Извлечение текста из изображений, таких как сканы или фото, становится необходимостью в различных сферах деятельности. Для этого используется технология оптического распознавания символов (OCR), которая позволяет преобразовать текст на изображении в редактируемый формат. Одним из самых удобных способов является использование бесплатных и платных OCR-сервисов, а затем вставка извлечённого текста в Word-документ для дальнейшей работы.
Первым шагом является выбор инструмента для распознавания текста. Программное обеспечение, например, Adobe Acrobat или онлайн-сервисы, такие как Online OCR или Google Docs, предоставляют удобные способы извлечения текста. Важно выбирать сервисы, которые поддерживают обработку различных языков и могут распознавать текст с минимальными ошибками. Для повышения точности распознавания рекомендуется использовать изображения высокого качества с четким контрастом между текстом и фоном.
После распознавания текста необходимо вставить его в Word. Один из простых способов – это копирование текста из OCR-сервиса и вставка его в открытый документ. Однако, чтобы избежать ошибок форматирования, лучше использовать функции импорта текста из файла, который сохраняется в формате .txt или .docx. Это поможет избежать разрывов строк и других нежелательных искажений.
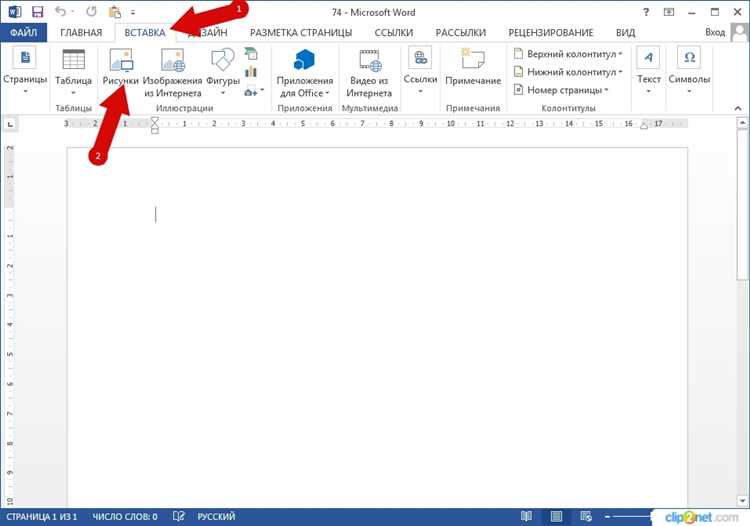
При вставке текста важно также проверять его на наличие ошибок. В OCR-технологиях могут встречаться погрешности, особенно если текст на изображении плохо различим. Рекомендуется использовать встроенные в Word инструменты для проверки орфографии и грамматики, а также вручную пройтись по документу для обнаружения возможных неточностей.
Выбор инструмента для извлечения текста из изображения
При выборе инструмента для извлечения текста с изображения важно учитывать несколько факторов, таких как точность, удобство использования и доступность различных функций. В зависимости от задачи можно выбрать одно из нескольких решений.
Для простых задач, например, если требуется извлечь текст с фотографии документа, оптимальным выбором станут онлайн-сервисы с функцией OCR (Оптическое Распознавание Символов). К примеру, Google Docs предлагает встроенную возможность распознавания текста из изображений при загрузке файла. Этот инструмент подойдет для большинства стандартных задач, но может не справляться с текстами, написанными нестандартным шрифтом или плохо видимыми на изображении.
Если вам требуется высокая точность и возможность работы с многоязычными документами, стоит обратить внимание на более специализированные программы, такие как ABBYY FineReader. Это решение может работать с различными языками, а также имеет инструменты для корректировки и форматирования текста после извлечения, что особенно полезно для сложных документов.
Для более профессиональной работы с изображениями, например, сканами или фотографиями с мелким текстом, подойдут инструменты с функциями улучшения качества изображения перед распознаванием. Программы типа Tesseract, открытый инструмент с поддержкой множества языков, позволяют настроить параметры распознавания и значительно повысить точность извлечения текста.
При использовании мобильных устройств удобным выбором станет приложение Microsoft Office Lens или Adobe Scan. Эти приложения автоматически обрезают изображения и настраивают их для лучшего распознавания, что существенно ускоряет процесс извлечения текста.
Выбор инструмента зависит от конкретных требований: если нужна высокая точность и работа с нестандартными шрифтами – лучше использовать специализированные программы, такие как ABBYY FineReader. Для базовых задач и работы с текстами без сложных элементов идеально подойдут онлайн-сервисы и мобильные приложения.
Как использовать бесплатные онлайн-сервисы для распознавания текста
Для распознавания текста с изображений онлайн существует множество бесплатных сервисов. Они позволяют извлечь текст за несколько шагов, не требуя установки дополнительных программ. Вот несколько популярных решений, которые стоит использовать:
- FreeOCR – простое и удобное средство для конвертации изображений в текст. Бесплатная версия поддерживает ограничение на 10 страниц, что подходит для небольших задач. Есть поддержка русского языка, а также возможность загрузки файлов через Google Drive.
- Google Docs – Google имеет встроенную функцию OCR. Для этого нужно загрузить изображение в Google Drive, затем открыть его с помощью Google Docs. Текст будет распознан и выведен в документ, что позволяет сразу редактировать и сохранять его в нужном формате.
- OCR.space – бесплатный сервис с хорошей поддержкой русского языка. Позволяет работать как с изображениями, так и с PDF-файлами. Результаты можно скачать в различных форматах, включая Word и текстовые файлы.
При использовании онлайн-сервисов важно учитывать несколько нюансов:
- Качество изображения – чем четче изображение, тем выше вероятность правильного распознавания. Размытые или слишком маленькие изображения могут привести к ошибкам.
- Поддержка языка – не все сервисы поддерживают русский язык на высоком уровне. Перед загрузкой изображения убедитесь, что выбран правильный язык для распознавания текста.
Используя эти онлайн-сервисы, вы сможете быстро и удобно извлечь текст из изображений и вставить его в Word для дальнейшей обработки.
Использование OCR-программ для извлечения текста с помощью ПК
Оптическое распознавание символов (OCR) позволяет извлекать текст из изображений и документов с помощью ПК. Для этого необходимо использовать специальные OCR-программы, которые применяют алгоритмы машинного обучения для распознавания текста на изображениях. Среди популярных решений – ABBYY FineReader, Tesseract, и Google Docs OCR.
ABBYY FineReader является одним из самых точных коммерческих OCR-инструментов. Он поддерживает работу с множеством форматов изображений, включая PDF и фотографии, и способен распознавать более 190 языков. FineReader предлагает удобный интерфейс и позволяет извлекать текст в форматах Microsoft Word, Excel, а также создавать редактируемые PDF-документы.
Tesseract – это открытая OCR-библиотека, разработанная Google. Она поддерживает множество языков, но требует определённых технических знаний для настройки. Tesseract может работать с изображениями в разных форматах и имеет возможность интеграции с другими программами и скриптами для автоматизации процесса распознавания.
Google Docs OCR встроен в сервис Google Диск и позволяет извлекать текст из изображений с помощью облачных технологий. Для этого достаточно загрузить картинку в Google Диск, открыть её через Google Документы, и система автоматически распознает текст, который затем можно редактировать и сохранить в нужном формате.
Чтобы добиться максимальной точности распознавания, важно учитывать качество исходного изображения. Оптимальные условия для OCR – это чёткие изображения с хорошим контрастом, без размытия и с минимальными искажениями. В случае если изображение содержит сложный фон или текст в нестандартном шрифте, может потребоваться дополнительная обработка перед распознаванием, например, увеличение контраста или использование специализированных фильтров для улучшения качества.
После извлечения текста с помощью OCR-программы его можно вставить в Microsoft Word или любой другой текстовый редактор. Важно проверить результат, так как распознавание текста может быть не всегда идеальным, особенно если на изображении присутствуют ошибки, тени или сложные элементы.
Как обработать сканированные документы и фотографии с помощью Google Docs
Google Docs позволяет извлекать текст из изображений и сканированных документов с помощью встроенной функции OCR (оптическое распознавание символов). Это особенно полезно, когда необходимо обработать не только фотографии, но и PDF-файлы с текстовыми сканами.
Для начала загрузите файл в Google Диск. Перетащите изображение или PDF в нужную папку. После этого щелкните правой кнопкой мыши по файлу и выберите «Открыть с помощью» > «Google Документы». Этот шаг активирует автоматическое распознавание текста.
Google Docs обрабатывает изображение или сканированную страницу, пытаясь выделить все текстовые элементы. После обработки вы увидите документ с изображением вверху страницы и распознанным текстом под ним. Процесс может занять от нескольких секунд до минуты в зависимости от сложности изображения и качества сканирования.
Для повышения точности распознавания используйте высококачественные сканы с четким текстом. Если файл содержит несколько страниц, Google Docs распознает текст на каждой странице, но результат может быть не идеальным, особенно при низком качестве исходных файлов.
Обработанный текст можно редактировать, форматировать и сохранять в различных форматах, включая Microsoft Word, PDF и другие. Для этого достаточно выбрать «Файл» > «Скачать» и выбрать нужный формат.
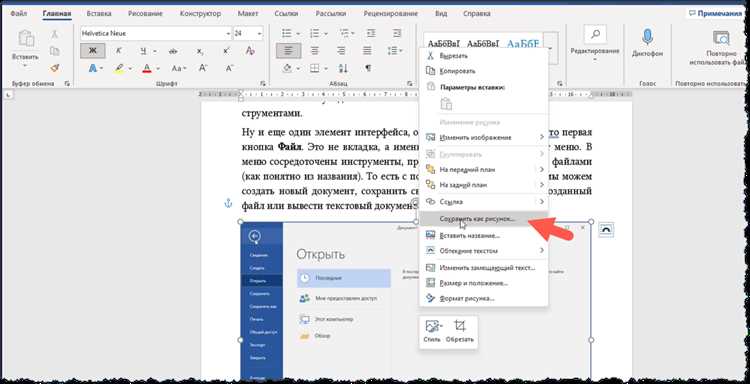 «Скачать» и выбрать нужный формат.»>
«Скачать» и выбрать нужный формат.»>
Если текст на изображении распознается некорректно, вручную отредактируйте его в Google Docs. Возможности OCR ограничены, особенно при наличии сложных шрифтов, рукописного текста или сильных искажений изображения.
Таким образом, Google Docs – это простой и эффективный инструмент для обработки сканированных документов и фотографий. С его помощью можно быстро извлечь текст и преобразовать его в редактируемый формат без использования сложных программных решений.
Как вставить извлечённый текст в Microsoft Word и отформатировать его
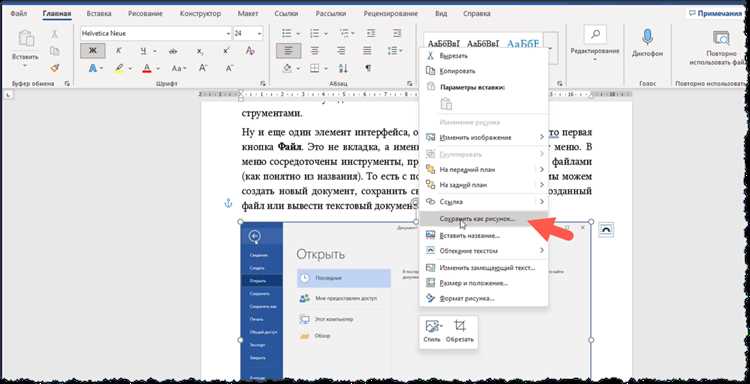
Сначала откройте Microsoft Word и создайте новый документ или выберите уже существующий. После этого вставьте извлечённый текст, используя стандартную команду «Вставить» (Ctrl + V) или через меню правой кнопки мыши. Важно, чтобы текст был правильно скопирован и не содержал артефактов распознавания, таких как случайные символы или ошибки OCR.
После вставки текста в документ, вам стоит обратить внимание на форматирование. В большинстве случаев, текст будет вставлен без какого-либо стиля или шрифта, что требует настройки. Для этого выберите весь вставленный текст (Ctrl + A) и примените нужный стиль шрифта, размер и межстрочный интервал. Рекомендуется использовать стандартный шрифт, такой как Calibri или Times New Roman, с размером 12 и межстрочным интервалом 1.5 для улучшения читаемости.
Если текст из картинки был вставлен с сохранением абзацев и структуры, важно удостовериться, что каждый абзац отделён корректным интервалом. Для этого можно использовать команду «Интервал» в меню «Главная» для точной настройки расстояния между абзацами.
Для улучшения структуры документа стоит использовать функции нумерации и списков, если в исходном тексте присутствуют пункты или элементы, требующие упорядочивания. Вставьте нумерацию или маркированный список с помощью кнопок на панели инструментов «Нумерация» или «Маркеры».
Не забывайте о проверке орфографии и грамматики. Даже если OCR распознал текст с высокой точностью, всегда стоит запустить встроенную проверку ошибок, чтобы избежать возможных опечаток или некорректных символов.
После выполнения этих шагов, текст будет готов к дальнейшему использованию. Если документ требует дополнительного оформления, например, заголовков, сносок или ссылок, используйте стандартные инструменты Word для добавления соответствующих элементов.
Вопрос-ответ:
Как извлечь текст из картинки и вставить его в Word?
Для извлечения текста из изображения можно использовать технологию оптического распознавания символов (OCR). Один из самых удобных способов – воспользоваться онлайн-сервисами или специальными приложениями. Например, можно загрузить картинку на сервис Google Docs или использовать программы, такие как ABBYY FineReader. После того как текст будет распознан, его можно скопировать и вставить в документ Word.
Что такое OCR и как оно помогает извлечь текст из картинки?
OCR (Optical Character Recognition) — это технология, которая позволяет преобразовывать текст, изображённый на картинках, в редактируемый текст. Это особенно полезно, когда нужно быстро скопировать информацию с отсканированных документов или фотографий. Программы для OCR анализируют картинку, распознают символы и переводят их в текстовый формат, который можно вставить в Word.
Какие программы для извлечения текста из картинок подходят для Windows?
Для пользователей Windows есть несколько хороших программ для извлечения текста с изображений. Одной из самых популярных является ABBYY FineReader, которая поддерживает множество языков и форматов. Также можно использовать программу Microsoft OneNote — она имеет встроенную функцию OCR для распознавания текста на изображениях. Бюджетными вариантами могут стать такие программы, как FreeOCR или SimpleOCR, которые тоже выполняют задачу распознавания символов.
Можно ли использовать Google Docs для распознавания текста с изображений?
Да, Google Docs имеет встроенную функцию OCR, которая позволяет извлекать текст из изображений. Для этого нужно загрузить изображение в Google Диск, открыть его с помощью Google Docs, и сервис автоматически попытается распознать текст на картинке. После этого текст появится в документе, и его можно будет скопировать в Word.
Какие сложности могут возникнуть при извлечении текста с изображений?
Основная сложность заключается в том, что качество распознавания зависит от четкости изображения и качества текста на картинке. Например, если текст на фотографии размытый или искажённый, программа может не распознать его корректно или сделать ошибки. Кроме того, шрифты, нестандартные символы или текст, написанный от руки, могут вызвать трудности. В таких случаях потребуется дополнительная проверка и редактирование извлечённого текста.
Как извлечь текст из картинки и вставить его в документ Word?
Для извлечения текста из картинки можно использовать функцию оптического распознавания символов (OCR). Сначала загрузите изображение с текстом в программу, которая поддерживает OCR, например, Adobe Acrobat, OneNote или онлайн-сервисы вроде Online OCR. После того как программа распознает текст, его можно скопировать и вставить в Word. Важно, чтобы текст на картинке был чётким, без искажений, иначе результат может быть не точным.
Какие программы можно использовать для распознавания текста с картинок, чтобы потом вставить его в Word?
Для распознавания текста с картинок можно использовать несколько популярных программ. Например, Google Docs предлагает функцию OCR: загрузите картинку в Google Диск, откройте её через Google Docs, и система автоматически распознает текст, который можно скопировать в Word. Также удобны программы типа ABBYY FineReader или OneNote, которые поддерживают распознавание и позволяют копировать текст в любой текстовый редактор, включая Word. Выбор программы зависит от точности распознавания и ваших предпочтений по интерфейсу.