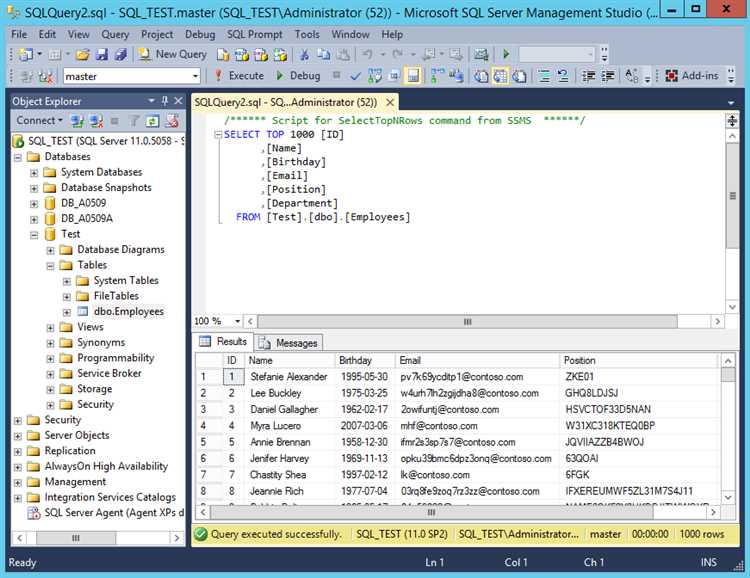
Просмотр данных в таблице SQL – основная операция, которую необходимо освоить при работе с базами данных. Для этого используется команда SELECT, которая позволяет извлекать информацию из таблиц, фильтровать и сортировать её. Чтобы начать, необходимо указать таблицу, из которой вы хотите получить данные, и при необходимости задать условия выборки.
Простой запрос выглядит так: SELECT * FROM имя_таблицы;. В данном случае * означает выбор всех столбцов таблицы. Однако, для эффективной работы с большими данными лучше выбирать только те поля, которые вам необходимы. Например, чтобы получить данные только из двух столбцов, запрос будет следующим: SELECT столбец1, столбец2 FROM имя_таблицы;.
Если требуется фильтрация данных, применяются условия с использованием оператора WHERE. Например, для поиска всех сотрудников старше 30 лет запрос будет следующим: SELECT * FROM сотрудники WHERE возраст > 30;. Это позволяет сузить выборку и работать только с необходимыми данными.
Кроме того, часто бывает полезно сортировать результаты по возрастанию или убыванию значений в столбцах. Для этого используется оператор ORDER BY. Например, чтобы отсортировать результаты по возрасту в порядке убывания, запрос будет таким: SELECT * FROM сотрудники ORDER BY возраст DESC;.
Использование этих базовых команд и операторов позволяет эффективно управлять выборками данных и анализировать таблицы в SQL. Совмещение фильтрации, сортировки и выборки нужных столбцов делает запросы более точными и удобными для работы.
Выбор базы данных для работы с таблицей
Если основная задача – хранение структурированных данных с возможностью выполнения сложных запросов, оптимальным выбором будет реляционная база данных. PostgreSQL и MySQL – одни из самых популярных решений для таких задач. PostgreSQL чаще выбирают для проектов с высокими требованиями к целостности данных и поддержке сложных запросов, благодаря мощной поддержке индексов и расширений.
Для приложений с высокой нагрузкой, требующих быстрой записи данных, подходит MySQL, особенно если нужно минимизировать время отклика при большом количестве запросов. Она также лучше подходит для ситуаций, где важна простота настройки и стабильность работы с небольшими и средними объемами данных.
Если проект предполагает работу с неструктурированными данными, стоит обратить внимание на NoSQL базы данных, такие как MongoDB или Cassandra. Они хорошо справляются с большими объемами данных, которые не требуют жесткой структуры, например, для хранения документов или пользовательских данных. MongoDB также удобна при работе с динамично изменяющимися данными, где важна гибкость схемы.
Когда требуется высокая производительность при работе с аналитическими данными или поддержка обработки больших объемов информации, стоит рассмотреть базы данных типа Hadoop или Apache HBase. Эти решения предлагают возможность масштабирования, что важно для крупных проектов, где количество записей в таблицах может превышать миллиарды.
Особое внимание стоит уделить системам, поддерживающим распределенную архитектуру, если проект предполагает масштабирование или работу в облачных средах. В таких случаях, например, Google BigQuery или Amazon Aurora, могут предложить удобные механизмы управления таблицами и быстрое выполнение запросов при обработке больших данных.
Важно также учитывать поддержку базы данных в выбранной технологии и языке программирования. Реляционные базы данных, такие как PostgreSQL, широко поддерживаются большинством фреймворков и библиотек, что позволяет легко интегрировать их в систему. Для NoSQL решений необходимо предварительно оценить поддержку в выбранных инструментах разработки.
Основные команды для просмотра данных в таблице
SELECT * FROM employees;Здесь символ * обозначает выбор всех столбцов. В случае необходимости можно указать конкретные столбцы, например:
SELECT name, position FROM employees;Команда LIMIT ограничивает количество строк в результатах. Это полезно при работе с большими таблицами. Пример:
SELECT * FROM employees LIMIT 10;Такой запрос вернёт только первые 10 строк из таблицы. Это часто используется для быстрого анализа данных или при пагинации результатов.
Для фильтрации данных используется оператор WHERE. Он позволяет задать условия для выборки. Например, чтобы получить данные только о сотрудниках с должностью «менеджер», используется следующий запрос:
SELECT * FROM employees WHERE position = 'менеджер';Можно комбинировать несколько условий с помощью логических операторов AND и OR. Пример:
SELECT * FROM employees WHERE position = 'менеджер' AND salary > 50000;Для сортировки результатов используется оператор ORDER BY. Он позволяет отсортировать данные по указанному столбцу. По умолчанию сортировка будет происходить по возрастанию. Чтобы отсортировать по убыванию, нужно использовать DESC. Например:
SELECT * FROM employees ORDER BY salary DESC;Чтобы отсортировать данные по нескольким столбцам, можно указать несколько критериев:
SELECT * FROM employees ORDER BY position ASC, salary DESC;Таким образом, используя эти основные команды и операторы, можно эффективно работать с данными в SQL, выбирая необходимые строки и столбцы в соответствии с заданными условиями.
Фильтрация строк с помощью WHERE в SQL
Оператор WHERE используется для фильтрации строк в SQL-запросах, позволяя выбрать только те записи, которые соответствуют определённым условиям. Он применяется после оператора FROM и перед операторами GROUP BY, HAVING и ORDER BY. Условие может включать различные операторы сравнения, логические операторы и функции.
Для фильтрации данных можно использовать такие операторы сравнения, как = (равно), < (меньше), > (больше), <= (меньше или равно), >= (больше или равно), <> или != (не равно). Например, для выбора всех сотрудников с зарплатой больше 50000, запрос будет выглядеть так:
SELECT * FROM employees WHERE salary > 50000;
Логические операторы AND, OR и NOT позволяют комбинировать несколько условий. Например, чтобы выбрать сотрудников, которые имеют зарплату больше 50000 и работают в департаменте ‘IT’, можно использовать запрос:
SELECT * FROM employees WHERE salary > 50000 AND department = 'IT';
Оператор BETWEEN позволяет выбирать значения в пределах указанного диапазона. Это удобно, например, для поиска дат или числовых диапазонов. Пример выбора сотрудников, чья зарплата находится между 40000 и 60000:
SELECT * FROM employees WHERE salary BETWEEN 40000 AND 60000;
Для работы с текстовыми данными используются операторы LIKE и ILIKE. LIKE позволяет выполнить поиск по шаблону, где % представляет собой любое количество символов, а _ – один символ. Например, для поиска сотрудников, чьи имена начинаются с буквы ‘А’, запрос будет таким:
SELECT * FROM employees WHERE name LIKE 'A%';
Если необходимо учитывать регистр символов, можно использовать ILIKE (для PostgreSQL) или COLLATE в других СУБД. Кроме того, можно использовать регулярные выражения для более сложных условий, например:
SELECT * FROM employees WHERE name ~ '^A.*';
Для фильтрации по датам также часто используется WHERE. Чтобы выбрать все записи, сделанные после 1 января 2023 года, можно написать запрос:
SELECT * FROM orders WHERE order_date > '2023-01-01';
Таким образом, оператор WHERE предоставляет мощные возможности для точного выбора данных, что особенно важно при работе с большими объемами информации. Важно помнить, что фильтрация данных происходит на уровне выборки, и её производительность напрямую зависит от правильности использования индексов и структуры базы данных.
Сортировка данных по столбцам с помощью ORDER BY
Команда ORDER BY в SQL используется для сортировки данных по одному или нескольким столбцам. По умолчанию сортировка выполняется по возрастанию (ASC), но можно указать и убывающее направление сортировки (DESC).
Для сортировки данных по одному столбцу достаточно указать его название после ORDER BY. Например:
SELECT * FROM employees ORDER BY last_name;
В этом примере результат будет отсортирован по фамилии сотрудников в алфавитном порядке.
Для сортировки по нескольким столбцам, их нужно указать через запятую. Например:
SELECT * FROM employees ORDER BY department, last_name;
Здесь данные будут сначала отсортированы по отделу, а затем по фамилии сотрудников внутри каждого отдела.
При использовании ORDER BY важно учитывать, что SQL сначала сортирует по первому указанному столбцу, затем по второму и так далее. Если столбец содержит одинаковые значения, сортировка продолжается по следующему в списке.
Чтобы изменить направление сортировки, укажите ASC для сортировки по возрастанию или DESC для убывающего порядка. Например:
SELECT * FROM employees ORDER BY hire_date DESC;
Этот запрос отсортирует сотрудников по дате их найма, начиная с самых последних.
Кроме того, можно сортировать данные по столбцам разных типов: числовым, текстовым, датам и т.д. SQL автоматически выбирает правильный порядок сортировки в зависимости от типа данных столбца. Например, для числовых данных сортировка будет производиться по величине, а для строк – по алфавиту.
Рекомендация: Если сортировка осуществляется по большим таблицам, важно учитывать, что это может повлиять на производительность. В таких случаях полезно индексировать столбцы, которые используются в ORDER BY.
В SQL оператор LIMIT позволяет ограничить количество строк, возвращаемых запросом. Это особенно полезно при работе с большими таблицами, когда необходимо получить только часть данных для анализа или оптимизации работы с базой. Например, можно получить первые 10 записей из таблицы с результатами или только последние 5 строк для проверки изменений.
Синтаксис использования LIMIT простой. Пример запроса, который возвращает первые 10 записей из таблицы «products»:
SELECT * FROM products LIMIT 10;
Также LIMIT может быть использован вместе с OFFSET, чтобы пропустить определённое количество строк и получить данные начиная с указанной позиции. Например, чтобы получить записи начиная с 11-й строки по 20-ю:
SELECT * FROM products LIMIT 10 OFFSET 10;
При этом важно помнить, что порядок строк в таблице не гарантирован, если в запросе не указано явное условие сортировки. Например, без использования ORDER BY, строки могут возвращаться в произвольном порядке. Поэтому всегда добавляйте оператор ORDER BY, если хотите контролировать последовательность данных.
LIMIT также используется для улучшения производительности при выполнении запросов на больших наборах данных. Например, при тестировании сложных запросов с большими объемами, можно использовать LIMIT для получения небольших выборок, что ускоряет разработку и проверку запросов.
Рекомендуется всегда указывать LIMIT, если нужно обработать только часть данных, чтобы избежать излишней нагрузки на систему. Однако будьте внимательны при использовании OFFSET, так как с увеличением его значения производительность может снижаться из-за того, что система должна пропускать множество строк перед тем, как вернуть результаты.
Как просмотреть структуру таблицы с помощью DESCRIBE
Команда DESCRIBE в SQL используется для получения информации о структуре таблицы, включая имена столбцов, их типы данных, а также информацию о том, могут ли столбцы содержать NULL-значения и какие ограничения на них наложены. Это полезно для анализа таблицы перед выполнением операций с данными.
Пример использования команды:
DESCRIBE имя_таблицы;
- Field – название столбца.
- Type – тип данных столбца (например, INT, VARCHAR, DATE и т.д.).
- Null – указание, можно ли записывать NULL в данный столбец (YES или NO).
- Key – информация о том, является ли столбец частью ключа (например, PRI – первичный ключ, UNI – уникальный ключ, NULL – нет ключа).
- Default – значение по умолчанию для столбца, если оно задано.
- Extra – дополнительная информация, такая как автоинкремент для числовых столбцов.
+------------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +------------+-------------+------+-----+---------+-------+ | id | int | NO | PRI | NULL | auto_increment | | name | varchar(255)| YES | | NULL | | | birth_date | date | YES | | NULL | | +------------+-------------+------+-----+---------+-------+
В этом примере столбец id является первичным ключом и имеет автоинкремент, а столбцы name и birth_date могут содержать NULL-значения.
Использование DESCRIBE полезно для анализа структуры базы данных перед выполнением сложных запросов, таких как объединения (JOIN), фильтрация данных или изменение схемы таблицы.
Вопрос-ответ:
Как открыть таблицу в SQL?
Для того чтобы просмотреть содержимое таблицы в SQL, используйте команду `SELECT`. Она позволяет выбрать данные из таблицы и вывести их на экран. Например, запрос `SELECT * FROM имя_таблицы;` отобразит все строки и столбцы таблицы. Если вам нужно вывести только определенные столбцы, используйте их имена вместо `*`. Пример: `SELECT имя_столбца1, имя_столбца2 FROM имя_таблицы;`.
Какие существуют способы фильтрации данных при просмотре таблицы в SQL?
В SQL можно использовать оператор `WHERE` для фильтрации данных. Это позволяет отобразить только те строки, которые соответствуют определенным условиям. Например, запрос `SELECT * FROM имя_таблицы WHERE возраст > 18;` отобразит только те записи, где возраст больше 18 лет. Также можно комбинировать условия с операторами `AND`, `OR` или использовать функции для более сложных фильтров.
Можно ли сортировать данные при просмотре таблицы в SQL?
Да, в SQL можно сортировать результаты с помощью оператора `ORDER BY`. Например, запрос `SELECT * FROM имя_таблицы ORDER BY имя_столбца;` отсортирует данные по указанному столбцу в порядке возрастания. Если нужно отсортировать данные в порядке убывания, добавьте `DESC` (например, `SELECT * FROM имя_таблицы ORDER BY имя_столбца DESC;`).
Как просмотреть только часть данных из таблицы в SQL?
Для того чтобы просмотреть только часть данных, можно использовать оператор `LIMIT`. Этот оператор позволяет ограничить количество возвращаемых строк. Например, запрос `SELECT * FROM имя_таблицы LIMIT 10;` выведет только первые 10 строк из таблицы. Также можно использовать `OFFSET` для пропуска определенного числа строк, например, `SELECT * FROM имя_таблицы LIMIT 10 OFFSET 20;` пропустит 20 строк и выведет следующие 10.