Перевод отсканированного документа в формат Word – задача, которая становится актуальной при необходимости редактирования или переработки текста. Простое сканирование документа сохраняет его в виде изображения, что затрудняет дальнейшую работу. Однако существует несколько проверенных способов извлечь текст и преобразовать его в редактируемый формат.
Для успешного преобразования нужно использовать технологию оптического распознавания текста (OCR). OCR-программы анализируют изображение и выделяют текстовые элементы, преобразуя их в редактируемый формат. Важно помнить, что качество распознавания зависит от разрешения сканирования, качества оригинала и используемой программы. Рекомендуется сканировать документ с разрешением не менее 300 dpi для оптимальных результатов.
Существует несколько популярных инструментов для конвертации отсканированных документов в Word. Среди них выделяются как платные, так и бесплатные решения. Например, Adobe Acrobat Pro обладает встроенной функцией OCR и позволяет сохранить текст в формате .docx. Бесплатные онлайн-сервисы, такие как Online OCR, также могут быть полезны для небольших проектов, однако их функциональность ограничена по сравнению с профессиональными программами.
При выборе инструмента важно учитывать не только стоимость, но и требования к точности распознавания. В случае сложных документов, содержащих нестандартные шрифты или графику, может понадобиться дополнительная ручная корректировка текста после распознавания. Это позволит избежать ошибок и гарантировать точность данных в итоговом документе.
Как выбрать программу для распознавания текста с отсканированного документа
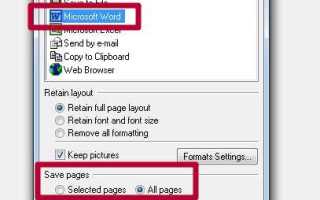
При выборе программы для распознавания текста с отсканированного документа важно учитывать несколько ключевых факторов: точность распознавания, поддержка форматов, скорость обработки и удобство интерфейса.
Точность распознавания – это главный параметр. Современные программы используют различные алгоритмы машинного обучения и нейросети для повышения точности. Обратите внимание на программы, которые поддерживают OCR (оптическое распознавание символов) на русском языке, так как это критично для корректного распознавания кириллицы. Некоторые инструменты могут ошибаться в сложных шрифтах или при плохом качестве сканированного документа. Программы как ABBYY FineReader или Tesseract обеспечивают высокую точность при распознавании текстов даже с поврежденных или низкокачественных изображений.
Поддержка форматов играет важную роль, если вам нужно не только распознать текст, но и преобразовать его в различные форматы, такие как Word, PDF, Excel или RTF. Программы, такие как Adobe Acrobat или FineReader, позволяют сохранять результаты в нужном формате с минимальными потерями в структуре документа.
Скорость обработки может варьироваться в зависимости от объема документа и мощности вашего устройства. Некоторые программы оптимизированы для работы с большими файлами, например, FineReader, а другие могут быть более медленными на больших объемах текста, но удобны для использования на личных компьютерах с ограниченными ресурсами, например, Tesseract или FreeOCR.
Удобство интерфейса и наличие дополнительных функций, таких как автоматическое разделение текста и изображений, поддержка многостраничных документов и интеграция с другими приложениями, значительно упрощают процесс работы. Оцените, насколько легко настраивать программу под свои нужды, и можно ли настраивать параметры распознавания для конкретных типов документов.
Если для вас важна бесплатность, рассмотрите варианты, такие как Tesseract, который является открытым исходным кодом. Однако для более высококачественного и удобного опыта работы с документами лучше выбрать коммерческие решения, такие как ABBYY FineReader, которые предлагают дополнительные функции, такие как редактирование текста и создание многостраничных документов.
Как использовать онлайн-сервисы для конвертации сканов в Word
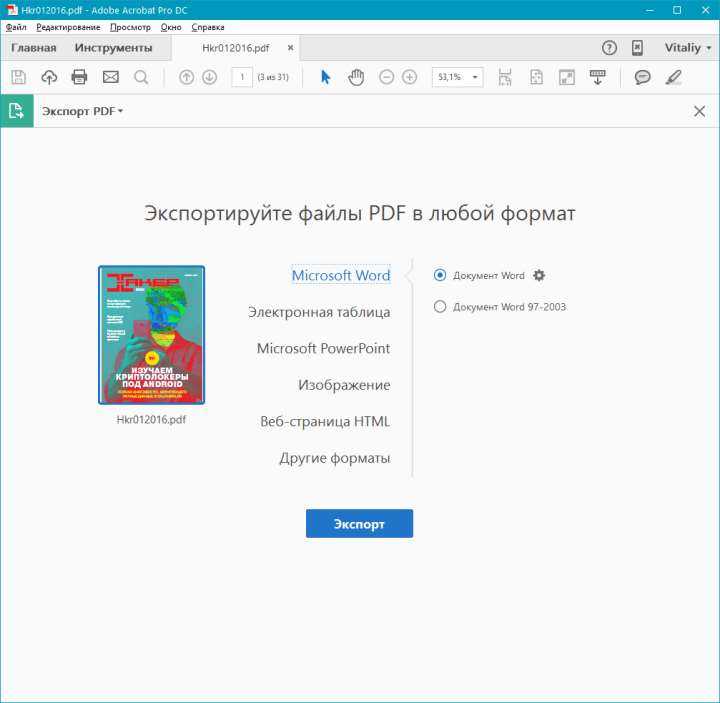
Онлайн-сервисы позволяют быстро и удобно преобразовать отсканированные документы в формат Word без необходимости установки дополнительных программ. Для этого используется технология оптического распознавания текста (OCR), которая извлекает текст из изображений и сохраняет его в редактируемом виде. Вот как это сделать эффективно:
Шаг 1. Выбор подходящего онлайн-сервиса. Существует множество бесплатных и платных платформ, предоставляющих OCR-услуги. Среди популярных – OnlineOCR, iLovePDF, OCR.space, Smallpdf. Все они поддерживают различные форматы изображений, включая PDF и JPG.
Шаг 2. Загрузка документа. После выбора сервиса, загрузите файл на сайт. Обычно доступна возможность перетаскивания файла в окно браузера или использование кнопки «Загрузить». Убедитесь, что качество изображения достаточно высокое, чтобы OCR мог корректно распознать текст.
Шаг 4. Конвертация и скачивание. Нажмите кнопку для начала процесса распознавания. После завершения конвертации скачайте файл в формате Word. Ожидайте, что процесс может занять несколько минут в зависимости от размера и сложности документа.
Шаг 5. Проверка результата. После загрузки файла откройте его в Microsoft Word или Google Docs. Оцените точность распознавания: текст может требовать минимальной корректировки, особенно если скан был не идеален. Обратите внимание на особенности шрифтов, форматирование и наличие ошибок.
Онлайн-сервисы для OCR идеально подходят для быстрого преобразования сканов в редактируемые документы. Однако стоит помнить, что бесплатные версии часто имеют ограничения по размеру файла или количеству использований в день. Если нужно обрабатывать большое количество документов или работать с конфиденциальной информацией, стоит рассмотреть платные опции с расширенными возможностями и повышенной безопасностью.
Как настроить параметры OCR для лучшего распознавания текста
Для достижения оптимальных результатов при распознавании текста важно правильно настроить параметры OCR. Вот основные рекомендации:
1. Выбор языка распознавания. Убедитесь, что выбран язык документа соответствует языку текста, который нужно распознать. Большинство OCR-программ позволяют загрузить дополнительные языковые пакеты. Это обеспечит точность распознавания, особенно для языков с особыми символами и знаками препинания.
2. Разрешение изображения. Чем выше разрешение исходного документа, тем точнее будет распознавание. Для текстовых документов минимальное рекомендуемое разрешение – 300 DPI. Разрешение ниже этого может привести к ошибкам при распознавании символов и искажению текста.
3. Предварительная обработка изображения. Использование фильтров для улучшения качества изображения перед его распознаванием значительно улучшает результаты. Увлажнение или коррекция контраста помогает выделить текст, что позволяет OCR-алгоритмам точнее воспринимать символы. Применение функции «Удаление шума» особенно важно для сканов низкого качества.
4. Выбор подходящего шрифта. OCR технологии лучше справляются с распознаванием стандартных шрифтов. Шрифты, скапливающиеся или слипающиеся буквы могут снижать точность. Желательно использовать шрифты с четкими и раздельными символами. Например, шрифты без засечек (Arial, Helvetica) легче поддаются распознаванию.
5. Настройки ориентации текста. Убедитесь, что документ не имеет искажений или наклонов. Некоторые OCR-системы могут автоматически корректировать наклон, но в некоторых случаях это может не сработать, особенно при сложных поворотах. Настроив автоматическое выравнивание, можно значительно повысить точность распознавания.
6. Разделение текста и изображений. В OCR-системах часто присутствует опция отделения текста от изображений на странице. Если ваш документ содержит изображения, убедитесь, что программное обеспечение настроено на распознавание только текстовых областей, чтобы избежать ошибок в процессе обработки.
7. Использование нескольких режимов распознавания. В некоторых OCR-программах доступны различные режимы распознавания в зависимости от типа документа. Для текстов, содержащих таблицы или диаграммы, стоит выбрать соответствующий режим, который позволяет обрабатывать такие элементы с минимальными ошибками.
8. Постобработка результатов. Некоторые OCR-программы включают функции проверки орфографии и предложений по исправлению ошибок после распознавания текста. Включив эту опцию, можно дополнительно повысить точность перевода изображения в текстовый формат.
Правильная настройка параметров OCR помогает значительно улучшить качество распознавания, снижая количество ошибок и улучшая форматирование результата.
Что делать, если текст не распознается или отображается некорректно
Если текст не распознается или отображается некорректно при попытке перевести отсканированный документ в формат Word, возможны несколько причин этой проблемы. Важно сразу исключить очевидные ошибки и провести несколько проверок.
1. Плохое качество сканирования
Первое, что стоит проверить – это качество исходного изображения. Низкое разрешение (менее 300 dpi) часто приводит к тому, что OCR (оптическое распознавание символов) не может точно распознать символы. Чтобы улучшить результат, отсканируйте документ снова, установив разрешение на 300 dpi или выше. Также важно, чтобы текст был четким, без размытостей и искажений.
2. Проблемы с шрифтами
Если текст распознается некорректно, возможно, OCR не поддерживает шрифт, используемый в документе. Попробуйте заменить нестандартные шрифты на более распространенные, такие как Arial, Times New Roman или Calibri. Это повысит вероятность успешного распознавания.
3. Использование специализированных OCR-программ
Стандартные бесплатные OCR-сервисы могут не всегда справляться с задачей. Если вы сталкиваетесь с проблемами, стоит попробовать профессиональные решения, такие как ABBYY FineReader или Adobe Acrobat Pro, которые предлагают более точное распознавание, особенно для документов с различными шрифтами, диаграммами или сложными макетами.
4. Проверьте язык документа
Ошибка в языке документа может быть одной из причин неудачного распознавания текста. Например, если документ на русском языке, а программа распознавания настроена на английский, результат будет искаженным. Убедитесь, что выбран правильный язык распознавания в настройках программы.
5. Откорректируйте результат вручную
Даже при использовании самых продвинутых OCR-систем текст может содержать ошибки. После распознавания внимательно проверьте полученный документ и устраните все ошибки. Особенно это касается чисел, знаков препинания и специальных символов, которые могут быть неправильно интерпретированы.
6. Обработка документов с рукописным текстом
OCR технологии, как правило, не справляются с распознаванием рукописного текста. Если на вашем документе присутствуют такие элементы, лучше воспользоваться специализированными сервисами для распознавания рукописных букв, например, Microsoft OneNote или Google Keep. В таких случаях также может потребоваться дополнительная ручная корректировка.
7. Использование других форматов
Если OCR все же не помогает, возможно, стоит попробовать другие методы перевода сканированного документа. Например, конвертировать его в формат PDF, а затем использовать онлайн-инструменты для преобразования PDF в Word. Это может привести к лучшему результату в случае некоторых типов документов.
Как исправить ошибки в документе после конвертации
После конвертации отсканированного документа в формат Word могут возникать различные ошибки, связанные с распознаванием текста. Вот несколько эффективных методов исправления этих ошибок.
- Исправление ошибок OCR: Программы для оптического распознавания текста (OCR) могут неправильно интерпретировать символы, особенно если качество сканирования низкое. Внимательно проверьте каждое слово на наличие пропусков или неверно распознанных букв. Используйте функции проверки орфографии и грамматики в Word для ускорения процесса.
- Проблемы с форматированием: Иногда форматирование документа нарушается при конвертации. Например, абзацы могут быть разделены, или интервалы между строками становятся слишком большими. Для исправления этого откройте вкладку «Разметка страницы» и вручную отрегулируйте интервалы и отступы.
- Решение проблем с изображениями: Если в документе были изображения, их расположение или размер могут нарушиться. Для исправления перетащите изображения в нужное место или измените их размер вручную, используя вкладку «Вставка» – «Изображения».
- Удаление лишних символов: Иногда в результате конвертации появляются лишние символы, такие как знаки препинания или случайные буквы. Проверьте каждую строку на наличие таких ошибок и удалите их вручную.
- Исправление таблиц: Если в исходном документе были таблицы, то в Word они могут быть представлены в виде текста или плохо отформатированных ячеек. Перейдите в раздел «Вставка» и создайте таблицу заново, а затем вставьте данные в нужные ячейки.
- Проверка шрифтов и стилей: При конвертации часто теряется стиль шрифта или используются не те шрифты. Для того чтобы исправить этот момент, выберите весь текст и примените нужный стиль шрифта и размер через вкладку «Главная».
- Исправление числовых ошибок: Если документ содержит числовые данные, особенно даты или номера, проверьте их на наличие ошибок. OCR может неверно распознать цифры или символы. Замените все неверно распознанные числа вручную.
Применяя эти методы, можно значительно улучшить качество документа после конвертации и получить документ с правильным форматированием и текстом без ошибок.
Как сохранить отсканированный документ в формат Word с соблюдением форматирования
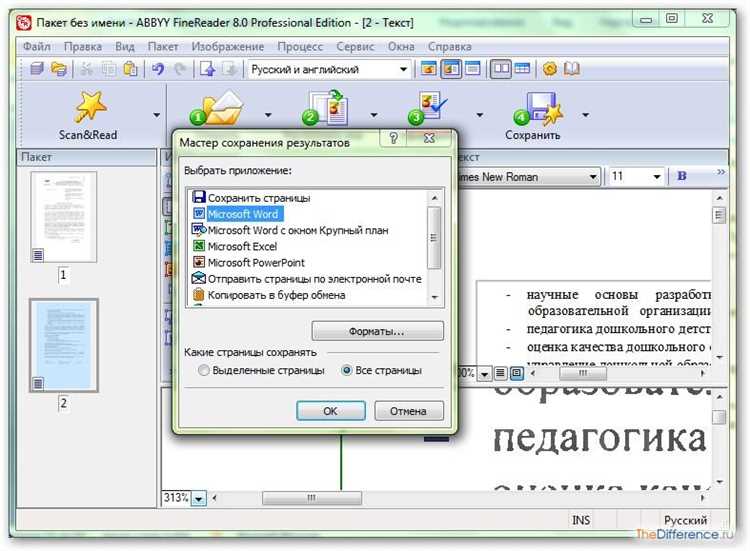
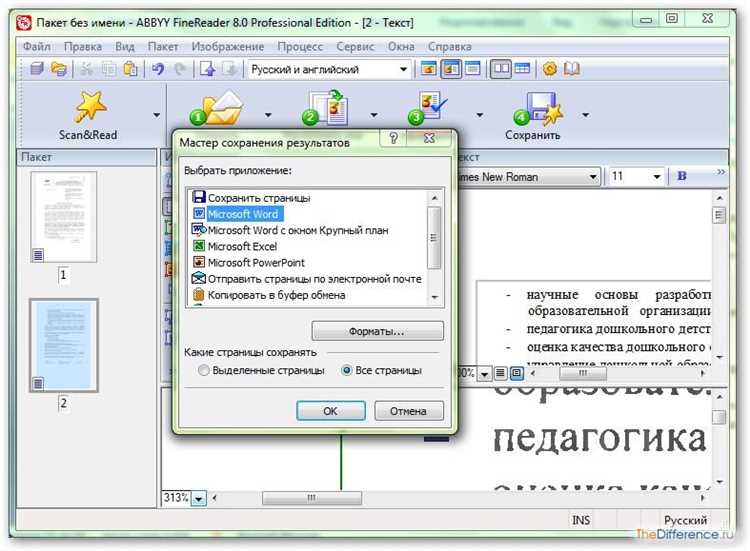
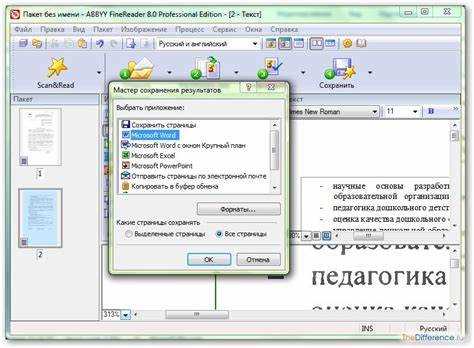
При использовании OCR-программы следует обратить внимание на её точность в распознавании шрифтов, абзацев, таблиц и других элементов форматирования. Среди наиболее популярных инструментов для таких целей – Adobe Acrobat, ABBYY FineReader и Google Docs. Эти программы позволяют не только распознавать текст, но и сохранять исходное форматирование документа.
После того как сканированный документ преобразован в текстовый файл с помощью OCR, важно тщательно проверить форматирование. Некоторые программы позволяют дополнительно настроить сохранение оригинального форматирования, включая стили шрифтов, выравнивание текста и таблицы. В случае использования ABBYY FineReader, программа автоматически сохраняет стили и структуру документа, что значительно сокращает время на редактирование.
Если вы используете Google Docs, сканированный документ можно загрузить в систему и распознать текст. Затем его можно экспортировать в формат .docx, однако для сложных форматов (например, многоколонковых страниц) может потребоваться дополнительная ручная настройка.
Кроме того, для сохранения оригинального форматирования можно использовать специализированные онлайн-сервисы, такие как OnlineOCR. Эти инструменты обеспечивают быстрое распознавание с возможностью экспорта в Word, но в некоторых случаях могут возникнуть проблемы с точностью отображения таблиц и сложных макетов.
Чтобы минимизировать ошибки при конвертации, рекомендуется после распознавания текста выполнить тщательную проверку документа в Word. Это особенно важно для документов с уникальными шрифтами, графиками или нестандартными таблицами, которые могут быть неправильно интерпретированы OCR-программой.
Вопрос-ответ:
Как перевести отсканированный документ в формат Word?
Для перевода отсканированного документа в формат Word нужно использовать программу для распознавания текста (OCR). Примеры таких программ включают Adobe Acrobat, ABBYY FineReader или Google Docs. Сначала нужно отсканировать документ в формате изображения, затем загрузить его в программу для OCR. Она распознает текст на изображении и преобразует его в редактируемый формат, например, Word. После распознавания можно отредактировать текст и сохранить его в формате .docx.
Можно ли перевести отсканированный текст в Word без установки дополнительных программ?
Да, это возможно. Один из способов — использовать онлайн-сервисы для распознавания текста, такие как OnlineOCR или Google Docs. Для этого достаточно загрузить отсканированный документ на сайт или в сервис, и он автоматически распознает текст, который затем можно сохранить в формате Word. Это удобный вариант, если не хочется устанавливать программы на компьютер.
Как улучшить качество распознавания текста с отсканированного документа?
Чтобы улучшить качество распознавания текста, нужно соблюдать несколько правил при сканировании. Во-первых, старайтесь использовать высокое разрешение (не менее 300 dpi) для получения четких изображений. Во-вторых, убедитесь, что текст на документе читаемый и не размытый. Также желательно использовать монохромные (черно-белые) сканы, так как это помогает программам распознавания точнее обработать текст. После сканирования можно использовать программы, которые позволяют улучшать качество изображения перед распознаванием.
Что делать, если после распознавания в Word появились ошибки?
Ошибки могут возникать из-за нечеткости текста или специфических шрифтов. Чтобы их исправить, можно вручную редактировать текст в Word, проверяя каждое слово. Некоторые программы для OCR также предлагают инструменты для автоматической коррекции ошибок, но всегда полезно вручную проверять результаты распознавания. Если ошибки связаны с неправильным форматом или шрифтами, попробуйте использовать другой метод сканирования или программу для распознавания.
Как перевести отсканированную таблицу в Word?
Для распознавания таблиц с отсканированных документов нужно использовать более сложные программы, например, ABBYY FineReader. Эти программы способны правильно интерпретировать таблицы, сохраняющие их структуру при переводе в формат Word. Некоторые онлайн-сервисы также поддерживают распознавание таблиц, но результаты могут требовать дополнительных правок. После распознавания можно редактировать таблицу, если необходимо, с помощью стандартных инструментов Word.