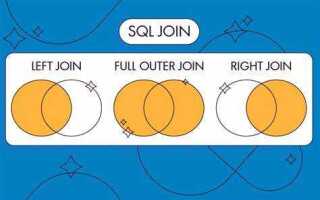
Соединение таблиц в SQL – это базовая операция, которая позволяет работать с данными из нескольких источников в рамках одного запроса. Наиболее распространённый метод соединения – это использование оператора JOIN, который помогает связать строки из разных таблиц, если они имеют общие данные. При этом важно понимать, какие типы соединений существуют и как выбрать правильное для конкретной задачи.
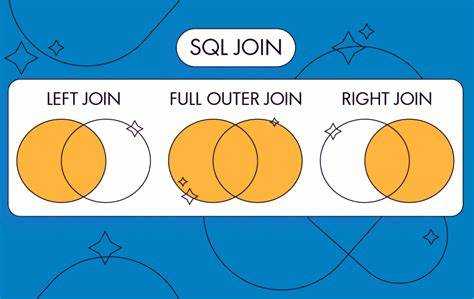
Основные типы соединений: INNER JOIN, LEFT JOIN, RIGHT JOIN и FULL JOIN. INNER JOIN используется для выбора строк, которые имеют совпадения в обеих таблицах. LEFT JOIN и RIGHT JOIN сохраняют все строки из одной из таблиц, добавляя данные из другой таблицы только при наличии совпадений. FULL JOIN возвращает все строки из обеих таблиц, заполняя пропуски значениями NULL, если нет совпадений.
Выбор подходящего типа соединения зависит от того, какие данные вам нужно получить. Например, если вам нужны только те записи, которые присутствуют в обеих таблицах, используйте INNER JOIN. Если важно сохранить все записи из одной таблицы, даже если они не имеют соответствующих значений в другой, выбирайте LEFT JOIN или RIGHT JOIN, в зависимости от того, какая таблица для вас является основной.
Использование оператора JOIN для соединения таблиц
Оператор JOIN используется для комбинирования данных из двух или более таблиц на основе взаимосвязанного столбца. Это основной инструмент для работы с нормализованными базами данных, где данные распределены по нескольким таблицам.
Основные типы JOIN включают:
- INNER JOIN – соединяет только те строки, которые имеют совпадения в обеих таблицах.
- LEFT JOIN (или LEFT OUTER JOIN) – включает все строки из левой таблицы, а из правой – только совпадающие. Если совпадений нет, то значения из правой таблицы будут NULL.
- RIGHT JOIN (или RIGHT OUTER JOIN) – аналогичен LEFT JOIN, но включает все строки из правой таблицы.
- FULL JOIN (или FULL OUTER JOIN) – включает строки, которые имеют совпадения в одной из таблиц или в обеих.
Чтобы выполнить соединение, важно правильно указать условие ON, которое определяет, по какому столбцу будет происходить связывание. Например, для соединения таблицы orders и customers по столбцу customer_id, запрос будет выглядеть так:
SELECT orders.order_id, customers.customer_name FROM orders INNER JOIN customers ON orders.customer_id = customers.customer_id;
При использовании JOIN важно учитывать порядок объединяемых таблиц. Например, при использовании LEFT JOIN таблица, указанная первой, определяет, какие строки будут возвращены. Для LEFT JOIN все строки из левой таблицы будут сохранены, даже если в правой таблице нет совпадений.
Помимо стандартных операторов соединения, можно использовать условия фильтрации с помощью WHERE, а также добавлять сортировку с ORDER BY для упорядочивания результатов. Например, для сортировки по имени клиента:
SELECT orders.order_id, customers.customer_name FROM orders INNER JOIN customers ON orders.customer_id = customers.customer_id ORDER BY customers.customer_name;
Для повышения производительности запросов с несколькими JOIN важно оптимизировать индексы на столбцах, по которым происходит соединение. Наличие индексов может значительно ускорить выполнение запросов, особенно в больших базах данных.
Типы JOIN: INNER JOIN, LEFT JOIN, RIGHT JOIN и FULL JOIN
В SQL существует несколько типов соединений, каждый из которых используется для различных сценариев извлечения данных из нескольких таблиц. Рассмотрим основные из них: INNER JOIN, LEFT JOIN, RIGHT JOIN и FULL JOIN.
INNER JOIN
INNER JOIN выполняет соединение между двумя таблицами, оставляя только те строки, которые имеют соответствующие значения в обеих таблицах. Этот тип соединения является наиболее часто используемым и всегда исключает строки, которые не имеют совпадений.
- Подходит для выборки данных, когда необходимо получить записи, существующие в обеих таблицах.
- Пример запроса:
SELECT * FROM orders INNER JOIN customers ON orders.customer_id = customers.customer_id; - Отсутствие совпадений означает, что строка не будет включена в результат.
LEFT JOIN
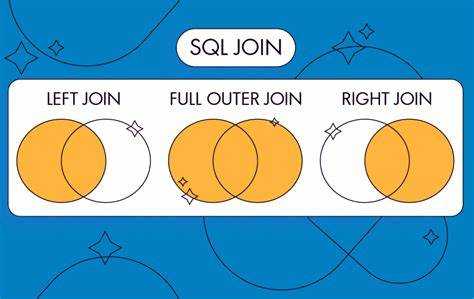
LEFT JOIN (или LEFT OUTER JOIN) возвращает все строки из левой таблицы и соответствующие строки из правой. Если в правой таблице нет соответствующих данных, то результат будет содержать NULL для столбцов правой таблицы.
- Полезен, когда нужно сохранить все данные из левой таблицы, независимо от того, существуют ли соответствующие записи в правой.
- Пример запроса:
SELECT * FROM customers LEFT JOIN orders ON customers.customer_id = orders.customer_id; - Если в правой таблице нет совпадений, то поля правой таблицы будут заполнены NULL.
RIGHT JOIN
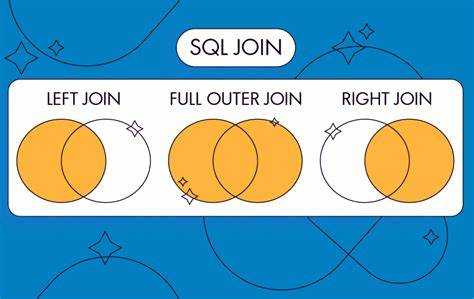
RIGHT JOIN (или RIGHT OUTER JOIN) аналогичен LEFT JOIN, но возвращает все строки из правой таблицы и соответствующие строки из левой. Если для строки правой таблицы нет совпадений в левой, результат будет содержать NULL в столбцах левой таблицы.
- Используется, когда важно сохранить все данные из правой таблицы, вне зависимости от наличия соответствующих строк в левой.
- Пример запроса:
SELECT * FROM orders RIGHT JOIN customers ON orders.customer_id = customers.customer_id; - Если нет совпадений в левой таблице, соответствующие поля будут заполнены NULL.
FULL JOIN
FULL JOIN (или FULL OUTER JOIN) возвращает все строки из обеих таблиц, включая те, для которых нет совпадений в другой таблице. Если строки из одной таблицы не имеют соответствий в другой, то поля отсутствующей таблицы будут заполнены NULL.
- Подходит для получения полного набора данных, включая строки, которые могут не иметь пар в другой таблице.
- Пример запроса:
SELECT * FROM orders FULL JOIN customers ON orders.customer_id = customers.customer_id; - Отличается от других JOIN тем, что результат будет включать все строки из обеих таблиц.
Пример использования INNER JOIN для объединения данных
INNER JOIN используется для объединения строк из двух таблиц, где для каждой строки из первой таблицы находятся совпадающие строки во второй таблице. При этом выбираются только те строки, которые имеют соответствия в обеих таблицах.
Рассмотрим пример: у нас есть две таблицы – orders (заказы) и customers (клиенты). Таблица orders содержит информацию о заказах, а таблица customers – данные о клиентах. Мы хотим получить список заказов с указанием имени клиента.
SQL-запрос для этого будет выглядеть так:
SELECT orders.order_id, orders.order_date, customers.customer_name FROM orders INNER JOIN customers ON orders.customer_id = customers.customer_id;
Здесь мы объединяем таблицы orders и customers по полю customer_id, которое присутствует в обеих таблицах. INNER JOIN гарантирует, что в результирующем наборе данных будут только те заказы, у которых есть соответствующий клиент. Если у заказа нет клиента или у клиента нет заказа, такая строка в результат не попадет.
Важно помнить, что порядок таблиц в запросе не влияет на результат при использовании INNER JOIN, но он может быть значимым в других контекстах. Также важно учитывать индексы на колонках, участвующих в объединении, чтобы улучшить производительность запроса.
Данный метод полезен, когда нужно соединить таблицы с четко определенными связями и исключить несоответствующие данные, обеспечивая более точные результаты.
Как объединить таблицы по нескольким условиям
Когда нужно объединить данные из двух таблиц с несколькими условиями, можно использовать несколько подходов в SQL, включая комбинацию логических операторов в условии объединения. Для этого применяются операторы AND и OR внутри условия ON в JOIN.
Рассмотрим пример с двумя таблицами: employees (сотрудники) и departments (отделы). Мы хотим получить информацию о сотрудниках, которые работают в определённом отделе и в определённом городском офисе.
SELECT e.name, e.position, d.department_name FROM employees e JOIN departments d ON e.department_id = d.department_id AND e.city = d.city
В этом запросе используется два условия для соединения: e.department_id = d.department_id и e.city = d.city. Эти два условия вместе обеспечивают правильное объединение таблиц.
В случаях, когда нужно объединить таблицы по разным признакам с разными приоритетами, можно использовать OR для более гибкого подхода. Например, если сотрудники могут работать в разных офисах, но их надо объединить с отделами, находящимися в том же городе или с одинаковым номером отдела, запрос будет выглядеть так:
SELECT e.name, e.position, d.department_name FROM employees e JOIN departments d ON e.department_id = d.department_id OR e.city = d.city
Здесь результат будет включать как сотрудников с одинаковым department_id, так и тех, кто работает в одном городе, независимо от отдела.
Чтобы избежать дублирования данных при соединении по нескольким условиям, можно использовать дополнительные фильтры в WHERE или применить ограничения через DISTINCT, если это необходимо для получения уникальных записей.
- AND: Условия должны быть выполнены одновременно. Подходит, если необходимо строгое совпадение по нескольким критериям.
- OR: Одно из условий может быть выполнено. Используется, если допустимы более широкие варианты объединения.
- WHERE: Дополнительная фильтрация уже после выполнения
JOIN, если нужно сузить результат по другим параметрам.
Когда объединение происходит по нескольким условиям, важно правильно учитывать приоритеты логических операторов, чтобы запрос работал как ожидается. В некоторых случаях, использование скобок для группировки условий позволяет управлять их порядком и избежать недоразумений в логике запроса.
Как избежать дублирования данных при соединении таблиц

Чтобы избежать дублирования данных при соединении таблиц в SQL, важно учитывать особенности используемых типов соединений и правильно структурировать запросы. Главная цель – обеспечить, чтобы каждая строка в результатах запроса представляла уникальную запись, исключая повторяющиеся значения.
Один из методов предотвращения дублирования – использование оператора JOIN с фильтрацией дублирующихся строк. Например, если соединяем таблицы с помощью INNER JOIN, можно применять условие для выборки уникальных записей из каждой таблицы, чтобы исключить ненужные повторения.
Кроме того, важно использовать условие GROUP BY, которое группирует данные по определённым полям. Это не только помогает избежать дублирования, но и может быть полезным для агрегации данных, таких как подсчёт количества или вычисление суммы. Важно правильно выбирать поля для группировки, чтобы результат запроса содержал только уникальные комбинации значений.
Использование оператора DISTINCT также поможет устранить дубли. Этот оператор исключает повторяющиеся строки в результате запроса. Однако стоит помнить, что DISTINCT применим только к строкам в результате, и не всегда подходит для сложных соединений, где необходимо учитывать не только уникальные строки, но и их связи между таблицами.
Для сложных ситуаций, когда необходимо соединить таблицы с множественными одинаковыми значениями, важно проанализировать структуру данных и оценить, какие ключи или индексы могут быть использованы для предотвращения дублирования. Часто помогает использование уникальных индексов в исходных таблицах, что минимизирует вероятность появления дубликатов на уровне базы данных.
Пример запроса, который использует DISTINCT для устранения дублирующихся данных при соединении таблиц:
SELECT DISTINCT t1.id, t1.name, t2.address
FROM customers AS t1
INNER JOIN orders AS t2 ON t1.id = t2.customer_id;
Такой запрос исключит повторяющиеся записи, если один клиент имеет несколько заказов, обеспечив уникальные строки для каждого клиента с их адресами.
Использование алиасов для улучшения читаемости запроса
Алиасы (псевдонимы) играют важную роль в SQL-запросах, особенно когда приходится работать с несколькими таблицами. Применение алиасов помогает упростить и сделать запросы более понятными, а также избежать излишней сложности при использовании длинных и неудобочитаемых имен таблиц или столбцов.
Для того чтобы улучшить читаемость запроса, алиасы назначаются непосредственно в разделе FROM и JOIN. Это особенно важно при объединении таблиц, когда одно название может повторяться несколько раз. Например, если требуется соединить таблицы customers и orders, алиасы могут сделать запрос компактнее и понятнее.
Пример использования алиасов:
SELECT c.customer_id, o.order_date
FROM customers AS c
JOIN orders AS o ON c.customer_id = o.customer_id;
В этом примере customers получает алиас c, а orders – o. Это позволяет сократить записи, а также улучшить восприятие запроса, так как сразу понятно, что за каждый столбец отвечает. Особенно это удобно, когда имена столбцов из разных таблиц совпадают.
Алиасы также могут быть полезны при работе с функциями или выражениями, например, при использовании агрегатных функций или подзапросов:
SELECT AVG(o.total_price) AS avg_price
FROM orders AS o
WHERE o.order_date BETWEEN '2025-01-01' AND '2025-12-31';
Здесь AVG(o.total_price) получает алиас avg_price, что позволяет легко понять, что за результат возвращает запрос, не обращая внимания на детали вычисления.
Использование алиасов особенно важно в сложных запросах с множественными соединениями. Правильно подобранные алиасы облегчают поиск и исправление ошибок, а также упрощают понимание структуры данных для других разработчиков.
Для улучшения читаемости важно придерживаться следующих рекомендаций:
- Использовать короткие и интуитивно понятные алиасы, соответствующие именам таблиц или их контексту.
- Обязательно использовать алиасы при соединении нескольких таблиц с одинаковыми названиями столбцов.
- Не злоупотреблять сокращениями, если они могут сбить с толку.
Алиасы – это простой, но эффективный способ улучшить читаемость SQL-запросов, повышая их удобство как для разработчика, так и для тех, кто будет работать с кодом в будущем.
Оптимизация запросов с соединениями таблиц
При выполнении запросов с соединениями таблиц важно учитывать, что неэффективные соединения могут значительно ухудшить производительность. Чтобы минимизировать время выполнения запросов, необходимо учитывать несколько ключевых аспектов.
1. Использование индексов. Для таблиц, которые часто участвуют в соединениях, рекомендуется создавать индексы на столбцах, по которым происходит соединение. Это ускоряет поиск соответствующих записей и снижает нагрузку на систему. Однако важно избегать излишнего количества индексов, так как это может замедлить операции вставки и обновления данных.
2. Правильный выбор типа соединения. Использование разных типов соединений (INNER JOIN, LEFT JOIN, RIGHT JOIN, CROSS JOIN) может влиять на производительность запроса. INNER JOIN чаще всего быстрее, так как ограничивает результат только совпадающими записями, тогда как LEFT JOIN может привести к большему объему данных. Если вам не нужны все записи из обеих таблиц, лучше использовать INNER JOIN, чтобы уменьшить размер выборки.
3. Порядок таблиц в запросе. В некоторых случаях порядок указания таблиц в запросе может повлиять на его производительность. СУБД может обрабатывать таблицы в другом порядке в зависимости от статистики и стоимости выполнения. Однако, если вы точно знаете, какая таблица содержит меньше данных, расположите её первой.
4. Использование подзапросов. Иногда подзапросы могут быть полезными для фильтрации данных до того, как они будут соединены. Это особенно актуально для таблиц с большим объемом данных, где использование подзапроса может уменьшить размер выборки и ускорить соединение. Однако стоит помнить, что подзапросы могут быть менее эффективны по сравнению с объединением таблиц через JOIN, особенно если подзапросы выполняются несколько раз.
5. Анализ статистики и планов выполнения. Использование EXPLAIN и других инструментов анализа запросов позволяет выявить узкие места в запросе. Это поможет понять, какие соединения или фильтры замедляют выполнение запроса. Оценка плана выполнения запроса позволяет оптимизировать порядок соединений и уменьшить количество операций чтения и записи.
6. Уменьшение объема данных. По возможности старайтесь минимизировать количество обрабатываемых данных. Например, вместо того чтобы соединять всю таблицу с другой, ограничьте выборку с помощью WHERE, чтобы заранее отфильтровать лишние записи. Это также уменьшит нагрузку на сервер и ускорит выполнение запроса.
7. Параллельная обработка запросов. Некоторые СУБД поддерживают выполнение запросов в параллельном режиме. Это может значительно ускорить обработку запросов, особенно если таблицы большие и запросы включают несколько соединений. Параллельная обработка позволяет распределить нагрузку на несколько процессоров или серверов, что может снизить время выполнения запросов.
Вопрос-ответ:
Как объединить две таблицы в SQL запросе?
Чтобы соединить две таблицы в SQL, используется оператор `JOIN`. Он позволяет выбрать данные из обеих таблиц, основываясь на общих значениях в столбцах. Например, можно использовать `INNER JOIN` для выбора строк, которые существуют в обеих таблицах, или `LEFT JOIN`, чтобы получить все строки из первой таблицы, даже если нет совпадений во второй.