаях, когда вставка данных происходит в несколько шагов или в несколько таблиц, стоит использовать транзакции. Это позволяет контролировать последовательность операций и откатывать изменения в случае ошибок, включая попытки вставки дубликатов. При этом важно обрабатывать ошибки на уровне транзакций, чтобы избежать случайного дублирования данных.
Используя эти методы, можно эффективно предотвратить появление дубликатов в базе данных, обеспечив целостность и уникальность данных при их вставке.
Вопрос-ответ:
Что такое дубликаты в SQL запросах и почему их нужно удалять?
Дубликаты в SQL запросах — это строки, которые повторяются в результате выполнения запроса. Например, при извлечении данных из таблиц с одинаковыми значениями в некоторых столбцах, запрос может вернуть несколько одинаковых строк. Удаление дубликатов важно для получения уникальных значений в выборке и улучшения читаемости данных. Кроме того, оно позволяет сократить объем передаваемых данных, что может повлиять на производительность запросов.
Как влияет наличие дубликатов на производительность SQL запросов?
Наличие дубликатов в базе данных может негативно сказаться на производительности SQL запросов, особенно если запросы возвращают большой объем данных. Дублирующиеся строки увеличивают объем передаваемых данных, что ведет к более длительному времени отклика и большему использованию ресурсов сервера. Удаление дубликатов помогает уменьшить нагрузку на систему, улучшить время выполнения запросов и снизить избыточность данных в базе.