В SQL существует возможность использовать операцию соединения (JOIN) для работы с одной таблицей, что позволяет эффективно решать задачи, требующие сравнения или агрегации данных внутри одной и той же структуры. Это соединение называется само-соединением (self-join), и оно применяется, когда необходимо сопоставить строки одной таблицы на основе какого-либо общего признака.
Чтобы выполнить само-соединение, нужно в запросе указать таблицу дважды с использованием псевдонимов. Это позволит создать два экземпляра таблицы, которые могут быть связаны между собой. Псевдонимы используются для различения этих экземпляров, что позволяет обращаться к каждому из них независимо.
Пример: Если у вас есть таблица сотрудников, и необходимо найти пары сотрудников, работающих в одном отделе, можно использовать само-соединение. В этом случае один экземпляр таблицы будет представлять первого сотрудника, а второй – второго. Для фильтрации данных можно использовать условие соединения, которое проверяет совпадение значений, например, идентификаторов отделов.
При использовании само-соединения важно внимательно подходить к выбору условий соединения, чтобы избежать получения избыточных данных. Также стоит учесть, что само-соединения могут быть ресурсоёмкими, если таблица содержит большое количество строк, поэтому рекомендуется использовать индексы на столбцы, которые участвуют в условии соединения.
Как создать самосоединение (self-join) в SQL

Самосоединение (self-join) позволяет связать таблицу с самой собой. Это полезно, когда необходимо получить данные из одной таблицы в зависимости от значений в той же таблице. Для создания самосоединения используется оператор JOIN, но таблица в запросе упоминается дважды с разными псевдонимами.
Пример: таблица employees, которая содержит информацию о сотрудниках, и в ней есть поле manager_id, ссылающееся на employee_id тех, кто управляет этим сотрудником. Чтобы получить список сотрудников вместе с именами их менеджеров, нужно использовать самосоединение:
SELECT e.employee_id, e.name AS employee_name, m.name AS manager_name FROM employees e LEFT JOIN employees m ON e.manager_id = m.employee_id;
В этом запросе таблица employees используется дважды: первый раз с псевдонимом e для сотрудников, второй – с псевдонимом m для менеджеров. Условие соединения e.manager_id = m.employee_id позволяет связать сотрудников с их менеджерами.
Если в таблице есть строка, в которой manager_id равно NULL, такой сотрудник не будет иметь менеджера. В таком случае в результате запроса значение в колонке manager_name будет равно NULL, если используется LEFT JOIN.
Важно помнить, что самосоединение может быть ресурсоёмким, особенно при работе с большими таблицами. Для повышения производительности можно использовать индексы на полях, участвующих в условии соединения, например, на employee_id и manager_id.
Использование alias для идентификации двух копий таблицы
Когда таблица соединяется сама с собой, важно различать ее копии, чтобы избежать путаницы при обращении к столбцам. Для этого используется alias – псевдонимы, которые позволяют назначить удобные имена таблицам в SQL-запросах. Alias помогает сэкономить время и улучшить читаемость кода.
При соединении таблицы с самой собой, например, при поиске связей между записями одного и того же набора данных, каждый экземпляр таблицы должен быть обозначен уникальным alias. Это важно для правильного указания столбцов, особенно если их имена одинаковые. Например, при попытке найти сотрудников и их руководителей в одной таблице сотрудников, таблица может быть соединена с самой собой.
Пример запроса с alias:
SELECT e1.name AS employee, e2.name AS manager FROM employees e1 JOIN employees e2 ON e1.manager_id = e2.id;
Здесь «e1» и «e2» – это alias для двух копий таблицы «employees». Важно, что каждая копия таблицы имеет свой alias, который позволяет точно указать, к какому столбцу из какой копии мы обращаемся. В данном примере столбцы «name» из двух копий таблицы «employees» обозначаются как «employee» и «manager» для удобства.
Также стоит помнить, что alias можно использовать не только для таблиц, но и для столбцов. Это помогает избежать ошибок, когда столбцы двух копий таблицы имеют одинаковые имена. Например:
SELECT e1.name AS employee, e2.name AS manager FROM employees e1 JOIN employees e2 ON e1.manager_id = e2.id WHERE e1.department = 'HR';
Таким образом, alias для таблиц упрощает код, делает его более понятным и удобным для восприятия, особенно при сложных запросах с несколькими соединениями. Применение alias также способствует улучшению производительности, поскольку позволяет избежать повторного указания полных имен таблиц и повышает читаемость SQL-запросов.
Пример самосоединения с использованием INNER JOIN
Самосоединение в SQL позволяет связать таблицу с самой собой. Это особенно полезно, когда необходимо сравнить строки внутри одной таблицы, например, для выявления зависимостей между записями. Рассмотрим пример использования оператора INNER JOIN для самосоединения.
Предположим, у нас есть таблица employees с колонками:
employee_id– уникальный идентификатор сотрудникаname– имя сотрудникаmanager_id– идентификатор руководителя, который является такжеemployee_id
Задача: вывести имена сотрудников и их руководителей.
Для этого используем самосоединение:
SELECT e.name AS employee_name, m.name AS manager_name
FROM employees e
INNER JOIN employees m
ON e.manager_id = m.employee_id;
В данном запросе:
e– алиас для первой копии таблицы, представляющей сотрудниковm– алиас для второй копии таблицы, которая содержит информацию о руководителях
Условие соединения (ON e.manager_id = m.employee_id) позволяет сопоставить каждого сотрудника с его руководителем, где manager_id сотрудника совпадает с employee_id руководителя.
Результат выполнения запроса покажет список сотрудников и их руководителей, например:
- Иванов – Петров
- Сидоров – Иванов
- Кузнецова – Петров
Использование INNER JOIN гарантирует, что в результат попадут только те строки, где найдены соответствующие пары сотрудник-руководитель.
Применение LEFT JOIN для самосоединений с пропущенными значениями
LEFT JOIN позволяет объединить таблицу с самой собой, сохраняя все строки из левой таблицы, даже если для них не найдены соответствия в правой. Это особенно полезно, когда нужно учитывать строки с пропущенными значениями в связанных столбцах. В таких случаях используется самосоединение, когда одна и та же таблица объединяется с собой, но результаты объединения могут содержать пропуски.
Предположим, у нас есть таблица сотрудников, где для каждого сотрудника указано его имя и идентификатор его менеджера. Нам нужно получить список всех сотрудников с именем их менеджера. В случае, если сотрудник не имеет менеджера (например, это CEO), для него в результате соединения будет отображаться пустое значение.
Пример запроса:
SELECT e1.имя AS сотрудник, e2.имя AS менеджер FROM сотрудники e1 LEFT JOIN сотрудники e2 ON e1.менеджер_id = e2.id;
В данном запросе таблица «сотрудники» объединяется сама с собой. Столбцы e1 и e2 представляют два экземпляра одной и той же таблицы. LEFT JOIN обеспечивает, что все сотрудники из e1 будут включены в результат, независимо от того, есть ли у них соответствующий менеджер в e2. Если менеджера нет, в соответствующем столбце будет NULL.
Для корректной работы самосоединений с пропущенными значениями важно понимать, что использование LEFT JOIN в таких ситуациях помогает избежать исключения строк с NULL значениями, которые могли бы быть удалены при использовании INNER JOIN. Это гарантирует, что вся информация о сотрудниках, включая тех, кто не имеет менеджеров, будет сохранена в результате.
Также стоит учитывать, что в больших таблицах самосоединение может привести к значительным затратам на производительность. Оптимизация запросов, например, с помощью индексов на колонках, участвующих в соединении, может значительно улучшить скорость выполнения.
Как соединить таблицу с самой собой по нескольким условиям
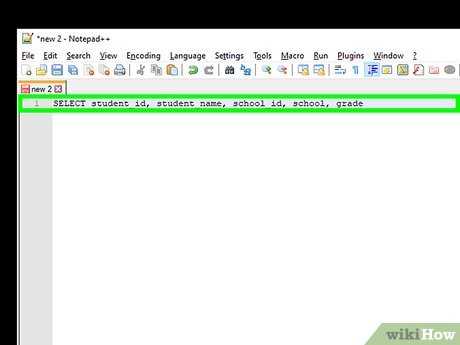
Когда требуется соединить таблицу с самой собой, обычно используется оператор JOIN. Для соединения по нескольким условиям необходимо указать их в блоке ON с помощью логических операторов, таких как AND или OR.
Предположим, что у вас есть таблица сотрудников, где каждый сотрудник может иметь менеджера. Вы хотите получить информацию о сотрудниках и их менеджерах, но с дополнительными условиями, например, только для сотрудников, работающих в одном департаменте и имеющих общий проект с менеджером.
Пример запроса для такого соединения:
SELECT e.name AS employee_name, m.name AS manager_name FROM employees e JOIN employees m ON e.manager_id = m.employee_id AND e.department_id = m.department_id AND e.project_id = m.project_id;
В этом примере:
e– алиас для сотрудников,m– алиас для менеджеров,- условия соединения: сотрудник и менеджер должны работать в одном департаменте и иметь общий проект.
Если требуется учитывать более сложные условия, можно комбинировать AND с OR, создавая гибкие запросы для более точных выборок. Например, если необходимо соединить таблицу по нескольким условиям, но также допускаются случаи, когда проект может не совпадать, добавьте условие OR:
SELECT e.name AS employee_name, m.name AS manager_name FROM employees e JOIN employees m ON e.manager_id = m.employee_id AND (e.department_id = m.department_id OR e.project_id = m.project_id);
В таком запросе результат будет включать сотрудников и их менеджеров, работающих в одном департаменте или на одном проекте.
Важно помнить, что при использовании соединений с несколькими условиями стоит внимательно следить за порядком логических операторов и скобками, чтобы избежать неожиданных результатов.
Ошибки, которые могут возникнуть при самосоединении таблицы
При самосоединении таблицы в SQL могут возникнуть различные проблемы, которые затрудняют корректную обработку данных. Рассмотрим несколько распространённых ошибок и способы их предотвращения.
- Отсутствие явных условий соединения: Если при самосоединении не указаны явные условия в блоке
ON, SQL создаёт декартово произведение, что может привести к значительному увеличению объёма данных. Это может вызвать ошибки переполнения памяти или замедление выполнения запросов. - Неверное использование псевдонимов: При работе с самосоединениями необходимо использовать псевдонимы для каждой из копий таблицы. Игнорирование этой практики может привести к путанице в запросах и ошибкам при фильтрации данных.
- Ошибка в логике условия соединения: Ошибки в написании условий соединения могут привести к неправильному выбору строк. Например, если соединение не уточняется корректно, можно случайно получить данные, которые не должны быть связаны между собой.
- Перепутанные поля для соединения: В случае использования нескольких условий для соединения таблицы с самой собой важно правильно указать поля для сопоставления. Неправильное сочетание полей может привести к некорректным данным в результате.
- Отсутствие индексов: При самосоединении больших таблиц отсутствие индексов на полях, участвующих в соединении, может существенно снизить производительность запроса. Рекомендуется индексировать поля, которые используются в условиях соединения.
- Использование ненужных типов соединений: Часто разработчики используют
INNER JOIN, когда для решения задачи подходитLEFT JOINили наоборот. Это может привести к потерям данных, особенно если одно из соединённых полей может содержать пустые значения. - Избыточное количество соединений: При многократных соединениях одной таблицы с самой собой важно следить за количеством соединений. Чрезмерное использование таких запросов может снизить их производительность, особенно если таблица содержит большое количество строк.
- Ошибки при агрегации данных: При выполнении агрегации после самосоединения нужно помнить, что некорректное использование функций агрегации может привести к ошибкам или некорректным результатам, например, при подсчёте сумм или средних значений.
Для предотвращения этих ошибок важно тщательно проверять условия соединений, использовать псевдонимы и правильно оптимизировать запросы. Следует также учитывать возможное влияние на производительность при работе с большими объёмами данных и внимательно подходить к выбору типа соединения.
Как оптимизировать запросы с самосоединением для больших данных
Самосоединения (self-joins) могут существенно замедлить выполнение запросов на больших наборах данных из-за необходимости многократного поиска и объединения строк в таблице. Для повышения производительности необходимо учитывать несколько ключевых аспектов.
1. Использование индексов – важнейшая мера для ускорения запросов. Создание индексов на столбцах, по которым выполняется соединение, существенно улучшает время выполнения. В идеале индексы должны быть созданы на полях, участвующих в условиях ON или WHERE. Например, если таблица соединяется по полю user_id, создание индекса на этом столбце повысит скорость поиска соответствий.
2. Ограничение выборки данных – минимизация объема данных, с которыми выполняется самосоединение, позволяет снизить нагрузку. Это можно достичь через фильтрацию данных до выполнения соединения. Например, если нужно получить записи только за последний месяц, лучше сначала отфильтровать таблицу по дате, а затем уже делать самосоединение.
3. Избегание использования SELECT * – извлечение только нужных столбцов уменьшает объем обрабатываемых данных. Использование точного списка столбцов в запросе позволяет не только ускорить выполнение, но и снизить использование памяти.
4. Применение JOIN вместо подзапросов – в некоторых случаях замена подзапроса на самосоединение может существенно улучшить производительность. Это особенно актуально для сложных запросов с множественными уровнями вложенности, где использование JOIN может упростить выполнение.
5. Использование ограничений на количество результатов – если запрос генерирует избыточное количество данных, добавление ограничения по числу строк, например через LIMIT, помогает сократить время выполнения и предотвратить излишнюю нагрузку на сервер.
6. Параллельная обработка – для крупных таблиц с большим числом строк можно использовать возможности параллельной обработки запросов. Многие СУБД поддерживают параллельные запросы, что позволяет обрабатывать несколько частей данных одновременно. Это требует дополнительной настройки, но может значительно ускорить выполнение запроса.
7. Анализ и оптимизация выполнения запроса – всегда полезно проанализировать план выполнения запроса с помощью инструментов EXPLAIN или аналогичных в вашей СУБД. Это позволит выявить узкие места и оптимизировать запросы, исключив лишние операции или изменив порядок соединений.
Соблюдая эти принципы, можно существенно повысить производительность запросов с самосоединением, минимизируя время отклика при работе с большими данными.
Вопрос-ответ:
Что такое соединение таблицы с самой собой в SQL?
Соединение таблицы с самой собой (или самосоединение) в SQL — это процесс, при котором одна и та же таблица используется в запросе дважды. В таких случаях таблица получает два разных псевдонима (алиаса), чтобы различать её экземпляры. Это полезно, например, для поиска связей между строками в одной таблице, таких как иерархические структуры или взаимосвязи между данными.
Когда нужно использовать самосоединение в SQL?
Самосоединение может понадобиться, если данные, которые нужно сравнить или связать, находятся в одной таблице. Например, если у вас есть таблица сотрудников, и каждый сотрудник связан с менеджером, который также является сотрудником этой же таблицы. В таком случае самосоединение поможет вам соединить строки этой таблицы и получить информацию о менеджере для каждого сотрудника.