Очистка базы данных SQL – это важная задача, с которой сталкиваются разработчики и администраторы при обслуживании серверов. Регулярное удаление неактуальных данных, старых записей и логов помогает поддерживать высокую производительность и уменьшить нагрузку на систему. Однако необходимо подходить к этому процессу с особой осторожностью, чтобы избежать потери критически важной информации.
Первый шаг в процессе очистки – это анализ структуры базы данных. Прежде чем удалять данные, важно понять, какие таблицы и поля нуждаются в очистке. Одним из наиболее эффективных инструментов для этого является запрос SELECT, который позволяет выявить записи, превышающие допустимый срок хранения или устаревшие с точки зрения бизнес-логики. Например, если база данных содержит таблицы с логами, имеет смысл удалять данные, которые старше 6 месяцев, в зависимости от политики компании.
После того как определены данные для удаления, следует выполнить проверку целостности. Используйте TRANSACTION для обеспечения атомарности операций. Это значит, что все изменения будут выполнены или отменены вместе, что минимизирует риски случайной потери данных. Важно также создать резервные копии до начала очистки, чтобы в случае ошибки можно было восстановить информацию.
Одним из распространенных методов оптимизации базы данных после очистки является перезапуск индексов. После удаления большого количества данных индексы могут стать неэффективными, что снижает скорость работы запросов. Регулярное обновление индексов и их дефрагментация позволяют значительно улучшить производительность системы.
Наконец, важно следить за использованием автоматизированных инструментов очистки. Системы с высокой частотой обновлений или большого объема данных могут потребовать написания регулярных скриптов, которые будут выполнять очистку по расписанию. Однако, такие скрипты требуют тщательной настройки и тестирования, чтобы избежать ненужного удаления.
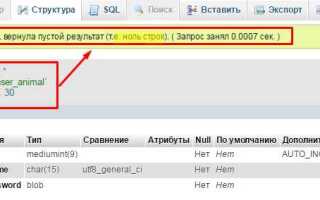
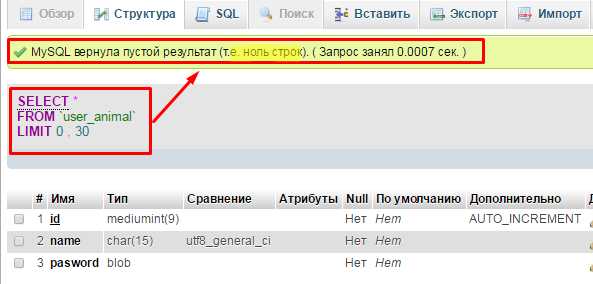
Удаление неиспользуемых индексов в базе данных
Неиспользуемые индексы в базе данных создают дополнительную нагрузку на систему, увеличивают время обновления и занимаются избыточным пространством на диске. Чтобы очистить базу данных и улучшить её производительность, важно идентифицировать и удалить такие индексы.
Прежде чем удалять индекс, необходимо убедиться, что он действительно не используется. В SQL Server и других СУБД можно использовать системные представления для анализа использования индексов. Например, в SQL Server можно запросить представление sys.dm_db_index_usage_stats, чтобы выяснить, сколько раз индекс был использован для чтения или записи.
Пример запроса для проверки использования индексов:
SELECT
OBJECT_NAME(IXOS.OBJECT_ID) AS Table_Name,
IX.name AS Index_Name,
IXOS.LEAF_INSERT_COUNT AS Inserts,
IXOS.LEAF_UPDATE_COUNT AS Updates,
IXOS.LEAF_DELETE_COUNT AS Deletes,
IXOS.LEAF_READ_COUNT AS Reads
FROM
SYS.DM_DB_INDEX_OPERATIONAL_STATS (NULL,NULL,NULL,NULL) AS IXOS
INNER JOIN
SYS.INDEXES AS IX
ON IX.OBJECT_ID = IXOS.OBJECT_ID
AND IX.INDEX_ID = IXOS.INDEX_ID
WHERE
OBJECTPROPERTY(IX.OBJECT_ID, 'IsUserTable') = 1;Этот запрос вернёт статистику по использованию индексов для каждой таблицы. Если индексы не использовались, их можно удалить.
Удаление неиспользуемого индекса осуществляется с помощью команды DROP INDEX. Однако стоит учитывать, что удаление индекса должно быть осмотрительным, поскольку некоторые индексы могут быть необходимы для быстрого выполнения специфичных запросов, даже если они не используются регулярно.
Пример команды для удаления индекса:
DROP INDEX IndexName ON TableName;Если удалённый индекс оказался нужным, его всегда можно воссоздать, но это повлечёт за собой дополнительные ресурсы на восстановление и тестирование. Поэтому перед удалением важно оценить влияние каждого индекса на производительность системы.
Для регулярной очистки от неиспользуемых индексов можно настроить автоматические скрипты, которые будут проверять статистику использования индексов и удалять их по мере необходимости. Это особенно полезно для крупных баз данных, где вручную контролировать каждый индекс может быть затруднительно.
Также важно помнить, что индексы, используемые для поддержания целостности данных (например, уникальные индексы или индексы на внешних ключах), не должны быть удалены. Поэтому стоит внимательно подходить к выбору индексов, которые могут быть лишними.
Очистка старых и неактуальных данных из таблиц
Первым шагом является определение, какие данные считаются старими или неактуальными. Чаще всего это данные, которые не используются в текущих операциях, например, старые записи о пользователях, завершенные заказы или устаревшие логи. Зачастую для таких данных устанавливается срок хранения, по прошествии которого они подлежат удалению или архивированию.
Для очистки можно использовать SQL-запросы с условием временной метки. Например, чтобы удалить записи, старше определённого количества дней, следует воспользоваться запросом вида:
DELETE FROM таблица WHERE дата < NOW() - INTERVAL 30 DAY;
Важно, чтобы такие запросы выполнялись регулярно, например, через планировщик задач или в рамках репликации базы данных. При удалении данных следует учитывать необходимость их архивации, если они могут понадобиться для аудита или анализа в будущем.
Кроме того, следует избегать простых "удалений" данных, так как это может привести к блокировке таблиц или значительному снижению производительности. Вместо этого можно использовать методы "мягкого удаления", например, пометив записи как удалённые с помощью флага в таблице:
UPDATE таблица SET удален = 1 WHERE дата < NOW() - INTERVAL 30 DAY;
Этот подход позволяет сохранить данные, но при этом они не будут учитываться в запросах и могут быть физически удалены позже, например, в период меньшей загрузки базы данных.
Если таблицы содержат большие объёмы данных, стоит применять методы деления таблиц на партиции (partitioning). Это позволяет разбить данные на более мелкие сегменты, например, по датам, и удалять старые записи, касающиеся только определённых партиций, что значительно снижает нагрузку на систему.
Необходимо также учитывать возможное влияние очистки на целостность данных. Например, удаление старых записей может повлиять на связи с другими таблицами, особенно если они связаны с внешними ключами. Чтобы избежать проблем, стоит проверять зависимости и обновлять внешние ключи при необходимости.
Реорганизация и перестроение таблиц для улучшения производительности
Реорганизация и перестроение таблиц – важные процессы для оптимизации работы SQL-базы данных. Эти операции помогают уменьшить фрагментацию данных, улучшить индексирование и ускорить выполнение запросов.
Реорганизация таблиц проводится для уменьшения фрагментации данных на уровне страниц и строк. Этот процесс эффективен, когда таблица не содержит значительных изменений в структуре данных, а фрагментация не слишком высока. Реорганизация не требует блокировки таблицы, что позволяет проводить её в рабочее время. В SQL Server для этого используется команда ALTER INDEX REORGANIZE, которая перестраивает только индексы, не затрагивая сами данные.
Реорганизация рекомендуется, если уровень фрагментации индекса составляет от 10% до 30%. При этом процесс требует минимальных системных ресурсов, так как он работает инкрементально, обновляя только изменённые части индекса.
Перестроение таблиц – более глубокая операция, при которой индексы пересоздаются полностью. Она используется для устранения более серьёзной фрагментации (более 30%) или если требуется восстановить порядок в таблицах с большими объёмами данных. В отличие от реорганизации, перестроение блокирует таблицу, что может повлиять на доступность данных во время операции. В SQL Server используется команда ALTER INDEX REBUILD.
Перестроение индексов ускоряет выполнение запросов, особенно для сложных операций с большими объёмами данных. При этом можно задать параметр ONLINE, чтобы минимизировать время простоя, если сервер поддерживает данную функцию.
Для оптимизации работы базы данных важно регулярно мониторить фрагментацию таблиц и индексов. Использование DMV (Dynamic Management Views), таких как sys.dm_db_index_physical_stats, позволяет отслеживать уровень фрагментации и принимать решение о необходимости реорганизации или перестроения. В идеале, эти операции должны проводиться в ночное время или в периоды низкой нагрузки на систему.
Также стоит учитывать, что частое перестроение может негативно повлиять на производительность в моменты пиковых нагрузок. Рекомендуется использовать гибридный подход, сочетая реорганизацию для регулярной очистки и перестроение для более тяжёлых случаев фрагментации.
Важно помнить, что после выполнения этих операций может потребоваться обновление статистики для обеспечения оптимальной работы запросов. В SQL Server для этого используется команда UPDATE STATISTICS.
Использование команды TRUNCATE для массового удаления данных
Команда TRUNCATE TABLE позволяет быстро удалить все строки из таблицы, не фиксируя каждое удаление в журнале транзакций. Это обеспечивает значительно более высокую производительность по сравнению с DELETE при работе с большим объёмом данных.
TRUNCATE не активирует триггеры, связанные с удалением, и не возвращает количество удалённых строк. Поэтому перед её использованием важно убедиться в отсутствии зависимостей и необходимости постобработки данных.
Команду нельзя использовать, если на таблицу ссылаются внешние ключи, даже при условии отключения проверок. Кроме того, она не работает с таблицами, участвующими в репликации или содержащими столбцы с идентификаторами, если требуется сброс их значений – хотя в большинстве СУБД она автоматически обнуляет счётчик IDENTITY.
TRUNCATE нельзя выполнить внутри активной транзакции в некоторых СУБД, таких как PostgreSQL. В MySQL команда требует наличия привилегии DROP на таблицу. В SQL Server она логируется частично, что снижает вероятность отката операции.
Использовать TRUNCATE стоит только при полной уверенности в необратимости очистки таблицы. Предварительное резервное копирование – обязательная мера. В автоматизированных сценариях очистки следует явно проверять структуру таблицы на наличие внешних связей перед выполнением команды.
Как правильно очистить журнал транзакций SQL Server
Очистка журнала транзакций необходима для предотвращения его неконтролируемого роста, особенно при использовании режима полной или массовой регистрации. Удаление данных напрямую из журнала невозможно – требуется его усечение (truncate) или резервное копирование. Рекомендуемые действия:
1. Убедитесь, что база данных использует нужный режим восстановления. Чтобы журнал можно было усечь, он должен быть в полном или массовом режиме:
SELECT name, recovery_model_desc FROM sys.databases WHERE name = 'Имя_Базы';
2. Выполните резервное копирование журнала транзакций. Это основной способ его очистки:
BACKUP LOG [Имя_Базы] TO DISK = 'D:\Backups\Имя_Базы_Log.trn';
3. Проверьте размер и использование журнала:
DBCC SQLPERF(LOGSPACE);
4. Если вы не нуждаетесь в возможности восстановления до точки отказа и хотите сбросить журнал вручную, временно переключите базу в простой режим, усеките журнал, затем верните режим обратно:
ALTER DATABASE [Имя_Базы] SET RECOVERY SIMPLE; DBCC SHRINKFILE([Имя_Журнального_Файла], 1); ALTER DATABASE [Имя_Базы] SET RECOVERY FULL;
5. Чтобы избежать повторного разрастания, настройте регулярное резервное копирование журнала и следите за авторасширением файла журнала. Оптимальные значения задаются вручную:
ALTER DATABASE [Имя_Базы] MODIFY FILE (NAME = N'Имя_Журнального_Файла', FILEGROWTH = 256MB);
6. Убедитесь, что журнал не удерживается активными транзакциями. Выполните:
DBCC OPENTRAN('Имя_Базы');
Если транзакция «зависла», завершите её вручную или перезапустите приложение, удерживающее соединение.
Планирование автоматической очистки данных с использованием задач

Автоматизация очистки данных в SQL-базе повышает производительность системы и снижает риски ошибок при ручной работе. Эффективнее всего реализовать её через встроенные механизмы планирования задач. В SQL Server используется SQL Server Agent, в PostgreSQL – pg_cron, в MySQL – EVENT.
- Создавайте отдельные задачи для каждой таблицы или группы таблиц с одинаковыми правилами хранения.
- Используйте условия на основе временных меток. Пример: удаление записей старше 90 дней по полю
created_at. - Планируйте выполнение задач в периоды минимальной нагрузки: ночное время или выходные.
- Добавляйте логирование каждой операции удаления: сохраняйте количество удалённых строк и временные метки в техническую таблицу.
- Устанавливайте ограничения по времени выполнения задач, чтобы избежать блокировок и влияния на производительность.
- В SQL Server создайте Job через SQL Server Agent. В шаге используйте T-SQL-команду:
DELETE FROM logs WHERE created_at < DATEADD(DAY, -90, GETDATE()); - В PostgreSQL активируйте расширение
pg_cronи настройте cron-задачу:SELECT cron.schedule('0 3 * * *', $$DELETE FROM logs WHERE created_at < now() - interval '90 days'$$); - В MySQL включите планировщик событий и создайте событие:
CREATE EVENT cleanup_logs ON SCHEDULE EVERY 1 DAY STARTS CURRENT_TIMESTAMP + INTERVAL 1 HOUR DO DELETE FROM logs WHERE created_at < NOW() - INTERVAL 90 DAY;
Обязательно тестируйте каждую задачу на копии данных. Исключайте влияние на активные транзакции с помощью блокировок WITH (ROWLOCK) или LIMIT в цикле. Отказ от автоматизации в пользу ручного удаления оправдан только в случае нестандартных условий или требований к аудиту.
Проверка и удаление «мусора» в базе данных с помощью скриптов

Ненужные данные – одна из основных причин замедления SQL-базы. Прежде всего, необходимо определить типы «мусора»: неиспользуемые записи, устаревшие временные данные, лог-файлы, неактуальные связи и осиротевшие записи в зависимых таблицах.
Выявление осиротевших записей проводится через LEFT JOIN с последующей фильтрацией по NULL. Пример для удаления заказов без клиента:
DELETE o
FROM Orders o
LEFT JOIN Customers c ON o.CustomerID = c.ID
WHERE c.ID IS NULL;Очистка временных таблиц проводится по дате создания. Если таблица содержит поле CreatedAt, можно использовать такой скрипт:
DELETE FROM TempData
WHERE CreatedAt < DATEADD(DAY, -7, GETDATE());Удаление дублей осуществляется с использованием CTE и оконных функций. Пример удаления повторяющихся e-mail в таблице пользователей:
WITH CTE AS (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY Email ORDER BY ID) AS rn
FROM Users
)
DELETE FROM CTE WHERE rn > 1;Очистка логов – частая необходимость при накоплении данных. Удаление логов старше 30 дней:
DELETE FROM SystemLogs
WHERE LogDate < DATEADD(DAY, -30, GETDATE());Автоматизация скриптов возможна с помощью SQL Agent (в SQL Server) или cron-задач (в PostgreSQL/MySQL через внешние скрипты). Это обеспечивает регулярное обслуживание без участия администратора.
Резервное копирование – обязательный этап перед любой очисткой. Используйте BACKUP DATABASE или экспорт в формат .bak/.sql для быстрой откатки при ошибках.
Вопрос-ответ:
Можно ли удалить все данные из таблицы, не удаляя саму таблицу?
Да, можно. Для этого используют команду `TRUNCATE TABLE`. Она удаляет все строки из таблицы, но оставляет структуру таблицы и её зависимости, такие как индексы и ограничения. В отличие от `DELETE`, эта команда работает быстрее и не записывает каждую удалённую строку в журнал транзакций. Однако `TRUNCATE` нельзя использовать, если на таблицу ссылаются внешние ключи из других таблиц, даже если в этих таблицах нет данных.
Как безопасно очистить таблицу с важными данными, чтобы не потерять нужную информацию?
Прежде всего, стоит сделать резервную копию данных. Это можно сделать через команду `BACKUP` (если используется SQL Server) или с помощью `pg_dump` в PostgreSQL. Затем желательно временно скопировать нужные данные в отдельную таблицу. После этого можно выполнить очистку, используя `DELETE` с нужными условиями или `TRUNCATE`, если удаляется всё. После завершения проверки можно вернуть сохранённые данные обратно, если они понадобятся. Такой подход уменьшает риск потерь при ошибках.