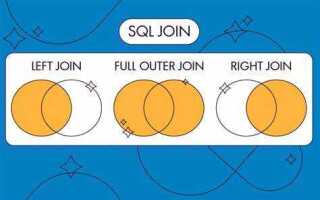
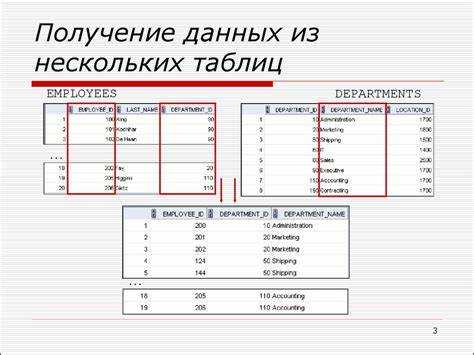
В реляционных базах данных информация часто распределена между несколькими таблицами. Для извлечения полной картины требуется объединение данных с помощью оператора JOIN. Например, таблица orders может содержать информацию о заказах, а таблица customers – о клиентах. Чтобы получить список заказов с именами клиентов, необходимо связать эти таблицы по полю customer_id.
Оператор INNER JOIN используется, когда важно получить только те строки, которые имеют соответствие в обеих таблицах. В случае, если нужно включить все строки из одной таблицы и только совпадающие – из другой, применяются LEFT JOIN или RIGHT JOIN. Их выбор зависит от приоритетной таблицы, в зависимости от контекста задачи.
При объединении таблиц критически важно использовать индексы на соединяемых полях – это ускоряет выполнение запросов, особенно при работе с большими объёмами данных. Кроме того, следует явно указывать имена таблиц или использовать алиасы, чтобы избежать неоднозначности при обращении к одноимённым столбцам.
Для повышения читаемости и удобства отладки рекомендуется разбивать JOIN-запросы на логические блоки: сначала FROM, затем JOIN с условиями ON, а после – фильтрация WHERE и сортировка ORDER BY. Такой подход облегчает сопровождение кода и уменьшает вероятность логических ошибок.
Как работает INNER JOIN на примере таблиц сотрудников и отделов
Рассмотрим две таблицы: employees и departments. Таблица employees содержит столбцы id, name, department_id. Таблица departments – столбцы id, department_name.
Цель – получить список сотрудников вместе с названиями отделов, в которых они работают. Для этого используется INNER JOIN, который объединяет строки двух таблиц только при совпадении значений в указанных столбцах.
SELECT
employees.name,
departments.department_name
FROM
employees
INNER JOIN
departments
ON
employees.department_id = departments.id;Запрос выбирает только те строки, где department_id из employees совпадает с id из departments. Сотрудники без привязки к отделу исключаются из результата.
Если в таблице employees есть строка с department_id = 3, а в departments отсутствует id = 3, то этот сотрудник не попадёт в результат. Это ключевое отличие INNER JOIN от других типов объединения.
Такой подход эффективен для выборки актуальных данных, где критична связь между сущностями. Он снижает риск получения неполной или некорректной информации, которая могла бы возникнуть при использовании LEFT JOIN без должной фильтрации.
Разница между LEFT JOIN и RIGHT JOIN при неполных данных
LEFT JOIN возвращает все строки из левой таблицы, даже если в правой нет соответствующих значений. Это особенно полезно при анализе первичных данных, когда необходимо сохранить полный набор записей основной таблицы, например, список всех клиентов вне зависимости от наличия у них заказов.
RIGHT JOIN работает наоборот: приоритет отдаётся правой таблице. Он применяется реже, но может быть удобен, если правая таблица содержит важные справочные или агрегированные данные, которые должны отображаться полностью, несмотря на отсутствие связей в левой таблице.
При наличии NULL-значений в ключевых столбцах поведение JOIN зависит от типа объединения. LEFT JOIN сохранит строку с NULL-ключом в левой таблице, но RIGHT JOIN её проигнорирует, если аналогичного ключа нет в правой.
Выбор между LEFT и RIGHT JOIN определяется не только структурой запроса, но и логикой анализа: от какой таблицы нужно отталкиваться как от основы. Практически всегда можно добиться одного и того же результата с обоими типами JOIN, но читаемость и поддерживаемость кода страдают, если выбор сделан неосознанно.
Рекомендуется избегать RIGHT JOIN в проектах с единой структурой данных: он затрудняет чтение и может вызвать ошибки при объединении с подзапросами или CTE. LEFT JOIN лучше согласуется с логикой «слева – основное, справа – дополнительное».
Применение FULL OUTER JOIN для объединения всех записей из двух таблиц
Оператор FULL OUTER JOIN используется для объединения всех строк из обеих таблиц, включая те, у которых нет совпадающих значений по ключевому полю. В результирующем наборе будут присутствовать как совпадающие записи, так и строки с одной из сторон, где отсутствует соответствие, при этом недостающие значения заполняются NULL.
Пример: требуется объединить таблицы employees и contractors по полю email, чтобы получить полную картину всех участников проекта, независимо от их статуса. Запрос будет выглядеть так:
SELECT *
FROM employees
FULL OUTER JOIN contractors
ON employees.email = contractors.email;Рекомендуется явно указывать нужные поля вместо использования *, чтобы избежать неоднозначностей и повысить читаемость. Например:
SELECT
employees.name AS employee_name,
contractors.name AS contractor_name,
COALESCE(employees.email, contractors.email) AS contact_email
FROM employees
FULL OUTER JOIN contractors
ON employees.email = contractors.email;Функция COALESCE позволяет выбрать первое ненулевое значение, что особенно полезно при объединении данных, где email может отсутствовать в одной из таблиц.
FULL OUTER JOIN следует использовать, когда необходимо сохранить как строки с совпадениями, так и все строки без соответствий. Это особенно важно при сравнении двух источников данных, учёте различий или построении отчётов с полной выборкой.
Использование JOIN с условиями на несколько столбцов
Для соединения таблиц по нескольким критериям в SQL применяются сложные условия в операторе ON. Вместо простого сравнения одного столбца, указываются несколько условий через AND, что обеспечивает точную фильтрацию строк при объединении.
Например, чтобы соединить таблицы orders и shipments по совпадению не только идентификатора заказа, но и даты отгрузки:
SELECT *
FROM orders o
JOIN shipments s
ON o.order_id = s.order_id
AND o.ship_date = s.ship_dateВажно следить за типами данных всех участвующих столбцов: несовпадение типов может привести к неоптимальному плану выполнения запроса. Использование функций над столбцами в условиях соединения (например, DATE() или CAST()) приводит к потере возможности использования индексов. Предпочтительно приводить значения к нужному формату заранее, до выполнения JOIN.
Если один из столбцов может содержать NULL, необходимо учитывать, что сравнение с NULL в условии соединения всегда возвращает FALSE. Для таких случаев используйте IS NULL или COALESCE(), если логика позволяет подставить значение по умолчанию.
При написании многокритериальных условий стоит помнить о порядке: хотя SQL не требует определённого порядка условий в ON, для читаемости лучше располагать их по степени значимости или частоте использования в индексах.
Проверяйте план выполнения запроса через EXPLAIN, чтобы убедиться, что соединение происходит эффективно и используются нужные индексы. Неправильно составленное условие на несколько столбцов может привести к полному сканированию таблиц и значительным задержкам при больших объёмах данных.
Как использовать алиасы таблиц для повышения читаемости запросов
Алиасы таблиц (псевдонимы) позволяют упростить SQL-запросы, особенно при соединении нескольких таблиц с длинными или однотипными именами. Они задаются с помощью ключевого слова AS или просто через пробел после имени таблицы.
- Сокращение повторяющихся имён: Вместо многократного указания длинного имени таблицы можно использовать короткий алиас. Это снижает визуальную нагрузку и ускоряет чтение.
- Избежание неоднозначности: При соединении таблиц с одинаковыми названиями колонок (например,
id,name) алиасы необходимы для явного указания источника данных. - Повышение логичности структуры: При использовании мнемонических алиасов (например,
uдляusers,oдляorders) становится легче следить за логикой запроса.
Пример без алиасов:
SELECT users.name, orders.total
FROM users
JOIN orders ON users.id = orders.user_id
WHERE users.active = true;Тот же запрос с алиасами:
SELECT u.name, o.total
FROM users u
JOIN orders o ON u.id = o.user_id
WHERE u.active = true;Рекомендации по использованию:
- Выбирайте короткие, но понятные алиасы –
cдляcustomers,pдляproducts. - Избегайте односимвольных алиасов при работе с более чем двумя таблицами – это снижает читаемость.
- Используйте одинаковые алиасы по всей кодовой базе – это улучшает навигацию и сопровождение.
- Прописывайте алиасы сразу после имени таблицы – это повышает однозначность кода.
Алиасы – не косметика, а инструмент ясности и точности. Они особенно ценны в подзапросах, CTE и сложных аналитических выборках.
Типичные ошибки при соединении таблиц и способы их устранения
При работе с SQL и соединении таблиц с помощью JOIN возникают несколько распространённых ошибок. Их устранение требует внимательности и понимания структуры данных.
Ошибка 1: Пропуск условия соединения
Одной из самых частых ошибок является забывание указания условия соединения (ON). Это приводит к получению декартова произведения, где каждая строка первой таблицы соединяется с каждой строкой второй. В результате можно получить огромное количество данных, которые не имеют смысла.
Решение: всегда указывайте корректное условие соединения, например, ON table1.id = table2.id.
Ошибка 2: Использование неверного типа соединения
Неправильный выбор типа соединения может привести к потере данных или, наоборот, к ненужному их дублированию. Например, при использовании LEFT JOIN вместо INNER JOIN, можно получить строки, которые не соответствуют ни одной записи из второй таблицы.
Решение: внимательно выбирайте тип соединения в зависимости от требований задачи. Используйте INNER JOIN для получения только совпадающих записей, LEFT JOIN для получения всех записей из первой таблицы, включая те, которые не имеют соответствий во второй.
Ошибка 3: Несоответствие типов данных
При соединении таблиц важно, чтобы поля, по которым происходит соединение, имели одинаковые типы данных. Несоответствие типов, например, соединение строкового поля с числовым, может вызвать ошибки выполнения или неверные результаты.
Решение: убедитесь, что типы данных в соединяемых столбцах совпадают. Если это не так, преобразуйте данные с помощью функции CAST или CONVERT.
Ошибка 4: Неоднозначность столбцов с одинаковыми именами
Если обе таблицы содержат столбцы с одинаковыми именами, SQL не сможет правильно идентифицировать, к какой таблице относится тот или иной столбец. Это может привести к ошибке или неверному результату запроса.
Решение: всегда используйте алиасы для таблиц и указывайте их перед именами столбцов. Например, table1.name и table2.name.
Ошибка 5: Неправильное использование WHERE и JOIN
Некоторые разработчики ошибочно помещают условие соединения в блок WHERE, что изменяет логику запроса и приводит к неожиданным результатам. Например, при использовании INNER JOIN, условие соединения должно быть в блоке ON, а не в WHERE.
Решение: соблюдайте правильную структуру запроса: условия соединения указывайте в ON, а фильтрацию данных – в WHERE.
Ошибка 6: Несоответствие логики объединения и фильтрации
Иногда условие в блоке WHERE может влиять на результат объединения данных, особенно при использовании LEFT JOIN. Это может привести к тому, что записи, которые должны быть включены в результат, будут исключены из-за условий фильтрации.
Решение: если используете LEFT JOIN, проверяйте, что условия фильтрации не исключают строки из первой таблицы, которые не имеют соответствий во второй.
Ошибка 7: Избыточные соединения
Часто встречается ситуация, когда одна и та же таблица соединяется несколько раз в одном запросе без необходимости. Это может существенно снизить производительность и сделать запрос сложным для понимания.
Решение: избегайте ненужных соединений, а если это необходимо, оптимизируйте запрос, используя подзапросы или временные таблицы.
Каждая из этих ошибок имеет конкретные решения, которые помогают избежать значительных проблем с производительностью и правильностью данных. Важно учитывать особенности данных и всегда тестировать запросы на небольших объемах информации перед запуском на больших таблицах.
Объединение более двух таблиц с помощью последовательных JOIN
Для объединения более двух таблиц в SQL используется техника последовательных JOIN. Каждый JOIN выполняет связь двух таблиц, и результат может быть передан следующему JOIN для объединения с третьей таблицей, и так далее. Этот метод позволяет гибко работать с несколькими таблицами, создавая сложные запросы для извлечения данных.
Основные принципы работы с последовательными JOIN:
- Каждый JOIN возвращает промежуточный результат, который затем может быть использован в следующем объединении.
- При объединении нескольких таблиц важно правильно указывать условия связи между ними. Обычно используется одинаковый столбец для каждой пары таблиц.
- При использовании последовательных JOIN важно учитывать порядок объединений, так как это влияет на производительность и корректность результатов.
Рассмотрим пример объединения трех таблиц:
SELECT * FROM таблица1 JOIN таблица2 ON таблица1.id = таблица2.id JOIN таблица3 ON таблица2.id = таблица3.id;
В данном примере:
- Первая операция – это соединение таблицы1 и таблицы2 по столбцу id.
- Затем результат этого соединения используется для объединения с таблицей3 по тому же столбцу id.
Советы по оптимизации запросов с несколькими JOIN:
- Всегда указывайте явные условия соединения, чтобы избежать неявных соединений, которые могут привести к увеличению объема данных.
- Используйте INNER JOIN, когда нужно вернуть только те строки, которые присутствуют в обеих таблицах. Это снижает количество ненужных данных.
- Если требуется вернуть все строки из одной таблицы и только совпадающие данные из другой, используйте LEFT JOIN или RIGHT JOIN.
При работе с большим количеством таблиц важно контролировать порядок объединений, чтобы избежать излишней нагрузки на систему и гарантировать точность данных.
Для сложных запросов с множественными JOIN часто применяют оптимизацию с помощью индексов на столбцах, по которым происходит соединение. Это помогает значительно ускорить выполнение запросов.
Вопрос-ответ:
Что такое SQL JOIN и для чего он используется?
SQL JOIN — это операция, которая позволяет объединить данные из двух или более таблиц на основе определённого условия. Это может быть полезно, например, для того, чтобы получить информацию о пользователях и их заказах, если они хранятся в разных таблицах. В зависимости от типа JOIN можно настроить, какие строки из таблиц будут возвращены в результирующем наборе данных.
Какой тип соединения в SQL позволяет вернуть все строки из обеих таблиц?
Для того чтобы вернуть все строки из обеих таблиц, используется оператор FULL JOIN. Этот тип соединения возвращает все строки из обеих таблиц, даже если в одной из таблиц нет соответствующих данных для соединения. Если совпадений не найдено, в соответствующих столбцах появятся NULL-значения.
Что такое INNER JOIN и чем он отличается от других типов JOIN?
INNER JOIN — это тип соединения, при котором в результирующий набор данных попадают только те строки, для которых существует совпадение по ключевым полям в обеих таблицах. Это означает, что если в одной из таблиц нет соответствующих данных для соединения, такие строки исключаются из результата. В отличие от других типов JOIN, например, LEFT JOIN или FULL JOIN, INNER JOIN не включает в выборку строки без совпадений в обеих таблицах.
Как можно объединить данные из нескольких таблиц в SQL, используя LEFT JOIN?
LEFT JOIN в SQL позволяет объединить таблицы таким образом, что все строки из левой таблицы будут присутствовать в результирующем наборе данных, даже если для некоторых из них нет соответствующих строк в правой таблице. Если в правой таблице нет совпадений, то в соответствующих столбцах будут отображаться NULL-значения. Этот тип соединения полезен, например, для того, чтобы получить все данные из одной таблицы и при этом добавить только те данные, которые совпадают с другой таблицей.
Что такое SQL JOIN и для чего он используется?
SQL JOIN — это операция, которая позволяет объединить строки из двух или более таблиц в базе данных на основе связанного столбца. JOIN используется для выполнения запросов, которые требуют информации из нескольких таблиц. Например, можно соединить таблицы заказов и клиентов, чтобы получить данные о покупках каждого клиента. С помощью JOIN можно выбрать только те записи, которые соответствуют условию соединения, например, совпадение идентификаторов клиентов в обеих таблицах.