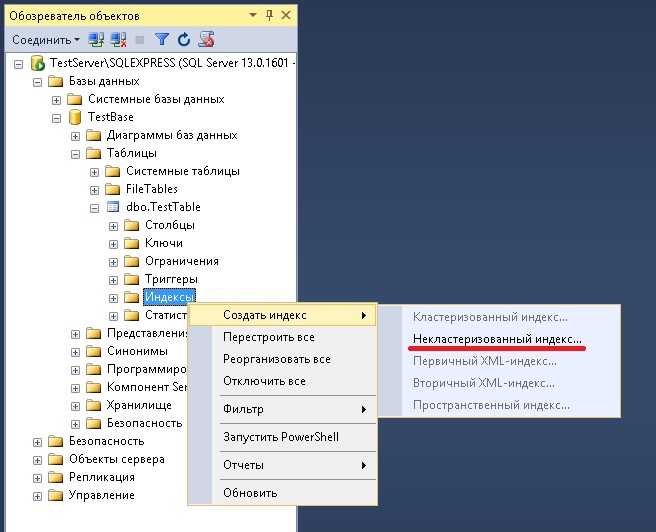
Некластеризованный индекс в SQL представляет собой структуру данных, которая улучшает скорость поиска и выборки данных в таблице, не изменяя физический порядок строк в этой таблице. В отличие от кластеризованных индексов, некластеризованный индекс хранит отдельную структуру, в которой содержатся ссылки на данные таблицы. Это позволяет ускорить выполнение запросов, особенно в случаях, когда необходимо быстро искать по неуникальным или часто обновляемым колонкам.
Создание некластеризованного индекса начинается с выбора подходящего столбца для индексации. Он должен быть часто используемым в операциях поиска или сортировки. Например, создание индекса на колонке с датами или ID может значительно ускорить выполнение запросов с условиями WHERE или ORDER BY, особенно если данные таблицы велики. При этом важно помнить, что индексация увеличивает время выполнения операций вставки, обновления и удаления данных, так как необходимо поддерживать актуальность индекса.
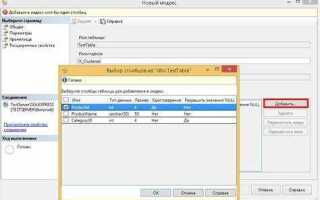
Для создания некластеризованного индекса в SQL используется команда CREATE INDEX. Пример создания индекса на столбце username в таблице users выглядит следующим образом:
CREATE INDEX idx_username ON users(username);Этот индекс будет хранить указатели на строки таблицы users, организованные по значению в столбце username. Если в запросах часто используются другие столбцы, можно создавать составные индексы, которые включают несколько колонок, что позволяет повысить производительность еще больше.
При проектировании некластеризованных индексов важно учитывать баланс между производительностью запросов и дополнительными ресурсами, необходимыми для поддержания индекса. На практике стоит избегать создания слишком большого количества индексов, поскольку каждый индекс требует места для хранения и времени на его обновление при изменении данных в таблице.
Выбор столбцов для некластеризованного индекса
1. Частота использования в условиях WHERE. Столбцы, которые часто используются в фильтрах запросов (например, в условиях WHERE), должны быть первыми кандидатами для индекса. Это снижает количество сканируемых строк в таблице и ускоряет выполнение запросов.
2. Уникальность значений столбца. Индексы наиболее эффективны на столбцах с высокой уникальностью значений. Столбцы с небольшим количеством уникальных значений (например, булевы значения или столбцы с ограниченным набором категорий) будут давать меньший прирост производительности.
3. Распределение данных. Для эффективной работы индекса важно учитывать, как распределены данные в столбцах. Если данные в столбце сильно сгруппированы, индекс будет менее эффективен, чем если бы данные были равномерно распределены. Например, индекс на столбце с временными метками, содержащими даты только одного года, может быть неэффективен.
4. Частота обновлений. Столбцы, которые часто обновляются, могут не быть лучшими кандидатами для индексации. Частые изменения требуют дополнительных затрат на обновление индекса, что снижает производительность при изменении данных.
5. Составные индексы. Если запросы часто используют несколько столбцов в фильтре, имеет смысл создавать составные индексы. Важно правильно определить порядок столбцов в составном индексе: на первом месте должен быть столбец, который наиболее часто используется для фильтрации или сортировки данных.
6. Тип данных. Тип данных столбца также играет важную роль. Индексы на текстовых или бинарных данных могут быть менее эффективными, чем на числовых или дата-временах, из-за большей сложности операций поиска и сортировки.
7. Размер таблицы и выборка данных. Индексы наиболее эффективны в больших таблицах, где необходимо быстро найти данные. В маленьких таблицах создание индекса может не дать значительных улучшений производительности, а наоборот, увеличить накладные расходы.
8. Комбинация с другими индексами. Важно учитывать, как выбранные столбцы будут взаимодействовать с другими индексами в базе данных. Индексы должны дополнять друг друга, а не конкурировать, что может привести к снижению производительности.
Команда SQL для создания некластеризованного индекса
Для создания некластеризованного индекса в SQL используется команда CREATE INDEX. Этот индекс улучшает производительность запросов за счет быстрого поиска данных, однако порядок строк в таблице не меняется. Структура данных индекса отделена от основной таблицы, что позволяет использовать несколько индексов для одной таблицы.
Пример базового синтаксиса для создания некластеризованного индекса:
CREATE INDEX имя_индекса
ON имя_таблицы (столбец1, столбец2, ...);В этом синтаксисе:
- имя_индекса – название создаваемого индекса. Рекомендуется давать осмысленные имена, чтобы легко понять, на каких столбцах индекс будет создан.
- имя_таблицы – название таблицы, к которой будет применен индекс.
- столбец1, столбец2, … – столбцы, на основе которых будет создан индекс. Можно указывать один или несколько столбцов.
Пример создания индекса на одном столбце:
CREATE INDEX idx_name ON customers (last_name);Если необходимо создать индекс на нескольких столбцах, например, для ускорения поиска по имени и фамилии:
CREATE INDEX idx_name ON customers (first_name, last_name);Также можно указать дополнительные параметры:
- UNIQUE – если индекс должен обеспечивать уникальность значений в столбце или наборе столбцов. Такой индекс не позволит вставить дублирующиеся записи.
- WITH (options) – для указания дополнительных параметров, таких как метод хранения или статистика.
Пример с уникальным индексом:
CREATE UNIQUE INDEX idx_unique_name ON customers (email);Некоторые СУБД (например, SQL Server или PostgreSQL) поддерживают возможность создания индексов с указанием параметров хранения или методики обновления. Это полезно в случае работы с большими объемами данных или с нуждой в тонкой настройке производительности.
При проектировании индексов следует учитывать:
- Индекс следует создавать на столбцах, которые часто участвуют в условиях WHERE или в операциях сортировки (ORDER BY).
- Создание большого количества индексов может снизить производительность при вставке, обновлении или удалении данных.
- Некластеризованные индексы лучше использовать для оптимизации запросов на чтение, но их нужно поддерживать, что увеличивает нагрузку на систему.
После создания индекса можно использовать команду DROP INDEX для его удаления, если он больше не нужен:
DROP INDEX имя_индекса ON имя_таблицы;Параметры, влияющие на производительность некластеризованного индекса
Производительность некластеризованного индекса зависит от ряда факторов, которые важно учитывать при проектировании базы данных. Рассмотрим ключевые из них.
Тип данных. Выбор типа данных для индексируемых колонок значительно влияет на скорость работы индекса. Например, числовые типы данных (INT, BIGINT) обрабатываются быстрее, чем строки (VARCHAR, TEXT). Это связано с тем, что операции сравнения для чисел выполняются быстрее, чем для строк, что снижает затраты на поиск и сортировку.
Количество уникальных значений. Чем больше уникальных значений в индексируемом столбце, тем эффективнее индекс, так как он может использовать меньшее количество уровней дерева B-дерева. При этом для столбцов с малым количеством уникальных значений (например, булевы или статичные значения) индекс может работать менее эффективно, т.к. его размер будет существенно больше, чем для тех же данных без индекса.
Размер таблицы и количество строк. При большом объеме данных некластеризованный индекс может требовать значительных затрат на обновление. Когда данные таблицы часто изменяются, индексы нужно постоянно пересоздавать, что ведет к дополнительным накладным расходам. Рекомендуется использовать индексы на часто запрашиваемых столбцах, минимизируя их количество в сильно изменяющихся таблицах.
Фрагментация индекса. Со временем индекс может фрагментироваться, что снижает его производительность. Частые операции вставки, удаления и обновления приводят к разрастанию «дыр» в индексе. Регулярная дефрагментация и реорганизация индекса позволяет поддерживать его эффективность на высоком уровне.
Состав индекса. Композитные индексы, состоящие из нескольких столбцов, могут существенно повысить производительность запросов, если они оптимально соответствуют шаблонам запросов. Однако важно учитывать, что использование слишком большого количества столбцов в индексе может замедлить его обновление, так как изменение любого из столбцов потребует перерасчета индекса.
Доступность памяти и настройки буфера. Для эффективного выполнения запросов с некластеризованным индексом важным параметром является доступность памяти для хранения индекса в кэше. Если индексы не помещаются в память, база данных вынуждена обращаться к диску, что значительно замедляет выполнение запросов. Поэтому правильная настройка кэширования и буферных пулов является важным элементом для поддержания высокой производительности.
Выбор между уникальностью и производительностью. Индексы с уникальными значениями требуют дополнительных усилий на проверку уникальности при каждом обновлении данных, что может замедлить операции вставки и обновления. В некоторых случаях, для повышения общей производительности системы, можно отказаться от уникальных ограничений на индексируемые столбцы, если уникальность данных поддерживается другими средствами.
Удаление и изменение некластеризованного индекса
Удаление некластеризованного индекса осуществляется с помощью команды DROP INDEX. Индекс можно удалить как на уровне таблицы, так и на уровне схемы базы данных. Для этого нужно указать имя индекса и объект, к которому он привязан. Пример запроса для удаления индекса:
DROP INDEX index_name ON table_name;Если индекс был создан с явной привязкой к схеме, то перед именем индекса необходимо указать имя схемы, например:
DROP INDEX schema_name.index_name;При удалении индекса происходит освобождение ресурсов, занимаемых этим объектом, однако данные в самой таблице остаются неизменными. Это важно учитывать при проектировании системы, чтобы избежать потери производительности из-за отсутствия индекса.
Изменение некластеризованного индекса невозможно напрямую. Однако, если требуется изменить характеристики индекса (например, добавить или удалить столбцы), нужно создать новый индекс с нужными параметрами, а затем удалить старый. Пример последовательности действий:
- Создание нового индекса с нужными параметрами:
CREATE NONCLUSTERED INDEX new_index_name ON table_name (column1, column2);- Удаление старого индекса:
DROP INDEX old_index_name ON table_name;Также для изменения типа индекса (например, переход с уникального на неуникальный) нужно сначала удалить старый индекс и создать новый с желаемыми характеристиками. Важно учитывать, что создание нового индекса может повлиять на производительность системы, особенно если таблица содержит большие объемы данных. При планировании изменений индексов следует принимать во внимание нагрузку на базу данных в момент выполнения операций.
Для предотвращения ошибок в процессе изменения индекса рекомендуется использовать транзакции. Это позволит откатить изменения, если что-то пойдет не так:
BEGIN TRANSACTION;
CREATE NONCLUSTERED INDEX new_index_name ON table_name (column1, column2);
DROP INDEX old_index_name ON table_name;
COMMIT;Не забывайте, что удаление и изменение индексов может повлиять на производительность запросов, поэтому такие операции лучше выполнять в периоды низкой нагрузки.
Ошибки при создании некластеризованного индекса и способы их устранения
При создании некластеризованного индекса в SQL могут возникать различные ошибки, которые напрямую влияют на производительность и функциональность базы данных. Некоторые из них связаны с неправильной конфигурацией, а другие – с неверным выбором полей для индексации.
Ошибка 1: Неверный выбор столбцов для индексации
Одной из распространённых ошибок является создание индекса на столбцах, которые не используются в запросах с фильтрацией или сортировкой. Это приводит к избыточному использованию памяти и снижению производительности. Чтобы устранить эту ошибку, важно анализировать типы запросов, выполняемых в системе. Если индекс не используется для ускорения запросов, его стоит удалить или пересоздать с учётом требований.
Ошибка 2: Создание индекса на очень больших таблицах
Индекс на больших таблицах может занимать слишком много времени для создания и значительно увеличивать нагрузку на систему. Чтобы минимизировать риски, необходимо выполнять создание индекса в периоды низкой активности. Можно использовать команду WITH (ONLINE = ON) (для SQL Server), чтобы не блокировать таблицу, или настроить операцию создания индекса в несколько этапов для разделённых таблиц.
Ошибка 3: Создание индекса с неудачным порядком столбцов
Некорректный порядок столбцов в индексе может привести к его низкой эффективности. Когда столбцы в индексе имеют неправильную последовательность, база данных не может использовать индекс для оптимизации запросов. Для устранения ошибки важно тщательно анализировать, какие столбцы наиболее часто участвуют в операциях фильтрации или сортировки, и ставить их на первые позиции в индексе.
Ошибка 4: Проблемы с уникальностью индекса
Некоторые пользователи неправильно создают некластеризованные индексы, предполагая, что они автоматически будут уникальными. Однако некластеризованный индекс не подразумевает уникальности данных. Для обеспечения уникальности индекса нужно использовать ключевое слово UNIQUE при его создании. Без этого ограничения на дублирование значений индекса не будет наложено, что может привести к проблемам с целостностью данных.
Ошибка 5: Проблемы с обновлением индекса
Некорректная настройка индекса может вызвать проблемы с его актуальностью после вставки, удаления или обновления данных. Важно настроить правильное автоматическое обновление индексов, чтобы они не становились устаревшими. Для этого стоит использовать анализ производительности запросов и периодическую оптимизацию индексов с помощью команды REBUILD или REORGANIZE, что поможет поддерживать их актуальность.
Ошибка 6: Недостаточная пропускная способность дисков
Создание индекса требует значительных ресурсов хранения и вычислений. Если диск, на котором располагается база данных, не имеет достаточной пропускной способности или свободного пространства, то процесс может завершиться с ошибкой. Решение заключается в мониторинге пространства на дисках перед созданием индекса и перемещении базы данных на более производительные устройства, если это необходимо.
Как проверить использование некластеризованного индекса в запросах

Для проверки использования некластеризованного индекса в запросах можно воспользоваться инструментами профилирования и анализа производительности, доступными в SQL-системах. Наиболее распространённые методы включают использование объяснённых планов выполнения запросов и мониторинг статистики индексов.
В SQL Server можно использовать команду EXPLAIN или SET STATISTICS IO ON, чтобы увидеть, как запрос использует индексы. При этом важно обратить внимание на строку, которая указывает использование некластеризованного индекса, например, NonClustered Index Seek или NonClustered Index Scan. Эти операции показывают, что запрос обращается к некластеризованному индексу для получения данных.
Если индексы не используются, стоит проверить статистику их эффективности с помощью команд, таких как SHOW INDEX в MySQL или pg_stat_user_indexes в PostgreSQL. Это позволяет увидеть количество сканирований индекса, что даёт представление о его реальной востребованности в запросах.
Для оптимизации работы с некластеризованными индексами важно следить за обновлениями статистики индексов. В некоторых случаях индекс может не использоваться, если статистика устарела. Это особенно актуально для сложных запросов, где выборки могут изменяться динамически. Регулярное обновление статистики и реорганизация индексов помогает улучшить их производительность.
Если индекс используется в запросах, но его производительность оставляет желать лучшего, следует обратить внимание на его структуру. Например, в SQL Server можно использовать команду DBCC SHOWCONTIG для анализа фрагментации индекса, которая может влиять на его эффективность.
Таким образом, правильный мониторинг и анализ запросов с помощью объясняющих планов и статистики индексов помогает точно определить, используются ли некластеризованные индексы в запросах, и как улучшить их производительность при необходимости.
Вопрос-ответ:
Что такое некластеризованный индекс в SQL и зачем его использовать?
Некластеризованный индекс в SQL — это структура данных, которая помогает ускорить поиск по таблице, но не изменяет порядок строк в самой таблице. В отличие от кластеризованного индекса, где строки хранятся в физическом порядке, соответствующем индексу, некластеризованный индекс хранит копии значений столбцов, на которые он ссылается, в отдельной структуре. Он используется для ускорения операций выборки данных, особенно когда нужно быстро искать по столбцам, которые не участвуют в сортировке таблицы. Его создание актуально, если требуется многократный доступ к данным по различным колонкам с фильтрами или условиями сортировки, не влияя на структуру самой таблицы.
Как выбрать столбцы для создания некластеризованного индекса?
Выбор столбцов для создания некластеризованного индекса зависит от того, какие запросы к базе данных будут наиболее частыми. Индексы обычно создаются на столбцах, по которым часто выполняются операции фильтрации (например, `WHERE`), сортировки (`ORDER BY`) или соединения (`JOIN`). Также полезно создавать индексы на столбцах, которые используются в агрегатных функциях (например, `COUNT()`, `SUM()` и т.д.). Однако создание индексов на всех столбцах подряд может привести к излишней нагрузке на систему, так как каждый индекс требует дополнительного места и времени на обновление при вставке, обновлении или удалении данных. Рекомендуется проводить анализ запросов и выбирать такие столбцы, которые обеспечат наибольшую производительность при минимальных затратах ресурсов.
Какие недостатки могут быть у некластеризованного индекса в SQL?
Одним из основных недостатков некластеризованного индекса является его влияние на производительность при изменении данных в таблице. Когда происходит вставка, обновление или удаление строк, индексы также нужно обновлять, что может замедлить операции записи. Кроме того, некластеризованный индекс занимает дополнительное место в базе данных, так как хранит отдельную структуру для индексных данных. Еще одним недостатком является возможность ухудшения производительности, если индекс используется неэффективно. Например, если на индекс часто ссылаются в запросах с маленькими выборками, но таблица очень велика, это может привести к дополнительным затратам на поиск и индексацию. Поэтому важно тщательно планировать, на каких столбцах создавать индексы, чтобы не увеличивать нагрузку на систему.