Ошибки в SQL запросах могут быть причиной различных проблем – от низкой производительности до неправильных результатов. Основной сложностью является то, что некоторые ошибки бывают неочевидными, что требует внимательного подхода к их обнаружению. Прежде чем приступать к исправлению, важно понять, как эффективно анализировать запросы, чтобы не пропустить детали, которые могут повлиять на итоговые данные.
1. Анализ синтаксических ошибок – это первый шаг, который нужно выполнить, если запрос не выполняется вообще. Многие ошибки возникают из-за неправильного использования ключевых слов, пропусков или ошибок в именах таблиц и полей. В SQL-системах часто присутствуют подсказки, которые показывают строку и позицию, где произошла ошибка. Важно внимательно читать сообщение об ошибке и проверить символы, которые могли быть вставлены неаккуратно, такие как лишние запятые или кавычки.
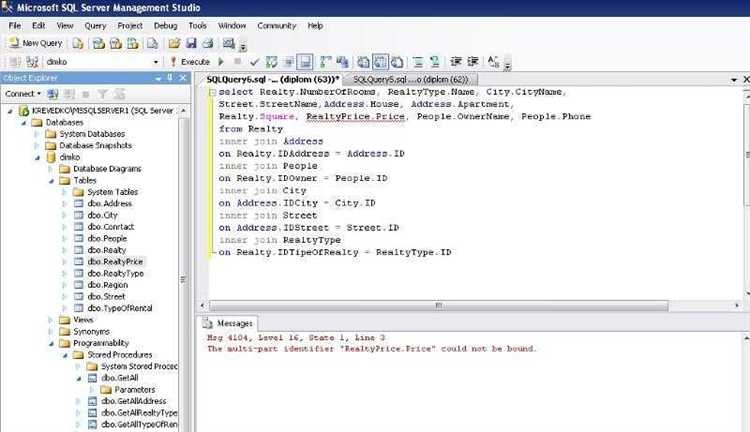
2. Оптимизация логики запроса начинается с того, чтобы внимательно проверить условия фильтрации, объединения таблиц и использования подзапросов. Например, часто ошибаются при использовании JOIN операторов, забывая про правильные условия для соединений, что может приводить к дублированию строк или неверному результату. Нужно также проверить, что индексы используются корректно, и что запрос не выполняет лишние операции, которые можно оптимизировать.
3. Проверка производительности запросов необходима, когда запрос работает, но его выполнение занимает слишком много времени. Использование инструментов профилирования, таких как EXPLAIN в MySQL или PostgreSQL, позволяет увидеть, какие части запроса являются узкими местами. Если запрос выполняет множество ненужных операций, таких как полные сканирования таблиц, необходимо оптимизировать использование индексов или переработать запрос для снижения затрат на выполнение.
Исправление ошибок в SQL запросах требует внимательности и системного подхода. Чем быстрее вы научитесь распознавать типичные ошибки и методы их исправления, тем эффективнее будут ваши запросы в будущем.
Проверка синтаксиса SQL запроса с помощью встроенных инструментов
Большинство современных СУБД имеют встроенные механизмы для проверки синтаксиса SQL-запросов. Эти инструменты помогают быстро идентифицировать ошибки на стадии написания запроса, что существенно упрощает процесс отладки и исправления ошибок. Важно использовать эти инструменты, чтобы минимизировать количество ошибок, связанных с синтаксисом и структурой запроса.
В MySQL встроенная команда EXPLAIN позволяет оценить структуру запроса и его исполнение, выявляя потенциальные проблемы с производительностью и синтаксисом. Она дает подробную информацию о том, как СУБД будет выполнять запрос, включая использование индексов и порядок соединений таблиц. Также полезна команда SHOW WARNINGS, которая отображает предупреждения о возможных проблемах в запросе, таких как устаревшие функции или синтаксические недочеты.
В PostgreSQL инструменты EXPLAIN и pgAdmin позволяют не только проверять синтаксис, но и анализировать план выполнения запроса. В pgAdmin можно использовать визуальный редактор запросов, который подскажет синтаксические ошибки в реальном времени. Кроме того, PostgreSQL генерирует подробные сообщения об ошибках, которые указывают на точное местоположение проблемы, что помогает быстрее устранить ошибку.
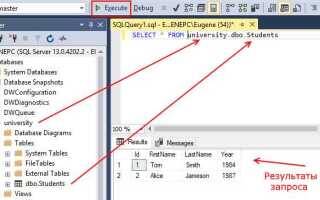
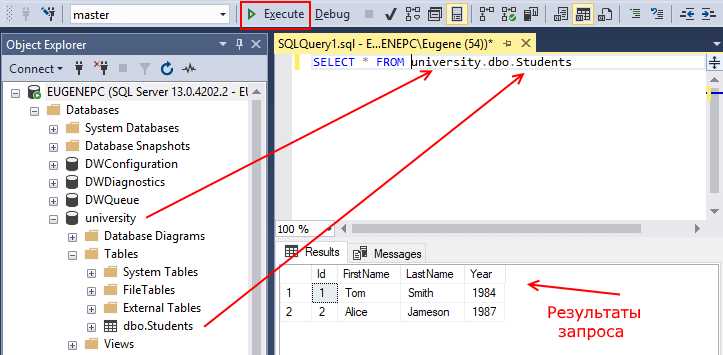
Для работы с SQL-запросами в MS SQL Server доступна опция «Parse» в SQL Server Management Studio. Она позволяет синтаксически проверить запрос до его выполнения. Если в запросе присутствуют ошибки, SSMS выдаст конкретное сообщение с указанием строки, где была обнаружена ошибка. Важно, что данная проверка не выполняет запрос, а только анализирует его на уровне синтаксиса.
В Oracle также доступна команда EXPLAIN PLAN, которая помогает анализировать запросы и выявлять проблемы на этапе синтаксического анализа. В случае ошибок в запросе Oracle предоставляет подробные сообщения с указанием ошибок и возможных мест их возникновения. Инструмент SQL Developer предоставляет встроенную функцию для автозаполнения и подсветки синтаксических ошибок в процессе написания запроса.
Использование этих встроенных инструментов ускоряет процесс отладки, помогает избежать распространенных ошибок и делает работу с запросами более удобной и эффективной.
Использование EXPLAIN для анализа выполнения запроса
Инструмент EXPLAIN позволяет получить детализированную информацию о том, как СУБД выполняет запрос. Это помогает выявить узкие места в производительности и улучшить эффективность запросов.
Основная цель использования EXPLAIN – понять, какие индексы используются, в каком порядке выполняются операции, а также оценить время выполнения запроса.
Для использования EXPLAIN достаточно перед запросом добавить ключевое слово EXPLAIN:
EXPLAIN SELECT * FROM employees WHERE department = 'HR';
После выполнения EXPLAIN, база данных отобразит план выполнения запроса. Важно понимать, как интерпретировать его результаты.
Основные элементы, которые следует анализировать:
- id – идентификатор запроса. В случае сложных запросов с несколькими подзапросами будет несколько записей с разными id.
- select_type – тип запроса (например, SIMPLE для простого запроса или SUBQUERY для подзапроса).
- table – таблица, к которой выполняется обращение. Помогает понять, какие таблицы участвуют в запросе.
- type – тип соединения. Важнейший параметр для анализа производительности. Хорошие значения:
const,eq_ref. Плохие значения:ALL(полное сканирование таблицы). - possible_keys – индексы, которые могут быть использованы для выполнения запроса. Если список пуст, возможно, запрос не использует индексы, что замедляет его выполнение.
- key – фактически используемый индекс. Если значение отличается от
NULL, это значит, что индекс был выбран для выполнения запроса. - rows – количество строк, которые необходимо обработать для выполнения запроса. Чем меньше это значение, тем быстрее будет выполнен запрос.
- Extra – дополнительная информация, например, использование файлового сортировки или объединения, которое может повлиять на производительность.
Пример анализа:
EXPLAIN SELECT name FROM employees WHERE department = 'HR';
Результат:
| id | select_type | table | type | possible_keys | key | rows | Extra | |----|-------------|-----------|-------|---------------|---------|------|-------------| | 1 | SIMPLE | employees | ref | department_idx| department_idx | 100 | Using where |
В данном примере видно, что для поиска сотрудников используется индекс department_idx, что оптимизирует выполнение запроса. Однако, если бы тип был ALL, это означало бы полное сканирование таблицы, что значительно медленнее.
Рекомендации по оптимизации:
- Используйте индексы для часто фильтруемых колонок.
- Проверьте наличие необязательных JOIN и замените их на подзапросы или скомпилированные запросы.
- Используйте EXPLAIN для анализа сложных запросов с несколькими JOIN, чтобы определить, какие из них стоит оптимизировать.
Использование EXPLAIN в процессе разработки и оптимизации запросов позволяет значительно улучшить их производительность и уменьшить нагрузку на систему. Регулярный анализ запросов с помощью этого инструмента помогает быстро выявлять и устранять потенциальные проблемы с производительностью.
Как интерпретировать ошибки и сообщения об ошибках от СУБД
Сообщения об ошибках от СУБД часто содержат информацию, которая поможет быстро локализовать проблему в запросе. Чтобы эффективно интерпретировать ошибки, важно понимать основные компоненты этих сообщений и то, как их можно использовать для исправления запроса.
1. Тип ошибки. СУБД обычно указывает тип ошибки, например, синтаксическая ошибка или ошибка выполнения. Синтаксические ошибки происходят, когда запрос не соответствует правилам SQL, тогда как ошибки выполнения часто связаны с данными или состоянием базы (например, нарушение ограничений целостности).
3. Сообщение об ошибке. Сообщение часто включает описание причины проблемы, например, «неожиданный символ», «неизвестный столбец» или «нарушение внешнего ключа». Если ошибка связана с отсутствием таблицы или столбца, СУБД укажет на конкретное место, где возникла ошибка, что упрощает поиск проблемы в запросе.
4. Использование контекста ошибки. Помимо основного сообщения, СУБД может включать дополнительные строки с подробным контекстом, например, указывая на строку или символ, где произошла ошибка. Например, если запрос имеет лишнюю запятую или закрывающую скобку, СУБД может указать на конкретное место.
5. Проверка документации СУБД. Каждая СУБД имеет свою специфику обработки ошибок. Важно обращаться к документации, чтобы понять, как правильно интерпретировать сообщения об ошибках, особенно когда код ошибки не очевиден или сообщение слишком общее.
6. Типичные ошибки и их исправление.
— Ошибка синтаксиса: Сюда относятся ошибки вроде неправильного расположения ключевых слов или пропущенных запятых. Например, ошибка «синтаксическая ошибка около ‘FROM’» часто означает, что ключевое слово или символ пропущены перед или после оператора.
7. Обработка ошибок на уровне клиента. При работе с СУБД важно правильно обрабатывать ошибки в клиентском приложении, чтобы предоставить пользователю более понятное сообщение, или, например, выполнить попытку исправления ошибки на основе информации, полученной от СУБД.
Системы управления базами данных предлагают множество различных типов сообщений об ошибках, и понимание их структуры и контекста – ключ к быстрому решению проблем с запросами.
Поиск ошибок в условиях JOIN и объединений таблиц
Ошибки при использовании условий JOIN часто связаны с неправильными ссылками на поля, ошибками в синтаксисе или неверным типом соединения. Для их поиска важно тщательно проверять каждое условие объединения.
Первое, на что стоит обратить внимание, – это правильность указания колонок в условии соединения. Часто ошибки возникают, если для объединения используются колонки с одинаковыми именами, но из разных таблиц. В таком случае важно указать полные имена с префиксом таблицы: например, `table1.id = table2.id` вместо `id = id`. Это помогает избежать неоднозначности при обработке запроса.
Второй распространенной ошибкой является использование неправильного типа соединения. В случае, если необходимо получить все строки из обеих таблиц, следует использовать `FULL OUTER JOIN`, а не `INNER JOIN`, который ограничивает результат только совпадающими строками. Если важно включать все строки из одной таблицы, а из другой – только те, что имеют соответствующие записи, то лучше использовать `LEFT JOIN` или `RIGHT JOIN` в зависимости от того, с какой таблицей вы хотите работать.
При сложных объединениях с несколькими таблицами могут возникнуть ошибки из-за несовпадения условий соединения. Например, если используются несколько условий `ON`, важно убедиться, что каждый из них корректно отражает логику объединения. Также стоит избегать избыточных условий, которые могут привести к дублированию строк или неправильному результату.
Еще одна частая ошибка – это игнорирование NULL-значений в колонках. Если одна из колонок в условии объединения может содержать NULL, стандартное сравнение через `=` не сработает. Вместо этого можно использовать конструкцию `IS NULL` или `IS NOT NULL`, чтобы корректно обработать такие случаи.
Важно также следить за производительностью запросов. Иногда чрезмерное использование соединений может приводить к значительным задержкам. В таких случаях стоит пересмотреть логику запроса, возможно, оптимизировать его, уменьшив количество объединений или используя индексы на ключевых столбцах.
Последний момент, который стоит проверить, – это правильность написания alias-ов таблиц. Когда используются псевдонимы для таблиц, важно убедиться, что они корректно указаны во всех частях запроса, включая условия соединений.
Как обнаружить и устранить проблемы с индексами и производительностью

Проблемы с индексами часто становятся причиной низкой производительности SQL-запросов. Чтобы выявить их, начните с анализа плана выполнения запроса с помощью команды EXPLAIN или аналогичной для вашей СУБД. Это поможет понять, какие индексы используются, а какие игнорируются.
Если запрос выполняется медленно, проверьте, используется ли индекс для операций WHERE, JOIN или ORDER BY. Для часто используемых столбцов создайте индексы, особенно если они часто участвуют в фильтрации или сортировке данных.
Иногда проблема кроется в отсутствии составных индексов, когда запрос использует несколько столбцов. Индексы, содержащие несколько колонок, могут существенно улучшить производительность. Однако, если индекс создан на неправильном порядке столбцов, его эффективность может снизиться. Столбцы, которые используются в условиях WHERE и в качестве первых аргументов для JOIN, должны быть в начале составного индекса.
Для поиска избыточных или неэффективных индексов используйте инструменты для мониторинга производительности, такие как SQL Server Management Studio, EXPLAIN в MySQL или ANALYZE в PostgreSQL. Удаление неиспользуемых индексов может ускорить операции вставки и обновления данных.
Не забывайте о том, что индексы могут замедлять обновления данных. При добавлении, изменении или удалении данных происходит обновление индексов, что увеличивает нагрузку на систему. Определите, какие индексы действительно нужны для конкретных запросов, и исключите ненужные.
Для эффективного использования памяти и ресурсов проверьте, не создаются ли избыточные индексы для одинаковых запросов. Индексы на маленьких таблицах могут не приносить заметного улучшения производительности, поэтому важно анализировать их на основе реальных данных и тестировать запросы с их применением.
Для оптимизации производительности запросов также можно рассмотреть использование частичных индексов или индексов с функциями. Это может существенно сократить количество данных, которые индексируются, и улучшить скорость выполнения запросов с фильтрацией по условиям.
Проверка правильности работы функций и агрегатных операций
При написании SQL-запросов важно не только правильно указать синтаксис, но и убедиться в корректной работе встроенных функций и агрегатных операций. Ошибки в их использовании могут привести к неверным результатам или замедлению выполнения запросов. Рассмотрим основные подходы к проверке их правильности.
1. Проверка корректности агрегации
Агрегатные функции, такие как SUM(), COUNT(), AVG(), MAX(), MIN(), часто используются для подсчета данных. Необходимо убедиться, что эти функции применяются только к числовым или соответствующим данным. Например, использование SUM() с текстовыми данными или с типом данных NULL приведет к ошибке или нежелательному результату.
2. Проверка наличия группы данных
Когда в запросе используются агрегатные функции вместе с GROUP BY, важно проверить, что все поля, которые не подвергаются агрегации, находятся в GROUP BY. Например, запрос SELECT name, COUNT(*) FROM employees GROUP BY department; будет работать корректно, но если забыть указать department в GROUP BY, результат может быть непредсказуемым.
3. Использование оконных функций
Оконные функции, такие как ROW_NUMBER(), DENSE_RANK(), RANK(), требуют внимания при проверке. Эти функции выполняются по частям набора данных (окон), и важно, чтобы разделение данных через PARTITION BY было логичным и соответствовало цели запроса. Неправильная настройка окна может привести к неверному расчету значений.
4. Проверка корректности типов данных
При работе с функциями типа DATE(), CONCAT(), COALESCE() и другими важно следить за правильностью типов данных. Например, если вы используете CONCAT() для соединения числовых значений, предварительно убедитесь, что они были преобразованы в строку. Ошибка преобразования данных приведет к тому, что запрос не выполнится или вернет ошибочные данные.
5. Использование вспомогательных функций для проверки
6. Тестирование на различных данных
После выполнения запроса с агрегатными функциями стоит протестировать его на различных наборах данных, включая граничные значения, пустые строки и NULL. Например, если функция должна игнорировать NULL значения, это стоит проверить, чтобы убедиться в правильности работы.
7. Анализ выполнения запроса
Важно также проверять план выполнения запроса, особенно если используются сложные функции. Иногда можно столкнуться с ситуацией, когда запрос с агрегатными функциями работает медленно. В таком случае поможет анализ выполнения запроса с помощью EXPLAIN или аналогичных инструментов, которые могут показать, какие части запроса требуют оптимизации.
Использование логирования и отладочных инструментов для поиска ошибок
Для анализа сбоев SQL-запросов необходимо включить расширенное логирование на уровне СУБД. В PostgreSQL активируйте параметры log_statement и log_min_error_statement в файле postgresql.conf, чтобы фиксировать все выполняемые запросы и ошибки исполнения. В MySQL используйте general_log и log_error для получения аналогичной информации.
Анализ логов позволяет отследить точный текст запроса, параметры, временные метки и сообщения об ошибках. Это упрощает локализацию проблем, особенно если ошибки не воспроизводятся в изолированной среде. Используйте фильтрацию по ключевым словам (syntax error, duplicate key, null constraint и пр.) для ускорения поиска нужных записей в больших логах.
В инструментах наподобие pgAdmin, DBeaver или DataGrip используйте встроенные средства профилирования и анализа выполнения. В PostgreSQL это EXPLAIN ANALYZE, в MySQL – EXPLAIN FORMAT=JSON. Они показывают порядок выполнения операций, индексы, стоимость запросов и узкие места.
Для динамических запросов используйте трассировку параметров. В Python – библиотека sqlalchemy.engine с включённым echo=True, в Java – логгеры JDBC с уровнями DEBUG или TRACE. Это даёт полное представление о финальной строке SQL и её переменных.
Никогда не ограничивайтесь только сообщением об ошибке. Проверяйте параметры подключения, уровень транзакции, поведение триггеров и хранимых процедур. Для сложных кейсов используйте трассировку выполнения запросов (например, pg_stat_statements в PostgreSQL) и журнал медленных запросов.
Вопрос-ответ:
Как найти ошибку в SQL-запросе, если результат не тот, который ожидаешь?
Если результат SQL-запроса отличается от ожидаемого, первым шагом стоит проверить синтаксис. Используйте средства разработки или SQL-редакторы с подсветкой синтаксиса, чтобы заметить возможные ошибки в написании запросов. Также важно убедиться, что используемые таблицы и поля существуют в базе данных и правильно написаны. Ошибки могут быть связаны с неверным использованием оператора JOIN или неправильно сформулированными условиями WHERE. Чтобы найти конкретную ошибку, попробуйте пошагово выполнять части запроса, начиная с простых SELECT-запросов, и постепенно усложнять их, добавляя условия.
Почему иногда SQL-запрос может работать с одной базой данных, но не с другой, хотя структуры одинаковы?
Разные базы данных могут иметь различные настройки, которые влияют на выполнение запросов. Например, в одной базе данных могут быть включены специфические индексы, которые ускоряют выполнение запроса, в другой — их нет. Также могут различаться версии СУБД, что может вызывать проблемы с совместимостью определенных функций или синтаксиса. Проверьте настройки вашей СУБД и версии используемого программного обеспечения, чтобы удостовериться, что запросы поддерживаются одинаково в разных средах.
Как найти и исправить ошибку в SQL-запросе с использованием агрегатных функций?
Ошибки при использовании агрегатных функций, таких как COUNT, SUM, AVG и других, часто возникают из-за неправильного указания группировки данных. Например, если в SELECT-запросе указаны агрегатные функции, но нет правильной директивы GROUP BY для группировки по нужным полям, это приведет к ошибке. Чтобы исправить это, нужно внимательно просмотреть запрос и убедиться, что все поля, которые не являются агрегатными функциями, включены в GROUP BY. Также стоит проверять, что агрегатные функции применяются к корректным данным (например, к числовым значениям, если это требуется для подсчета суммы).
Что делать, если SQL-запрос возвращает ошибку «Синтаксическая ошибка»?
Ошибки синтаксиса обычно происходят из-за неправильного порядка или отсутствия ключевых слов, таких как SELECT, FROM, WHERE и других, а также из-за пропущенных или лишних символов, например, запятых или кавычек. Чтобы исправить ошибку, внимательно проверьте структуру запроса и убедитесь, что все части запроса написаны правильно. Используйте SQL-редакторы с подсветкой синтаксиса для быстрого поиска ошибок. Часто такая ошибка возникает при забывании закрыть кавычки или скобки, либо из-за неправильного написания имен таблиц или полей.