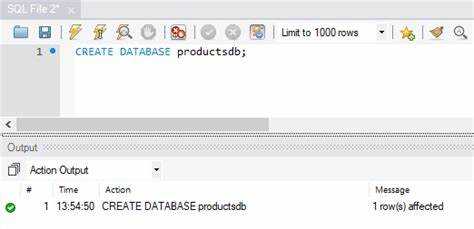
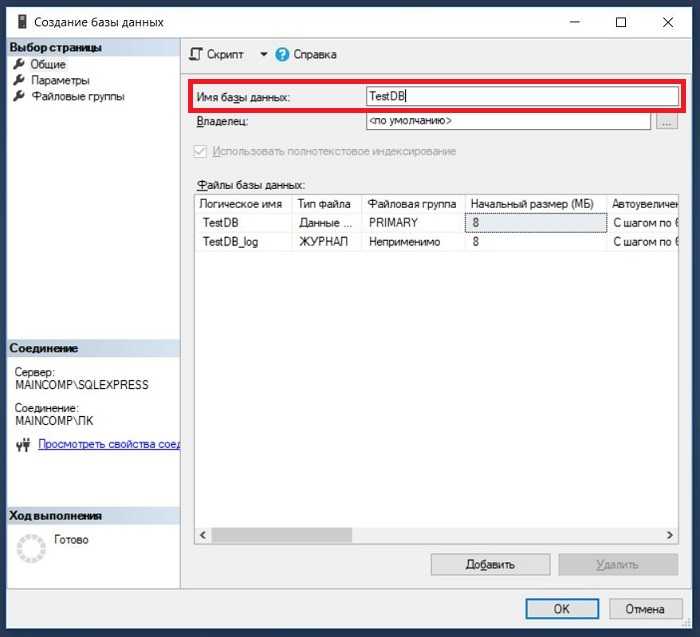
Для создания базы данных с помощью SQL необходимо понимать основные команды, которые используются в процессе разработки. SQL предоставляет набор инструкций для работы с данными, включая создание, изменение и удаление баз данных и таблиц. Основной командой для создания базы данных является CREATE DATABASE, после чего можно переходить к добавлению таблиц и настройке связей между ними.
После создания базы данных с помощью CREATE DATABASE имя_базы;, следующий шаг – это создание таблиц. Для этого используется команда CREATE TABLE, в которой определяются имена столбцов, их типы данных и другие характеристики. Например, для создания таблицы с информацией о пользователях можно использовать такой запрос:
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);В этом примере таблица users содержит четыре столбца: id, name, email и created_at. Для столбца id указано, что он является первичным ключом, что обеспечивает уникальность каждой записи. Важно правильно выбирать типы данных для столбцов, чтобы минимизировать ошибки при вводе данных и повысить производительность.
Настройка связей между таблицами выполняется через FOREIGN KEY, что позволяет создавать полноценные реляционные базы данных. Например, если существует таблица заказов, которая ссылается на таблицу пользователей, можно использовать следующий запрос для установления связи:
CREATE TABLE orders (
order_id INT PRIMARY KEY,
user_id INT,
amount DECIMAL(10, 2),
FOREIGN KEY (user_id) REFERENCES users(id)
);Этот запрос создает таблицу заказов и связывает столбец user_id с id из таблицы users. Такая связь помогает поддерживать целостность данных и облегчает выполнение запросов с соединениями.
Успешное создание базы данных и ее структурирование позволяет значительно повысить эффективность хранения и обработки данных. Использование SQL для этих целей обеспечивает точность, гибкость и масштабируемость в работе с большими объемами информации.
Выбор СУБД для создания базы данных
При выборе СУБД для создания базы данных важно учитывать несколько ключевых факторов: масштабируемость, поддержка транзакций, производительность и требования к совместимости. Каждая система управления базами данных (СУБД) имеет свои особенности, которые могут подойти или не подойти в зависимости от специфики проекта.
Для небольших проектов или при ограниченных ресурсах хорошим выбором может стать MySQL или PostgreSQL. Обе СУБД бесплатны, поддерживают основные функции и широко используются в веб-разработке. MySQL подходит для проектов с высокой нагрузкой на чтение данных, в то время как PostgreSQL лучше справляется с обработкой сложных запросов и поддерживает более гибкие типы данных.
Для крупных и сложных проектов стоит рассматривать СУБД, такие как Oracle Database или Microsoft SQL Server. Эти системы обеспечивают высокую производительность при обработке больших объемов данных и предоставляют расширенные возможности для масштабирования и обеспечения надежности. Однако они требуют значительных ресурсов и могут иметь высокие затраты на лицензирование.
Если проект включает в себя работу с неструктурированными данными или требует гибкости в управлении данными, стоит обратить внимание на NoSQL базы данных, такие как MongoDB или Cassandra. Они позволяют эффективно работать с большим количеством данных, которые не требуют строгой схемы, и обеспечивают высокую производительность в распределенных системах.
Выбор СУБД должен базироваться на реальных потребностях проекта, учитывая тип данных, нагрузку и требования к масштабируемости. Важно также учитывать возможные затраты на поддержку и обучение команды.
Подключение к серверу базы данных с использованием SQL
Для работы с базой данных SQL необходимо сначала установить соединение с сервером. Это можно сделать с помощью различных инструментов и библиотек, в зависимости от используемой платформы и типа базы данных. Ниже приведены основные шаги для подключения к серверу базы данных.
1. Убедитесь, что у вас есть доступ к серверу базы данных. Для этого необходимы:
- Адрес сервера (IP-адрес или доменное имя).
- Порт, на котором работает сервер (обычно 3306 для MySQL, 5432 для PostgreSQL).
- Имя пользователя и пароль для аутентификации.
- Имя базы данных, к которой нужно подключиться.
2. Использование командной строки SQL-клиента. Пример для MySQL:
mysql -h <сервер> -u <пользователь> -p<пароль> <база_данных>
Для PostgreSQL:
psql -h <сервер> -U <пользователь> -d <база_данных>
3. Использование библиотек для работы с SQL в коде (например, для Python). Пример для Python и библиотеки psycopg2 для PostgreSQL:
import psycopg2 conn = psycopg2.connect( host="<сервер>", database="<база_данных>", user="<пользователь>", password="<пароль>" )
4. Обработка ошибок подключения. При подключении к серверу могут возникнуть ошибки. Важно правильно их обрабатывать, чтобы избежать сбоев в работе. Основные типы ошибок:
- Ошибка неверных учетных данных (неправильный логин или пароль).
- Ошибка подключения (неправильный адрес или порт сервера).
- Ошибка доступности базы данных (база данных не существует или недоступна).
5. Закрытие соединения. После завершения работы с базой данных необходимо закрыть соединение. Пример для Python:
conn.close()
Эти шаги обеспечат успешное подключение к серверу базы данных и позволят вам начать выполнять SQL-запросы.
Создание структуры базы данных: определение таблиц и типов данных
Таблицы служат основными объектами для хранения данных. Каждая таблица состоит из строк и столбцов. Столбцы представляют атрибуты объекта, а строки – конкретные записи. Каждый столбец должен иметь имя и тип данных, который определяет, какие значения можно в него вносить. Названия столбцов должны быть осмысленными и отражать суть данных. Например, для таблицы сотрудников это могут быть столбцы «id», «имя», «фамилия», «должность», «дата_приема».
После определения таблиц важно правильно выбрать типы данных для каждого столбца. SQL поддерживает различные типы данных, среди которых можно выделить:
- INTEGER – для хранения целых чисел. Например, для поля «id» или «возраст».
- VARCHAR – для строковых данных переменной длины. Используется для хранения текста, например, имени или адреса. Рекомендуется указывать максимальную длину строки, чтобы избежать избыточного использования памяти.
- DATE – для хранения дат. Идеален для записи информации о дате рождения, дате регистрации и т.д.
- DECIMAL – для хранения чисел с фиксированной точностью, например, для финансовых данных.
- BOOLEAN – для хранения логических значений (TRUE/FALSE).
Каждый тип данных имеет свои ограничения. Например, VARCHAR позволяет хранить строки, но их длина должна быть ограничена, чтобы не тратить ресурсы на лишнюю память. В то время как TEXT может хранить большие объемы текста, но его использование может быть менее эффективным. Важно подходить к выбору типов данных с учетом требований к производительности и объема данных.
Кроме того, следует учесть ограничения, такие как уникальность данных, обязательность заполнения (NOT NULL), а также создание индексов для ускорения поиска.
После того как таблицы и типы данных определены, можно переходить к созданию связей между таблицами. Для этого используют внешние ключи, которые обеспечивают целостность данных между таблицами. Например, связь между таблицами «сотрудники» и «отделы» может быть реализована через внешний ключ, ссылающийся на идентификатор отдела в таблице «отделы».
Таким образом, создание структуры базы данных – это процесс, требующий внимательности к деталям. Правильно определенные таблицы и типы данных обеспечат эффективность работы базы данных и облегчат дальнейшую работу с ней.
Определение первичных ключей и индексов для таблиц
Первичный ключ – это столбец или набор столбцов, который уникально идентифицирует каждую запись в таблице. Он не может содержать пустых значений и дубли. В большинстве случаев это поле с уникальными значениями, например, идентификатор записи.
- Первичный ключ устанавливается при создании таблицы через
PRIMARY KEY. - Каждая таблица может иметь только один первичный ключ, состоящий из одного или нескольких столбцов.
- Первичный ключ автоматически создаёт уникальный индекс, что ускоряет поиск записей по этому ключу.
Пример создания таблицы с первичным ключом:
CREATE TABLE Users (
user_id INT PRIMARY KEY,
username VARCHAR(50),
email VARCHAR(100)
);Индексы – это структуры данных, которые ускоряют выполнение запросов на основе поиска, сортировки и фильтрации. Они не обязательны, но значительно повышают производительность при работе с большими объёмами данных.
- Индекс можно создавать для одного или нескольких столбцов таблицы.
- Индексы могут быть уникальными или не уникальными. Уникальные индексы запрещают дублирование значений, аналогично первичному ключу.
- Индексы часто создаются для столбцов, по которым выполняются часто используемые запросы с условиями поиска.
Пример создания индекса для столбца:
CREATE INDEX idx_username ON Users (username);При использовании индексов важно учитывать их влияние на производительность. Слишком большое количество индексов может замедлить операции вставки, обновления и удаления, так как каждый индекс должен быть обновлён.
Рекомендации по созданию индексов:
- Создавайте индексы только на тех столбцах, по которым выполняются часто используемые запросы.
- Используйте составные индексы, если запросы часто фильтруют по нескольким столбцам одновременно.
- Удаляйте ненужные индексы, чтобы избежать излишней нагрузки на систему.
Пример создания составного индекса:
CREATE INDEX idx_user_email ON Users (username, email);Добавление данных в таблицы с помощью SQL-запросов
Для внесения данных в таблицы базы данных используется SQL-запрос INSERT INTO. С помощью этого запроса можно добавлять новые строки в таблицу. Основной синтаксис выглядит так:
INSERT INTO имя_таблицы (колонка1, колонка2, колонка3)
VALUES (значение1, значение2, значение3);Каждое значение должно соответствовать типу данных в соответствующей колонке. Если столбец позволяет хранить пустые значения (NULL), то можно указать NULL в списке значений.
Пример добавления данных в таблицу employees с полями name, age и position:
INSERT INTO employees (name, age, position)
VALUES ('Иван Иванов', 30, 'Менеджер');Можно добавлять несколько строк за один запрос. В таком случае нужно перечислить значения для каждой строки, разделяя их запятой:
INSERT INTO employees (name, age, position)
VALUES ('Мария Петрова', 25, 'Разработчик'),
('Сергей Сидоров', 40, 'Директор');Если в запросе не указываются все колонки таблицы, то необходимо уточнить только те, для которых будут вставляться данные. Например, если столбец id является автоинкрементируемым, его можно опустить в списке колонок:
INSERT INTO employees (name, age)
VALUES ('Алексей Козлов', 28);Для предотвращения ошибок, связанных с дублированием уникальных значений (например, по первичному ключу), можно использовать конструкцию INSERT IGNORE или ON DUPLICATE KEY UPDATE, чтобы игнорировать или обновлять записи при столкновении с уже существующими значениями.
INSERT INTO employees (name, age, position)
VALUES ('Иван Иванов', 30, 'Менеджер')
ON DUPLICATE KEY UPDATE position = 'Менеджер';Важно учитывать, что для успешного выполнения запроса на добавление данных, в таблице должны быть предусмотрены все необходимые ограничения (например, уникальность значений или соответствие типов данных), иначе запрос может завершиться с ошибкой.
Использование внешних ключей для обеспечения целостности данных
Для создания внешнего ключа используется команда FOREIGN KEY, которая определяет столбец в одной таблице как ссылку на первичный ключ другой таблицы. Это позволяет предотвратить введение данных, которые не соответствуют существующим записям в связанных таблицах.
Пример создания внешнего ключа:
CREATE TABLE Заказы (
ID INT PRIMARY KEY,
Дата DATE,
Клиент_ID INT,
FOREIGN KEY (Клиент_ID) REFERENCES Клиенты(ID)
);В этом примере столбец Клиент_ID в таблице Заказы ссылается на столбец ID в таблице Клиенты. Это обеспечивает, что каждый заказ связан с действительным клиентом, который существует в таблице Клиенты.
Когда внешний ключ установлен, SQL автоматически проверяет целостность данных, предотвращая добавление записей, которые нарушают эти связи. Например, нельзя вставить заказ с несуществующим Клиент_ID. Аналогично, если попытаться удалить запись в таблице Клиенты, которая имеет связанные заказы, система либо заблокирует операцию, либо предложит каскадное удаление (если задано соответствующее правило).
Правила, которые могут быть применены при удалении или обновлении данных, связаны с поведением внешнего ключа:
- CASCADE – удаляет или обновляет связанные записи автоматически.
- SET NULL – заменяет связанные значения на
NULLпри удалении или обновлении. - NO ACTION – запрещает удаление или обновление, если существуют связанные записи.
- RESTRICT – аналогично
NO ACTION, но проверка выполняется сразу после попытки изменения данных.
Пример с каскадным удалением:
CREATE TABLE Заказы (
ID INT PRIMARY KEY,
Клиент_ID INT,
FOREIGN KEY (Клиент_ID) REFERENCES Клиенты(ID) ON DELETE CASCADE
);Использование внешних ключей не только повышает целостность данных, но и упрощает поддержание базы данных, предотвращая ошибки, связанные с устаревшими или несогласованными записями. Это позволяет в дальнейшем легко поддерживать и обновлять данные, минимизируя риски нарушений целостности.
Модификация и удаление данных: SQL-запросы на изменение
В SQL для изменения и удаления данных используются операторы UPDATE и DELETE. Оба запроса важны для работы с базами данных, поскольку позволяют манипулировать содержимым таблиц в ответ на различные потребности.
UPDATE применяется для изменения существующих данных в таблице. Синтаксис запроса следующий:
UPDATE имя_таблицы SET колонка1 = новое_значение1, колонка2 = новое_значение2 WHERE условие;
В запросе указывается таблица, данные в которой нужно изменить. Использование оператора WHERE обязательно, чтобы избежать изменения всех строк в таблице. Например, чтобы обновить адрес сотрудника с определенным ID:
UPDATE сотрудники SET адрес = 'Новый адрес' WHERE id = 123;
Важно помнить, что если условие WHERE не указано или написано неверно, запрос может обновить все строки таблицы, что приведет к непредсказуемым последствиям.
DELETE используется для удаления данных. Запрос выглядит так:
DELETE FROM имя_таблицы WHERE условие;
Если условие WHERE не указано, будет удалена вся таблица. Пример удаления записи по ID сотрудника:
DELETE FROM сотрудники WHERE id = 123;
Чтобы предотвратить случайное удаление всех строк, всегда проверяйте условие WHERE. Для защиты данных в некоторых случаях используют транзакции, которые можно откатить в случае ошибки.
Еще одна важная деталь – запросы UPDATE и DELETE могут затронуть несколько строк сразу, если условие WHERE соответствует нескольким записям. В таких случаях рекомендуется заранее проверять данные с помощью SELECT-запроса, чтобы убедиться, что изменение или удаление затронет только нужные записи.
Оптимизация работы с базой данных: индексы и запросы
Типы индексов: для улучшения производительности часто применяют несколько типов индексов. Наиболее распространенные – это B-деревья и хеш-индексы. B-деревья обеспечивают эффективный поиск по диапазону значений, а хеш-индексы – быстрый доступ по конкретному значению. Выбор зависит от типа запросов, которые часто выполняются.
Как выбрать индексы? Индексы стоит создавать на столбцах, которые участвуют в фильтрации или сортировке данных. Например, для поля email в таблице пользователей индекс будет полезен, так как часто может использоваться для поиска.
Когда не стоит использовать индексы? Индексы замедляют операции вставки, обновления и удаления, так как база данных должна обновлять индекс при каждом изменении данных. Также не стоит индексировать столбцы с высокой уникальностью значений (например, автоинкрементные ID), так как это не даст значительного прироста в скорости запросов.
Оптимизация запросов включает в себя несколько ключевых аспектов. Использование JOIN может значительно замедлить выполнение запроса, если индексы не настроены должным образом. Рекомендуется индексация колонок, участвующих в соединениях. Особенно это важно для сложных запросов с несколькими таблицами.
Анализ и улучшение выполнения запросов: инструменты, такие как EXPLAIN в MySQL или PostgreSQL, позволяют изучить план выполнения запроса. Эти инструменты показывают, какие индексы используются, сколько времени занимает каждый шаг и как можно улучшить запрос. Использование EXPLAIN помогает выявить узкие места, например, отсутствие индекса на колонке, по которой происходит фильтрация.
Избегайте избыточных индексов. Создание лишних индексов может замедлить операции записи и увеличит использование памяти. Важно регулярно анализировать существующие индексы и удалять те, которые не используются в запросах.
Основной принцип оптимизации работы с базой данных – это баланс между быстродействием чтения и затратами на обновление данных. Правильное использование индексов и оптимизация запросов могут значительно улучшить производительность системы и сократить время отклика на запросы.