Объединение таблиц – ключевая операция в SQL, позволяющая собирать данные из разных источников в один логический набор. На практике это используется для составления отчетов, анализа связанной информации или подготовки данных для BI-систем. Основные способы объединения – INNER JOIN, LEFT JOIN, RIGHT JOIN и FULL OUTER JOIN. Выбор метода зависит от того, какие записи должны быть включены в результат.
Чтобы корректно выполнить объединение, необходимо наличие связующего столбца, обычно представляющего собой первичный ключ одной таблицы и внешний ключ другой. Например, если есть таблица orders с заказами и customers с клиентами, связывающим столбцом может быть customer_id. Важно, чтобы типы данных этих столбцов совпадали, иначе потребуется приведение типов, что может повлиять на производительность.
При использовании INNER JOIN возвращаются только те строки, где найдено совпадение в обеих таблицах. LEFT JOIN включает все строки из левой таблицы и добавляет данные из правой, если совпадение найдено, или NULL в противном случае. RIGHT JOIN работает аналогично, но приоритет отдается правой таблице. FULL OUTER JOIN объединяет все строки из обеих таблиц, заполняя NULL там, где совпадений нет.
Чтобы избежать дублирования данных и путаницы, особенно при наличии одинаковых имен столбцов в обеих таблицах, рекомендуется использовать алиасы и указывать, из какой таблицы берется каждый столбец. Это делает запросы более читаемыми и облегчает отладку. Также следует следить за индексами на столбцах соединения – их наличие значительно ускоряет выполнение запросов, особенно при больших объемах данных.
Объединение таблиц с помощью INNER JOIN
INNER JOIN используется для выборки строк, у которых есть совпадения по указанному условию в обеих таблицах. Основное требование – наличие логически связанных столбцов, чаще всего внешнего ключа в одной таблице и первичного ключа в другой.
Синтаксис: SELECT столбцы FROM таблица1 INNER JOIN таблица2 ON таблица1.ключ = таблица2.ключ. Обратите внимание: порядок таблиц влияет только на читаемость, а не на результат.
Если в таблице orders есть поле customer_id, связанное с id из таблицы customers, запрос SELECT orders.id, customers.name FROM orders INNER JOIN customers ON orders.customer_id = customers.id вернёт только те заказы, у которых есть соответствующий покупатель. Строки без совпадений исключаются полностью.
При использовании псевдонимов повышается удобство чтения: SELECT o.id, c.name FROM orders o INNER JOIN customers c ON o.customer_id = c.id. Это особенно полезно при объединении более двух таблиц.
При работе с одноимёнными столбцами необходимо указывать полные имена или псевдонимы, иначе возникнет конфликт: SELECT a.id, b.id FROM table_a a INNER JOIN table_b b ON a.ref_id = b.id.
INNER JOIN исключает NULL-значения в ключевых полях объединения. Чтобы избежать потери данных при отсутствии связей, рассмотрите LEFT JOIN, если требуется сохранить строки из первой таблицы.
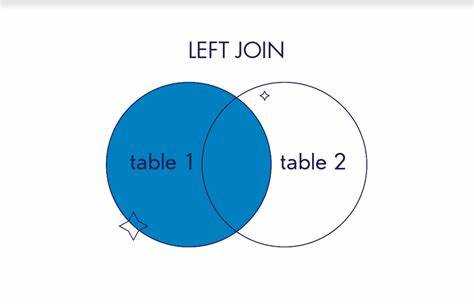
Использование LEFT JOIN для сохранения всех строк из первой таблицы
Оператор LEFT JOIN позволяет объединить две таблицы таким образом, чтобы результат содержал все строки из левой (первой) таблицы, даже если для некоторых из них отсутствуют соответствия во второй таблице. Это особенно полезно при анализе данных с неполной информацией или необходимости отображения всех элементов, независимо от наличия связей.
- Левая таблица – та, что указана первой в выражении
FROM. - Правая таблица – та, что присоединяется с помощью
LEFT JOIN. - Если соответствия не найдено, значения столбцов правой таблицы заполняются
NULL.
Пример: нужно получить список всех сотрудников и информацию об их проектах, если такие есть.
SELECT employees.name, projects.title
FROM employees
LEFT JOIN projects ON employees.project_id = projects.id;Рекомендации:
- Уточняйте условие
ON– от него зависит корректность результата. Пример:ON employees.department_id = departments.id. - Используйте
IS NULLвWHERE, если нужно отобрать только те строки, где нет соответствий. Например, сотрудники без проектов. - Для повышения читаемости используйте псевдонимы таблиц:
FROM employees e LEFT JOIN projects p ON e.project_id = p.id. - Избегайте
WHEREфильтров по правой таблице безIS NULL– они могут превратитьLEFT JOINвINNER JOINпо сути.
Такой подход позволяет сохранять полную картину по основной таблице даже при отсутствии данных во вспомогательной.
Применение RIGHT JOIN при необходимости включить все строки второй таблицы
Оператор RIGHT JOIN используется в случаях, когда требуется сохранить все строки из второй (правой) таблицы вне зависимости от наличия соответствующих записей в первой. Это особенно актуально при анализе справочников, логов или неполных связей между сущностями.
Допустим, есть таблица Employees с данными о сотрудниках и таблица Departments со списком отделов. Нужно получить список всех отделов, включая те, в которых нет сотрудников. Запрос будет выглядеть так:
SELECT Departments.DepartmentName, Employees.Name FROM Employees RIGHT JOIN Departments ON Employees.DepartmentID = Departments.ID;
Этот запрос вернёт все отделы, даже если в них не работает ни один сотрудник. Поля из Employees для таких строк будут содержать NULL.
RIGHT JOIN удобен для проверки неполных связей. Например, можно выявить несвязанные строки во второй таблице, добавив условие WHERE Employees.ID IS NULL. Это позволяет быстро определить, какие записи остались без сопоставления в первой таблице.
Следует избегать использования RIGHT JOIN, если порядок таблиц в выражении FROM не соответствует логике обработки. В большинстве случаев предпочтительнее переписать запрос с использованием LEFT JOIN, изменив порядок таблиц, так как LEFT JOIN читается интуитивно проще и более распространён.
RIGHT JOIN полезен при генерации отчётов, где правая таблица играет роль основы – например, перечень всех продуктов с указанием наличия продаж. В этом случае гарантируется отображение всей номенклатуры, включая те позиции, по которым ещё не было операций.
Разница между JOIN и UNION при объединении таблиц
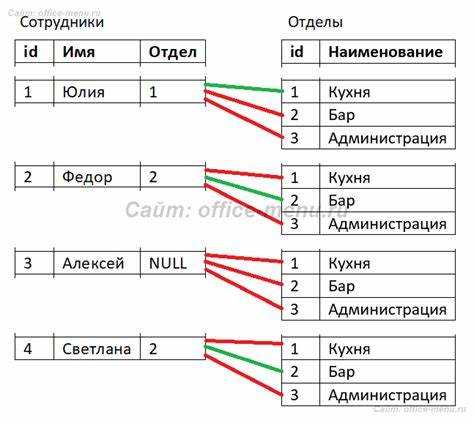
JOIN используется для объединения строк из двух таблиц на основе логического отношения между ними, чаще всего через совпадение значений в связанных столбцах. Например, INNER JOIN возвращает только те строки, в которых найдено соответствие по ключу в обеих таблицах. LEFT JOIN включает все строки из левой таблицы и добавляет данные из правой, если есть совпадения; при отсутствии – проставляются NULL.
UNION объединяет результаты двух SELECT-запросов в один набор данных, исключая дубликаты. Главное условие: количество и порядок столбцов в обоих запросах должны совпадать, а их типы быть совместимыми. Для сохранения дубликатов применяется UNION ALL, что полезно для анализа повторяющихся значений.
JOIN применяется, когда необходимо связать таблицы по логике данных – например, заказ и покупатель. UNION нужен, если требуется получить объединённый список из одинаковых по структуре данных, находящихся в разных таблицах – например, архивные и текущие записи.
При JOIN можно использовать фильтрацию, сортировку и агрегации в одном запросе. UNION требует выполнения этих операций в каждом SELECT отдельно. JOIN эффективнее при нормализованных структурах, UNION – при работе с распределёнными или логически разобщёнными данными.
Объединение таблиц с дублирующими значениями: работа с ON и USING
При объединении таблиц с дублирующими значениями критически важно точно указать условия соединения. Оператор ON позволяет использовать сложные выражения и сравнивать столбцы с разными именами. Например:
SELECT * FROM employees e JOIN departments d ON e.dept_id = d.id;
В этом случае явное указание столбцов помогает избежать неоднозначностей, особенно когда в обеих таблицах присутствуют поля с одинаковыми именами, но разным содержимым. Использование ON обязательно при наличии более одного условия соединения или при необходимости фильтрации по логическим операторам.
Оператор USING применяется, если столбцы, по которым происходит соединение, имеют одинаковые имена и типы. Пример:
SELECT * FROM orders JOIN customers USING(customer_id);
Здесь результат автоматически исключает дублирование столбца customer_id, он будет отображён только один раз. Однако USING нельзя применить, если необходимо использовать алиасы или проводить соединение по выражению (например, table1.col + table2.col).
Также важно помнить, что JOIN с дублирующими значениями может нарушить семантику запроса, если не проанализировать кардинальность связей. Всегда проверяйте ожидаемое количество строк до и после соединения.
Обработка NULL-значений при объединении таблиц

При объединении таблиц в SQL часто встречаются строки с NULL-значениями. Эти значения требуют особого внимания, поскольку они могут влиять на результаты объединений. Важно понимать, как NULL-значения ведут себя в различных операциях объединения и как корректно с ними работать.
При использовании оператора JOIN NULL-значения могут проявляться как в таблицах, так и в результатах объединения. Например, если один из столбцов содержит NULL, условие соединения не выполнится для таких строк. В случае использования INNER JOIN, строки с NULL в поле соединения будут исключены из результатов, поскольку условие объединения для них не выполняется.
Для работы с NULL в объединениях можно использовать несколько подходов:
- LEFT JOIN: При объединении с LEFT JOIN строки из левой таблицы всегда будут присутствовать в результате, даже если соответствующая строка в правой таблице имеет NULL в поле соединения. Это позволяет сохранить все данные из левой таблицы, несмотря на отсутствие соответствующих значений в правой.
- IS NULL и IS NOT NULL: В условиях соединения можно явно проверять столбцы на наличие NULL-значений с помощью операторов
IS NULLилиIS NOT NULL. Например, можно соединить только те строки, где в одном из столбцов отсутствуют NULL.
Пример использования LEFT JOIN для обработки NULL-значений:
SELECT a.id, a.name, b.amount
FROM table1 a
LEFT JOIN table2 b ON a.id = b.id;В этом примере строки из table1 будут присутствовать в результате, даже если для них не найдется соответствующих строк в table2, а значения для amount будут NULL.
При использовании RIGHT JOIN и FULL JOIN обработка NULL-значений аналогична: для строк, не имеющих соответствий в другой таблице, будет возвращен NULL в соответствующих столбцах.
Обработка NULL-значений также играет важную роль в агрегации данных. Функции агрегирования, такие как SUM(), AVG(), COUNT(), игнорируют NULL-значения, что может влиять на результаты подсчета. Использование COALESCE() позволяет заменить NULL на значимые значения, что предотвращает пропуск данных в расчетах.
Таким образом, правильная обработка NULL-значений помогает избежать потери данных и делает объединение таблиц более гибким и точным.
Вопрос-ответ:
Что такое объединение таблиц в SQL?
Объединение таблиц в SQL — это процесс соединения данных из двух или более таблиц, чтобы получить единую таблицу с информацией, которая есть в этих таблицах. Основные способы объединения — это различные виды операций JOIN: INNER JOIN, LEFT JOIN, RIGHT JOIN и FULL JOIN, которые позволяют объединять данные на основе общих полей или условий.