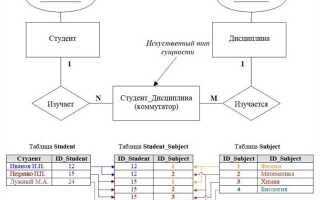
Связь типа «многие ко многим» не поддерживается напрямую в реляционных базах данных, поскольку нарушает принципы нормализации. Для корректной реализации используется промежуточная таблица, которая выступает в роли связующего звена между двумя основными сущностями. Такая таблица содержит как минимум два внешних ключа – каждый ссылается на первичный ключ одной из связанных таблиц.
Например, для моделирования отношений между студентами и курсами создаётся таблица student_course с колонками student_id и course_id. Каждое значение этих колонок – внешний ключ, ссылающийся на соответствующие таблицы students и courses. Чтобы избежать дублирующих записей, рекомендуется установить составной первичный ключ на эти два поля или добавить уникальное ограничение.
Для выполнения выборки данных по такой связи необходимо использовать оператор JOIN. Пример: чтобы получить список курсов, на которые записан конкретный студент, требуется выполнить INNER JOIN между таблицами students, student_course и courses по соответствующим ключам. Это позволяет извлекать связанные данные без нарушения целостности схемы.
Следует уделять внимание каскадному обновлению и удалению данных. Установка опций ON DELETE CASCADE и ON UPDATE CASCADE на внешние ключи помогает поддерживать согласованность при изменениях в связанных таблицах. При этом важно учитывать возможные последствия для производительности при больших объёмах данных.
Когда и зачем использовать связь многие ко многим
Связь многие ко многим применяется, когда один элемент первой сущности может быть связан с несколькими элементами второй, и наоборот. Примеры: студенты и курсы, авторы и книги, теги и статьи. В таких случаях невозможна реализация через прямой внешний ключ без потери данных или нарушения нормализации.
Использование этой связи оправдано, если:
1. Наблюдается динамическое множество связей. Когда количество ассоциаций между сущностями может изменяться произвольно – например, пользователь может подписаться на любое количество сообществ, а каждое сообщество содержит множество пользователей.
2. Необходимо хранить дополнительные данные о связи. Промежуточная таблица (например, user_course) может содержать дату добавления, статус или другие параметры, относящиеся не к сущностям, а к их связи.
3. Требуется гибкий анализ. Запросы по связи многие ко многим позволяют делать выборки, основанные на пересечениях, исключениях, фильтрации по дополнительным атрибутам связей – например, найти всех пользователей, которые прошли определённые курсы, но не другие.
4. Предотвращается дублирование данных. Без связи многие ко многим данные приходилось бы дублировать в виде множественных колонок или строк, нарушая первую нормальную форму (1NF) и усложняя обновления.
Итог: использовать связь многие ко многим следует в тех случаях, когда сущности находятся в симметричной, изменяемой и логически независимой ассоциации, которую невозможно выразить иными типами связей без ущерба для структуры данных и логики приложения.
Структура таблицы-связки: обязательные поля и ключи
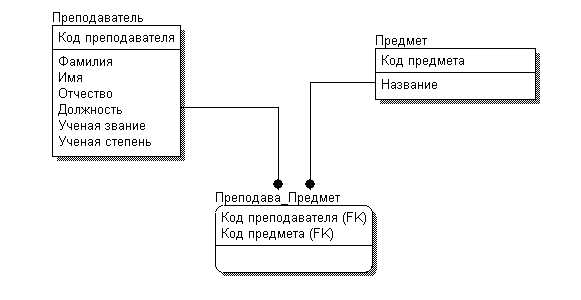
Таблица-связка необходима для корректного отображения связи многие ко многим между двумя сущностями. Её структура должна быть минималистичной и строго функциональной. Ниже приведены обязательные элементы, без которых связь теряет консистентность и эффективность.
- Внешние ключи (FOREIGN KEY): два поля, каждое из которых ссылается на первичный ключ соответствующей основной таблицы. Тип данных должен строго соответствовать типу первичного ключа родительской таблицы.
- Составной первичный ключ (PRIMARY KEY): объединение двух внешних ключей в один составной ключ исключает дублирование связей. Это предпочтительнее отдельного surrogate-ключа, если таблица не несёт дополнительной нагрузки.
- Индексы на внешние ключи: ускоряют операции соединения и поиска. Обычно создаются автоматически при объявлении внешних ключей, но стоит убедиться в их наличии и корректности.
Если таблица-связка должна хранить дополнительные атрибуты (например, дату создания связи), составной первичный ключ по-прежнему остаётся актуальным, но при этом необходимо добавить уникальный индекс на комбинацию внешних ключей для исключения дубликатов.
Имена полей должны быть однозначны и отражать семантику связи. Избегайте обобщённых названий вроде id1, id2; используйте user_id, role_id и т.п., чтобы структура была читаема без дополнительного контекста.
Создание связи многие ко многим с помощью FOREIGN KEY
Связь многие ко многим невозможно реализовать напрямую между двумя таблицами. Для этого требуется промежуточная таблица, содержащая внешние ключи на каждую из связанных таблиц. Эта таблица играет роль ассоциативной и позволяет управлять связями между записями.
- Создаются две основные таблицы, каждая из которых имеет первичный ключ. Например:
students(id)иcourses(id). - Создаётся третья таблица, например
student_courses, содержащая два столбца:student_idиcourse_id. - Оба столбца в
student_coursesобъявляются как FOREIGN KEY:student_idссылается наstudents(id)course_idссылается наcourses(id)
- Для исключения дубликатов добавляется составной PRIMARY KEY по обоим столбцам или UNIQUE-ограничение.
Пример SQL-запроса:
CREATE TABLE student_courses (
student_id INT NOT NULL,
course_id INT NOT NULL,
PRIMARY KEY (student_id, course_id),
FOREIGN KEY (student_id) REFERENCES students(id) ON DELETE CASCADE,
FOREIGN KEY (course_id) REFERENCES courses(id) ON DELETE CASCADE
);- PRIMARY KEY предотвращает дублирование пар
student_idиcourse_id. - ON DELETE CASCADE обеспечивает автоматическое удаление записей при удалении связанных объектов.
Такой подход гарантирует целостность данных и позволяет эффективно строить запросы для выборки связанных данных через JOIN.
Реализация связи через JOIN: пошаговый пример
Рассмотрим задачу: у нас есть студенты и курсы. Один студент может записаться на несколько курсов, а один курс может включать нескольких студентов. Это типичная связь многие ко многим.
Создаём три таблицы: students, courses и промежуточную таблицу student_courses.
Структура таблицы students: id (PRIMARY KEY), name.
Структура таблицы courses: id (PRIMARY KEY), title.
Структура таблицы student_courses: student_id, course_id. Оба поля – FOREIGN KEY, совместно образуют составной PRIMARY KEY.
Пример запроса, чтобы получить список студентов с их курсами:
SELECT
students.name AS student_name,
courses.title AS course_title
FROM
students
JOIN
student_courses ON students.id = student_courses.student_id
JOIN
courses ON courses.id = student_courses.course_id;
Важно: промежуточная таблица student_courses должна исключать дубли. Используйте ограничение PRIMARY KEY (student_id, course_id).
Добавление записи в связь:
INSERT INTO student_courses (student_id, course_id) VALUES (1, 3);Удаление связи между студентом и курсом:
DELETE FROM student_courses WHERE student_id = 1 AND course_id = 3;Для фильтрации, например, всех курсов студента по имени:
SELECT
courses.title
FROM
courses
JOIN
student_courses ON courses.id = student_courses.course_id
JOIN
students ON students.id = student_courses.student_id
WHERE
students.name = 'Иван';Добавление и удаление записей в таблицу-связку
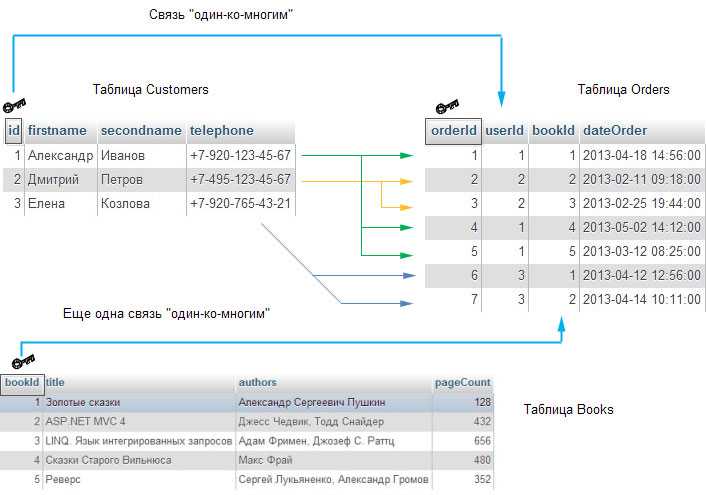
Для добавления связи между сущностями в модели многие ко многим используется оператор INSERT в таблицу-связку. Пример: если имеются таблицы students и courses, а таблица-связка называется student_course, то добавление студента с student_id = 5 к курсу с course_id = 3 выполняется так:
INSERT INTO student_course (student_id, course_id) VALUES (5, 3);
Если в таблице-связке заданы ограничения уникальности по паре ключей, попытка вставить дублирующую запись приведёт к ошибке. Чтобы избежать этого, используйте INSERT ... ON CONFLICT DO NOTHING (PostgreSQL) или INSERT IGNORE (MySQL).
Удаление связи осуществляется через DELETE. Чтобы разорвать конкретную связь, например между студентом и курсом:
DELETE FROM student_course WHERE student_id = 5 AND course_id = 3;
Удаление всех связей студента или всех курсов определённого типа осуществляется выбором нужного условия. Пример – удалить все курсы для студента:
DELETE FROM student_course WHERE student_id = 5;
При проектировании убедитесь, что внешние ключи в таблице-связке используют ON DELETE CASCADE, если необходимо автоматическое удаление связей при удалении основной записи.
Избежание дублирующихся записей при вставке данных
Для эффективной работы с базами данных важно предотвращать появление дублирующихся записей, особенно при вставке данных. Проблема дублирования может возникнуть в связях «многие ко многим», где данные часто вставляются в несколько таблиц одновременно.
Первое, что следует учитывать, это использование ограничения UNIQUE на столбцах, которые не могут содержать одинаковые значения. Например, в связующей таблице для связи между двумя сущностями можно применить UNIQUE к комбинации внешних ключей. Это гарантирует, что одна пара значений будет присутствовать только один раз.
Кроме того, важным механизмом для предотвращения дублирования является использование ON CONFLICT в SQL-запросах. Например, при вставке записи в PostgreSQL можно использовать конструкцию INSERT … ON CONFLICT DO NOTHING, которая автоматически исключит вставку, если запись с такими же значениями уже существует в базе данных.
Для работы с MySQL подход будет немного отличаться. В MySQL аналогичную задачу можно решить с помощью INSERT IGNORE, что предотвращает ошибку, если запись с такими же значениями уже существует, и просто игнорирует её вставку.
Если требуется обновление данных при дублировании, можно использовать ON DUPLICATE KEY UPDATE в MySQL. Это позволяет обновить поля существующей записи, если вставляемая запись уже существует, с минимальными затратами на выполнение.
Рекомендуется также использовать транзакции для группировки вставок данных в одном запросе, что позволит откатить изменения в случае ошибок или дублирования. Важно тщательно продумать логику вставки и обновления, чтобы избежать лишней нагрузки на базу данных.
Еще одной мерой защиты от дублирования может быть использование проверок на стороне приложения. Перед вставкой данных в базу можно выполнить запрос, который проверит существование необходимых записей. Однако этот подход не всегда подходит для высоконагруженных систем, где требуется минимизация запросов.
Проверка существующих связей через SQL-запросы
Для проверки существующих связей в таблицах, участвующих в связи многие ко многим, важно использовать SQL-запросы, которые позволяют не только убедиться в наличии связи, но и получить подробную информацию о её параметрах. В типичной реализации такой связи имеется промежуточная таблица, которая содержит идентификаторы связанных сущностей. Например, если у нас есть таблицы «пользователи» и «группы», то промежуточная таблица может называться «пользователь_группа» и содержать пары (user_id, group_id).
Для того чтобы проверить, какие пользователи состоят в каких группах, можно выполнить следующий запрос:
SELECT user_id, group_id FROM user_group;
Этот запрос вернёт все записи о существующих связях между пользователями и группами. Важно учитывать, что в данном случае возвращаемые значения представляют собой комбинацию идентификаторов из двух таблиц, но не дают представления о других атрибутах этих сущностей. Если необходимо получить более подробную информацию, можно использовать JOIN:
SELECT u.user_id, u.name AS user_name, g.group_id, g.name AS group_name FROM user_group ug JOIN users u ON ug.user_id = u.user_id JOIN groups g ON ug.group_id = g.group_id;
Этот запрос вернёт имена пользователей и группы, к которым они принадлежат. Такой подход полезен, если нужно не только удостовериться в наличии связи, но и проанализировать связанные данные из разных таблиц.
Если необходимо проверить, состоит ли конкретный пользователь в определённой группе, можно использовать запрос с условием:
SELECT 1 FROM user_group WHERE user_id = ? AND group_id = ?;
Если запрос возвращает строку, это означает, что связь существует. В противном случае связь отсутствует. Этот метод полезен для быстрого поиска конкретных связей.
Для проверки всех уникальных связей между пользователями и группами можно использовать следующий запрос:
SELECT DISTINCT user_id, group_id FROM user_group;
Этот запрос обеспечит уникальные пары значений user_id и group_id, исключая дубликаты, что позволяет убедиться в корректности и полноте связей между сущностями. В случае, если в промежуточной таблице записывается большое количество связей, данный запрос поможет выявить повторяющиеся записи и уменьшить вероятность ошибок.
Для сложных проверок на наличие связей между несколькими таблицами можно комбинировать несколько JOIN-запросов, а также использовать агрегатные функции для получения статистики о количестве связей, например:
SELECT g.group_id, COUNT(ug.user_id) AS user_count FROM user_group ug JOIN groups g ON ug.group_id = g.group_id GROUP BY g.group_id;
Этот запрос покажет, сколько пользователей состоит в каждой группе. Подобные запросы полезны для анализа распределения данных и проверки корректности работы связей многие ко многим в системе.
Вопрос-ответ:
Что такое связь многие ко многим в SQL?
Связь многие ко многим в SQL описывает отношение между двумя таблицами, где одна запись в первой таблице может быть связана с несколькими записями во второй таблице, и наоборот. Для реализации такой связи необходимо использовать промежуточную таблицу, которая будет содержать внешние ключи обеих таблиц. Например, если у нас есть таблица студентов и таблица курсов, то связь многие ко многим позволит одному студенту записаться на несколько курсов, а каждый курс может включать несколько студентов.
Как выглядит структура базы данных для связи многие ко многим?
Структура базы данных для связи многие ко многим состоит как минимум из трех таблиц: двух основных таблиц и одной промежуточной. Например, если у нас есть таблицы «студенты» и «курсы», то для реализации связи многие ко многим нам нужна третья таблица, которая будет включать внешние ключи к обеим таблицам. Таблица «студенты» может содержать столбцы для имени и ID студента, таблица «курсы» — для названия курса и его ID, а промежуточная таблица будет содержать столбцы с ID студента и ID курса. Такой подход позволяет хранить множественные связи между студентами и курсами.
Почему для связи многие ко многим используется промежуточная таблица?
Промежуточная таблица необходима для того, чтобы избежать дублирования данных и правильно организовать связи между записями. В случае, если бы связь реализовывалась напрямую через внешние ключи в каждой из основных таблиц, данные могли бы стать неструктурированными и неудобными для управления. Промежуточная таблица позволяет хранить ссылки на связанные записи в обеих таблицах, обеспечивая нормализацию данных и их правильное представление в базе.
Как реализовать связь «многие ко многим» в SQL?
Для реализации связи «многие ко многим» в SQL используется промежуточная таблица, которая содержит внешние ключи для обеих таблиц, между которыми устанавливается связь. Например, если у нас есть таблицы «студенты» и «курсы», то для связи между ними создаём таблицу «студенты_курсы», которая будет содержать два поля: «студент_id» и «курс_id». Эти поля будут внешними ключами, указывающими на первичные ключи соответствующих таблиц. Такая структура позволяет каждому студенту быть записанным на несколько курсов и наоборот, каждому курсу может быть присвоено несколько студентов.