Дубликаты в таблицах – частая причина снижения производительности запросов и искажения аналитических данных. Проблема чаще всего возникает при объединении данных из разных источников, отсутствии уникальных ограничений или ошибках при импорте. Выявление и удаление таких строк требует точного понимания структуры таблицы и логики сравнения данных.
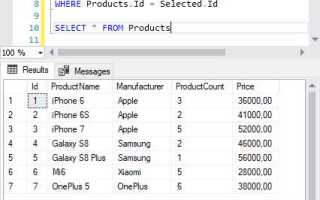
Если таблица содержит явный идентификатор (например, первичный ключ или surrogate key), задача упрощается. В таких случаях для удаления дубликатов можно использовать конструкцию DELETE с использованием подзапроса и оконной функции ROW_NUMBER(). Это позволяет сохранить только одну строку из каждой группы повторяющихся записей.
Когда уникального идентификатора нет, приходится опираться на сравнение по всем или ключевым столбцам. Здесь помогает GROUP BY с последующим JOIN на исходную таблицу для удаления строк, не попавших в агрегированное представление. Альтернатива – временная таблица с SELECT DISTINCT и последующей заменой оригинала.
Следует избегать удаления дубликатов без предварительного анализа: одинаковые значения в строках не всегда являются ошибкой. Полезно начать с запроса, который подсчитает количество повторений каждой строки. Это поможет отделить технические дубликаты от содержательно допустимых повторений.
Как найти дубликаты по всем столбцам в таблице
Для поиска строк, полностью совпадающих по значениям всех столбцов, используйте агрегирующий запрос с GROUP BY по всем колонкам таблицы. Например, если в таблице data_table четыре столбца: col1, col2, col3, col4, запрос будет следующим:
SELECT col1, col2, col3, col4, COUNT(*)
FROM data_table
GROUP BY col1, col2, col3, col4
HAVING COUNT(*) > 1;
Этот запрос возвращает только те комбинации значений, которые встречаются более одного раза. Для получения самих дублирующихся строк с их id или другими уникальными идентификаторами потребуется соединение с исходной таблицей:
SELECT dt.*
FROM data_table dt
INNER JOIN (
SELECT col1, col2, col3, col4
FROM data_table
GROUP BY col1, col2, col3, col4
HAVING COUNT(*) > 1
) dup ON dt.col1 = dup.col1 AND dt.col2 = dup.col2 AND dt.col3 = dup.col3 AND dt.col4 = dup.col4;
Чем больше столбцов в таблице, тем выше риск упустить один из них при составлении условия ON. Используйте генерацию SQL через системные представления, если структура таблицы неизвестна заранее.
Удаление строк-дубликатов с сохранением одной записи
Чтобы удалить дубликаты, оставив только одну строку с уникальными значениями, необходимо определить, какие столбцы считаются определяющими дубликат. Например, если дублируются строки по столбцам name и email, но имеют разные id, задача сводится к удалению всех строк с одинаковыми name и email, кроме одной.
Подход с использованием CTE (Common Table Expression) позволяет это сделать без подзапросов:
WITH CTE AS (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY name, email ORDER BY id) AS rn
FROM users
)
DELETE FROM users
WHERE id IN (
SELECT id FROM CTE WHERE rn > 1
);PARTITION BYуказывает, по каким столбцам определяются дубликаты.ORDER BYопределяет, какая запись будет сохранена – здесь остаётся строка с наименьшимid.- Нумерация начинается с 1, поэтому условие
rn > 1исключает первую строку в группе.
Если СУБД не поддерживает CTE, можно воспользоваться подзапросом:
DELETE FROM users
WHERE id NOT IN (
SELECT MIN(id)
FROM users
GROUP BY name, email
);MIN(id)сохраняет одну строку из каждой группы дубликатов.- Группировка должна точно соответствовать критериям повторяемости.
Перед выполнением рекомендуется сделать резервную копию или использовать оператор SELECT с теми же условиями, чтобы проверить, какие строки будут удалены.
Удаление повторяющихся строк по одному или нескольким столбцам
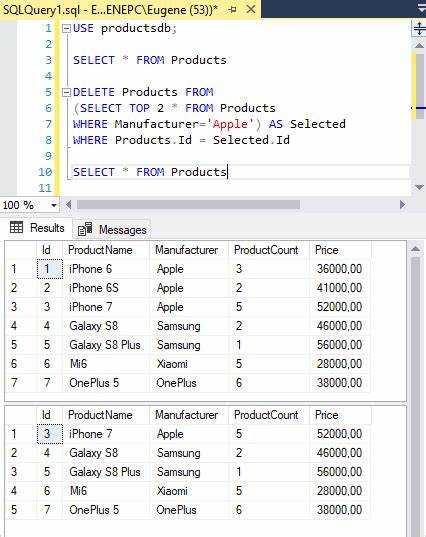
Для удаления дубликатов по одному или нескольким столбцам используют оконные функции и подзапросы. Пример ниже показывает удаление повторяющихся записей, где уникальность определяется комбинацией столбцов email и created_at:
DELETE FROM users
WHERE id IN (
SELECT id FROM (
SELECT id,
ROW_NUMBER() OVER (PARTITION BY email, created_at ORDER BY id) AS rn
FROM users
) t
WHERE t.rn > 1
);Функция ROW_NUMBER() присваивает номер каждой строке в группе. Оставляется только строка с rn = 1, остальные удаляются. Порядок в ORDER BY определяет, какая из дублирующихся строк будет сохранена.
Если важна дата создания, и требуется оставить наиболее свежую запись, сортировку меняют:
ROW_NUMBER() OVER (PARTITION BY email, created_at ORDER BY created_at DESC)Если таблица большая, стоит создать индекс на столбцы, указанные в PARTITION BY, чтобы сократить время выполнения:
CREATE INDEX idx_users_email_created_at ON users(email, created_at);Для случаев, когда нельзя использовать оконные функции (например, в старых версиях MySQL), применяется временная таблица:
CREATE TABLE temp_users AS
SELECT MIN(id) AS id
FROM users
GROUP BY email, created_at;
DELETE FROM users
WHERE id NOT IN (SELECT id FROM temp_users);Такой подход сохраняет по одной строке для каждой группы дубликатов. После завершения операции временную таблицу можно удалить:
DROP TABLE temp_users;Использование оконных функций для удаления дубликатов
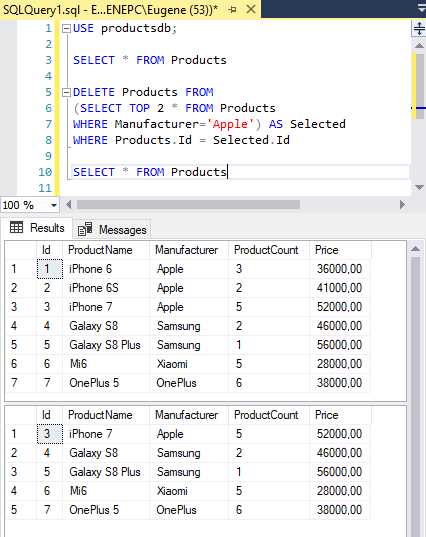
Пример: необходимо оставить только одну строку для каждой уникальной комбинации значений в столбцах name и email. Используется следующий запрос:
WITH cte AS (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY name, email ORDER BY id) AS rn
FROM users
)
DELETE FROM users
WHERE id IN (
SELECT id FROM cte WHERE rn > 1
);Функция ROW_NUMBER() присваивает каждой строке уникальный номер в пределах группы, заданной через PARTITION BY. Строки с rn > 1 считаются дубликатами и подлежат удалению.
Важно выбрать правильный критерий сортировки в ORDER BY. Если необходимо сохранить первую вставленную запись, указывают ORDER BY id. Для удаления более старых записей – ORDER BY created_at DESC, при наличии временной метки.
Этот метод не требует явного сравнения всех столбцов, достаточно указать те, по которым определяется уникальность. Он работает быстро даже на больших объёмах данных при наличии индексов на участвующие столбцы.
Удаление дубликатов с помощью временных таблиц
Для удаления дубликатов через временную таблицу необходимо создать структуру, идентичную исходной, и скопировать в неё только уникальные строки. Это особенно полезно при работе с таблицами без первичных ключей или при необходимости сохранить промежуточные результаты.
Пример на базе таблицы users с дублирующимися строками по столбцам name и email:
1. Создание временной таблицы:
CREATE TEMPORARY TABLE temp_users AS SELECT * FROM users WHERE 1=0;
2. Вставка уникальных строк:
INSERT INTO temp_users SELECT MIN(id) AS id, name, email FROM users GROUP BY name, email;
3. Очистка исходной таблицы:
DELETE FROM users;
4. Перенос уникальных записей обратно:
INSERT INTO users SELECT * FROM temp_users;
Вместо MIN(id) можно использовать MAX(id) или другие агрегаты, если важен выбор конкретной версии строки. Такой подход исключает побочные эффекты, часто возникающие при удалении дубликатов с помощью подзапросов. Временная таблица автоматически удаляется по завершении сессии, дополнительная очистка не требуется.
Удаление повторяющихся строк при импорте данных
При импорте данных из внешних источников часто возникают ситуации, когда данные содержат дубли. Удаление этих повторений важно для обеспечения точности и целостности базы данных. В SQL для таких случаев можно использовать несколько подходов в зависимости от ситуации и объема данных.
Если импортируемые данные загружаются через команду INSERT INTO, важно сначала проверить, есть ли уже идентичные записи в целевой таблице. В таких случаях можно использовать конструкцию INSERT INTO … SELECT DISTINCT, чтобы избежать дублирования. Этот запрос сначала выбирает уникальные строки из источника данных и затем вставляет их в целевую таблицу.
Для предотвращения появления повторяющихся строк можно использовать ключевые ограничения, такие как UNIQUE или PRIMARY KEY. Они гарантируют, что в таблице не появятся дублирующиеся строки с одинаковыми значениями в колонках, по которым установлено ограничение. Эти ограничения эффективно блокируют вставку дублирующихся данных на этапе импорта.
В случае работы с большими объемами данных, когда необходимо удалить повторяющиеся записи после их загрузки, можно использовать запросы с временными таблицами. Например, можно создать временную таблицу с уникальными записями, а затем выполнить обновление или замену данных в основной таблице.
Для удаления дублирующихся строк после импорта можно использовать CTE (Common Table Expressions). Пример запроса: с помощью CTE выбираются уникальные строки, после чего удаляются все остальные записи с использованием идентификатора строки (например, ROW_NUMBER()). Это позволяет эффективно удалить дубли после загрузки данных.
Оптимизация процесса удаления дубликатов включает в себя использование индексов для ускорения поиска повторяющихся записей и минимизации времени обработки запросов. Также стоит учитывать использование транзакций при удалении повторяющихся данных для обеспечения целостности данных в случае ошибок.
Проверка результата после удаления дубликатов

После выполнения операции удаления повторяющихся строк важно убедиться в правильности результата. Для этого можно использовать несколько подходов.
1. Сравнение количества строк до и после удаления
Первым шагом можно проверить разницу в количестве записей в таблице. Для этого следует выполнить два запроса: один до удаления дубликатов, второй – после. Если количество строк уменьшилось на ожидаемое количество дубликатов, операция прошла успешно.
2. Проверка с использованием группировки
Для точной проверки, что все дубликаты были удалены, используйте запрос с группировкой. Это поможет убедиться, что каждая строка таблицы уникальна. Пример запроса:
SELECT column1, column2, COUNT(*) FROM table GROUP BY column1, column2 HAVING COUNT(*) > 1;Если запрос не вернет результатов, это означает, что дубликаты успешно удалены.
3. Проверка на основе конкретных значений
Можно также выполнить выборку с фильтрацией по значениям, которые раньше встречались в виде дубликатов. Например, если известно, что повторяющиеся строки содержат одинаковые значения в определенных столбцах, выполните запрос на проверку их присутствия в таблице.
4. Использование контрольных данных
Для предотвращения ошибок можно заранее создать набор тестовых данных, включающих дубликаты. После удаления дубликатов сравните результаты с исходными контрольными данными, чтобы убедиться в корректности удаления.
5. Ручная проверка выборки
Если количество записей в таблице относительно небольшое, можно вручную проверить несколько строк, чтобы убедиться в уникальности значений после удаления.
После выполнения этих шагов можно с уверенностью утверждать, что дубликаты были удалены правильно.
Вопрос-ответ:
Как найти и удалить все повторяющиеся строки в таблице SQL?
Чтобы удалить повторяющиеся строки в таблице, нужно сначала найти их с помощью запроса, который выявляет дубликаты. Например, можно использовать конструкцию GROUP BY с функцией COUNT для подсчета количества одинаковых строк. После того как дубликаты найдены, можно использовать команду DELETE с условием, чтобы удалить их. Важно использовать уникальные идентификаторы, чтобы избежать удаления оригинальных строк.
Почему при удалении дубликатов могут возникнуть ошибки с уникальными ключами?
Ошибка может возникнуть, если вы пытаетесь удалить строку, которая участвует в индексе или ограничении, таком как уникальный ключ или внешний ключ. В таких случаях нужно сначала удалить или изменить зависимости, связанные с этими строками, чтобы не нарушить целостность данных. Также можно сначала удалить все дубликаты, оставив одну строку, а потом создать индекс или уникальное ограничение на нужное поле.
Есть ли способ автоматизировать процесс удаления дубликатов при добавлении новых данных в таблицу?
Да, можно использовать триггер для автоматического удаления дубликатов при вставке новых данных. Например, триггер будет срабатывать каждый раз, когда данные добавляются в таблицу, и будет проверять наличие дубликатов, чтобы исключить их. Также можно использовать механизм проверки уникальности на уровне базы данных с помощью ограничений или индексов, чтобы предотвратить появление повторяющихся строк с самого начала.