При работе с реляционными базами данных часто возникает необходимость представить данные в более аналитическом, «широком» формате. В таких случаях используется оператор PIVOT, позволяющий преобразовать строки в столбцы на основе агрегированных значений. Это особенно актуально для отчетности, где требуется сгруппировать информацию по категориям и временным интервалам.
Оператор PIVOT поддерживается в Microsoft SQL Server и позволяет агрегировать значения с помощью функций SUM, AVG, COUNT и других. Ключевое требование – наличие трех элементов: агрегируемого значения, столбца, по которому будет производиться поворот, и оси группировки. Без четкой структуры исходных данных результат будет некорректным или вовсе вызовет ошибку выполнения.
Применение PIVOT существенно упрощает SQL-запросы, избавляя от необходимости писать множественные CASE WHEN конструкции или подзапросы. Однако важно контролировать объем уникальных значений в поворачиваемом столбце – при превышении определенного порога может произойти деградация производительности. В таких случаях стоит рассмотреть динамический SQL с генерацией столбцов на лету.
Для эффективного использования PIVOT необходимо заранее нормализовать данные, убедиться в отсутствии дублирующихся комбинаций ключей и выбрать оптимальную агрегатную функцию. Отдельное внимание стоит уделить сортировке, поскольку результирующая таблица не гарантирует порядок без явного ORDER BY.
Как подготовить исходные данные для PIVOT
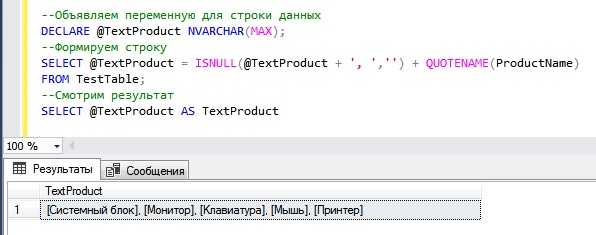
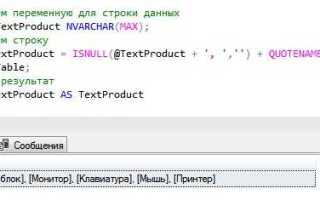
Оператор PIVOT требует строго определённой структуры входных данных. Чтобы избежать ошибок и получить ожидаемый результат, следуйте этим требованиям:
- В наборе данных должна присутствовать одна колонка, значения которой станут названиями столбцов в результирующей таблице. Это ось поворота (pivot column).
- Нужна колонка, содержащая агрегируемые значения. Как правило, это числовое поле (например, суммы продаж, количество заказов).
- Должна быть хотя бы одна колонка, определяющая категорию или ключ для группировки (например, имя клиента, дата, ID заказа).
Перед использованием PIVOT:
- Проверьте, что значения в pivot-колонке уникальны в рамках каждой группы. Если это не так, агрегатные функции могут исказить данные.
- Приведите значения pivot-колонки к одному формату – без лишних пробелов, с одинаковым регистром и типом данных.
- Убедитесь, что нет пропущенных значений в pivot-колонке и колонке с агрегируемыми данными.
- Если значения агрегируемой колонки нужно суммировать, заранее определите, как обрабатывать дубликаты и нули.
- Подготовьте список значений pivot-колонки, которые будут участвовать в повороте – SQL требует их явного указания.
Используйте подзапрос или CTE для предварительной фильтрации и нормализации данных. Это упростит основной PIVOT-запрос и минимизирует ошибки на этапе агрегации.
Синтаксис оператора PIVOT на примере SQL Server
В SQL Server оператор PIVOT используется для преобразования строк в столбцы. Он применяется внутри подзапроса, результаты которого агрегируются по заданному столбцу. Структура следующая:
SELECT <столбцы>
FROM (
SELECT <исходные_данные>
FROM <таблица>
) AS SourceTable
PIVOT (
<агрегационная_функция>(<столбец_значений>)
FOR <столбец_категорий> IN ([значение1], [значение2], ...)
) AS PivotTable;
Обязательно указание агрегатной функции: SUM, AVG, COUNT и т.д. Столбец, указанный после FOR, должен содержать дискретные значения, которые становятся заголовками новых столбцов. Эти значения указываются явно в скобках после IN.
Пример: есть таблица Sales со столбцами Region, Quarter, Revenue. Необходимо отобразить выручку по кварталам в виде отдельных столбцов для каждого региона:
SELECT Region, [Q1], [Q2], [Q3], [Q4]
FROM (
SELECT Region, Quarter, Revenue
FROM Sales
) AS Source
PIVOT (
SUM(Revenue)
FOR Quarter IN ([Q1], [Q2], [Q3], [Q4])
) AS PivotResult;
Названия столбцов внутри IN должны точно соответствовать значениям в исходных данных. Если значение отсутствует – результат будет NULL. Для подстановки дефолтных значений используйте ISNULL или COALESCE.
Оператор PIVOT не работает напрямую с несколькими агрегатами. Для таких случаев необходимо использовать объединение нескольких PIVOT или GROUP BY с условной агрегацией.
Выбор столбца для значений и агрегатной функции
Если выбранный столбец содержит дубликаты в сочетании с группирующими признаками, агрегатная функция должна корректно обрабатывать множественные записи. SUM используется для числовых итогов, COUNT – для подсчёта записей, AVG – для средней величины. Выбор зависит от аналитической задачи. Например, если необходимо узнать максимальную стоимость заказа по категориям, применяется MAX. В случае отображения минимального значения – MIN.
Использование неподходящего столбца, например текстового, приведёт к ошибке выполнения, так как агрегатные функции не применимы к строкам без явного преобразования. При необходимости использовать строковый столбец, следует сначала агрегировать его через STRING_AGG или аналогичную функцию, если это поддерживается СУБД.
Также важно учитывать производительность: чем больше уникальных значений в группирующем столбце, тем больше столбцов будет создано в результате PIVOT, что может повлиять на читаемость и время выполнения запроса. Рекомендуется ограничивать количество уникальных значений в столбце, по которому происходит поворот, до разумного числа, особенно при работе с большими наборами данных.
Указание фиксированных значений для формирования столбцов
Оператор PIVOT требует явного указания значений, которые будут использоваться в качестве имен столбцов. Эти значения задаются в конструкции IN (...) после ключевого слова PIVOT. Без явного списка трансформация невозможна – серверу необходимо точно знать, какие значения из исходного столбца будут перенесены в заголовки новых столбцов.
Формат использования:
SELECT *
FROM (
SELECT Год, Показатель, Значение
FROM Данные
) AS Источник
PIVOT (
SUM(Значение)
FOR Показатель IN ([Доход], [Расход], [Прибыль])
) AS ПивотТаблица;
Список значений в скобках должен соответствовать реальным данным в столбце, указанном после FOR. Если указать несуществующее значение, будет создан соответствующий столбец, но он заполнится NULL.
Для предотвращения ошибок используйте предварительный запрос с SELECT DISTINCT, чтобы получить актуальный список значений. Например:
SELECT DISTINCT Показатель FROM Данные;
Жестко заданный список обеспечивает стабильность структуры результата, особенно важно при автоматизированной обработке данных или построении отчетов. При динамической генерации PIVOT-запроса на стороне клиента необходимо учитывать возможные изменения в данных и обновлять список фиксированных значений.
Обработка NULL-значений при использовании PIVOT

Оператор PIVOT в SQL не обрабатывает NULL-значения автоматически: если для определённого сочетания строк и столбцов нет данных, результатом будет NULL. Это может исказить аналитику и нарушить логику агрегирования. Чтобы избежать этого, используйте функцию COALESCE для замены NULL на значение по умолчанию.
Например, при агрегации суммы по категориям, отсутствующие значения можно заменить нулём: COALESCE(SUM(Amount), 0). Это гарантирует, что итоговая таблица будет содержать числовые значения даже при отсутствии исходных данных для конкретной категории.
Если используется агрегатная функция COUNT, то NULL-значения игнорируются автоматически. Однако при COUNT(*), строки учитываются даже с NULL в агрегируемом столбце, что может привести к логическим ошибкам при интерпретации данных. Уточняйте COUNT по конкретному столбцу: COUNT(ColumnName).
При необходимости различать отсутствие данных и фактическое значение NULL, используйте внешние соединения до выполнения PIVOT. Это позволяет сохранить строки, которые иначе были бы исключены, и обрабатывать их отдельно.
В случае динамического PIVOT с EXEC или FOR XML PATH, особое внимание требуется к предварительной фильтрации данных. Отсутствие значений в выборке приведёт к отсутствию соответствующих столбцов в результирующей таблице. Используйте WITH CTE для подготовки полного перечня значений до PIVOT.
Как объединить PIVOT с другими операциями SELECT
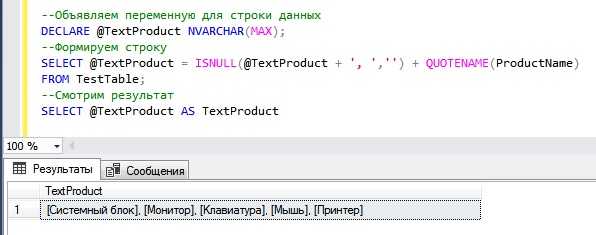
Если нужно дополнительно сгруппировать данные по определённым условиям, оператор PIVOT можно использовать в подзапросах, а затем применить GROUP BY для объединения результатов. Например, можно посчитать средние значения по каждому столбцу после выполнения поворота данных:
SELECT Department, AVG([January]), AVG([February]) FROM ( SELECT Department, Month, Revenue FROM Sales ) AS SourceTable PIVOT ( SUM(Revenue) FOR Month IN ([January], [February]) ) AS PivotTable GROUP BY Department;
В этом примере, после преобразования данных с использованием PIVOT, данные агрегируются по отделам, и для каждого месяца вычисляется средняя выручка.
Ещё одной полезной техникой является применение фильтрации данных через WHERE или HAVING после выполнения PIVOT. Например, можно отфильтровать результаты для получения только тех отделов, где выручка в январе превышает определённое значение:
SELECT Department, [January], [February] FROM ( SELECT Department, Month, Revenue FROM Sales ) AS SourceTable PIVOT ( SUM(Revenue) FOR Month IN ([January], [February]) ) AS PivotTable WHERE [January] > 5000;
В данном примере PIVOT используется для создания столбцов по месяцам, а затем фильтрация выполняется на основе значений в столбце для января.
Иногда необходимо объединить результаты PIVOT с другими операциями, такими как JOIN. Это позволяет комбинировать данные из нескольких источников. Пример: если у нас есть таблица с данными о продажах, а также таблица с информацией о сотрудниках, можно использовать PIVOT в сочетании с JOIN для получения данных о продажах по сотрудникам и месяцам:
SELECT E.EmployeeName, [January], [February] FROM Employees AS E JOIN ( SELECT EmployeeID, Month, Revenue FROM Sales ) AS S ON E.EmployeeID = S.EmployeeID PIVOT ( SUM(Revenue) FOR Month IN ([January], [February]) ) AS PivotTable;
Здесь происходит объединение таблицы сотрудников с таблицей продаж, а затем преобразование данных с помощью PIVOT для создания отчёта по выручке для каждого сотрудника по месяцам.
Таким образом, PIVOT можно успешно комбинировать с другими операциями SELECT, чтобы создавать более сложные и информативные запросы, которые отвечают специфическим аналитическим требованиям.
Частые ошибки при работе с PIVOT и способы их устранения
Использование оператора PIVOT в SQL может быть не таким прямолинейным, как кажется на первый взгляд. Разберем основные ошибки, с которыми сталкиваются разработчики, и способы их устранения.
- Ошибка: Неправильное использование агрегатных функций
- Решение: Убедитесь, что для каждого столбца, который вы хотите преобразовать с помощью PIVOT, используется правильная агрегатная функция. Если агрегатная функция не указана, запрос вернет ошибку.
- Ошибка: Невозможность обработки NULL значений
- Решение: Используйте функции для обработки NULL значений, такие как COALESCE или ISNULL, чтобы заменить NULL на дефолтное значение перед применением PIVOT.
- Ошибка: Неверный порядок столбцов в операторе PIVOT
- Решение: Перепроверьте порядок столбцов, указываемых в секции PIVOT. Использование неверного порядка или нечеткая логика может привести к некорректному формированию итоговой таблицы.
- Ошибка: Отсутствие правильных группировок
- Решение: Убедитесь, что при использовании PIVOT присутствует необходимая группировка данных, особенно когда необходимо агрегировать данные по нескольким признакам.
- Ошибка: Отсутствие динамического PIVOT в случае изменения данных
- Решение: В таких случаях используйте динамический PIVOT, который позволяет адаптировать запрос к изменяющимся данным. Для этого нужно строить запрос в виде строки и выполнять его с помощью EXEC.
- Ошибка: Использование неподдерживаемых типов данных
- Решение: Убедитесь, что используемые типы данных совместимы с PIVOT. При необходимости преобразуйте типы данных (например, с помощью CAST или CONVERT) перед выполнением операции.
- Ошибка: Неверная агрегация при наличии дублирующихся данных
- Решение: Перед использованием PIVOT очистите данные от дубликатов с помощью DISTINCT или других методов предварительной агрегации данных.
- Ошибка: Проблемы с производительностью при больших объемах данных
- Решение: Оптимизируйте запросы с использованием индексов, избегайте лишних преобразований данных, а также рассмотрите возможность использования подзапросов для предварительной агрегации.
При работе с PIVOT важно правильно указывать агрегатные функции. Например, если требуется посчитать суммы или средние значения, необходимо правильно применить функцию (SUM, AVG и т.д.) для соответствующих столбцов.
Когда в исходных данных присутствуют NULL значения, оператор PIVOT может не выполнить нужное преобразование. Результатом может стать потеря данных или некорректное их отображение в результирующем наборе.
Если в запросе не указаны необходимые группировки (GROUP BY), это приведет к ошибкам выполнения или некорректным данным. Например, если при применении PIVOT не учтены все уникальные значения, итоговый набор данных может быть искажен.
Статический PIVOT может стать проблемой, если структура данных изменяется (например, появляются новые значения в столбце, по которому происходит свертка).
Некоторые типы данных (например, типы с плавающей точкой или текстовые поля) могут не поддерживаться в операциях PIVOT. Это приведет к ошибкам выполнения или невозможности выполнения запроса.
Если в исходных данных содержатся дубли, агрегатные функции могут работать неправильно, особенно если дубли не были предварительно обработаны.
Когда данные в базе данных растут, запросы с PIVOT могут значительно замедлиться. Особенно это касается сложных операций с большим количеством вычислений и агрегирования.
Правильное использование PIVOT в SQL требует внимательности и тщательной проверки данных. Понимание возможных ошибок и способов их устранения поможет повысить эффективность работы с этим мощным инструментом.
Вопрос-ответ:
Что такое оператор PIVOT в SQL и как он используется?
Оператор PIVOT в SQL позволяет преобразовывать строки в столбцы, что полезно для представления данных в более удобном для анализа виде. Он используется для того, чтобы «повернуть» таблицу таким образом, чтобы уникальные значения одного столбца стали заголовками новых столбцов, а данные из других столбцов распределились по ним. Например, можно преобразовать таблицу с данными о продажах, где каждая строка представляет продажу по определенной категории, в таблицу, где категории будут колонками, а суммы продаж — значениями.
Можно ли использовать оператор PIVOT для работы с несколькими агрегациями в одном запросе?
Да, оператор PIVOT поддерживает использование нескольких агрегаций в одном запросе. Для этого можно выполнить несколько операций PIVOT в одном запросе, объединив их с помощью подзапросов или с помощью оператора UNION. Например, если вам нужно получить не только суммы продаж, но и средние значения или количество продаж для каждой категории, можно использовать несколько агрегатных функций в одном запросе. Это позволяет гибко работать с данными и представлять их в удобном виде.
Можно ли использовать PIVOT для динамического создания столбцов?
Оператор PIVOT в SQL не поддерживает динамическое создание столбцов напрямую. Все столбцы должны быть указаны заранее в списке IN. Однако, можно написать динамический SQL-запрос, который будет генерировать список значений для столбцов в зависимости от данных в таблице. Для этого можно использовать систему переменных и динамическое формирование SQL-запроса в зависимости от уникальных значений столбца категорий. Это позволяет создавать запросы, которые автоматически адаптируются под изменяющиеся данные.
Что такое оператор PIVOT в SQL и как он работает?
Оператор PIVOT в SQL позволяет преобразовывать строки в столбцы, что помогает представить данные в более удобном для анализа виде. Обычно его используют для создания сводных таблиц, где различные значения из одной колонки становятся заголовками столбцов, а соответствующие данные агрегируются. Чтобы использовать PIVOT, необходимо указать столбец, который будет преобразован в заголовки, а также функцию агрегации, которая будет применяться к оставшимся данным.
Какие могут быть сложности при использовании оператора PIVOT в SQL?
Основная сложность при использовании PIVOT заключается в необходимости заранее указать значения, которые будут использоваться в качестве заголовков столбцов. Это может быть проблемой, если набор данных динамичен, и значения в столбце, который используется для создания заголовков, меняются со временем. В таких случаях можно использовать динамический SQL, чтобы генерировать запросы с необходимыми заголовками столбцов. Еще одна проблема — необходимость правильно выбрать функцию агрегации, чтобы корректно обрабатывать повторяющиеся значения.